Harness Engineering 深度解析:从"能说"到"能做"的工程跃迁
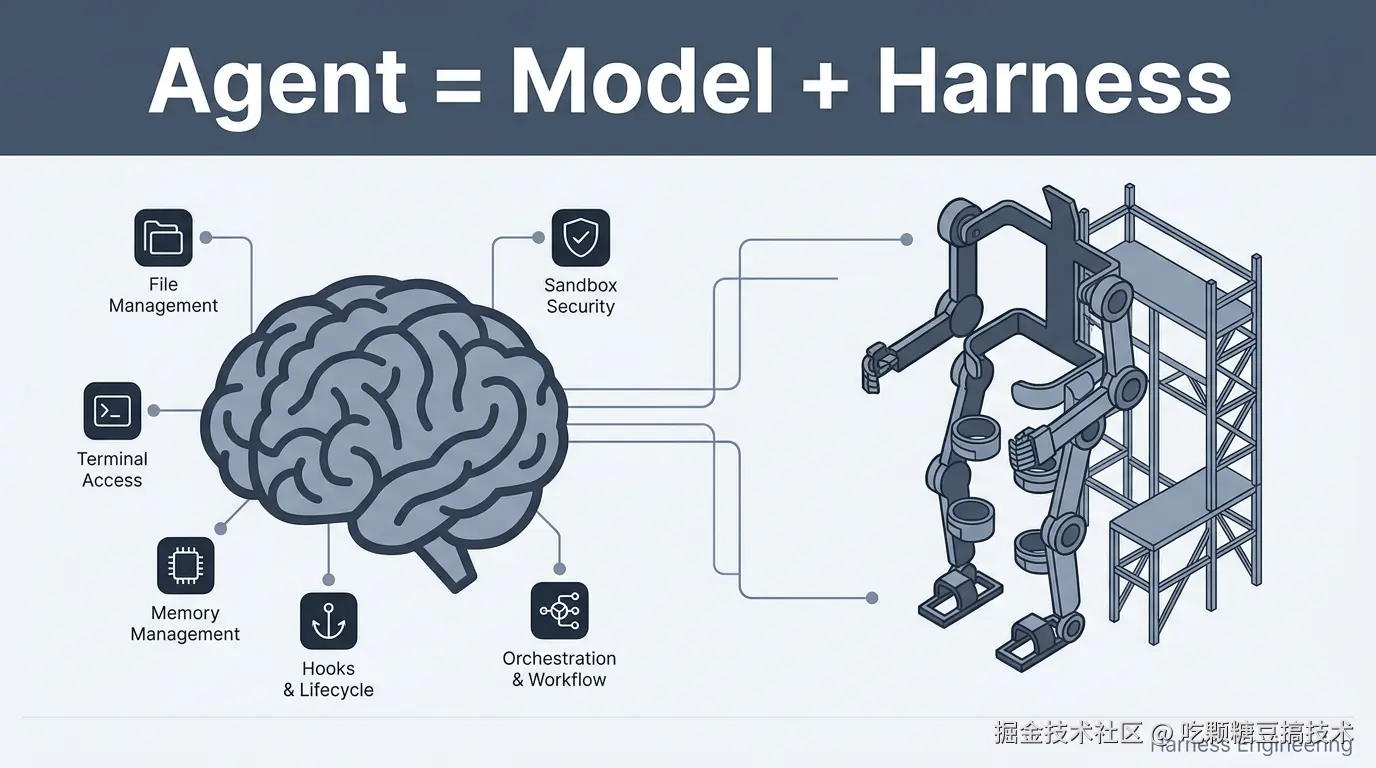
这是「AI 工程四次范式跃迁」系列的第三篇。前两篇我们讲了 Prompt Engineering(怎么写指令)和 Context Engineering(怎么管理上下文),这篇我们讲"光说不练假把式"的解法------Harness Engineering。
最近不少朋友在讨论"Claude Code 和 Cursor 到底差在哪",以及也被问到为什么同一个模型在不同工具里表现差很多,故而有了这篇文章。
直接说结论 :差的不是模型,是 Harness。Addy Osmani 和 Viv Trivedy 都给出了同一个公式:Agent = Model + Harness。同一个 Claude Opus 4.6,在 Claude Code 里和在一个精心设计的自定义 Harness 里,Terminal Bench 2.0 的排名可以从 Top 30 飙到 Top 5------只改 Harness,不改模型。这就是 Harness Engineering 的力量。
--微信公众号同步更新:吃颗糖豆搞技术;感兴趣可以关注--
目录
- [什么是 Harness:模型之外的一切](#什么是 Harness:模型之外的一切 "#1-%E4%BB%80%E4%B9%88%E6%98%AF-harness%E6%A8%A1%E5%9E%8B%E4%B9%8B%E5%A4%96%E7%9A%84%E4%B8%80%E5%88%87")
- [核心公式:Agent = Model + Harness](#核心公式:Agent = Model + Harness "#2-%E6%A0%B8%E5%BF%83%E5%85%AC%E5%BC%8Fagent--model--harness")
- [Harness 的六大核心组件](#Harness 的六大核心组件 "#3-harness-%E7%9A%84%E5%85%AD%E5%A4%A7%E6%A0%B8%E5%BF%83%E7%BB%84%E4%BB%B6")
- 棘轮原则:每次失败变成一条规则
- [Hook 机制:从"说了要做"到"系统强制做"](#Hook 机制:从"说了要做"到"系统强制做" "#5-hook-%E6%9C%BA%E5%88%B6%E4%BB%8E%E8%AF%B4%E4%BA%86%E8%A6%81%E5%81%9A%E5%88%B0%E7%B3%BB%E7%BB%9F%E5%BC%BA%E5%88%B6%E5%81%9A")
- [长周期执行:Ralph Loop 与规划验证](#长周期执行:Ralph Loop 与规划验证 "#6-%E9%95%BF%E5%91%A8%E6%9C%9F%E6%89%A7%E8%A1%8Cralph-loop-%E4%B8%8E%E8%A7%84%E5%88%92%E9%AA%8C%E8%AF%81")
- [模型与 Harness 的共训练循环](#模型与 Harness 的共训练循环 "#7-%E6%A8%A1%E5%9E%8B%E4%B8%8E-harness-%E7%9A%84%E5%85%B1%E8%AE%AD%E7%BB%83%E5%BE%AA%E7%8E%AF")
- [Harness 不缩小,它移动](#Harness 不缩小,它移动 "#8-harness-%E4%B8%8D%E7%BC%A9%E5%B0%8F%E5%AE%83%E7%A7%BB%E5%8A%A8")
- [AI 编程中的 Harness 规范约束](#AI 编程中的 Harness 规范约束 "#9-ai-%E7%BC%96%E7%A8%8B%E4%B8%AD%E7%9A%84-harness-%E8%A7%84%E8%8C%83%E7%BA%A6%E6%9D%9F")
- 写在最后
