普罗米修斯是开源云原生监控 + 告警工具套件
标准三大核心组件:
- Prometheus Server主服务,负责定时抓取指标、存储时序数据、提供 PromQL 查询、规则引擎(告警 / 记录规则)。
- **Exporter(采集器)**各类指标暴露程序,部署在被监控端,把系统 / 业务指标转换成 Prometheus 可识别的 HTTP metrics 格式,如 node-exporter、mysqld-exporter。
- Alertmanager独立告警组件,接收 Prometheus 推送的告警,实现告警分组、去重、抑制、静默、分发(钉钉 / 邮件 / 企业微信等)
Prometheus 如何监控多台 Linux 服务器?
整体流程:node-exporter 采集 → Prometheus 配置 Targets 自动发现 / 静态配置 → Grafana 可视化
步骤拆解
-
所有 Linux 主机部署 node-exporter node-exporter 专门采集服务器硬件、系统指标(CPU、内存、磁盘、网卡、负载、inode 等),默认暴露
9100端口/metrics接口。 -
Prometheus 添加监控目标,两种方式
-
方式 1:静态配置(小规模机器)在
prometheus.yml的scrape_configs中写 static_configs,填写多台机器 IP:9100 列表。 -
方式 2:服务发现(多机器 / 集群推荐)支持文件发现、consul、kubernetes、DNS 等,新增机器只需注册,不用改 Prom 配置重启。示例:file_sd_configs,读取本地 json 文件维护机器列表。
-
重启 / 热加载 Prometheus
kill -HUP pid热加载配置,无需停机。 -
验证 Prometheus UI → Targets 查看所有 Linux 节点状态;用 PromQL 查询系统指标(如
node_cpu_seconds_total)。 -
Grafana 导入 Linux 模板展示大盘
-
Prometheus 如何监控 MySQL 数据库?
采用 mysqld_exporter 采集 MySQL 指标,分完整流程:
- 部署 mysqld_exporter 安装在 MySQL 服务器(或单独机器,能连通 MySQL),默认端口
9104。 - MySQL 创建专用监控账号给 exporter 最小权限账号,用于查询状态、性能指标:
- 配置 exporter 连接 MySQL 通过环境变量或配置文件指定账号密码:
DATA_SOURCE_NAME=exporter:xxx@(127.0.0.1:3306)/ - Prometheus 配置抓取任务
- 指标类型采集连接数、慢查询、innodb 缓冲池、锁、主从复制延迟、QPS、磁盘 IO 等。
- 可视化Grafana 导入 MySQL 专用监控面板,搭配告警规则监控主从延迟、连接满、慢查询突增等。
拓展:多实例 MySQL 可通过多 target、标签区分不同库;K8s 环境用服务发现自动抓取。
Prometheus 常规告警如何配置?静默告警如何配置?
一、常规告警完整配置(分两步:Prometheus 告警规则 + Alertmanager 分发)
1)Prometheus 配置告警规则 rules.yml
在 prometheus.yml 加载规则文件,编写告警表达式、阈值、标签、注释
2)Alertmanager 配置接收渠道(钉钉 / 企业微信 / 邮件)
配置路由、接收器,实现告警推送
二、静默告警(Alertmanager silences 静默规则)
两种使用方式:UI 界面创建静默 / API 命令创建静默
核心作用
临时屏蔽某一类告警,不删除规则,到期自动取消静默;适合维护停机、临时扩容场景。
关键配置参数
- 匹配标签匹配器(matchers):精准过滤要静默的告警示例:
instance=192.168.1.10,alertname=HighCpuLoad - 静默起止时间:设置静默时长(如维护 2 小时)
- 创建人、备注:记录维护原因
补充:告警抑制(Inhibit Rules)和静默区别
- 静默 Silence:手动临时屏蔽,人为维护使用;
- 抑制 Inhibit:自动规则,比如机器宕机后自动屏蔽该机器所有磁盘、CPU 衍生告警。
Prometheus 是通过怎样的方式与工具来实现监控数据图形化展示的?
核心方案:Prometheus + Grafana 组合(企业标准方案)
- 分工说明
-
Prometheus:时序数据库,存储指标、提供 PromQL 查询 API,自身 UI 仅简易图表,不适合大屏运维面板;
-
Grafana:专业可视化工具,作为前端展示层,对接 Prometheus 数据源绘图。
完整实现流程
-
Grafana 添加 Prometheus 数据源 填入 Prometheus 服务地址
http://prometheus:9090,连通时序数据库。 -
编写 PromQL 绘制图表在 Grafana 面板中输入指标查询语句,支持折线图、柱状图、仪表盘、热力图、表格、告警阈值线。
-
导入现成模板Grafana 官网共享大量模板(Linux、MySQL、K8s、Nginx),输入模板 ID 一键导入,无需从零写图表。
-
大屏与告警联动自定义监控大盘、多面板分组;图表配置阈值变色,和 Alertmanager 告警联动展示故障节点。
备选轻量化方案(小规模自用)
Prometheus 自带内置 UI:直接访问 9090 端口,输入 PromQL 生成简单临时图表,缺点:无持久化面板、无法分屏、样式简陋,生产环境不用。
安装
获取安装包https://prometheus.io/download/
#下载到windows的安装包下载到Linux里
rz
#解压到当前路径
tar xvf prometheus-3.10.0.linux-amd64.tar.gz
#移动到/export/server 并且重命名为一个短名字
mv prometheus-3.10.0.linux-amd64 /export/server/prometheus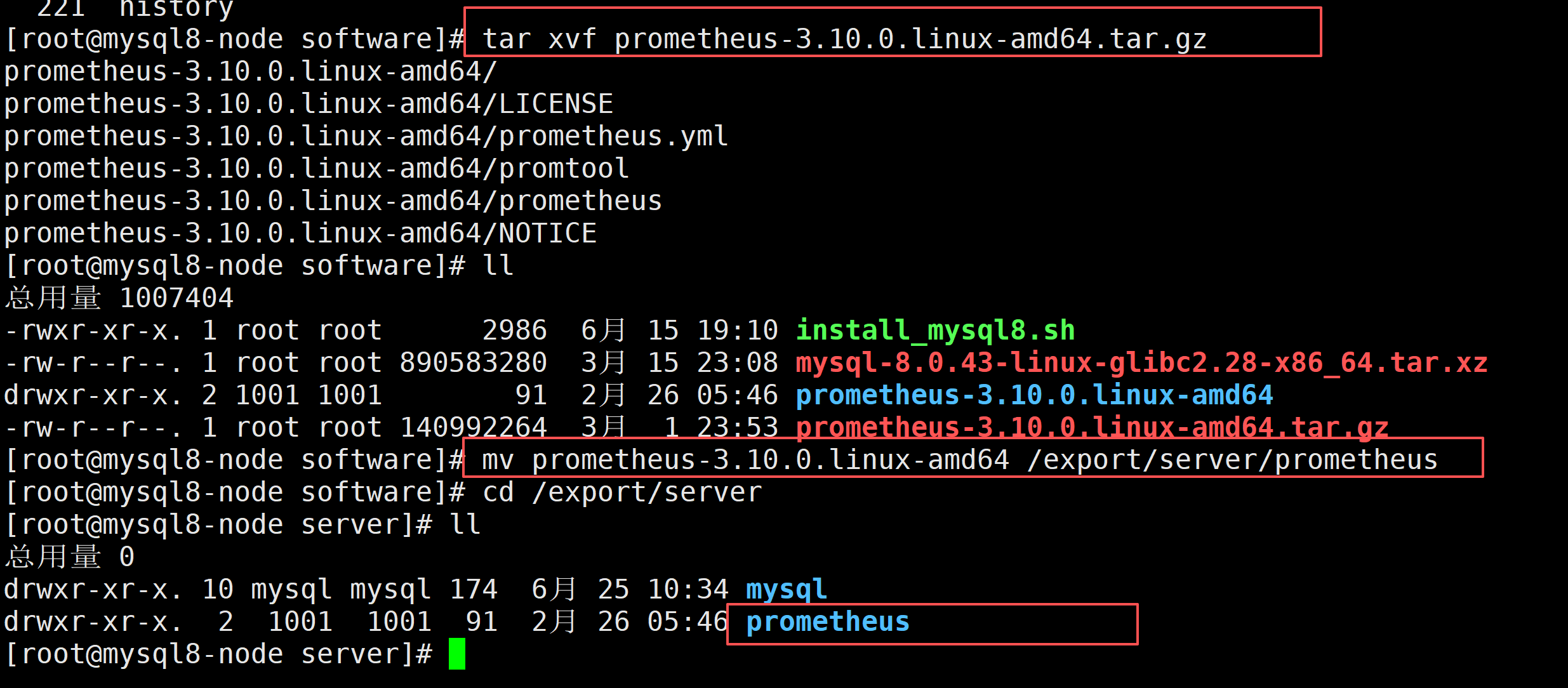
cd /export/server/prometheus
wc -l prometheus.yml
grep 9090 prometheus.yml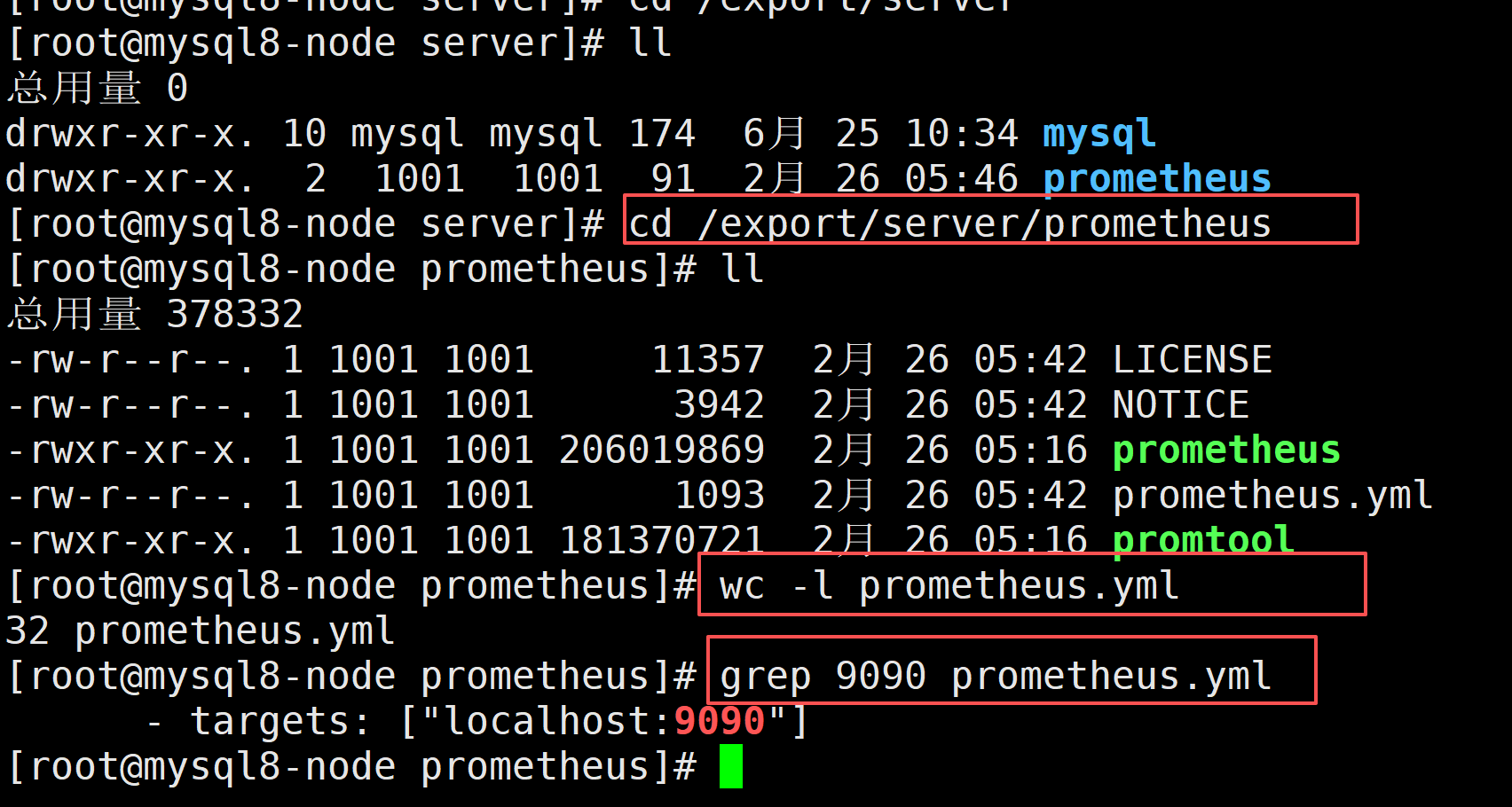
cat > prometheus.yml <<'EOF'
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"
EOF
# 用 cat 命令创建/覆盖 prometheus.yml 配置文件,内容从 EOF 开始到下一个 EOF 结束
cat > prometheus.yml <<EOF
# ====================== 全局配置段 ======================
# 全局配置:对整个 Prometheus 生效的基础设置
global:
# 数据采集间隔:每 15 秒去目标机器拉取一次监控指标
scrape_interval: 15s
# 规则评估间隔:每 15 秒检查一次告警规则/记录规则
evaluation_interval: 15s
# 采集超时时间:未手动配置,使用默认值 10 秒
# ====================== 告警管理器配置 ======================
# 告警配置:关联 Prometheus 与 AlertManager(告警通知组件)
alerting:
alertmanagers:
- static_configs:
- targets:
# 告警管理器地址:当前已注释,未启用告警通知
# - alertmanager:9093
# ====================== 规则文件配置 ======================
# 规则文件:加载告警规则、聚合指标规则的配置文件列表
rule_files:
# 自定义规则文件1(已注释,未启用)
# - "first_rules.yml"
# 自定义规则文件2(已注释,未启用)
# - "second_rules.yml"
# ====================== 监控采集任务配置 ======================
# 采集任务:定义 Prometheus 要监控哪些服务、怎么采集
scrape_configs:
# 任务名称:任务名会自动变成标签 job=prometheus
- job_name: "prometheus"
