在大模型落地应用的过程中,幻觉问题、知识滞后、领域适配差是三大核心痛点。
原生大模型仅依赖训练数据生成内容,不仅容易编造虚假信息,还无法获取训练截止日期后的最新数据,很难满足企业知识库、业务问答、私有文档解析等落地场景。
而 RAG(Retrieval-Augmented Generation,检索增强生成) 技术,正是解决以上问题的最优低成本方案。无需微调大模型、无需海量算力,仅通过外部知识库检索增强上下文,就能大幅提升大模型回答的准确性、实时性与专业性。
本文将从零系统讲解RAG完整技术体系,包含核心原理、优势对比、多格式文档加载、两种主流文本分割策略,最后手把手实现带对话记忆的RAG智能问答机器人,全程可直接复刻落地。
一、RAG核心基础:原理、优势与适用场景
1.1 什么是RAG?
RAG 检索增强生成,是一种大模型外部知识增强技术。核心逻辑是:在大模型生成回答前,先从自定义外部权威知识库中检索相关内容,将检索结果作为上下文拼接进提示词,辅助大模型生成精准、可靠的答案。
简单来说:RAG = 语义检索 + 大模型生成,让大模型不再凭空作答,而是有据可依。
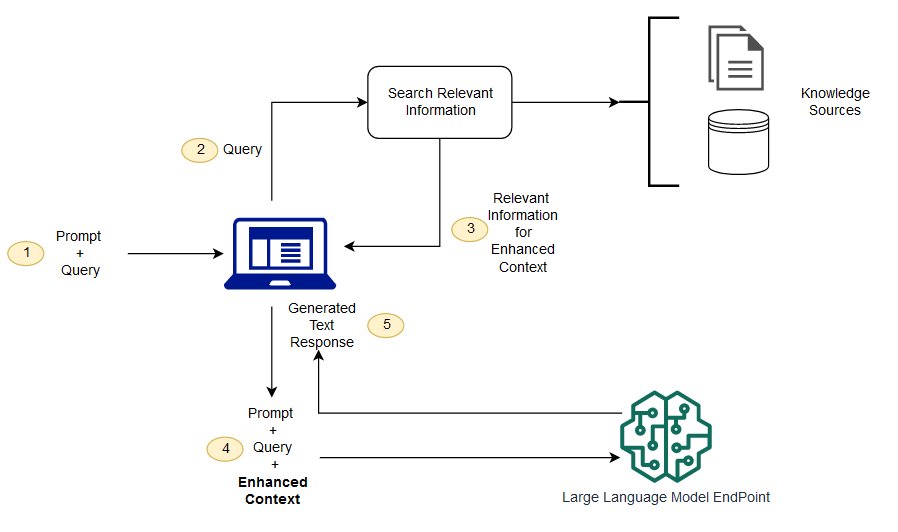
1.2 原生LLM的核心痛点
未接入RAG的原生大模型,落地企业场景存在诸多致命问题:
- 幻觉问题:无答案时强行编造虚假信息,可信度极低
- 知识滞后:训练数据固定,无法获取最新资讯、业务数据
- 领域缺失:不适配企业私有知识库、行业专属数据
- 来源不可追溯:回答无权威依据,无法核验真伪
1.3 RAG vs 模型微调:核心选型对比
很多开发者会纠结微调和RAG的选型,二者核心差异如下,绝大多数轻量化落地场景优先选RAG:
| 对比维度 | RAG检索增强生成 | 模型微调 |
|---|---|---|
| 算力成本 | 极低,无需训练模型 | 极高,需大量GPU算力 |
| 数据需求 | 无需标注,原始文档即可使用 | 需要大量高质量标注数据 |
| 更新迭代 | 实时更新,替换文档即可更新知识 | 需重新训练,迭代成本极高 |
| 适用场景 | 私有知识库、实时数据、高频更新场景 | 固定领域、需要对齐输出风格的场景 |
1.4 RAG核心优势
- 低成本落地:无需模型训练,快速部署上线
- 知识实时更新:支持对接最新文档、网页、动态数据
- 答案可溯源:可展示检索来源,提升用户信任度
- 权限可控:可限制检索范围,适配企业数据安全规范
1.5 RAG完整工作流程
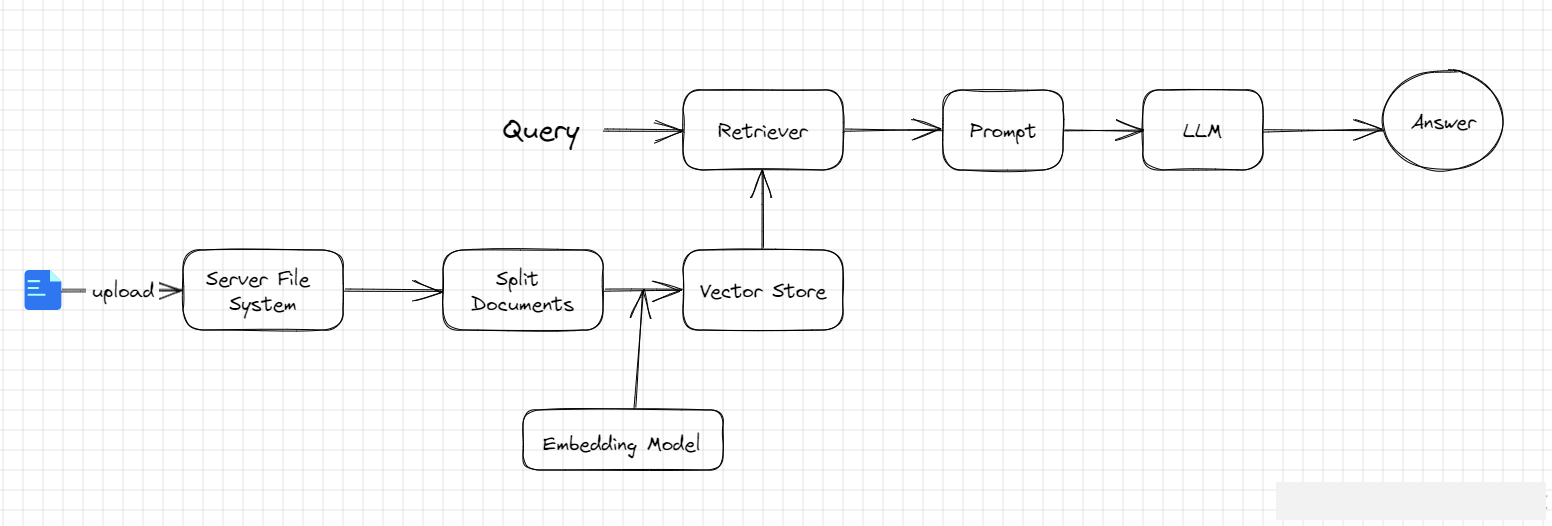
标准RAG流水线分为5个核心步骤,也是后续项目落地的核心逻辑:
- 数据准备:加载PDF/CSV/HTML/TXT等多格式外部文档
- 文本处理:清洗文本、分块分割,适配模型Token限制
- 向量化存储:通过Embedding模型将文本转为向量,存入向量数据库
- 语义检索:用户提问后,将问题向量化,匹配相似文本片段
- 增强生成:检索结果拼接提示词,交由大模型生成精准答案
1.6 语义搜索 vs 普通关键词搜索
传统关键词搜索仅匹配字面文字,无法理解语义,容易出现搜不到、搜不准的问题;
而RAG依赖的语义搜索,通过向量嵌入理解文本深层含义,可精准匹配用户意图,是RAG高精度问答的核心基础。