1. 什么是 Harness:模型之外的一切
定义
Harness 是包裹在 AI 模型外面的所有代码、配置和执行逻辑------包括系统 Prompt、工具、文件系统、沙箱、编排逻辑、Hook、可观测性。模型本身只负责"生成文本",Harness 负责让这些文本变成"真实的行动"。
Viv Trivedy(LangChain)的原始定义最精炼:
"Agent = Model + Harness。如果你不是模型,你就是 Harness。"
为什么需要 Harness
一个裸模型(raw model)不是 Agent。它只能接收文本、输出文本。它不能:
- 维护持久状态------对话结束就忘了
- 执行代码------它只能"说"要执行什么,不能真的执行
- 访问实时知识------它的知识止步于训练数据
- 搭建环境------它不能自己安装依赖、配置运行时
这些都是 Harness 的职责。Harness 给模型"手"和"脚",让它的"想法"能变成"行动"。
生活类比
模型是一个极其聪明但对你的公司一无所知的顾问。他坐在那里,你说什么他都能分析得头头是道。但他没有办公室、没有电脑、没有权限、没有同事、没有记事本。
Harness 就是给这个顾问配的"全套装备"------办公室(沙箱)、电脑(代码执行)、权限(工具访问)、同事(子 Agent 协作)、记事本(记忆系统)、行为规范(AGENTS.md)、审批流程(Hook)。
没有 Harness,顾问只能"纸上谈兵"。有了 Harness,他能真正"干活"。
Claude Code、Cursor、Codex 都是 Harness
这是理解 Harness Engineering 的关键切入点:你平时用的 AI 编码工具,本质上都是不同设计的 Harness。它们底层的模型可能是同一个(比如都用 Claude),但你体验到的差异------代码质量、响应速度、错误恢复------主要来自 Harness 设计的差异。
Addy Osmani 的原话:"Claude Code、Cursor、Codex、Aider、Cline------这些都是 Harness。底层的模型有时是同一个,但你体验到的行为主要由 Harness 决定。"
2. 核心公式:Agent = Model + Harness
公式的含义
这个公式不是"模型 + 一些辅助工具 = Agent"。它表达的是:模型只是 Agent 的一个输入,Harness 是让模型变成可用 Agent 的全部工程。
过去两年,行业一直在争论"哪个模型最强"。Addy Osmani 指出这个争论只覆盖了公式左边。真正的杠杆在右边------Harness。
数据证明
Viv Trivedy 的团队做过一个实验:同一个 Claude Opus 4.6 模型,只改 Harness,Terminal Bench 2.0 排名从 Top 30 提升到 Top 5。
HumanLayer 也报告了类似的数据:Claude Opus 4.6 在 Claude Code(官方 Harness)里的得分,远低于同一个模型在自定义 Harness 里的得分。
为什么?因为模型在训练时就和特定 Harness 耦合了。Claude 在训练时用的是 Claude Code 的 Harness 逻辑。当你换一个 Harness------更好的工具、更紧的 Prompt、更锐利的反馈压力------你能释放出原 Harness 留在桌面上的能力。
"这不是模型问题,是配置问题"
HumanLayer 提出了一个关键观点:大多数 Agent 失败不是"模型不够聪明",而是"Harness 配置不对"。
- Agent 不知道某个约定?→ 加到 AGENTS.md
- Agent 执行了危险命令?→ 加一个 Hook 拦截
- Agent 在 40 步任务中迷失了?→ 拆成"规划者 + 执行者"
- Agent 总是交付有 bug 的代码?→ 接一个 typecheck 反馈信号