# 指标采集路径:默认 /metrics,已省略不写
# metrics_path defaults to '/metrics'
# 访问协议:默认 http,已省略不写
# scheme defaults to 'http'.
# 静态配置:直接写死监控目标地址(不使用服务发现)
static_configs:
# 监控目标:本机 9090 端口(即 Prometheus 自己)
- targets: ["localhost:9090"]
# 自定义标签:给这条监控数据额外打上 app=prometheus 标签
labels:
app: "prometheus"
EOF启动
临时测试启动方式,必须在安装路径启动
./prometheus --config.file=prometheus.yml 关一下防火墙,管理selinux
sed -i -r 's/SELINUX=[ep].*/SELINUX=disabled/g' /etc/selinux/config
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config &> /dev/null
setenforce 0
systemctl stop firewalld &> /dev/null
systemctl disable firewalld &> /dev/null
iptables -F
# 查看9090端口监听(无输出=进程没起来)
ss -tlnp | grep 9090Prometheus Web 界面里看看 192.168.103:9090/query
注意:后台这里不能退出,这个是实时的
进来之后是这样的
配置服务
# 创建用户组和用户
groupadd prometheus
useradd -r -g prometheus -s /bin/false prometheus
chown -R prometheus:prometheus /export/server/prometheus
# 或者使用精简命令
useradd -r -s /bin/false prometheus
chown -R prometheus:prometheus /export/server/prometheus
# 添加 service 文件
cat > /etc/systemd/system/prometheus.service <<EOF
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Restart=on-failure
ExecStart=/export/server/prometheus/prometheus \
--config.file=/export/server/prometheus/prometheus.yml \
--storage.tsdb.path=/export/server/prometheus/data \
--storage.tsdb.retention.time=7d \
--web.enable-lifecycle \
--web.enable-admin-api
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl restart prometheus
systemctl enable prometheus
systemctl status prometheus详解
# ====================== 1. 创建专用用户和用户组 ======================
# 创建一个名叫 prometheus 的用户组(用于权限分组管理)
groupadd prometheus