二、RAG核心组件一:多格式文档加载器(Document Loaders)
文档加载是RAG落地的第一步,LangChain内置了丰富的文档加载器,支持CSV、HTML、PDF等主流格式,可快速将各类文件解析为模型可识别的Document对象。
2.1 CSV文档加载器(表格数据专用)
CSVLoader专门用于解析表格数据,默认一行对应一个Document文档块,支持自定义分隔符、表头、字段合并,适配结构化数据问答场景。
基础加载代码
python
from langchain_community.document_loaders.csv_loader import CSVLoader
# 基础加载配置
loader = CSVLoader(file_path="resource/data.csv", encoding="utf-8")
docs = loader.load()
print(docs[0].page_content)高级自定义加载(适配特殊表格)
python
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(
file_path="resource/data.csv",
encoding="UTF-8",
csv_args={
"delimiter": ",", # 自定义分隔符
"quotechar": '"', # 字段包裹符号
"fieldnames": ["名称", "种类", "年龄", "栖息地"] # 自定义表头
}
)
docs = loader.load()2.2 HTML文档加载器(网页内容解析)
支持两种主流解析方式,自动剔除HTML标签、保留纯文本内容,适配网页知识库爬取解析场景。
方式1:UnstructuredHTMLLoader(通用解析)
python
pip install "unstructured[html]"
from langchain_community.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader(file_path="resource/page.html", encoding="utf-8")
doc = loader.load()方式2:BSHTMLLoader(BeautifulSoup精准解析)
python
pip install bs4
from langchain_community.document_loaders import BSHTMLLoader
# 自动提取页面标题到元数据,文本内容纯净度更高
loader = BSHTMLLoader(file_path="resource/page.html", open_encoding="UTF-8")
doc = loader.load()2.3 PDF文档加载器(最常用文档格式)
PyPDFLoader是PDF解析主流工具,支持纯文本PDF快速解析,同时兼容OCR模式,可识别图片型PDF中的文字。
基础文本PDF解析
python
pip install pypdf
