"""
光伏发电量预测系统 - Flask主应用
"""
import os
import json
import traceback
from datetime import datetime
from functools import wraps
import pandas as pd
import numpy as np
from flask import (
Flask, render_template, request, redirect, url_for,
session, jsonify, flash, send_file, g
)
from werkzeug.utils import secure_filename
from config import Config
from models import db, User, Dataset, PredictionRecord
from ml_engine import MLAlgorithms
app = Flask(__name__)
app.config.from_object(Config)
# 确保目录存在
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)
os.makedirs(app.config['DATA_FOLDER'], exist_ok=True)
db.init_app(app)
ml = MLAlgorithms()
# ==================== 工具函数 ====================
def login_required(f):
@wraps(f)
def decorated_function(*args, **kwargs):
if 'user_id' not in session:
if request.is_json or request.headers.get('Content-Type') == 'application/json':
return jsonify({'error': '请先登录'}), 401
return redirect(url_for('login'))
return f(*args, **kwargs)
return decorated_function
def get_current_user():
if 'user_id' in session:
return User.query.get(session['user_id'])
return None
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in app.config['ALLOWED_EXTENSIONS']
def load_dataset_file(filepath, file_type=None):
"""加载数据集文件"""
if not os.path.exists(filepath):
raise FileNotFoundError(f'文件不存在: {filepath}')
if file_type is None:
ext = filepath.rsplit('.', 1)[-1].lower()
file_type = ext
if file_type in ['csv']:
# 尝试不同编码
for encoding in ['utf-8', 'gbk', 'gb2312', 'latin-1']:
try:
return pd.read_csv(filepath, encoding=encoding)
except Exception:
continue
raise ValueError('无法解析CSV文件,请检查编码')
elif file_type in ['xlsx', 'xls']:
return pd.read_excel(filepath)
else:
raise ValueError(f'不支持的文件类型: {file_type}')
# ==================== 认证路由 ====================
@app.route('/')
def index():
if 'user_id' in session:
return redirect(url_for('dashboard'))
return redirect(url_for('login'))
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
data = request.form
username = data.get('username', '').strip()
email = data.get('email', '').strip()
password = data.get('password', '')
confirm = data.get('confirm_password', '')
if not username or not email or not password:
return jsonify({'error': '请填写所有必填字段'}), 400
if password != confirm:
return jsonify({'error': '两次密码不一致'}), 400
if len(password) < 6:
return jsonify({'error': '密码长度至少6位'}), 400
if User.query.filter_by(username=username).first():
return jsonify({'error': '用户名已存在'}), 400
if User.query.filter_by(email=email).first():
return jsonify({'error': '邮箱已注册'}), 400
user = User(username=username, email=email)
user.set_password(password)
db.session.add(user)
db.session.commit()
session['user_id'] = user.id
return jsonify({'success': True, 'message': '注册成功', 'redirect': url_for('dashboard')})
return render_template('auth/register.html')
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
data = request.form
username = data.get('username', '').strip()
password = data.get('password', '')
