
crictl info 报错,先别急着重启 kubelet
这类问题通常发生在三个场景:
-
新装 Kubernetes 节点后,执行
sudo crictl info直接报错。 -
Docker 迁移到 containerd 后,原来能查容器的节点突然查不到运行时信息。
-
kubelet 日志里出现 CRI 连接异常,手动用
crictl验证也连不上。
最常见的报错长这样:
bash
FATA[0000] connect: no such file or directory或者:
bash
FATA[0000] connect: connection refused还有一种更容易误判:
bash
FATA[0000] permission denied这三类报错看起来都像"containerd 坏了",但原因可能完全不同。生产环境里不要一上来就重启 kubelet、重装 containerd,先把路径走完:配置 -> socket -> 服务 -> 日志 -> kubelet 端点。
如果你还不熟悉 kubectl、crictl、ctr 的边界,建议先阅读当天 A 篇:\[2026-07-02 A crictl 实战指南:没有 docker 命令后,Kubernetes 节点该怎么排障?]。本文只聚焦一个单点问题:crictl info 连不上 containerd 时怎么定位。
先划边界:crictl 连的是 CRI endpoint,不是随便一个 containerd 路径
crictl 不是直接替代 docker 的通用客户端,它面向的是 CRI endpoint。对 containerd 节点来说,常见 endpoint 是:
bash
unix:///run/containerd/containerd.sock这个 endpoint 要同时满足三个条件:
-
/etc/crictl.yaml里写的是这个 endpoint。 -
/run/containerd/containerd.sock这个 socket 文件真实存在。 -
containerd 正在运行,并且 CRI 插件能提供服务。
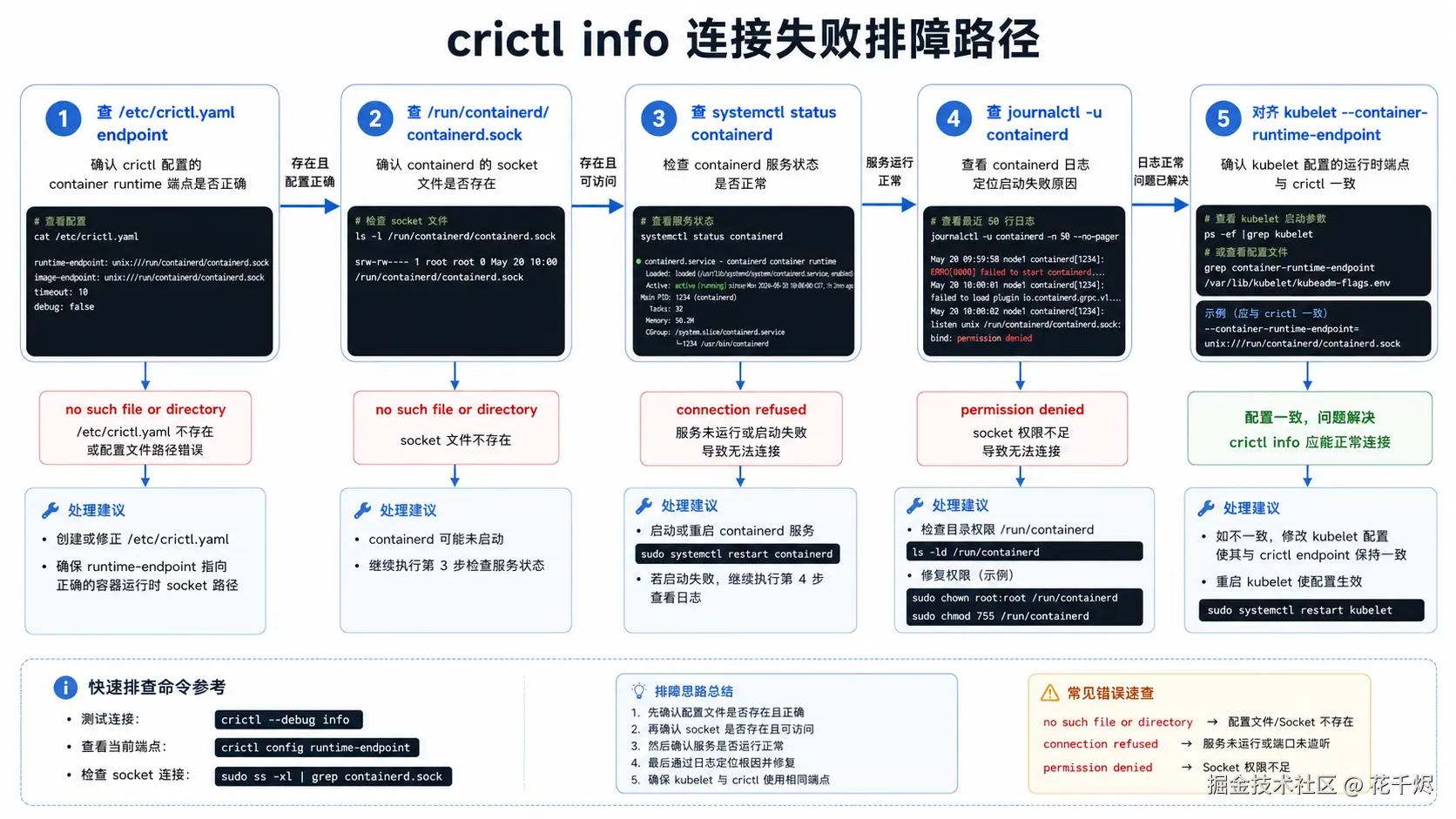
一张表先定位报错方向
| 报错或现象 | 常见原因 | 先跑的命令 | 判断标准 | 处理方向 | |
|---|---|---|---|---|---|
no such file or directory |
endpoint 路径写错,或 socket 不存在 | sudo cat /etc/crictl.yaml |
runtime-endpoint 是否指向真实 socket |
修正 /etc/crictl.yaml,再查 socket |
|
no such file or directory |
containerd 没有创建 socket | sudo ls -l /run/containerd/containerd.sock |
文件是否存在,类型是否为 socket | 检查 containerd 服务和日志 | |
connection refused |
socket 存在但服务未正常监听 | sudo systemctl status containerd --no-pager |
是否 active (running) |
重启前先看日志,避免掩盖启动失败原因 | |
context deadline exceeded |
服务卡住、CRI 插件异常、节点负载过高 | sudo journalctl -u containerd -n 200 --no-pager |
是否有插件、磁盘、权限、镜像存储错误 | 按日志关键字继续定位 | |
permission denied |
当前用户无权访问 socket 或目录 | sudo ls -ld /run/containerd /run/containerd/containerd.sock |
用户、组、权限是否允许访问 | 用 sudo 验证;生产上谨慎调整权限 |
|
crictl 能连,kubelet 仍报 CRI 错误 |
kubelet runtime endpoint 和 crictl 不一致 | `ps -ef | grep 'kubelet'` | --container-runtime-endpoint 是否一致 |