# 创建一个 系统专用用户 prometheus:
# -r:系统用户(不用于登录)
# -g prometheus:归到 prometheus 组
# -s /bin/false:禁止登录服务器(安全加固)
useradd -r -g prometheus -s /bin/false prometheus
# 把 /usr/local/prometheus 目录的所有者、所属组 改成 prometheus
# 让 Prometheus 进程有权限读写自己的目录、数据文件
chown -R prometheus:prometheus /usr/local/prometheus
# ====================== 2. 创建 systemd 服务文件 ======================
# 用 cat 命令创建 prometheus.service 服务文件(让系统能管理 Prometheus)
cat > /etc/systemd/system/prometheus.service <<EOF
# 服务描述段
[Unit]
# 服务名称描述
Description=Prometheus Server
# 官方文档地址
Documentation=https://prometheus.io/docs/introduction/overview/
# 启动顺序:等网络准备好再启动 Prometheus
After=network-online.target
# 服务运行参数
[Service]
# 以 prometheus 用户运行
User=prometheus
# 以 prometheus 用户组运行
Group=prometheus
# 服务异常崩溃时,自动重启
Restart=on-failure
# 核心:启动 Prometheus 的命令
ExecStart=/usr/local/prometheus/prometheus \
# 指定配置文件路径
--config.file=/usr/local/prometheus/prometheus.yml \
# 指定时序数据存储目录
--storage.tsdb.path=/usr/local/prometheus/data \
# 数据保留时间:只保留 7 天(超过自动删除)
--storage.tsdb.retention.time=7d \
# 开启热重载功能(改配置不用停服务)
--web.enable-lifecycle \
# 开启管理 API(用于清理数据、调试)
--web.enable-admin-api
# 系统启动级别
[Install]
# 让服务在系统多用户模式下自动启动(开机自启)
WantedBy=multi-user.target
EOF
# ====================== 3. 加载服务并启动 Prometheus ======================
# 重新加载 systemd 配置(让系统识别新添加的服务文件)
systemctl daemon-reload
# 重启 Prometheus 服务(第一次执行=启动)
systemctl restart prometheus
# 设置开机自启(服务器重启后自动跑 Prometheus)
systemctl enable prometheus
# 查看 Prometheus 运行状态(看是否成功启动、有无报错)
systemctl status prometheusweb端