每个"模型变蠢了"的故事,背后都有一个"Harness 没配好"的根因。
3. Harness 的六大核心组件
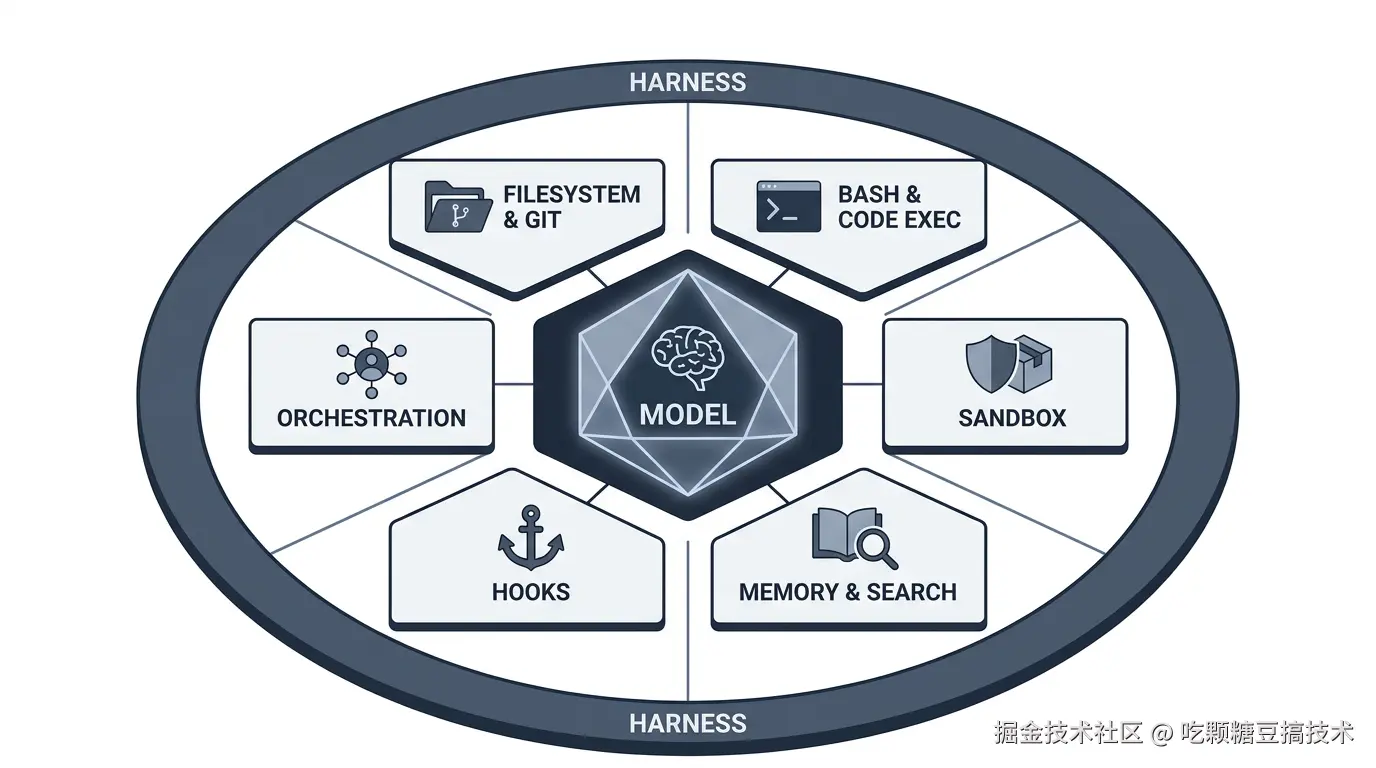
Viv Trivedy 和 Addy Osmani 的文章中,Harness 被拆解为六大核心组件。我们从"行为倒推组件"的角度逐个讲。
组件一:Filesystem & Git(文件系统与版本控制)
它解决的问题:模型只能直接操作上下文窗口内的信息。没有文件系统,你就是在聊天框里复制粘贴------那不是工作流。
核心价值:
- 给 Agent 一个工作区------读数据、代码、文档
- 可以卸载中间结果------不用全塞在上下文里
- 多 Agent 和人类可以通过共享文件协作
加上 Git:版本控制让 Agent 可以追踪进度、回滚错误、分支实验。Git 是 Agent 的"安全网"------做错了可以回退。
为什么被低估:文件系统太"基础"了,所以容易被忽视。但 Addy Osmani 强调:"文件系统是最基础的原语,大多数其他 Harness 组件最终都会指向文件系统。"
组件二:Bash & Code Execution(命令行与代码执行)
它解决的问题:Agent 需要能"动手做",而不只是"说要做"。
核心洞察:与其为每个可能的操作预建一个专用工具,不如给 Agent 一个"通用工具"------bash。模型可以自己写代码、执行、看结果、改代码------这是自主解决问题的能力。
Simon Willison 的观点:"Agent 已经很擅长 shell 命令了。大多数任务可以归结为几个精心选择的 CLI 调用。"
类比:专用工具像"只给员工一个搅拌机"------他只能打果汁。Bash 像"给员工整个厨房"------他什么都能做。
组件三:Sandbox(沙箱)
它解决的问题:Agent 生成的代码需要在某处运行,而且要安全。
核心价值:
- 隔离的执行环境------不影响你的机器
- 命令白名单------限制危险操作
- 网络隔离------防止数据泄露
- 按需创建和销毁------支持并行 Agent
好的沙箱自带好工具:预装的语言运行时、Git 和测试 CLI、无头浏览器。浏览器和测试运行器让 Agent 能"看到自己的工作结果"------这是自验证循环的基础。
组件四:Memory & Search(记忆与搜索)
它解决的问题:模型没有训练数据之外的知识,也没有跨会话的记忆。
文件型记忆:AGENTS.md / CLAUDE.md 每次启动时注入上下文。Agent 可以编辑这个文件,知识从一个会话延续到下一个。这是"持续学习"的粗粒度实现。
搜索型知识:Web Search 和 Context7 等 MCP 工具让 Agent 访问训练截止后的新知识------新库版本、最新文档、今天的实时数据。
组件五:Hooks(钩子机制)
它解决的问题:"我告诉 Agent 不要做 X"和"系统强制 Agent 不做 X"之间的鸿沟。
核心机制:Hook 是在特定生命周期点运行的脚本------工具调用前、文件编辑后、提交前、会话启动时。
典型 Hook:
- 每次编辑后运行 typecheck 和 lint------失败信息注入循环
- 拦截危险 bash------
rm -rf、git push --force、DROP TABLE - 推送前要求人工审批
- 写入时自动格式化------省得模型浪费 token 在空格上
关键原则:"成功时沉默,失败时详尽"。typecheck 通过了,Agent 听不到任何声音。失败了,错误信息注入循环让 Agent 自动修正。这让反馈循环在日常情况下几乎免费,出问题时直接可执行。
组件六:Orchestration(编排逻辑)
它解决的问题:复杂任务需要多个 Agent 分工协作。
子 Agent:为独立子任务生成子 Agent,每个有隔离的上下文。这是"上下文防火墙"------搜索 Agent 的巨大上下文不会污染修改 Agent 的上下文。