user = User.query.filter_by(username=username).first()
if not user:
user = User.query.filter_by(email=username).first()
if not user or not user.check_password(password):
return jsonify({'error': '用户名或密码错误'}), 400
user.last_login = datetime.now()
db.session.commit()
session['user_id'] = user.id
session.permanent = True
return jsonify({'success': True, 'message': '登录成功', 'redirect': url_for('dashboard')})
return render_template('auth/login.html')
@app.route('/logout')
def logout():
session.clear()
return redirect(url_for('login'))
# ==================== 页面路由 ====================
@app.route('/dashboard')
@login_required
def dashboard():
user = get_current_user()
datasets = Dataset.query.filter_by(user_id=user.id).order_by(Dataset.created_at.desc()).all()
predictions = PredictionRecord.query.filter_by(user_id=user.id).order_by(PredictionRecord.created_at.desc()).limit(10).all()
stats = {
'dataset_count': len(datasets),
'prediction_count': PredictionRecord.query.filter_by(user_id=user.id).count(),
'total_data_points': sum(d.row_count for d in datasets),
'algorithms_used': len(set(p.algorithm for p in PredictionRecord.query.filter_by(user_id=user.id).all())),
}
return render_template('dashboard.html', user=user, stats=stats,
datasets=[d.to_dict() for d in datasets[:5]],
predictions=[p.to_dict() for p in predictions])
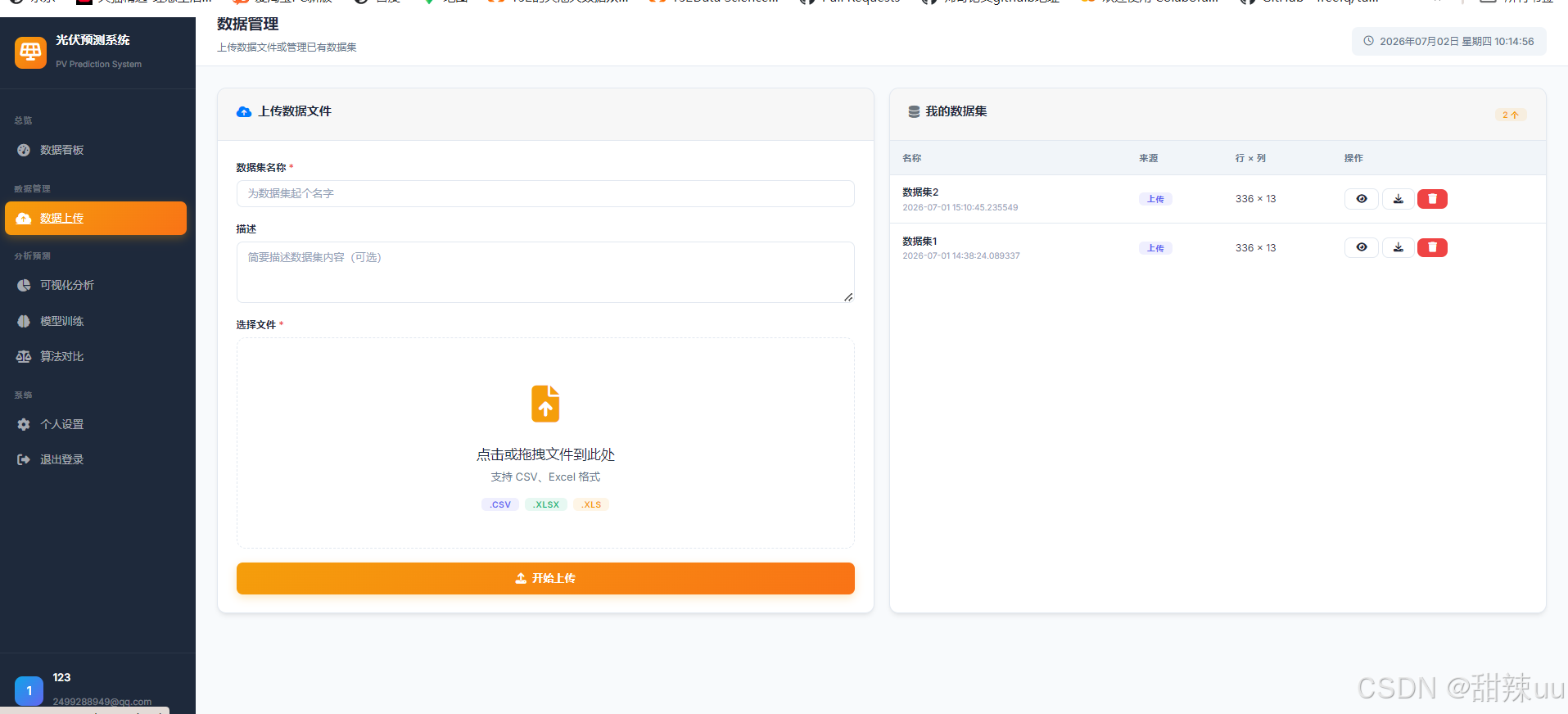
@app.route('/data/upload')
@login_required
def data_upload():
user = get_current_user()
datasets = Dataset.query.filter_by(user_id=user.id).order_by(Dataset.created_at.desc()).all()
return render_template('data/upload.html', user=user, datasets=datasets)
@app.route('/visualization')
@login_required
def visualization():
user = get_current_user()
datasets = Dataset.query.filter_by(user_id=user.id).order_by(Dataset.created_at.desc()).all()
return render_template('visualization/analysis.html', user=user, datasets=datasets)
@app.route('/prediction/train')
@login_required
def prediction_train():
user = get_current_user()
datasets = Dataset.query.filter_by(user_id=user.id, status='active').order_by(Dataset.created_at.desc()).all()
algorithms = MLAlgorithms.get_algorithm_info()
return render_template('prediction/train.html', user=user, datasets=datasets, algorithms=algorithms)
@app.route('/prediction/compare')
@login_required
def prediction_compare():
user = get_current_user()
datasets = Dataset.query.filter_by(user_id=user.id, status='active').order_by(Dataset.created_at.desc()).all()
algorithms = MLAlgorithms.get_algorithm_info()
records = PredictionRecord.query.filter_by(user_id=user.id).order_by(PredictionRecord.created_at.desc()).all()
return render_template('prediction/compare.html', user=user, datasets=datasets,
algorithms=algorithms, records=records)
@app.route('/prediction/results/<int:record_id>')
@login_required
def prediction_results(record_id):
user = get_current_user()
record = PredictionRecord.query.get_or_404(record_id)
if record.user_id != user.id:
return redirect(url_for('prediction_compare'))