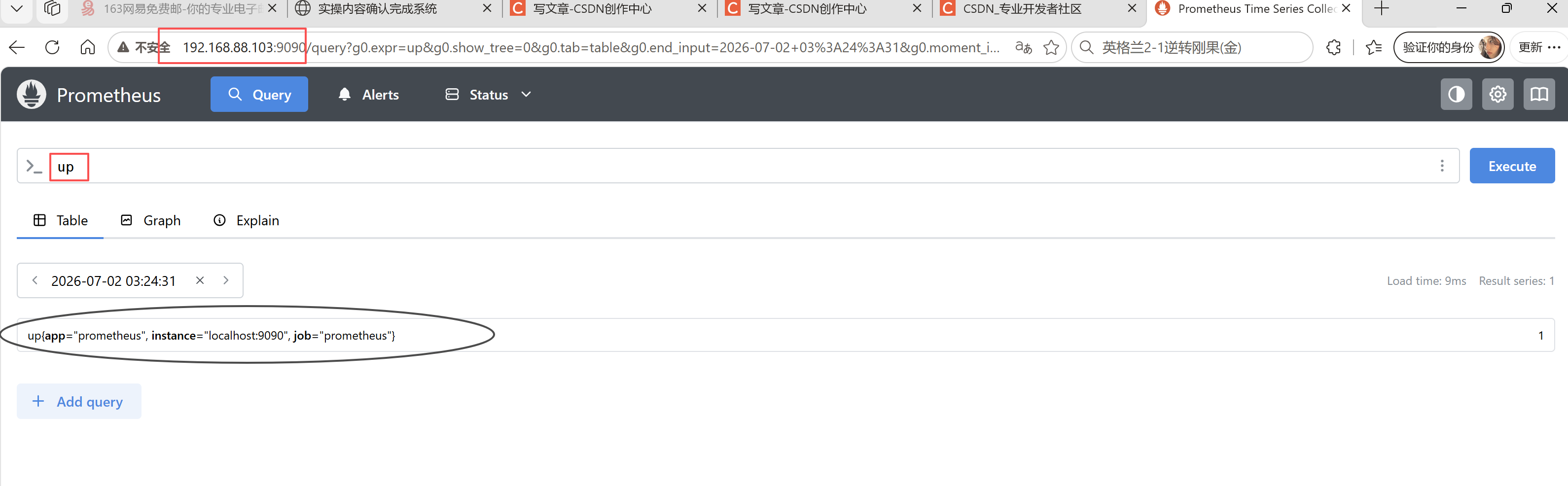
up指标含义up是 Prometheus 内置健康指标,用来判断监控目标是否能正常拉取指标:
- 数值 =
1:目标存活,采集正常; - 数值 =
0:目标失联,采集失败
查询一分钟的数据
未来配置的告警规则显示在这里
采集指标健康度

服务器监控数据采集node_exporter
node_exporter 是 Prometheus 官方配套的服务器硬件 & 操作系统指标采集器 ,专门抓取 Linux 系统底层监控数据,部署在每一台需要监控的 Linux 主机上,对外暴露 /metrics 接口供 Prometheus 定时拉取。
安装
# 下载 Node Exporter 二进制包(用于采集 Linux 服务器的硬件/系统监控指标)
curl -LO https://github.com/prometheus/node_exporter/releases/download/v1.10.2/node_exporter-1.10.2.linux-amd64.tar.gz
或者
#国内镜像下载地址
curl -L0 https://mirror.ghproxy.com/https://github.com/prometheus/node_exporter/releases/download/v1.10.2/node_exporter-1.10.2.linux-amd64.tar.gz
或者
# 拖动本地压缩包到Linux服务器
node_exporter-1.10.2.linux-amd64.tar.gz解压
# 1. 解压 Node Exporter 压缩包
# x=解压 v=显示过程 f=指定文件
tar xvf node_exporter-1.10.2.linux-amd64.tar.gz
# 2. 进入解压后的目录
cd node_exporter-1.10.2.linux-amd64/
# 3. 把 node_exporter 可执行文件 移动到系统命令目录
# 这样在任何目录都能直接运行 node_exporter
mv node_exporter /usr/local/bin
# 4. 查看 node_exporter 命令所在路径
# 验证是否安装成功:输出 /usr/local/bin/node_exporter 就是成功
which node_exporter
# 5. 后台启动 Node Exporter
# nohup = 让程序脱离终端,关闭窗口也不会停
# & = 后台运行
nohup node_exporter &
# 6. 查看 Node Exporter 是否在运行
# ps aux 列出所有进程
# grep node_exporter 过滤出这个程序
ps aux|grep node_exporter
# 7. 查看 node_exporter 占用的端口
# 能看到 9100 端口正在被监听
netstat -pantul|grep node_exporter
# 8. 直接用端口号 9100 检查监听状态
# Node Exporter 默认端口 = 9100
netstat -pantul|grep 9100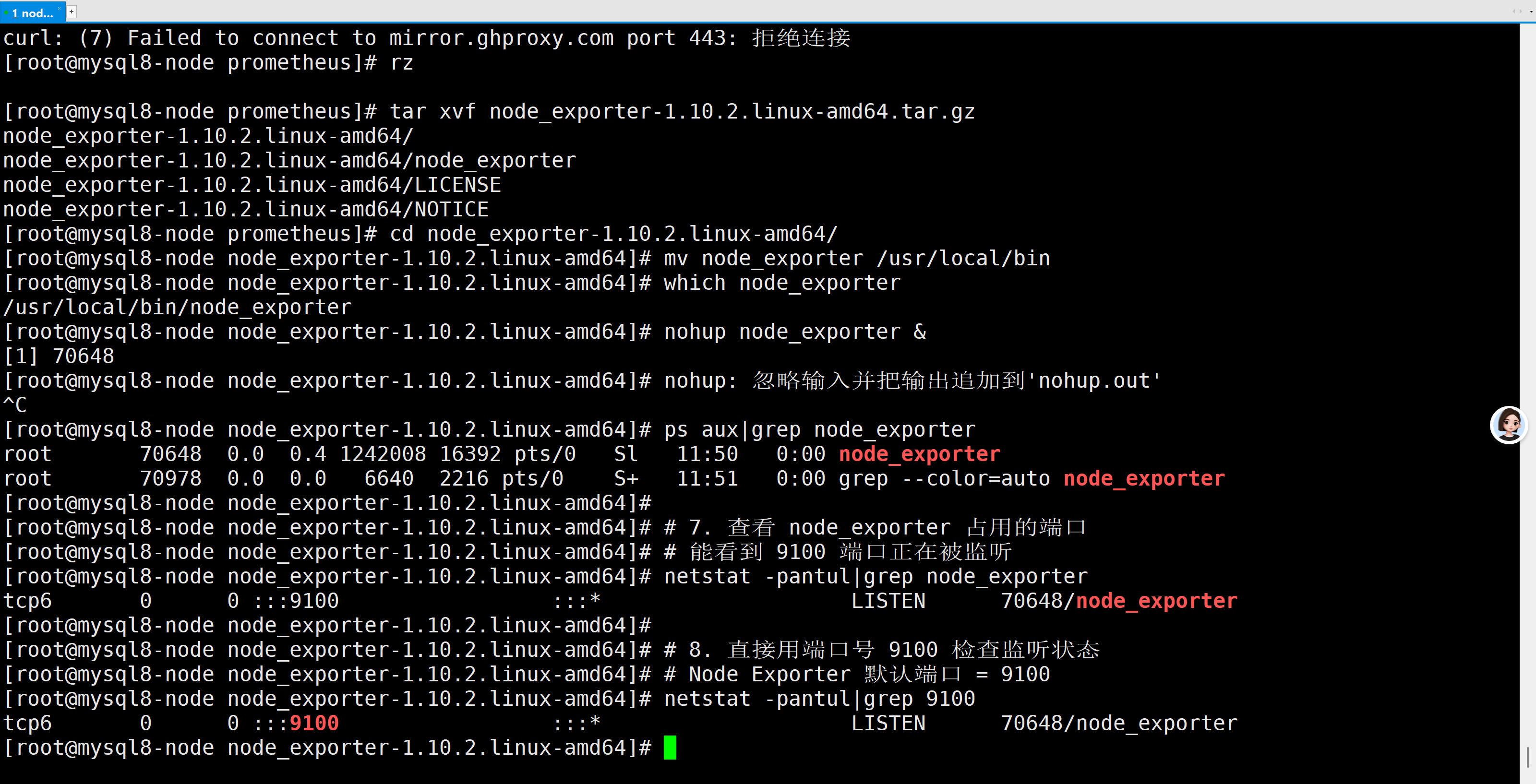
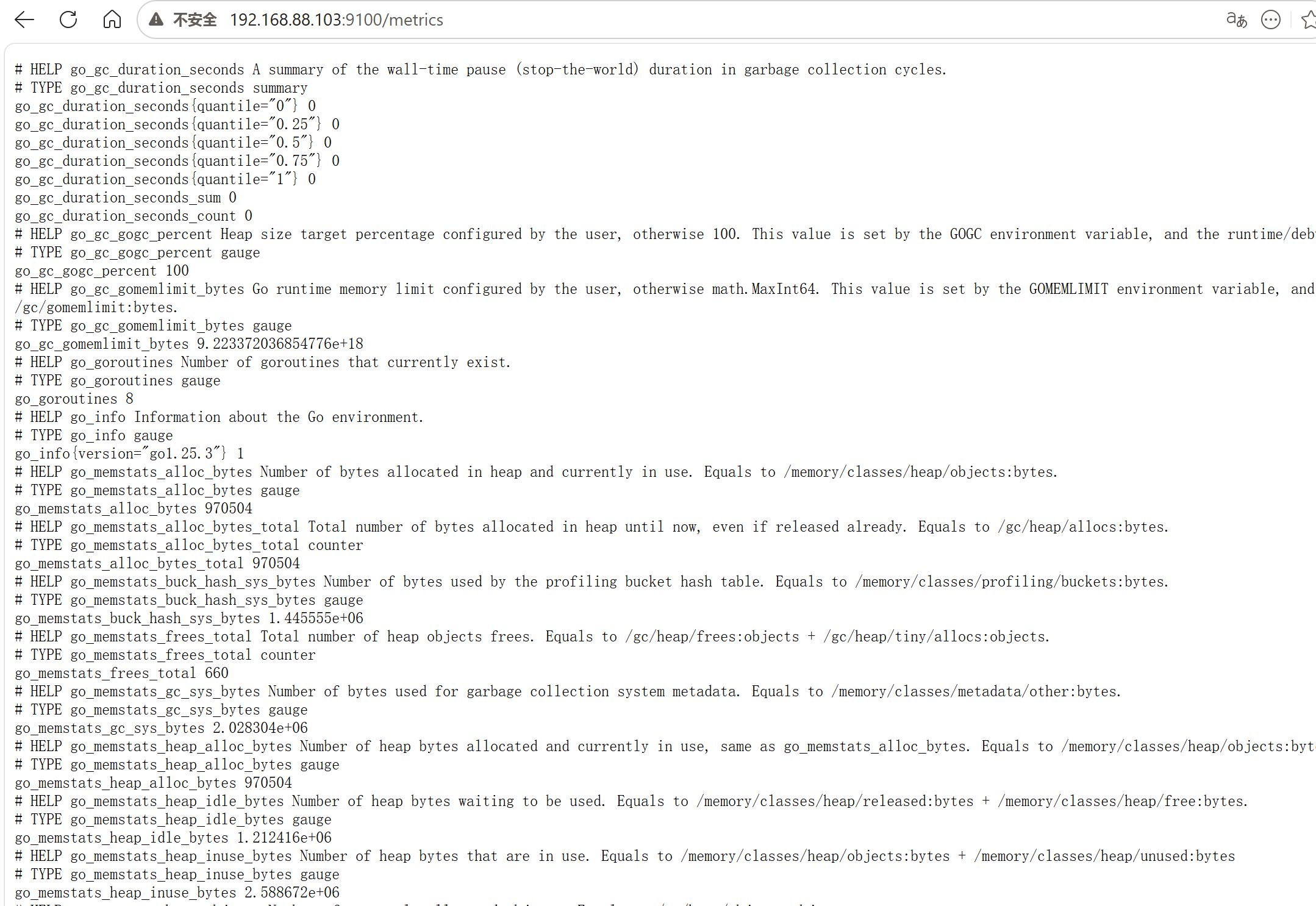
查看 node_exporter 采集的内容,打开 http://IP:9100,点击 metrics
http://192.168.88.103:9100/metrics