模型路由:不同任务用不同模型------简单任务用快速便宜的模型,复杂任务用强力模型。
交接机制:Agent 之间通过文件或结构化消息传递工作。
4. 棘轮原则:每次失败变成一条规则
核心理念
Harness Engineering 最重要的习惯是:把 Agent 的每次错误当成永久信号。不是一笑而过的"翻车故事",不是"运气不好重试一下"。而是信号------要转化为一条规则。
棘轮的工作方式
Addy Osmani 给了一个具体例子:
"如果 Agent 提交了一个注释掉的测试,而我不小心合并了------这是一个输入。下一版 AGENTS.md 写'永远不要注释掉测试,要么删掉要么修好'。下一版 pre-commit Hook 会 grep
.skip(和xit(。下一版 reviewer 子 Agent 会把注释掉的测试标记为阻塞项。"
每一条规则都来自一次具体失败。这就是"棘轮"------只进不退,每一步都让系统更健壮。
两个纪律
只在实际失败后加规则:不要"预想"可能的问题然后加规则。规则太多会导致"注意力稀释"。HumanLayer 建议保持 AGENTS.md 不超过 60 行------飞行检查清单,不是风格指南。
只在模型能力提升后删规则:当模型已经能内化某条规则时,这条规则就是"承载了无用之物的负载",应该删掉。Opus 4.6 基本消除了"上下文焦虑"的失败模式------之前为缓解焦虑写的脚手架现在成了死代码。
为什么 Harness 是"学科"而非"框架"
Addy Osmani 的总结:"你的代码库的合适 Harness 是由你的失败历史塑造的。你没法下载它。"
框架可以开箱即用,但 Harness 必须在实践中一点点积累。这也是为什么 Harness Engineering 是一个持续工程,而不是一次性配置。
5. Hook 机制:从"说了要做"到"系统强制做"
Hook 的本质
Hook 是 Harness Engineering 中"执行层"和"说教层"的分界线。
没有 Hook 的系统:你在 AGENTS.md 里写"不要推 force 到 main"------Agent 可能遵守,也可能"忘了"。
有 Hook 的系统:你在 pre-push Hook 里写一段脚本检查分支------不管 Agent"记不记得",它都推不了。系统强制。
Hook 的生命周期点
| 时机 | Hook 用途 | 例子 |
|---|---|---|
| 会话启动 | 注入记忆、加载配置 | 读取 AGENTS.md 注入上下文 |
| 工具调用前 | 权限检查、参数校验 | 拦截 rm -rf 命令 |
| 文件编辑后 | 自动格式化、lint 检查 | 编辑后自动 prettier |
| 提交前 | 运行测试、检查敏感信息 | 提交前跑 typecheck |
| 推送前 | 人工审批、分支保护 | 推到 main 需要确认 |
"成功沉默,失败详尽"原则
这是 HumanLayer 强调的核心设计原则。
为什么:如果 Hook 每次都输出"通过了"------Agent 的上下文会被噪声填满。如果 Hook 只在失败时输出------日常运行几乎零成本,失败时直接给可执行的错误信息。
实现:Hook 成功时返回空,失败时返回错误文本。Harness 把错误文本注入 Agent 循环,Agent 看到"测试失败:expected true, got false at line 42"就会自动去修。
Hook 的实战例子
一个典型的生产级 Agent Harness 会部署以下 Hook 组合:
pre-tool-call Hook :在每次工具调用前检查。比如检测到 rm -rf 或 git push --force 时拦截并要求人工确认。
post-file-edit Hook:每次文件编辑后自动运行 prettier/eslint。这样 Agent 不需要浪费 token 去处理格式问题。