from langchain_community.document_loaders.pdf import PyPDFLoader
loader = PyPDFLoader("resource/sample.pdf")
# 按页面分割文档,保留页码元数据
pages = loader.load_and_split()OCR模式:解析图片型PDF
python
pip install rapidocr-onnxruntime
from langchain_community.document_loaders.pdf import PyPDFLoader
# 开启图片提取OCR模式,自动识别图片文字
loader = PyPDFLoader("resource/sample.pdf", extract_images=True)
pages = loader.load()三、RAG核心组件二:文本分割器(Text Splitters)
原始文档普遍存在Token超长、语义冗余问题,受大模型上下文窗口限制(如4096 Token),必须对文本进行分块。合理的分块策略,直接决定检索精度和问答效果。
3.1 为什么必须做文本分割?
- 突破大模型上下文Token限制,避免输入溢出
- 缩小检索粒度,提升语义匹配精准度
- 减少冗余信息,加快向量检索响应速度
3.2 递归字符分割器(通用首选)
RecursiveCharacterTextSplitter 是工业级通用分割方案,优先按段落、句子、单词层级递归分割,最大限度保留文本语义完整性,支持重叠分块避免信息丢失。
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 初始化分割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # 单个文本块最大字符数
chunk_overlap=50, # 相邻块重叠字符数,防止语义断裂
length_function=len, # 字符统计方式
separators=["\n\n", "\n", "。", ",", " "] # 中文适配分割符
)
# 文本分块
chunks = splitter.split_text(text)核心参数解析 :chunk_overlap 是关键参数,通过块重叠解决段落分割导致的上下文丢失问题,中文场景建议设置为chunk_size的10%-20%。
3.3 语义分割器(高精度场景专用)
传统字符分割仅按长度切割,容易割裂完整语义。
SemanticChunker语义分割器 基于Embedding向量相似度,自动识别语义边界,语义相近的句子合并为一个块,分割精度更高。
python
pip install langchain-experimental
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
# 初始化嵌入模型
embeddings = OpenAIEmbeddings()
# 初始化语义分割器
semantic_splitter = SemanticChunker(
embeddings=embeddings,
breakpoint_threshold_type="percentile", # 阈值计算方式