采集 node_exporter
它会自动采集操作系统几乎所有核心资源数据,覆盖运维最关心的监控项:
硬件资源类
-
CPU:总使用率、各核心负载、空闲率、iowait、中断、上下文切换
-
内存:总内存、可用内存、缓存、缓冲区、Swap 交换分区使用量
-
磁盘:磁盘读写 IO、IO 等待、磁盘分区使用率、inode 剩余、磁盘吞吐量
-
网络:网卡收发流量、丢包率、错误包、TCP 连接数(ESTABLISHED/TIME_WAIT 等)
系统状态类
-
系统负载(1/5/15 分钟平均负载)、运行时长
-
文件句柄、进程总数、僵尸进程
-
系统内核版本、主机名、操作系统发行版(对应你之前 Grafana 用到的
node_uname_info) -
挂载点、硬件温度、RAID 磁盘状态等硬件信息
find / -name prometheus.yml
/export/server/prometheus/prometheus.yml

-
.yml是配置文件:只能读 / 改,不能执行; -
prometheus/promtool/node_exporter是二进制程序,才可以./xxx执vim /export/server/prometheus/prometheus.yml
在最下面追加
# node_exporter
- job_name: "node"
static_configs:
- targets: ['192.168.88.101:9100','192.168.88.102:9100']
labels:
env: 'test'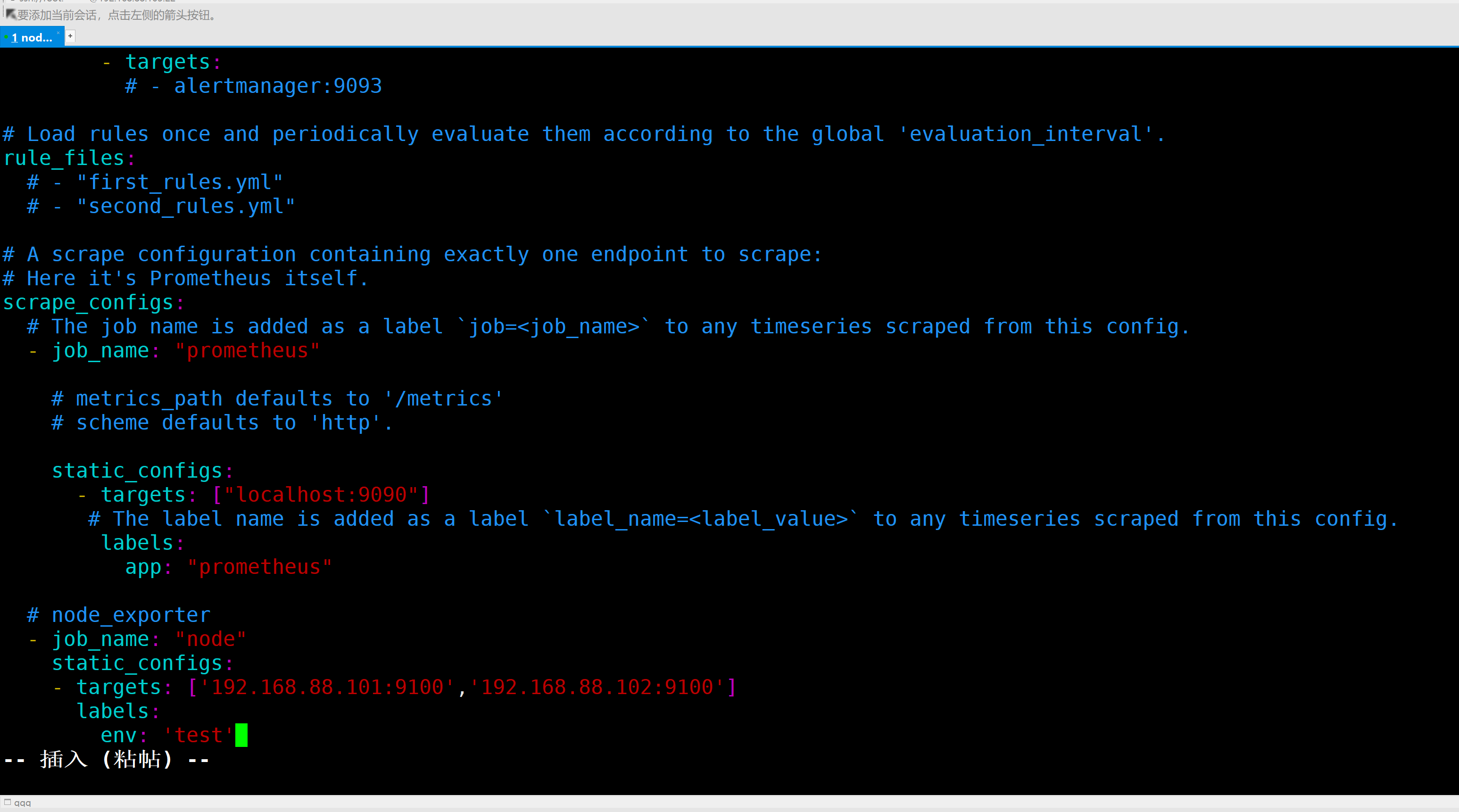
看一下配置文件有没有语法错误,返回sucess就是ok
/export/server/prometheus/promtool check config /export/server/prometheus/prometheus.yml
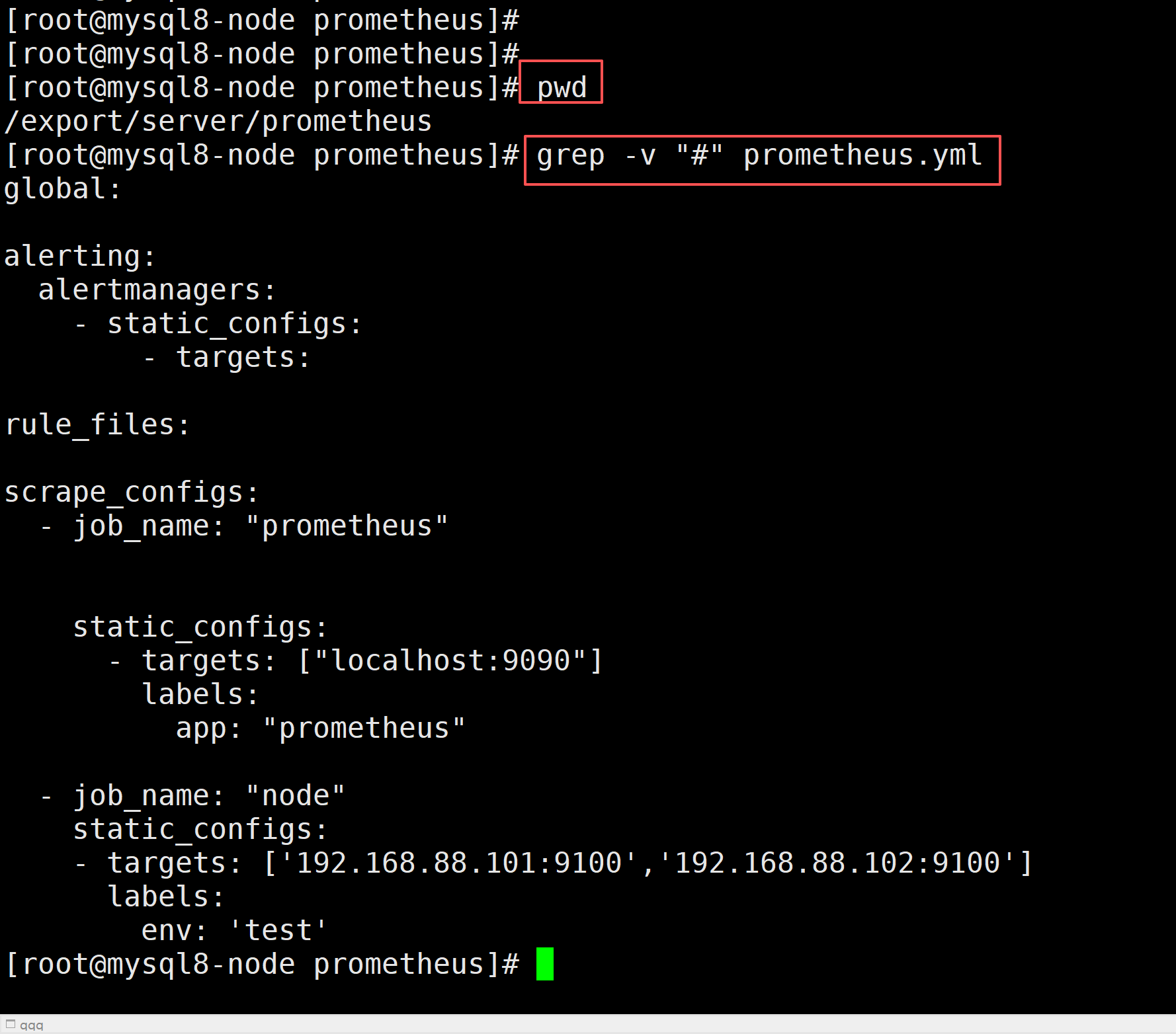
查看无注释的纯净配置
只看有效配置能瞬间得到 3 个关键信息,用于排错:
-
现在监控了哪些服务:只有
prometheus自身、node主机两类任务; -
要采集哪些服务器:101、102 两台机器,没包含本机 103;
-
给指标打了什么分类标签:
env="test",后续 Grafana 筛选、告警过滤全靠标签。grep -v "#" prometheus.yml
static_configs 属于静态抓取,逻辑是:运维清楚机房所有服务器 IP,手动把每台部署了 node_exporter 的机器 IP 写死在配置里。Prometheus 的工作逻辑:
- 你写什么 IP,它就定时去访问
IP:9100/metrics; - 它不会自己探测局域网、不会自动发现其他机器;
- 如果 101/102 机器关机、没开 node_exporter,页面查询
up{job="node"}对应实例的值会变成 0,代表采集失败。
重载配置
ps -ef | grep prometheus
进程 PID 59103,父进程 PID=1(系统托管后台常驻),说明服务已经成功后台启动,不是临时前台运行。执行用户是 prometheus 普通用户,而非 root,权限运行正常。
curl -ksvvXPOST http://192.168.88.103:9090/-/reload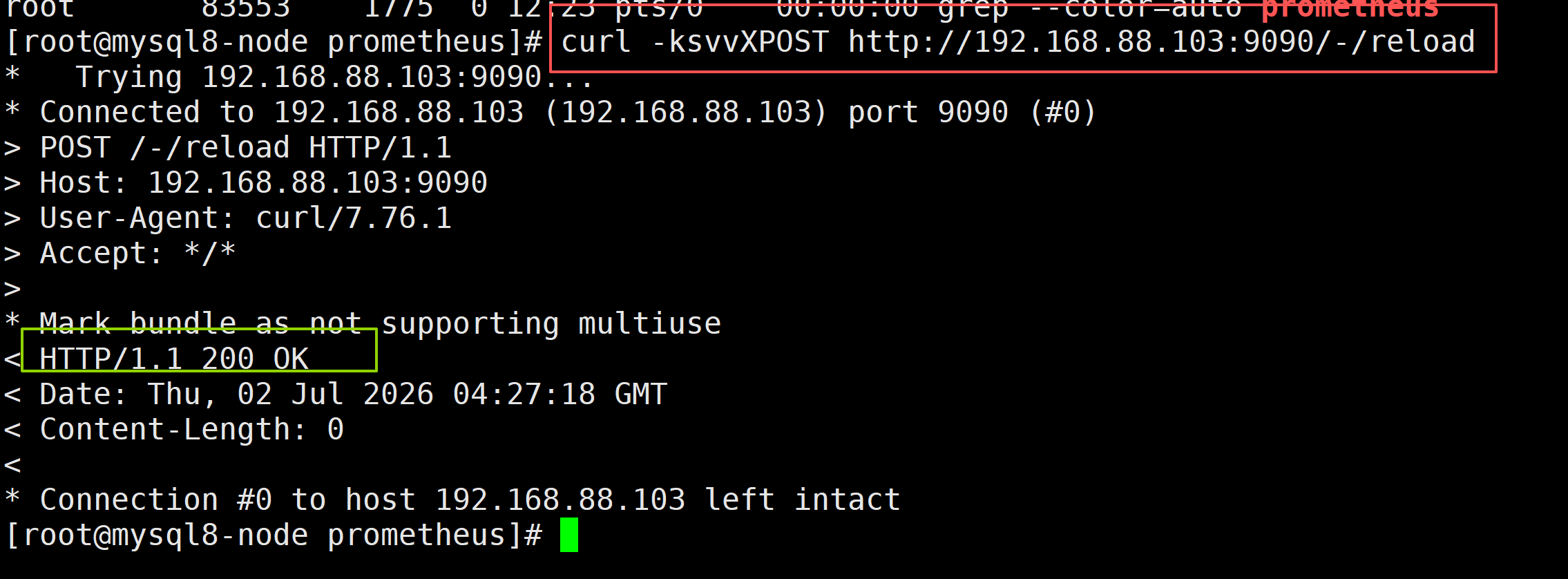