修正 kubelet 配置后灰度重启 |
第一步:检查 /etc/crictl.yaml
先看 crictl 到底准备连哪里:
bash
sudo cat /etc/crictl.yaml用途:确认 runtime-endpoint 和 image-endpoint。 判断标准:containerd 节点通常应看到下面这种配置:
bash
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false如果文件不存在,或者 endpoint 还是旧路径,例如 Docker shim 时代的路径,就先补齐:
bash
sudo tee /etc/crictl.yaml >/dev/null <<'EOF'
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF用途:把 crictl 固定到 containerd 的 CRI socket。 判断标准:再次执行 sudo cat /etc/crictl.yaml,确认两个 endpoint 都是 unix:///run/containerd/containerd.sock。
生产提醒:如果这是别人维护的节点,修改前先备份:
bash
sudo cp -a /etc/crictl.yaml /etc/crictl.yaml.$(date +%F-%H%M%S).bak 2>/dev/null || true用途:保留原配置,便于回滚。 判断标准:如果原文件存在,应生成一个带时间戳的备份文件。
第二步:确认 socket 文件是否存在
endpoint 写对了,不代表 socket 一定存在。继续查文件:
bash
sudo ls -l /run/containerd/containerd.sock用途:确认 containerd socket 是否真实存在。 判断标准:正常情况下应看到类似:
bash
srw-rw---- 1 root root 0 Jul 2 15:00 /run/containerd/containerd.sock关注三点:
-
第一位是
s,说明它是 socket。 -
路径和
/etc/crictl.yaml完全一致。 -
用
sudo能访问。
如果返回:
bash
No such file or directory不要直接改权限,先判断 containerd 是否运行。
还可以确认 containerd 是否真的监听这个 socket:
bash
sudo ss -xl | grep containerd.sock用途:检查本机 Unix socket 监听状态。 判断标准:能看到 /run/containerd/containerd.sock,说明 socket 被进程监听;如果文件存在但没有监听,继续查服务状态和日志。
第三步:检查 containerd 服务状态
查看服务:
bash
sudo systemctl status containerd --no-pager用途:确认 containerd 是否处于运行状态。 判断标准:Active: active (running) 是基本前提;如果是 failed、inactive、activating,继续看日志,不要只看状态行。
如果服务未运行,先不要立刻在生产节点上反复重启。先看最近日志:
bash
sudo journalctl -u containerd -n 200 --no-pager用途:查看 containerd 最近 200 行日志。 判断标准:重点搜索这些关键词:
| 关键词 | 可能方向 | 下一步 |
|---|---|---|
failed to load plugin |
插件加载失败,可能是配置或依赖问题 | 查 /etc/containerd/config.toml |
permission denied |
目录、socket、镜像存储权限异常 | 查目录属主和 SELinux/AppArmor |
address already in use |
socket 或端口被占用 | 查监听进程 |
invalid plugin config |
containerd 配置字段不兼容 | 备份后修正配置 |
no space left on device |
磁盘满导致运行时异常 | 清理镜像/日志前先确认影响 |