return render_template('prediction/results.html', user=user, record=record)
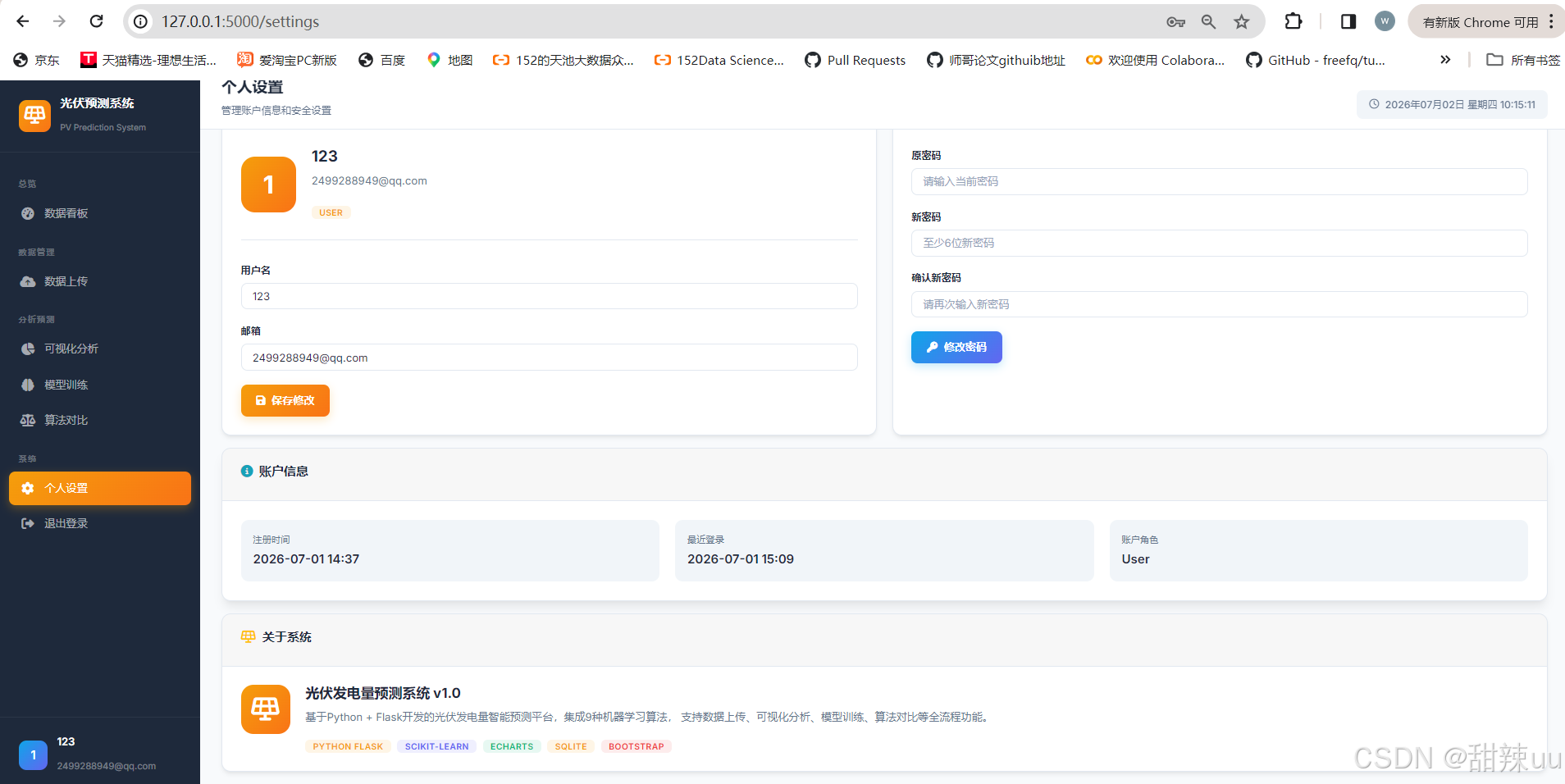
@app.route('/settings')
@login_required
def settings():
user = get_current_user()
return render_template('settings.html', user=user)
# ==================== API: 数据管理 ====================
@app.route('/api/data/upload', methods=['POST'])
@login_required
def api_data_upload():
user = get_current_user()
if 'file' not in request.files:
return jsonify({'error': '请选择文件'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': '请选择文件'}), 400
if not allowed_file(file.filename):
return jsonify({'error': '仅支持CSV、Excel文件'}), 400
filename = secure_filename(file.filename)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f'{timestamp}_{filename}'
filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(filepath)
try:
df = load_dataset_file(filepath)
except Exception as e:
os.remove(filepath)
return jsonify({'error': f'文件解析失败: {str(e)}'}), 400
# 获取列信息
columns_info = {}
for col in df.columns:
col_data = df[col]
if col_data.dtype in ['int64', 'float64', 'int32', 'float32']:
columns_info[col] = {
'type': 'numeric',
'min': float(col_data.min()) if not col_data.isna().all() else 0,
'max': float(col_data.max()) if not col_data.isna().all() else 0,
'mean': round(float(col_data.mean()), 2) if not col_data.isna().all() else 0,
}
else:
columns_info[col] = {
'type': 'categorical',
'unique_count': int(col_data.nunique()),
}
dataset = Dataset(
name=request.form.get('name', file.filename.rsplit('.', 1)[0]),
description=request.form.get('description', ''),
source='upload',
file_path=filepath,
file_type=filename.rsplit('.', 1)[-1],
row_count=len(df),
col_count=len(df.columns),
columns_info=json.dumps(columns_info, ensure_ascii=False),
user_id=user.id,
)
db.session.add(dataset)
db.session.commit()
return jsonify({
'success': True,
'message': '数据上传成功',
'dataset': dataset.to_dict(),
'preview': df.head(20).fillna('').to_dict(orient='records'),
'columns': list(df.columns),
})
@app.route('/api/data/<int:dataset_id>/preview')
@login_required
def api_data_preview(dataset_id):
user = get_current_user()
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
except Exception as e:
return jsonify({'error': f'加载失败: {str(e)}'}), 500
page = request.args.get('page', 1, type=int)
per_page = request.args.get('per_page', 50, type=int)
start = (page - 1) * per_page
end = start + per_page
total = len(df)
df_page = df.iloc[start:end]
return jsonify({
'dataset': dataset.to_dict(),
'columns': list(df.columns),
'data': df_page.fillna('').to_dict(orient='records'),
'total': total,
'page': page,
'per_page': per_page,
'total_pages': (total + per_page - 1) // per_page,
})
@app.route('/api/data/<int:dataset_id>/delete', methods=['DELETE'])
@login_required
def api_data_delete(dataset_id):
user = get_current_user()
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
# 删除文件
if os.path.exists(dataset.file_path):
os.remove(dataset.file_path)
db.session.delete(dataset)
db.session.commit()