breakpoint_threshold_amount=50 # 语义差异阈值
)
# 生成语义分块
chunks = semantic_splitter.create_documents([text])适用场景:论文、合同、专业文档等对语义完整性要求极高的场景;缺点是需要调用Embedding模型,速度略慢于递归分割。
四、RAG 核心组件三:嵌入模型与向量数据库
文本分割完成后,还不能直接用于语义检索 ------ 计算机无法直接理解文本的语义含义,需要通过嵌入模型(Embedding Model) 将非结构化文本转换为高维空间中的数值向量(即嵌入向量),再存入专门的向量数据库,这是实现语义匹配的核心前提,也是 RAG 链路中承上启下的关键环节。
4.1 嵌入模型:语义检索的底层基础
嵌入模型的核心特性是:语义越相近的文本,其对应的向量在高维空间中的距离越近。
比如 "年假有多少天" 和 "带薪休假天数",字面文字差异很大,但语义高度相似,嵌入模型会将二者映射到空间中距离很近的位置;而 "年假" 和 "年假结算流程" 语义有差异,向量距离也会相应更远。这也是语义搜索能超越传统关键词搜索的核心原因。
在完整 RAG 链路中,嵌入模型承担两个不可替代的作用:
- 知识库批量向量化:将所有分块后的文档文本统一转换为向量,存入向量数据库,完成私有知识库的构建
- 用户查询向量化:用户提问时,将问题同步转为同维度的向量,用于后续的相似度匹配检索
注意:知识库向量化与查询向量化,必须使用同一个嵌入模型,否则向量维度、语义空间不统一,相似度计算会完全失效。
4.2 主流嵌入模型选型
嵌入模型的质量直接决定检索精度,是影响 RAG 最终问答效果的核心变量。目前主流方案分为闭源商用 API 与开源私有化部署两类,可根据业务场景按需选择:
| 模型类型 | 代表模型 | 核心优势 | 适用场景 |
|---|---|---|---|
| 闭源商用 API | OpenAI text-embedding-3 系列、通义千问 Embedding、豆包 Embedding | 效果稳定、多语言适配好、接入成本极低 | 快速原型验证、公网 SaaS 服务、无数据合规要求的场景 |
| 开源中文模型 | BGE-v3、M3E 系列、GTE 系列 | 中文语义效果优异、支持全量私有化部署、无数据泄露风险 | 企业内网部署、涉密私有知识库、数据安全要求高的生产场景 |
选型落地建议:
- 原型开发、快速验证:优先选择大厂商用 Embedding API,无需部署、效果有保障,专注业务逻辑即可
- 企业生产、数据敏感:选择 BGE 等开源中文嵌入模型,本地化部署,全程数据不出域,适配中文业务场景
4.3 向量数据库:高性能语义检索的载体
普通关系型数据库无法高效处理高维向量的相似度计算,向量数据库是专门为向量存储、检索优化的数据库系统,支持毫秒级的相似度匹配,是 RAG 系统的核心存储组件。
它的核心能力包括:
- 向量索引构建:通过 IVF、HNSW 等专业索引算法,将高维向量做结构化索引,将检索复杂度从 O (n) 降至对数级
- 相似度计算:内置余弦相似度、欧氏距离、内积等多种计算方式,快速返回 Top-K 个最相似的文本块