HTTP 状态码 200 代表重载请求执行成功,Prometheus 已经重新读取并加载 prometheus.yml 配置文件。
或者重启普罗米修斯
systemctl restart prometheus
systemctl status prometheus验证
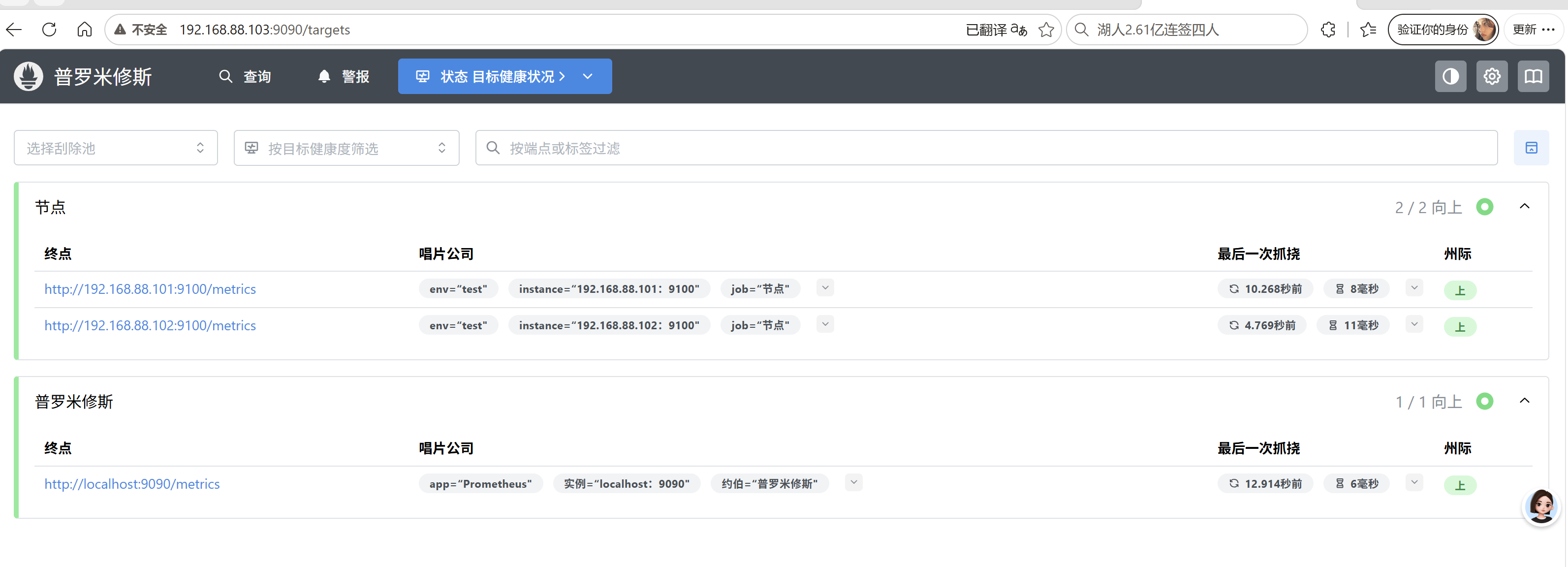
用浏览器打开
http://192.168.88.103:9090/targets
查看
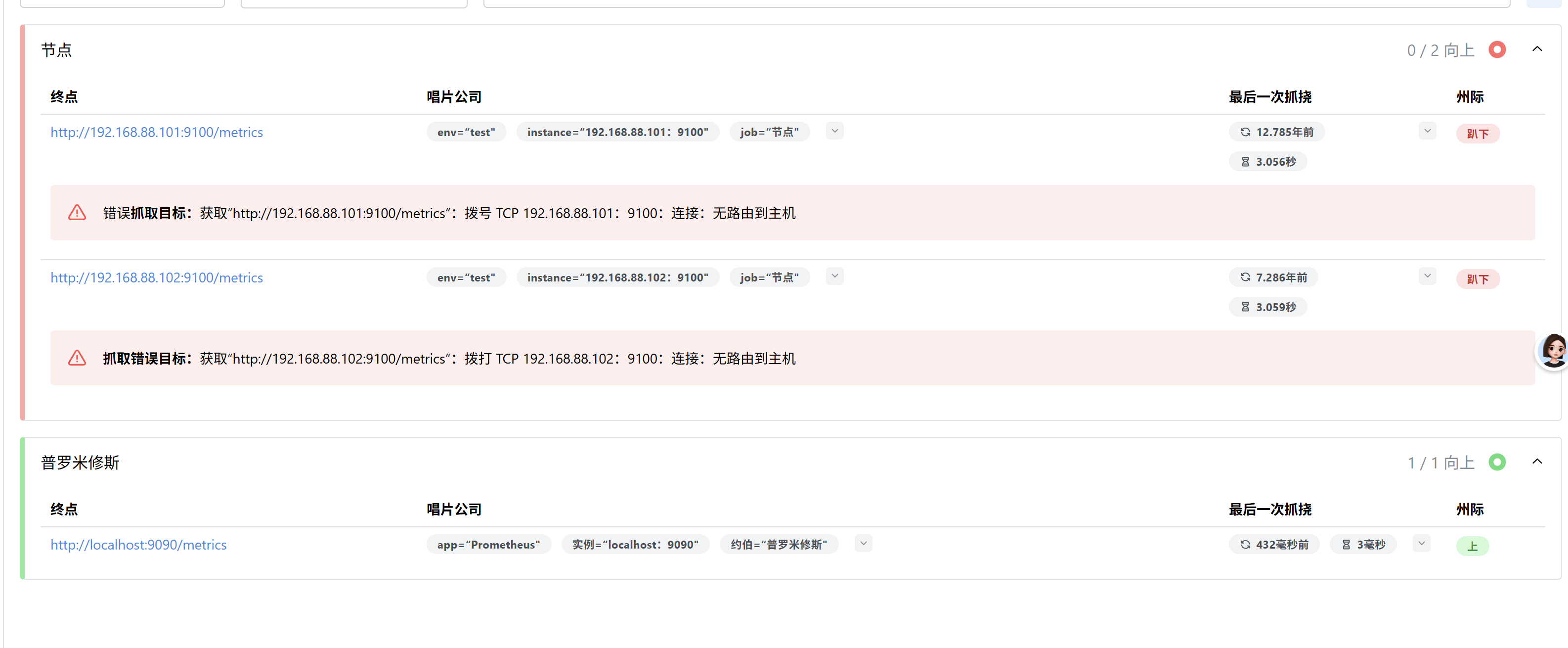
添加节点
# 把本机 /usr/local/bin 下的 node_exporter 二进制文件
# 远程拷贝到 192.168.88.101 机器的 /usr/local/bin 目录
scp /usr/local/bin/node_exporter 192.168.88.101:/usr/local/bin/
# 同理:拷贝到第二台被监控节点 192.168.88.102
scp /usr/local/bin/node_exporter 192.168.88.102:/usr/local/bin/被监控的地方执行
nohup node_exporter &页面再刷新一下
防火墙和SELinux
sed -i -r 's/SELINUX=[ep].*/SELINUX=disabled/g' /etc/selinux/config
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config &> /dev/null
setenforce 0
systemctl stop firewalld &> /dev/null
systemctl disable firewalld &> /dev/null
iptables -FGrafana
一、基础介绍
-
访问地址 :
http://192.168.88.100:3000/-
3000 是 Grafana 默认端口;
-
它是一套开源监控可视化面板工具,专门搭配 Prometheus 使用。
-
-
和 Prometheus 是什么关系?
-
Prometheus:负责采集服务器、MySQL 的监控指标,存时序数据;
-
Grafana:负责把 Prometheus 里枯燥的数字,做成曲线图、仪表盘、状态仪表盘,给人直观看负载。二者是运维监控标准搭档:采集存储 (Prometheus) + 可视化展示 (Grafana)。
Linux服务器 → node_exporter(9100) → Prometheus采集存储(9090) → Grafana(3000)绘图展示
下载 Grafana 安装包
获取安装包下载链接 https://grafana.com/grafana/download?pg=get\&edition=oss
wget https://dl.grafana.com/grafana/release/12.4.0/grafana_12.4.0_22325204712_linux_amd64.tar.gz
tar -zxvf grafana_12.4.0_22325204712_linux_amd64.tar.gz我有一个包,直接 rz 上传上来解压了
groupadd grafana
useradd -r -g grafana -s /bin/false grafana
mv grafana-12.4.0 /export/server/grafana把官方全套默认配置复制一份,生成可修改、程序启动会读取的 grafana.ini