return jsonify({'success': True, 'message': '删除成功'})
@app.route('/api/data/<int:dataset_id>/download')
@login_required
def api_data_download(dataset_id):
user = get_current_user()
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
if os.path.exists(dataset.file_path):
return send_file(dataset.file_path, as_attachment=True,
download_name=f'{dataset.name}.csv')
return jsonify({'error': '文件不存在'}), 404
# ==================== API: 可视化分析 ====================
@app.route('/api/visualization/<int:dataset_id>/overview')
@login_required
def api_viz_overview(dataset_id):
user = get_current_user()
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
except Exception as e:
return jsonify({'error': f'加载失败: {str(e)}'}), 500
# 统计信息
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
stats = {}
for col in numeric_cols:
col_data = df[col].dropna()
stats[col] = {
'count': int(len(col_data)),
'mean': round(float(col_data.mean()), 2),
'std': round(float(col_data.std()), 2),
'min': round(float(col_data.min()), 2),
'q25': round(float(col_data.quantile(0.25)), 2),
'q50': round(float(col_data.median()), 2),
'q75': round(float(col_data.quantile(0.75)), 2),
'max': round(float(col_data.max()), 2),
}
# 相关性矩阵
corr = df[numeric_cols].corr().round(3) if len(numeric_cols) > 0 else pd.DataFrame()
corr_data = {
'columns': numeric_cols,
'matrix': corr.values.tolist() if len(corr) > 0 else [],
}
# 时间序列(如果有时间列)
time_col = None
for col in df.columns:
if '时间' in col or 'time' in col.lower() or 'date' in col.lower():
time_col = col
break
time_series = {}
if time_col:
# 采样以减少数据量
sample_step = max(1, len(df) // 500)
df_sample = df.iloc[::sample_step]
time_series = {
'time_col': time_col,
'labels': df_sample[time_col].astype(str).tolist(),
'series': {},
}
for col in numeric_cols:
if col != time_col:
time_series['series'][col] = df_sample[col].fillna(0).tolist()
return jsonify({
'stats': stats,
'correlation': corr_data,
'time_series': time_series,
'row_count': len(df),
'col_count': len(df.columns),
'columns': list(df.columns),
'numeric_columns': numeric_cols,
})
@app.route('/api/visualization/<int:dataset_id>/distribution/<column>')
@login_required
def api_viz_distribution(dataset_id, column):
user = get_current_user()
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
except Exception as e:
return jsonify({'error': f'加载失败: {str(e)}'}), 500
if column not in df.columns:
return jsonify({'error': '列不存在'}), 400
col_data = df[column].dropna()
if col_data.dtype in ['int64', 'float64', 'int32', 'float32']:
# 数值列:直方图
hist, bin_edges = np.histogram(col_data, bins=30)
return jsonify({
'type': 'numeric',
'bins': [round(b, 2) for b in bin_edges.tolist()],
'counts': hist.tolist(),
'stats': {
'mean': round(float(col_data.mean()), 2),
'std': round(float(col_data.std()), 2),
'min': round(float(col_data.min()), 2),
'max': round(float(col_data.max()), 2),
}
})
else:
# 分类列:计数
value_counts = col_data.value_counts().head(20)
return jsonify({
'type': 'categorical',
'labels': value_counts.index.tolist(),