pre-commit Hook:提交前运行 typecheck 和单元测试。失败信息注入循环让 Agent 自动修。
on-session-start Hook:加载 AGENTS.md 和记忆文件。这是记忆系统的入口。
on-exit-intercept Hook:这就是 Ralph Loop 的核心------拦截 Agent 的退出尝试,判断是否真的完成了任务。
6. 长周期执行:Ralph Loop 与规划验证
长周期执行的三大难题
今天的模型在长周期自主执行上面临三个问题:
- 早期停止------做了一半就说"完成了"
- 分解困难------不会把复杂问题拆成有序步骤
- 跨窗口不连贯------跨多个上下文窗口后变得"前后不一致"
Ralph Loop:拦截退出
Ralph Loop 是一个简单但强大的 Harness 模式:用 Hook 拦截模型的"退出尝试",把原始 Prompt 重新注入一个干净的上下文窗口,强制 Agent 继续工作。
每次迭代从干净的上下文开始,但通过文件系统读取上一次的状态。这让单次会话的 Agent 变成"多会话"的------而且不需要更聪明的模型。
规划与自验证
规划:模型把目标分解成一系列步骤,写入磁盘上的 plan 文件。Harness 在每步后提醒 Agent 检查 plan 文件。
自验证:Hook 运行预定义的测试套件,失败时把错误信息循环回模型。或者模型被提示自我评估输出是否符合明确标准。
规划者 / 生成者 / 评估者分离
Anthropic 的长周期 Harness 工作明确指出:把生成和评估分离到不同的 Agent,效果优于自我评估------因为 Agent 评估自己的工作时会系统性地偏正面。
这就像"散文的 GAN"------一个 Agent 生成,一个 Agent 批判,互相博弈提升质量。
Sprint Contract:生成者和评估者在写代码前先协商"什么算完成"。Addy Osmani 的经验:"在开始前写下完成条件,比任何 Prompt 调整都能抓到更多的范围漂移。"
7. 模型与 Harness 的共训练循环
共训练现象
今天的 Agent 产品(如 Claude Code、Codex)在训练时就和 Harness 耦合。模型在训练中会专门提升"Harness 设计者认为它应该擅长的动作"------文件操作、bash、规划、子 Agent 调度。
这就是为什么 Opus 4.6 在 Claude Code 里和在别的 Harness 里"感觉不同"------它被训练成"在 Claude Code 的 Harness 逻辑里"运行得最好。
副作用:过度耦合
这种共训练有副作用------模型对特定工具逻辑过度拟合。Codex-5.3 的 Prompting Guide 提到:apply_patch 工具的逻辑变了,模型性能就下降。一个真正通用的模型应该不在意用哪种 patch 方法,但共训练导致了这种"过度敏感"。
对你的启示
最佳 Harness 不一定是模型训练时用的那个。Viv 团队的 Top 30 → Top 5 跃迁就是证据。一个为你具体任务和代码库设计的 Harness,可能释放出官方 Harness 留在桌面上的能力。
Harness 是"活的系统",不是一次配好的配置文件。它需要随着你的项目演进、随着模型升级而持续调整。
实践建议
如果你刚开始构建自己的 Harness,Addy Osmani 和 Viv Trivedy 都推荐从简入手:
第一步:从一个简单的 AGENTS.md 开始------写上你的项目技术栈、编码规范、禁止事项。控制在 30 行以内。
第二步:加一个 pre-commit Hook------运行 typecheck 和 lint。这是回报率最高的单一改进。
第三步:遇到 Agent 犯错时,不要只修当前问题。问自己:"这个错误以后还会发生吗?如果会,我该加什么规则或 Hook 来永久防止它?"