cp /export/server/grafana/conf/defaults.ini /export/server/grafana/conf/grafana.inidefaults.ini(模板文件)
- 存放所有配置项的完整默认值、注释说明;
- 不要直接编辑它,升级 Grafana 时会被覆盖;
- Grafana 运行不会读取这个文件。
grafana.ini(生效配置)
- 复制后生成,你在这里修改自定义参数;
- Grafana 启动时优先加载
grafana.ini,里面写的配置会覆盖 defaults.ini 默认值;- 不会随软件升级被覆盖,自定义配置永久保留。
刚安装完 Grafana 时,conf 目录只有 defaults.ini,没有 grafana.ini:
-
不复制:Grafana 只能用硬编码的内置默认参数,无法自定义(改端口、改密码、开启匿名登录、对接 Prometheus、邮件告警等都做不了);
-
复制出
grafana.ini后:你可以打开文件注释、修改参数,重启 Grafana 即可生效。chown -R grafana:grafana /export/server/grafana
配置服务
cat > /etc/systemd/system/grafana.service <<EOF
[Unit]
Description=Grafana Server
After=network.target
[Service]
Type=simple
User=grafana
Group=grafana
ExecStart=/export/server/grafana/bin/grafana server --config=/export/server/grafana/conf/grafana.ini --homepath=/export/server/grafana
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl start grafana
systemctl enable grafana
systemctl status grafana
netstat -pantul|grep grafana
# 停止服务
systemctl stop grafana
# 重启(改完grafana.ini必须执行)
systemctl restart grafana
# 实时看运行日志
journalctl -u grafana -f查看验证
浏览器打开
登陆,默认账号/密码 admin/admin
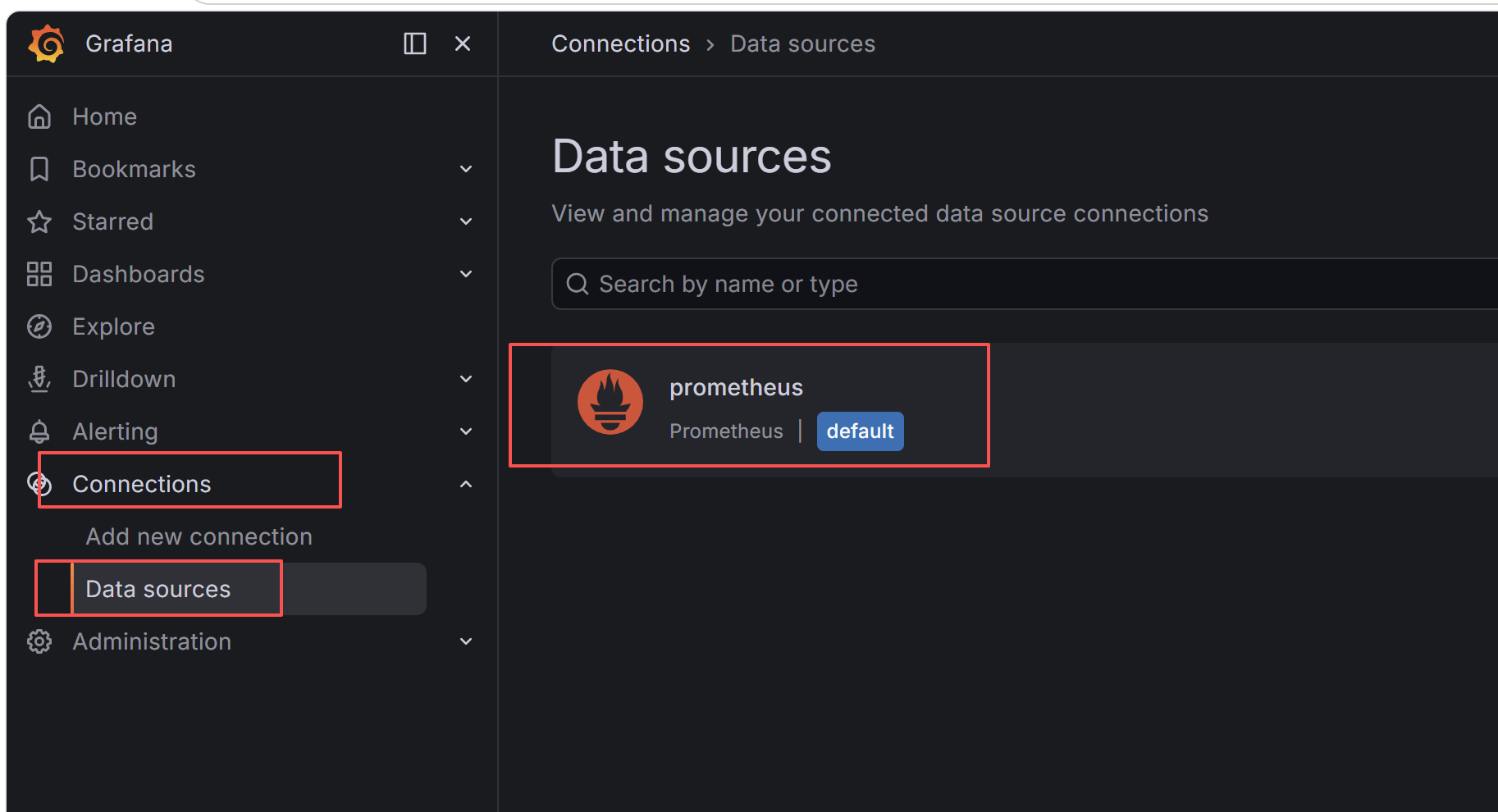
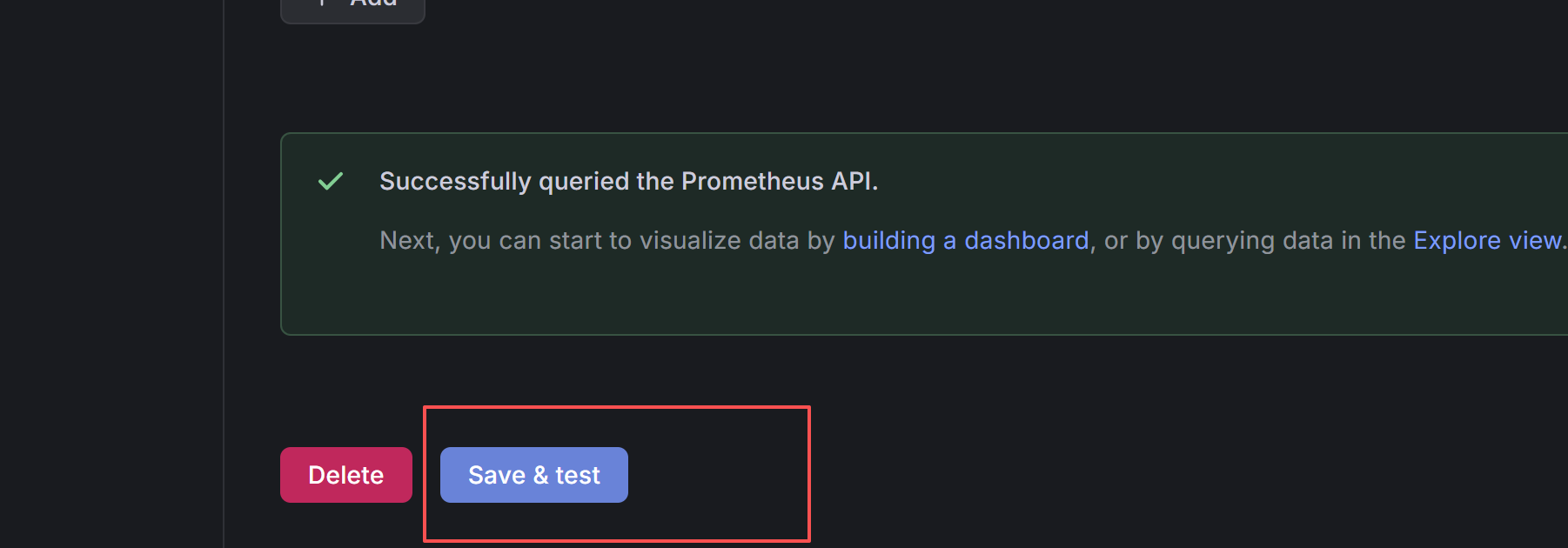
数据源配置
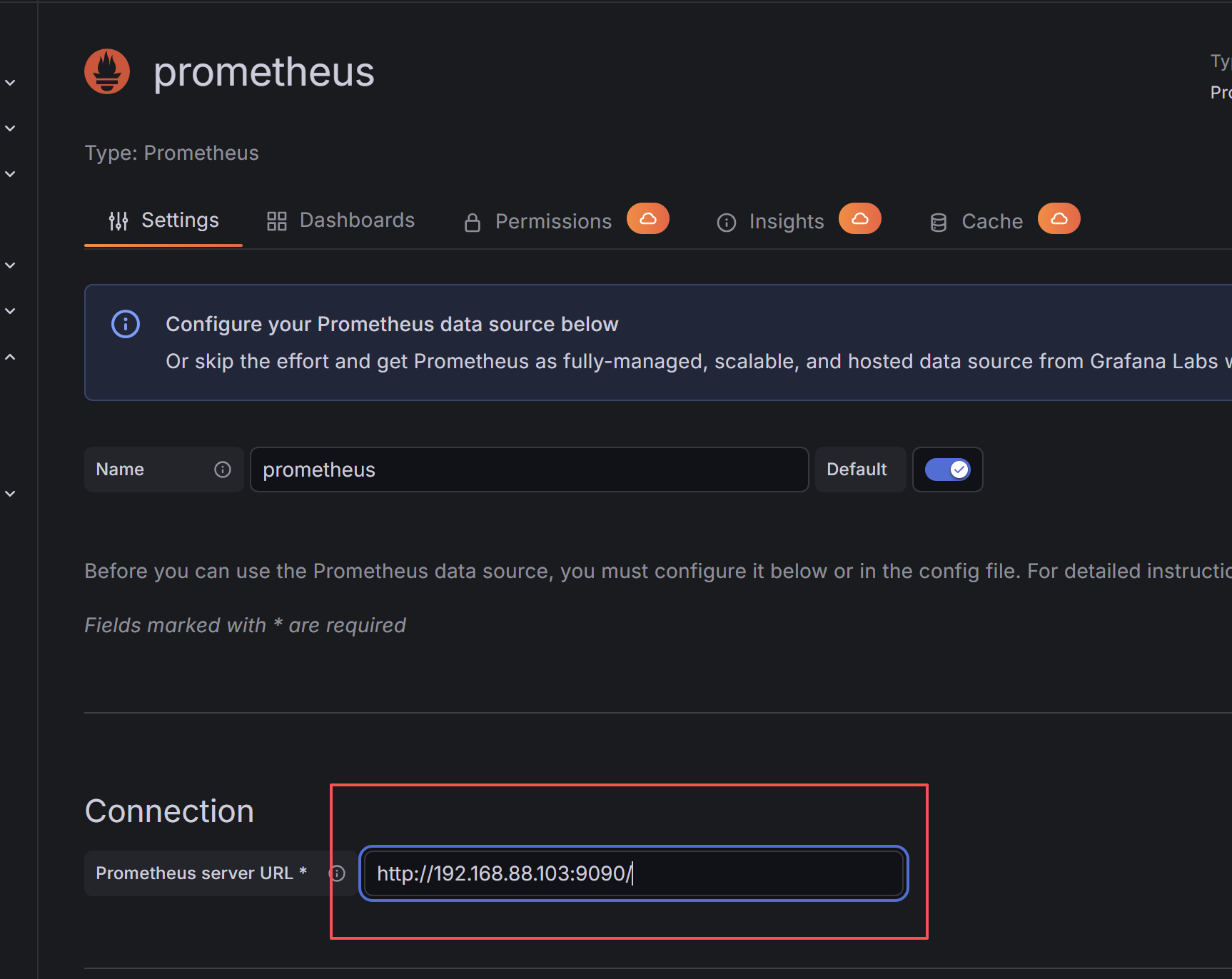
然后滑到最下面
Dashboard 开发
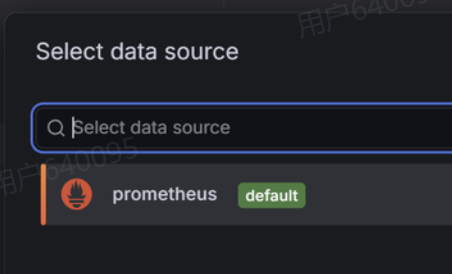
调整 metric
默认 Builder
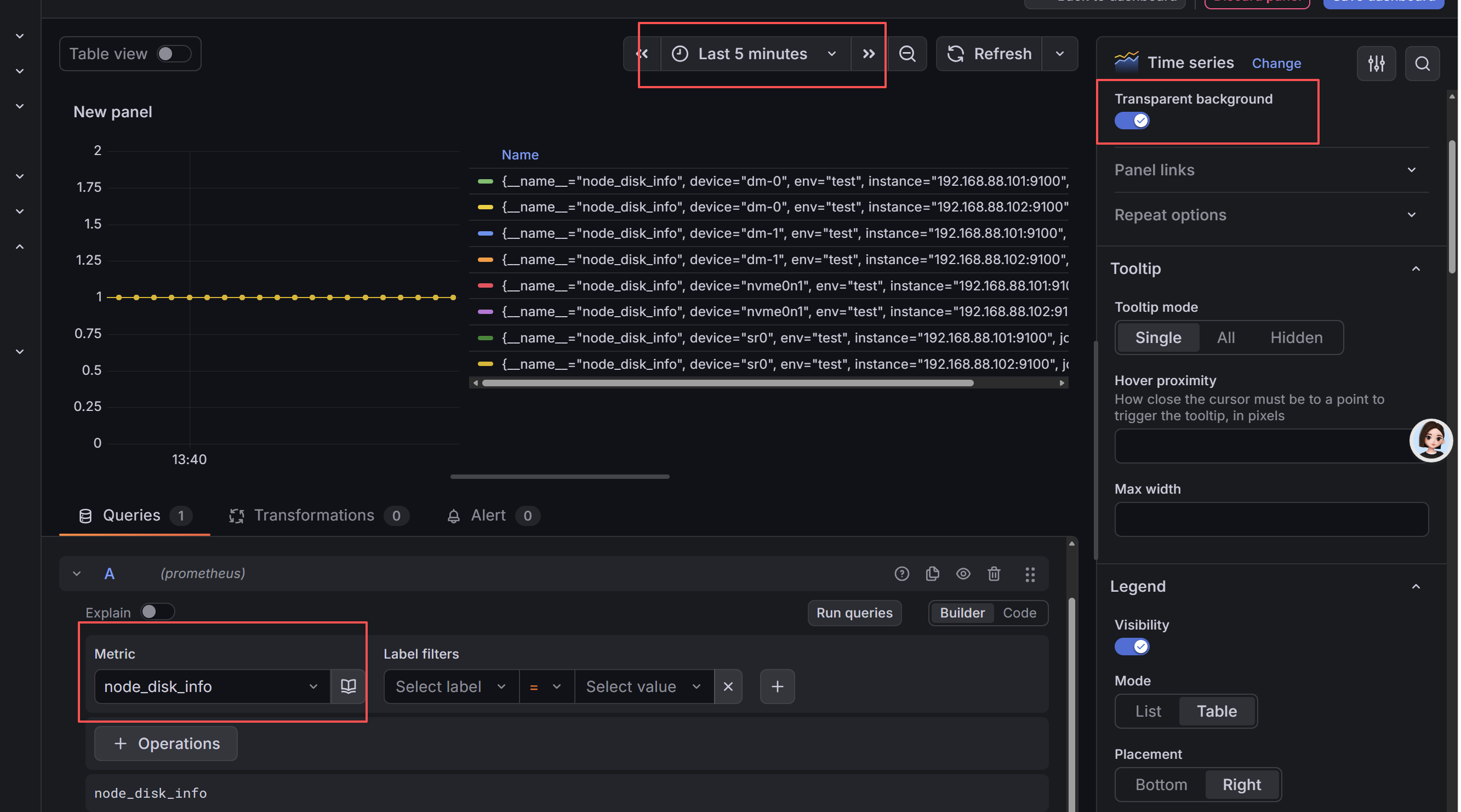
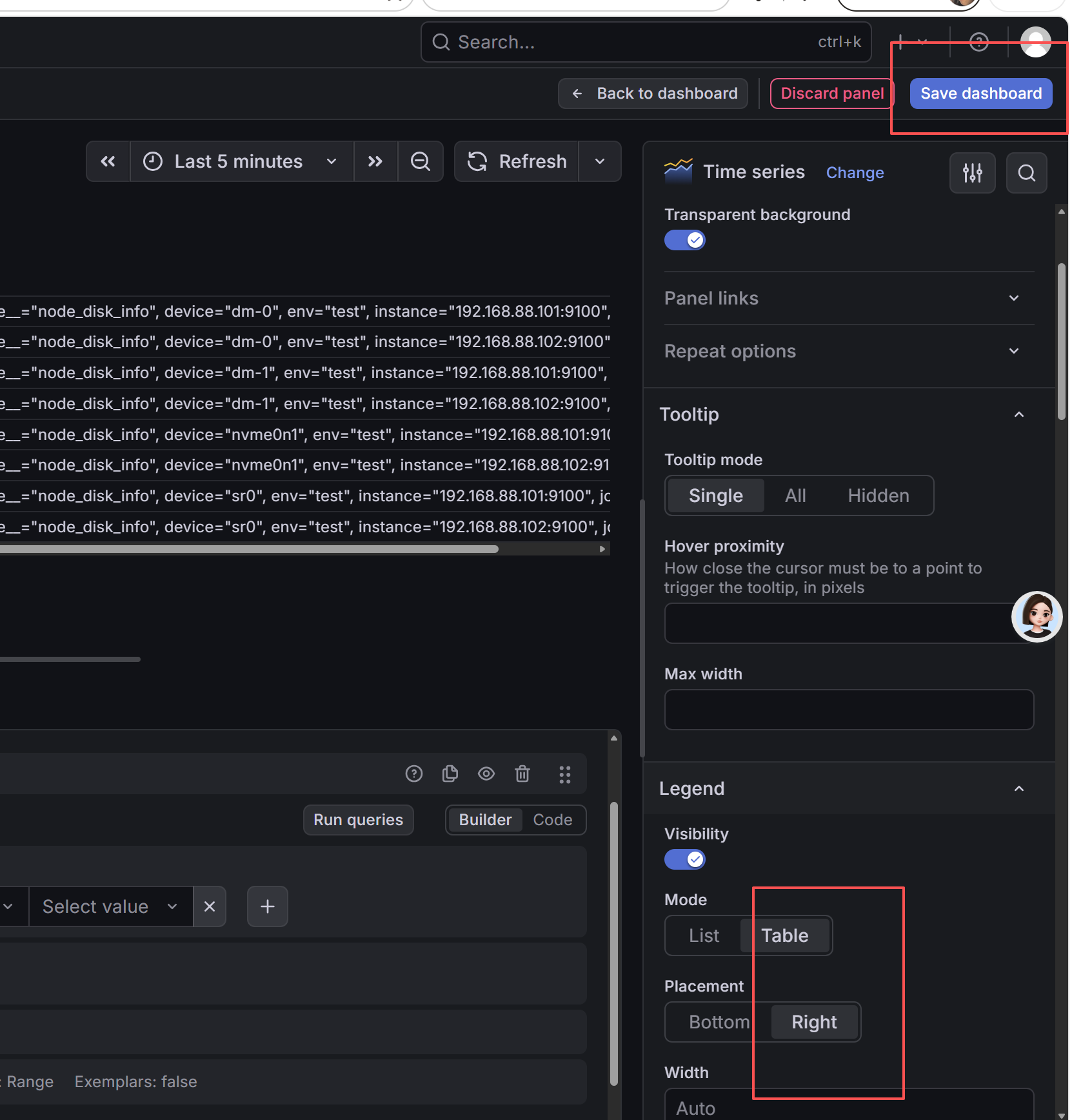
保存之后,
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes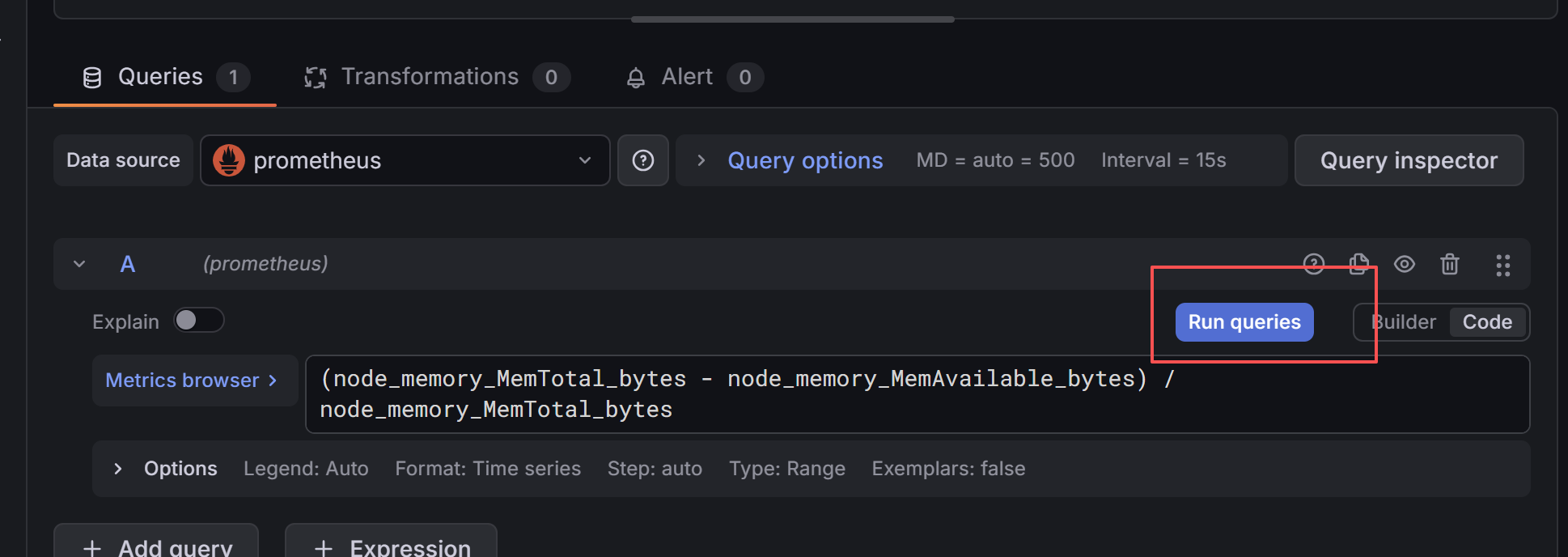
这个公式 = 算 内存使用率百分比
就是你在 Windows 任务管理器、手机设置里看到的**"内存已用 45%"** 这种数字!