'counts': value_counts.values.tolist(),
})
@app.route('/api/visualization/<int:dataset_id>/scatter')
@login_required
def api_viz_scatter(dataset_id):
user = get_current_user()
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
x_col = request.args.get('x', '')
y_col = request.args.get('y', '')
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
except Exception as e:
return jsonify({'error': f'加载失败: {str(e)}'}), 500
if x_col not in df.columns or y_col not in df.columns:
return jsonify({'error': '列不存在'}), 400
sample_step = max(1, len(df) // 1000)
df_sample = df.iloc[::sample_step]
return jsonify({
'x': df_sample[x_col].fillna(0).tolist(),
'y': df_sample[y_col].fillna(0).tolist(),
'x_name': x_col,
'y_name': y_col,
'count': len(df_sample),
'correlation': round(float(df[x_col].corr(df[y_col])), 3) if df[x_col].dtype in ['int64', 'float64'] else 0,
})
# ==================== API: 预测分析 ====================
@app.route('/api/prediction/train', methods=['POST'])
@login_required
def api_prediction_train():
user = get_current_user()
data = request.get_json()
dataset_id = data.get('dataset_id')
algorithms = data.get('algorithms', [])
features = data.get('features', None)
target = data.get('target', None)
test_size = float(data.get('test_size', 0.2))
params_map = data.get('params', {})
if not dataset_id or not algorithms:
return jsonify({'error': '请选择数据集和算法'}), 400
dataset = Dataset.query.get_or_404(dataset_id)
if dataset.user_id != user.id:
return jsonify({'error': '无权限'}), 403
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
except Exception as e:
return jsonify({'error': f'数据加载失败: {str(e)}'}), 500
try:
# 准备数据
prepared = ml.prepare_data(df, features=features, target=target, test_size=test_size)
except Exception as e:
return jsonify({'error': f'数据预处理失败: {str(e)}'}), 500
# 训练
results = ml.train_multiple(algorithms, prepared, params_map)
# 保存记录
saved_records = []
for result in results:
if 'error' in result:
record = PredictionRecord(
name=f'{result["algorithm_name"]}_{datetime.now().strftime("%m%d%H%M")}',
algorithm=result['algorithm'],
dataset_id=dataset_id,
user_id=user.id,
params=json.dumps(result.get('params', {}), ensure_ascii=False),
status='failed',
error_msg=result['error'],
)
else:
metrics = result['metrics']
record = PredictionRecord(
name=f'{result["algorithm_name"]}_{datetime.now().strftime("%m%d%H%M")}',
algorithm=result['algorithm'],
dataset_id=dataset_id,
user_id=user.id,
params=json.dumps(result.get('params', {}), ensure_ascii=False),
rmse=metrics['rmse'],
mae=metrics['mae'],
r2=metrics['r2'],
mape=metrics['mape'],
train_score=metrics['train_r2'],
test_score=metrics['test_r2'],
feature_count=len(prepared['features']),
sample_count=len(prepared['y_train']) + len(prepared['y_test']),
status='completed',
)
db.session.add(record)
db.session.commit()
saved_records.append(record)
# 返回结果
response_data = {
'success': True,
'results': [],
'features': prepared['features'],
'target': prepared['target'],
}
for i, result in enumerate(results):
record = saved_records[i]