- 元数据过滤:支持按文档来源、页码、业务标签等元数据筛选检索范围,进一步提升检索精准度
主流向量数据库对比
| 数据库 | 部署方式 | 核心特点 | 适用数据规模 |
|---|---|---|---|
| Chroma | 本地轻量文件存储 | 零配置、Python 原生支持、开箱即用 | 原型开发、万级以下小数据量 |
| FAISS | 本地算法库 | Meta 开源、纯内存检索、性能极强 | 十万 - 百万级中等数据量 |
| Milvus | 分布式服务部署 | 云原生架构、支持亿级向量、可横向扩展 | 企业级生产、百万 - 亿级大规模数据 |
本文实战项目选用 Chroma,正是因为其轻量、零配置的特性,非常适合快速搭建 RAG 原型,验证业务可行性。
4.4 语义检索的完整执行逻辑
语义检索是 RAG 知识增强的核心环节,完整执行流程分为三步,也是实战代码中检索器的底层逻辑:
- 查询向量化:将用户输入的自然语言问题,通过与知识库相同的嵌入模型,转换为统一维度的问题向量
- 相似度匹配:向量数据库接收问题向量,通过余弦相似度计算,从所有文档向量中检索出 Top-K 个最相似的文本块
- 上下文整理:将检索到的文本块按格式拼接整理,作为参考上下文填充进提示词模板,最终送入大模型生成基于文档的精准答案
五、端到端实战:带记忆的RAG问答机器人
基于以上核心组件,我们将完整搭建一个支持文档上传、语义检索、对话记忆、实时问答的RAG智能问答应用,基于Streamlit快速搭建可视化界面,开箱即用。
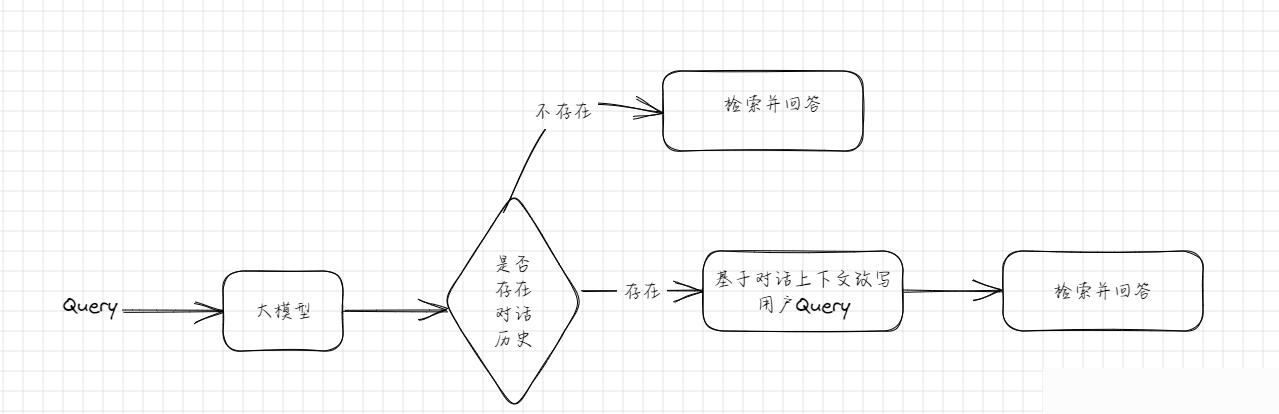
4.1 整体技术架构
- 文件上传:支持多TXT文档批量上传
- 文档处理:加载文档+递归文本分块
- 向量存储:Chroma轻量向量数据库存储向量
- 智能检索:语义相似度匹配相关文档片段
- 对话记忆:保存上下文对话,支持多轮问答
- Agent推理:基于检索结果智能生成答案
4.2 完整可运行代码
python
# pip install streamlit==1.37.0 langchain langchain-openai langchain-chroma
import streamlit as st
import tempfile
import os
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools.retriever import create_retriever_tool
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler
# 页面配置
st.set_page_config(page_title="RAG智能问答助手", layout="wide")
st.title("📚 基于RAG的私有文档问答机器人")
# 文档上传模块
uploaded_files = st.sidebar.file_uploader(
label="上传TXT私有文档",
type=["txt"],
accept_multiple_files=True
)
if not uploaded_files:
st.info("请先上传TXT格式文档,开启智能问答!")