第四步:当任务变复杂时,考虑拆子 Agent。每个子 Agent 有隔离的上下文和明确的职责。
Viv 的建议:"好的 Agent 构建是一种迭代练习。如果你没有 v0.1,你没法迭代。" 不要追求一步到位的完美 Harness------先跑起来,然后根据失败持续改进。
8. Harness 不缩小,它移动
朴素故事的陷阱
朴素直觉是:"模型越强,Harness 越不重要。模型能规划了就不需要规划器。模型长上下文连贯了就不需要上下文重置。"
Addy Osmani 指出这个故事只对了一半。是的,Opus 4.6 基本杀死了"上下文焦虑"的失败模式------半年前为缓解焦虑写的脚手架现在是死代码。
天花板随模型移动
但天花板也随模型移动了。之前够不到的任务现在够得着了,而它们有自己的失败模式:
- 焦虑缓解的脚手架消失了 → 需要多日记忆策略
- 单 Agent 够强了 → 需要协调三个专业 Agent 的 Harness
- 模型能生成 UI 了 → 需要设计质量评估器
Anthropic 的总结:"Harness 中的每个组件都编码了一个关于'模型自己做不到什么'的假设。当模型在某方面变强时,那个组件就成了承载无用之物的负载,应该移除。当模型解锁新能力时,需要新脚手架来触及新天花板。"
类比
这就像盖楼。地基技术进步了,你能盖更高。但更高的楼有新的工程挑战------风载荷、电梯系统、消防安全。脚手架没有消失,它的"形状"变了。
Harness Engineering 不会随模型进步而消失------它的重心会从"补足模型缺陷"转移到"释放模型潜力"。
9. AI 编程中的 Harness 规范约束
前面讲的是"通用 Agent Harness"的概念。但在日常 AI 编程中,Harness Engineering 已经落地为一套具体的配置文件和工具链------AGENTS.md、Hooks、Skills、MCP 配置等。Martin Fowler 网站的 Birgitta Böckeler 在 2026 年 4 月发表了一篇非常系统的文章,把编码 Agent 的 Harness 分为两大类:
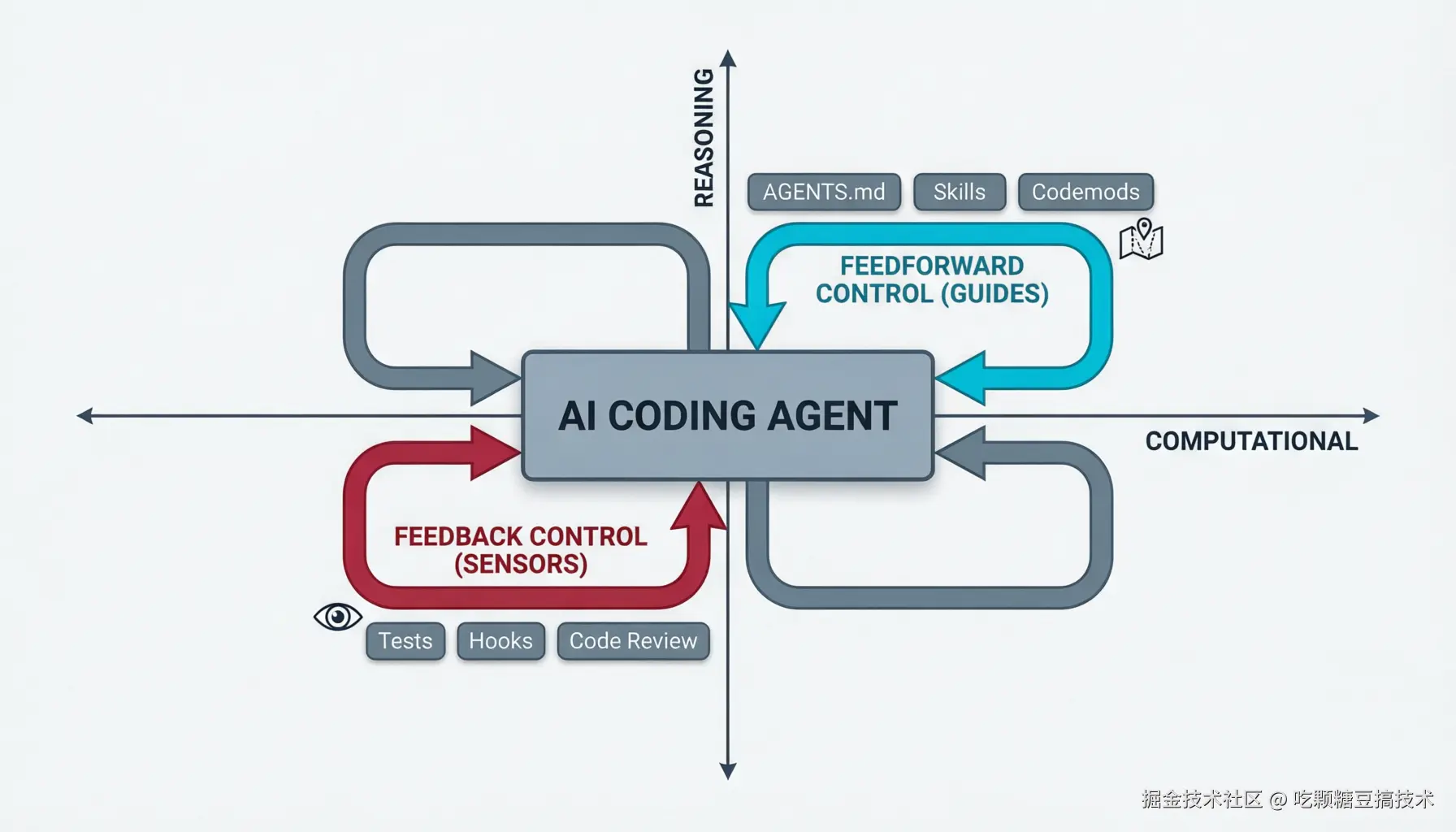
前馈控制(Guides)vs 反馈控制(Sensors)
Birgitta 的核心框架:前馈控制预判 Agent 行为、提前引导;反馈控制观察 Agent 行为、事后纠正。
| 类型 | 方向 | 机制 | 例子 |
|---|---|---|---|