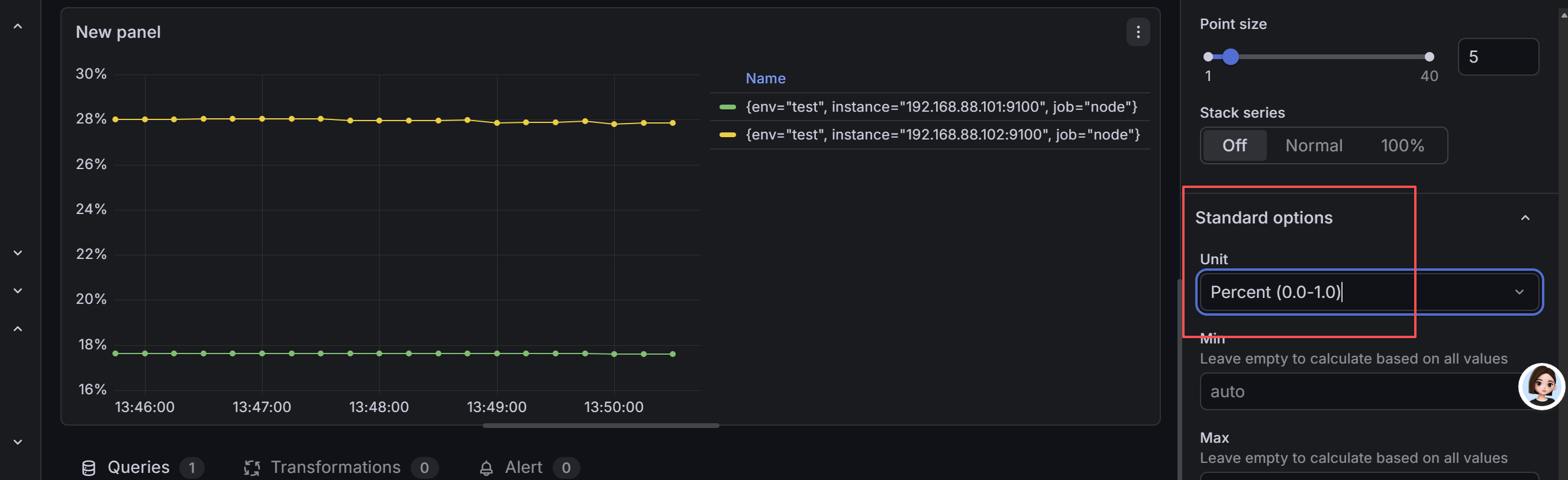
跑完曲线后,右侧 Panel options 里可以设置单位为百分比,数值会带 % 显示
添加磁盘读写情况
(rate 函数)
统计最近 1 分钟内,真实物理磁盘 每秒磁盘读写操作次数 IOPS(Input/Output Operations Per Second)
rate(node_disk_reads_completed_total{device!="sr0", device!="dm-*"}[1m])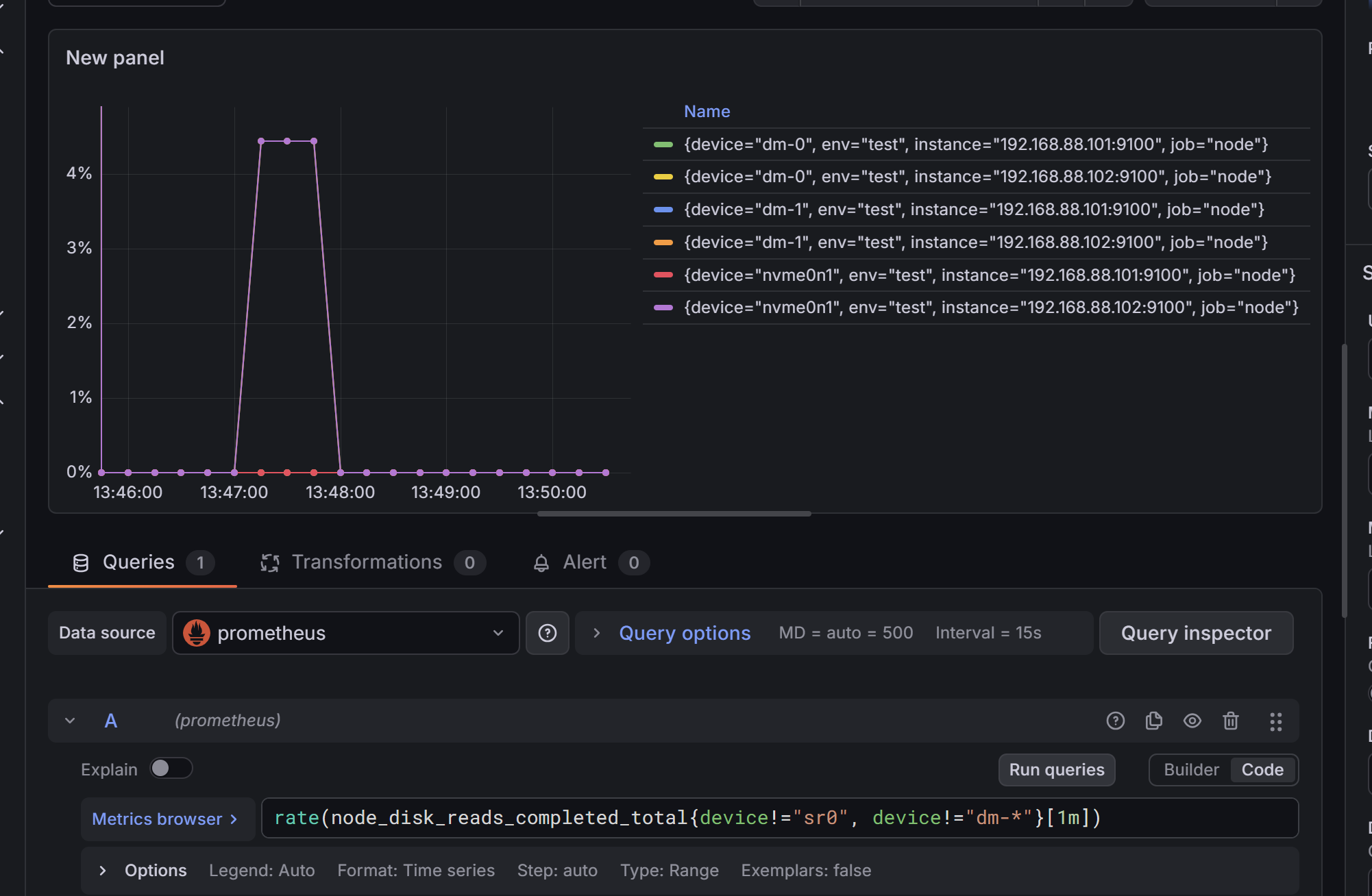
不关注磁盘,只看整体。
(聚合函数)
以最近 1 分钟为计算时间窗口,基于磁盘累计写完成总次数,算出真实物理磁盘每秒写操作次数(写 IOPS);过滤排除光驱 sr0、LVM 映射盘、loop 循环设备、ram 内存盘,只统计真实物理硬盘。
sum(rate(node_disk_writes_completed_total{device!="sr0",device!~"dm.*|loop.*|ram.*"}[1m]))node_disk_writes_completed_total:磁盘累计写入完成的次数(比如写 1 个文件算 1 次 / 几次,看系统统计);rate(xxx[1m]):算「过去 1 分钟内,每秒平均完成的写入次数」(把累计数变成每秒的速率);sum(xxx):把所有非无用磁盘(排除光驱 sr0、虚拟磁盘 dm/loop/ram)的写入次数加起来;device!="sr0"...:过滤掉光驱、虚拟磁盘这些没用的设备,只看真实物理磁盘。
监控指标 PromQL 查询
磁盘读取速率
rate(node_disk_reads_completed_total{device!="sr0", device!="dm-*"}[1m])
磁盘 IO 总操作数
rate(node_disk_io_time_seconds_total{device!="sr0", device!="dm-*"}[1m])
磁盘等待时间
rate(node_disk_io_time_weighted_seconds_total{device!="sr0", device!="dm-*"}[1m])
磁盘吞吐量(写入)
rate(node_disk_written_bytes_total{device!="sr0", device!="dm-*"}[1m])
磁盘吞吐量(读取)
rate(node_disk_read_bytes_total{device!="sr0", device!="dm-*"}[1m])Dashboard 导入
官方 Dashboard 下载地址:https://grafana.com/grafana/dashboards/
搜索 node、server 等关键词
下载完了上传
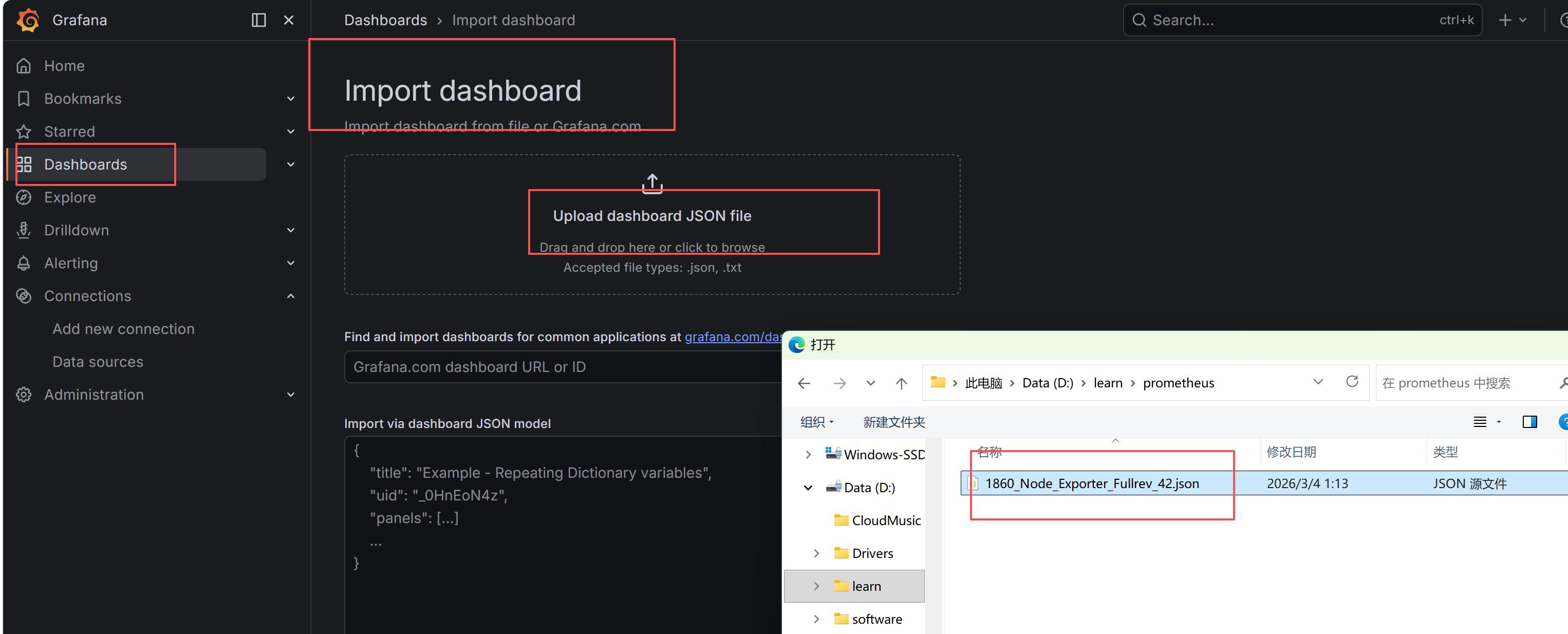
JSON 文件里存了啥?(就是大盘的 "设计图纸")
这个文件里写满了:
-
所有监控面板的位置、大小;
-
每个面板的 PromQL 查询语句;
-
图表样式(颜色、单位、图例位置);
-
时间范围、数据源绑定等所有配置。Grafana 读这个文件,就能 1:1 还原出做好的大盘。
忘记 Grafana 登录密码怎么办?
http://192.168.88.100:3000/login
在 Grafana 所在的服务器上执行以下操作
systemctl stop grafana
/usr/local/grafana/bin/grafana cli --homepath="/usr/local/grafana" admin reset-admin-password admin666
systemctl start grafanaAlertmanager
Alertmanager = 监控的 "报警器 + 通知员" 会主动报警
安装
注意:在 Prometheus 所在的服务器上安装 Alertmanager
# 从 GitHub 官方下载 Alertmanager 0.31.1 版本安装包(告警管理器)
wget https://github.com/prometheus/alertmanager/releases/download/v0.31.1/alertmanager-0.31.1.linux-amd64.tar.gz
# 解压下载好的 Alertmanager 压缩包
tar xvf alertmanager-0.31.1.linux-amd64.tar.gz
# 将解压后的文件夹移动到 /usr/local/alertmanager 目录(统一安装路径)
mv alertmanager-0.31.1.linux-amd64 /export/server/alertmanager
# 将整个目录的所有者和组设置为 prometheus 用户(保证程序有读写权限)
chown -R prometheus:prometheus /export/server/alertmanager
配置服务
# 添加 service 文件
cat > /etc/systemd/system/alertmanager.service <<EOF
[Unit]
Description=AlertManager
Documentation=https://prometheus.io/docs/alerting/latest/overview/
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Restart=on-failure
ExecStart=/export/server/alertmanager/alertmanager \
--config.file=/export/server/alertmanager/alertmanager.yml \
--storage.path=/export/server/alertmanager/data
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl start alertmanager
systemctl enable alertmanager
systemctl status alertmanager
netstat -pantul|grep alertmanager-
9093 (公开端口): 面向用户和外部服务,用于访问Web UI和接收Prometheus推送的告警。
-
9094 (私有端口): 仅用于Alertmanager节点之间的数据同步,对外部工具不可见。因此,用
curl或浏览器直接访问9094被拒绝是完全正常的。
查看
地址