st.stop()
# 缓存检索器,1小时有效期,避免重复加载文档
@st.cache_resource(ttl="1h")
def configure_retriever(upload_files):
docs = []
# 临时存储上传文件
temp_dir = tempfile.TemporaryDirectory()
for file in upload_files:
temp_path = os.path.join(temp_dir.name, file.name)
with open(temp_path, "wb") as f:
f.write(file.getvalue())
# 加载文档
loader = TextLoader(temp_path, encoding="utf-8")
docs.extend(loader.load())
# 文本分割
splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = splitter.split_documents(docs)
# 向量化并存入向量数据库
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(splits, embeddings)
# 创建检索器,默认返回top2相关片段
retriever = vectordb.as_retriever(search_kwargs={"k": 2})
return retriever
# 初始化检索器
retriever = configure_retriever(uploaded_files)
# 初始化对话记忆
chat_history = StreamlitChatMessageHistory()
memory = ConversationBufferMemory(
chat_memory=chat_history,
memory_key="chat_history",
return_messages=True,
output_key="output"
)
# 初始化会话消息
if "messages" not in st.session_state or st.sidebar.button("清空对话记录"):
st.session_state["messages"] = [{"role": "assistant", "content": "您好!我是RAG智能问答助手,已加载您的文档,可随时提问~"}]
# 渲染历史对话
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 创建检索工具
retrieve_tool = create_retriever_tool(
retriever,
"私有文档检索",
"专门用于检索上传的私有文档内容,基于检索结果回答用户问题,无相关信息则如实告知用户"
)
tools = [retrieve_tool]
# 自定义Agent提示词模板
agent_instructions = """
你是一个专业的私有文档问答助手,必须严格遵循以下规则:
1. 优先使用文档检索工具获取答案,不凭空作答
2. 检索无相关信息时,回复:抱歉,该问题暂无相关文档信息
3. 结合上下文对话历史,理解用户多轮提问
4. 回答简洁准确、通俗易懂,不冗余堆砌内容
"""
prompt_template = """
{instructions}
TOOLS: {tools}
Previous conversation history: {chat_history}
New user input: {input}
{agent_scratchpad}
"""
base_prompt = PromptTemplate.from_template(prompt_template)
prompt = base_prompt.partial(instructions=agent_instructions)
# 初始化大模型与Agent
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors=True
)
# 问答交互逻辑
user_input = st.chat_input("请输入你的问题...")
if user_input:
st.session_state.messages.append({"role": "user", "content": user_input})
st.chat_message("user").write(user_input)
# 模型推理与结果展示
with st.chat_message("assistant"):
callback = StreamlitCallbackHandler(st.container())
response = agent_executor.invoke(
{"input": user_input},
callbacks=[callback]
)
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
st.write(response["output"])六、常见问题答疑
-
Q:CSV文档分割规则是什么?
A:CSVLoader默认按行分割,每行解析为一个独立Document文档块,适配表格逐条数据检索。
-
Q:语义分割是否支持重叠设置?
A:语义分割默认无重叠,若需避免边缘语义丢失,可手动配置缓冲区参数,或搭配递归分割重叠逻辑使用。
-
Q:缓存过期后如何处理?
A:本项目设置1小时缓存有效期,缓存过期后会自动重新加载文档、分割文本、构建向量库,无需手动操作。
-
Q:检索到内容后为什么不调用工具?
A:若模型通过上下文对话历史已明确答案,且无需补充文档信息,会自动跳过工具调用,直接生成回答,提升响应速度。
-
Q:RAG的增强逻辑在哪一步生效?
A:检索完成后,将匹配的文档片段作为上下文,拼接用户问题组成增强提示词,输入大模型生成答案,实现知识增强。
总结
本文完整拆解了RAG从理论原理、核心组件到项目落地的全流程,覆盖多格式文档处理、两种主流文本分割策略、嵌入模型和向量数据库、带记忆的智能问答系统搭建。
给大家的落地选型建议:
- 通用场景:优先使用递归字符分割,速度快、稳定性高,适配绝大多数文档
- 高精度专业场景:使用语义分割,保障语义完整性,提升问答准确率
- 快速落地需求:直接复用本文Streamlit项目,无需复杂部署,开箱即用
- 企业生产场景:可扩展对接FAISS、Milvus等高性能向量数据库,增加权限管控、日志监控、批量更新文档功能
RAG作为大模型落地的核心技术,上手简单、落地成本低,是企业私有化部署、私有知识库问答的最优解,掌握这套完整流程,可快速应对绝大多数大模型应用开发场景。