| 编码规范 | 前馈 | 推理性 | AGENTS.md、Skills 文件 |
| 项目引导 | 前馈 | 计算+推理 | Skill 包含指令 + 引导脚本 |
| 代码修改工具 | 前馈 | 计算性 | OpenRewrite codemod |
| 结构测试 | 反馈 | 计算性 | ArchUnit 检查模块边界 |
| Review 指令 | 反馈 | 推理性 | 代码审查 Skill |
关键洞察:只有前馈,Agent 编码了规则但不知道是否生效。只有反馈,Agent 不断重复同样错误。两者必须结合。
AI 编程 Harness 配置生态(2026 年 6 月)
Cody Lindley 整理的《AI Harness Engineering Compatibility Matrix》展示了当前各工具的支持情况:
| 配置文件 | 作用 | Copilot | Claude Code | Codex | Cursor | Gemini |
|---|---|---|---|---|---|---|
| AGENTS.md | 仓库级指令 | ✅ | --- | ✅ | ✅ | opt-in |
| CLAUDE.md | Claude 原生指令 | fallback | ✅ | --- | --- | --- |
| .claude/rules/*.md | 路径级指令 | fallback | ✅ | --- | --- | --- |
| .cursor/rules/*.mdc | Cursor 原生规则 | --- | --- | --- | ✅ | --- |
| .agents/skills/ | 跨工具 Skills | ✅ | --- | ✅ | ✅ | ✅ |
| hooks 配置 | 生命周期钩子 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MCP 配置 | 工具服务器 | ✅ | ✅ | ✅ | ✅ | ✅ |
AGENTS.md 是目前最通用的指令文件 ------Copilot、Codex、OpenCode、Cursor、Devin、Amp 都原生读取。Claude Code 仍然使用 CLAUDE.md,但可以通过 @AGENTS.md 导入。
两个 Harness 视角的共通与区别
Addy Osmani 的"通用 Agent Harness"和 Birgitta 的"编码 Agent Harness"有什么异同?