if 'error' in result:
response_data['results'].append({
'record_id': record.id,
'algorithm': result['algorithm'],
'algorithm_name': result['algorithm_name'],
'error': result['error'],
'status': 'failed',
})
else:
response_data['results'].append({
'record_id': record.id,
'algorithm': result['algorithm'],
'algorithm_name': result['algorithm_name'],
'metrics': result['metrics'],
'predictions': result['predictions'],
'feature_importance': result['feature_importance'],
'params': result['params'],
'status': 'completed',
})
return jsonify(response_data)
@app.route('/api/prediction/compare', methods=['POST'])
@login_required
def api_prediction_compare():
"""对比已训练的多个记录"""
user = get_current_user()
data = request.get_json()
record_ids = data.get('record_ids', [])
if not record_ids:
return jsonify({'error': '请选择记录'}), 400
records = PredictionRecord.query.filter(
PredictionRecord.id.in_(record_ids),
PredictionRecord.user_id == user.id,
PredictionRecord.status == 'completed'
).all()
# 重新加载数据并训练以获取预测曲线
results = []
dataset_cache = {}
for record in records:
if record.dataset_id not in dataset_cache:
dataset = Dataset.query.get(record.dataset_id)
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
dataset_cache[record.dataset_id] = df
except Exception:
continue
df = dataset_cache[record.dataset_id]
prepared = ml.prepare_data(df)
try:
result = ml.train_single(record.algorithm, prepared, json.loads(record.params) if record.params else None)
results.append({
'record_id': record.id,
'algorithm': record.algorithm,
'algorithm_name': MLAlgorithms.ALGORITHMS.get(record.algorithm, {}).get('name', record.algorithm),
'metrics': result['metrics'],
'predictions': result['predictions'],
'feature_importance': result['feature_importance'],
})
except Exception as e:
results.append({
'record_id': record.id,
'algorithm': record.algorithm,
'algorithm_name': MLAlgorithms.ALGORITHMS.get(record.algorithm, {}).get('name', record.algorithm),
'error': str(e),
})
return jsonify({'success': True, 'results': results})
@app.route('/api/prediction/<int:record_id>/detail')
@login_required
def api_prediction_detail(record_id):
user = get_current_user()
record = PredictionRecord.query.get_or_404(record_id)
if record.user_id != user.id:
return jsonify({'error': '无权限'}), 403
if record.status != 'completed':
return jsonify({'error': '记录状态异常'}), 400
# 重新训练获取详细数据
dataset = record.dataset
try:
df = load_dataset_file(dataset.file_path, dataset.file_type)
except Exception as e:
return jsonify({'error': f'数据加载失败: {str(e)}'}), 500
prepared = ml.prepare_data(df)
result = ml.train_single(record.algorithm, prepared, json.loads(record.params) if record.params else None)
return jsonify({
'success': True,
'record': record.to_dict(),
'metrics': result['metrics'],
'predictions': result['predictions'],
'feature_importance': result['feature_importance'],
'features': prepared['features'],
'target': prepared['target'],
'algorithm_info': MLAlgorithms.get_algorithm_info(record.algorithm),
})