需要重启时,先确认维护窗口或至少灰度到单个节点:
bash
sudo systemctl restart containerd用途:让修正后的 containerd 配置重新加载。 判断标准:重启后 sudo systemctl status containerd --no-pager 返回 active (running),并且 sudo crictl info 能返回运行时信息。
生产提醒:重启 containerd 前要评估节点上已有 Pod。不同环境下容器进程是否受影响、kubelet 是否重建 Sandbox、业务是否有 PDB 和多副本,不能靠一句"重启一下"跳过。
第四步:用 debug 模式看 crictl 连接细节
当配置、socket、服务都看起来正常,但 crictl info 仍失败时,打开 debug:
bash
sudo crictl --debug info用途:打印更详细的 CRI 连接过程。 判断标准:关注它实际使用的 endpoint、报错发生在 dial 阶段还是 runtime service 返回阶段。
如果 debug 输出里显示它尝试了多个默认 endpoint,说明 /etc/crictl.yaml 没被正确读取,或者当前用户环境下配置文件不是你以为的那个。此时重新确认:
bash
sudo crictl config runtime-endpoint用途:查看当前 crictl 生效的 runtime endpoint。 判断标准:应返回 unix:///run/containerd/containerd.sock。
如果返回为空或不是预期路径,直接设置:
bash
sudo crictl config runtime-endpoint unix:///run/containerd/containerd.sock用途:通过 crictl config 写入 runtime endpoint。 判断标准:再次执行 sudo crictl config runtime-endpoint,确认输出一致。
第五步:对齐 kubelet 使用的 runtime endpoint
有时 crictl 已经能连,但 kubelet 仍报 CRI 连接错误。这个时候要查 kubelet 使用的是不是同一个 endpoint。
先看 kubelet 进程参数:
bash
ps -ef | grep '[k]ubelet'用途:确认 kubelet 是否带了 --container-runtime-endpoint。 判断标准:如果看到参数,应与 crictl 配置一致,例如:
bash
--container-runtime-endpoint=unix:///run/containerd/containerd.sockkubeadm 集群还要看这个文件:
bash
sudo cat /var/lib/kubelet/kubeadm-flags.env用途:检查 kubeadm 写入的 kubelet 启动参数。 判断标准:KUBELET_KUBEADM_ARGS 里不要残留旧 runtime endpoint。
如果修改 kubelet 配置,先备份:
bash
sudo cp -a /var/lib/kubelet/kubeadm-flags.env /var/lib/kubelet/kubeadm-flags.env.$(date +%F-%H%M%S).bak用途:保留 kubelet 参数文件,便于回滚。 判断标准:生成带时间戳的备份文件。
修正后再重启 kubelet:
bash
sudo systemctl restart kubelet用途:让 kubelet 重新读取 runtime endpoint。 判断标准:sudo journalctl -u kubelet -n 100 --no-pager 不再持续出现 CRI 连接错误,节点状态逐步恢复。
命令速查表:按这个顺序跑

| 顺序 | 命令 | 用途 | 看什么 | |
|---|---|---|---|---|
| 1 | sudo cat /etc/crictl.yaml |
查 crictl endpoint 配置 | runtime-endpoint 是否指向 containerd socket |
|