共通点:
-
核心公式相同:Agent = Model + Harness。不管你做的是通用 Agent 还是编码 Agent,Harness 都是模型之外的全部工程。
-
棘轮原则一致:Birgitta 说"每次问题重复出现,就应该改进前馈和反馈控制"------这和 Addy Osmani 的"每次失败变成一条规则"完全一致。
-
成功沉默、失败详尽:两者都强调反馈信号应该只在失败时输出,通过时保持静默。
-
人的角色:Birgitta 说"Harness 不应完全消除人的输入,而是把人的输入引导到最重要的位置"------和 Loop Engineering 篇的"人从执行者变成设计师"异曲同工。
区别点:
| 维度 | Addy Osmani(通用 Agent) | Birgitta(编码 Agent) |
|---|---|---|
| 关注焦点 | Agent 的"做事能力" | 人对 Agent 产出的"信任度" |
| 核心问题 | 怎么让 Agent 完成复杂任务 | 怎么让你放心地用 Agent 写代码 |
| 框架 | 六大组件(文件系统、bash、沙箱...) | 二维分类(前馈/反馈 × 计算/推理) |
| 实践建议 | 从 AGENTS.md 开始,每次失败加规则 | 设计 Guide + Sensor 的组合系统 |
| 成熟度 | 偏概念和架构设计 | 偏工程落地和质量保障 |
Birgitta 的独到贡献是把 Harness 从"让 Agent 能做事"提升到了"让人对 Agent 产出有信心"。她引入了控制论的视角------前馈和反馈、计算性和推理性------这让你可以像设计测试策略一样设计 Harness。
Addy Osmani 的独到贡献是"棘轮原则"和"从行为倒推组件"的设计方法。他告诉你 Harness 不是配置文件,而是一个持续积累的"失败→规则"循环。
给你的行动建议
如果你在用 AI 编码工具,可以按 Birgitta 的框架设计你的 Harness:
第一步:前馈引导------写一份 AGENTS.md(或 CLAUDE.md),包含技术栈、编码规范、禁止事项。控制在 30-60 行。
第二步:反馈传感器------配一个 pre-commit Hook 跑 typecheck + lint。这是回报率最高的单一改进。
第三步:渐进积累------每次 Agent 犯错,问自己:"这属于哪个控制分类?我应该加前馈(改 AGENTS.md)还是加反馈(加 Hook/测试)?"
第四步:信任升级------当 Agent 在一个模块上连续 10 次不出错时,减少人工 review 频率。信任是通过 Harness 挣来的,不是默认给的。
10. 写在最后
Harness Engineering 的核心洞察是:Agent 的能力不只取决于模型参数,也取决于包裹模型的工程系统。
这个洞察在 2026 年正在改变行业对 AI Agent 的认知。过去两年,所有人都在争论"哪个模型最强"。Harness Engineering 的视角告诉你:模型只是方程的一半,真正的杠杆在 Harness。
四篇文章的全景
现在我们可以把整个系列串起来了:
| 范式 | 核心问题 | 核心技术 | 时代 |
|---|---|---|---|
| Prompt Engineering | 怎么写指令 | Zero/Few-Shot、CoT、ReAct | 2022-2024 |
| Context Engineering | 怎么管理上下文 | RAG、MCP、Memory、Compaction | 2025 |
| Harness Engineering | 怎么让模型能做 | 沙箱、Hook、工具、编排 | 2025-2026 |
| Loop Engineering | 怎么持续运行改进 | Agent Loop、Verification Loop、Event Loop、Hill Climbing | 2026 |
每一次跃迁都不是推翻前一次------而是把它吸收进更大的框架。Prompt 变成了 Context 的一层,Context 变成了 Harness 的一部分,Harness 的"循环执行逻辑"变成了 Loop Engineering 的研究对象。
这不是四个独立的技术,而是 AI 工程的一体四面------从"说"到"看"到"做"到"持续做好"的完整路径。
理解了这四次跃迁,你就理解了 2026 年 AI Agent 工程的全貌。下一次有人问你"怎么做一个好的 AI Agent",你的回答不会是"换个更强的模型",而是"设计一个好的 Harness"。
参考资料:
- Addy Osmani: Agent Harness Engineering (2026) --- addyosmani.com/blog/agent-...
- Birgitta Böckeler / Martin Fowler: Harness engineering for coding agent users (2026.04) --- martinfowler.com/articles/ha...
- Viv Trivedy (LangChain): The Anatomy of an Agent Harness (2026) --- www.langchain.com/blog/the-an...
- Cody Lindley: AI Harness Engineering Compatibility Matrix (2026.06) --- codylindley.github.io/ai-harness-...
- HumanLayer: "It's not a model problem, it's a configuration problem"
- Anthropic Engineering: How we built our multi-agent research system
- Simon Willison: "An agent is a system that runs tools in a loop to achieve a goal"