@app.route('/api/prediction/<int:record_id>/delete', methods=['DELETE'])
@login_required
def api_prediction_delete(record_id):
user = get_current_user()
record = PredictionRecord.query.get_or_404(record_id)
if record.user_id != user.id:
return jsonify({'error': '无权限'}), 403
db.session.delete(record)
db.session.commit()
return jsonify({'success': True, 'message': '删除成功'})
@app.route('/api/algorithms')
@login_required
def api_algorithms():
return jsonify({'algorithms': MLAlgorithms.get_algorithm_info()})
# ==================== API: 用户设置 ====================
@app.route('/api/user/profile', methods=['PUT'])
@login_required
def api_update_profile():
user = get_current_user()
data = request.get_json()
username = data.get('username', '').strip()
email = data.get('email', '').strip()
if not username or not email:
return jsonify({'error': '请填写用户名和邮箱'}), 400
existing = User.query.filter_by(username=username).first()
if existing and existing.id != user.id:
return jsonify({'error': '用户名已存在'}), 400
existing = User.query.filter_by(email=email).first()
if existing and existing.id != user.id:
return jsonify({'error': '邮箱已注册'}), 400
user.username = username
user.email = email
db.session.commit()
return jsonify({'success': True, 'message': '更新成功', 'user': user.to_dict()})
@app.route('/api/user/password', methods=['PUT'])
@login_required
def api_update_password():
user = get_current_user()
data = request.get_json()
old_password = data.get('old_password', '')
new_password = data.get('new_password', '')
if not user.check_password(old_password):
return jsonify({'error': '原密码错误'}), 400
if len(new_password) < 6:
return jsonify({'error': '新密码至少6位'}), 400
user.set_password(new_password)
db.session.commit()
return jsonify({'success': True, 'message': '密码修改成功'})
# ==================== 错误处理 ====================
@app.errorhandler(404)
def not_found(e):
if request.is_json or request.headers.get('Content-Type') == 'application/json':
return jsonify({'error': '资源不存在'}), 404
return render_template('error.html', code=404, message='页面不存在'), 404
@app.errorhandler(500)
def server_error(e):
if request.is_json or request.headers.get('Content-Type') == 'application/json':
return jsonify({'error': '服务器错误'}), 500
return render_template('error.html', code=500, message='服务器内部错误'), 500
# ==================== 模板上下文 ====================
@app.context_processor
def inject_globals():
return {
'current_user': get_current_user(),
'current_year': datetime.now().year,
}
# ==================== 初始化 ====================
def init_db():
with app.app_context():
db.create_all()
# 创建默认管理员
if not User.query.filter_by(username='admin').first():
admin = User(username='admin', email='admin@pv-system.com', role='admin')
admin.set_password('admin123')
db.session.add(admin)
db.session.commit()
print('默认管理员: admin / admin123')
if __name__ == '__main__':
init_db()
print('=' * 50)
print(' 光伏发电量预测系统')
print(' 访问地址: http://127.0.0.1:5000')
print(' 默认账号: admin / admin123')
print('=' * 50)
app.run(debug=True, host='0.0.0.0', port=5000)