| 2 | sudo crictl config runtime-endpoint |
查实际生效 endpoint | 是否为 unix:///run/containerd/containerd.sock |
|
| 3 | sudo ls -l /run/containerd/containerd.sock |
查 socket 文件 | 文件是否存在,是否是 socket | |
| 4 | `sudo ss -xl | grep containerd.sock` | 查 socket 监听 | 是否有进程监听该 socket |
| 5 | sudo systemctl status containerd --no-pager |
查服务状态 | 是否 active (running) |
|
| 6 | sudo journalctl -u containerd -n 200 --no-pager |
查 containerd 日志 | 插件、配置、权限、磁盘错误 | |
| 7 | sudo crictl --debug info |
查 crictl 连接细节 | 实际连接哪个 endpoint,在哪一步失败 | |
| 8 | `ps -ef | grep 'kubelet'` | 查 kubelet 参数 | runtime endpoint 是否一致 |
| 9 | sudo cat /var/lib/kubelet/kubeadm-flags.env |
查 kubeadm 写入参数 | 是否残留旧 endpoint | |
| 10 | sudo journalctl -u kubelet -n 100 --no-pager |
查 kubelet 侧报错 | 是否还在报 CRI 连接失败 |
不建议的处理方式
不要看到 crictl info 失败就直接做这些事:
-
直接重装 containerd。
-
直接删除
/run/containerd。 -
在没有备份的情况下改
/etc/containerd/config.toml。 -
把 socket 权限随手改成
777。 -
同时重启 containerd、kubelet、网络插件,导致故障边界被打乱。
更稳的做法是:每次只验证一层,记录命令输出,再决定是否进入下一层。生产环境涉及 containerd 配置、kubelet 参数、socket 权限时,必须先备份、再灰度、最后保留回滚路径。
最小排障路径
可以把这段当成值班时的一页式 checklist:
bash
sudo cat /etc/crictl.yaml
sudo crictl config runtime-endpoint
sudo ls -l /run/containerd/containerd.sock
sudo ss -xl | grep containerd.sock
sudo systemctl status containerd --no-pager
sudo journalctl -u containerd -n 200 --no-pager
sudo crictl --debug info
ps -ef | grep '[k]ubelet'
sudo cat /var/lib/kubelet/kubeadm-flags.env
sudo journalctl -u kubelet -n 100 --no-pager判断顺序也固定:
-
endpoint 配置不对,先修
/etc/crictl.yaml。 -
socket 不存在,先查 containerd 是否启动。
-
socket 存在但连接拒绝,查监听和服务状态。
-
服务 running 但仍失败,查 containerd 日志和 debug 输出。
-
crictl 正常但 kubelet 异常,查 kubelet runtime endpoint 是否一致。
参考资料
-
Kubernetes 官方文档:Debugging Kubernetes nodes with crictl,Debugging Kubernetes nodes with crictl | Kubernetes
-
cri-tools 项目:crictl 使用与配置,github.com/kubernetes-...
-
containerd 项目文档,github.com/containerd/...