Ultralytics:解读DeformableTransformerDecoderLayer模块
- 前言
- 相关介绍
-
- [Ultralytics 简介](#Ultralytics 简介)
- 前提条件
- 实验环境
- DeformableTransformerDecoderLayer(可变形Transformer解码器层)
- 参考文献
前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)
相关介绍
Ultralytics 简介
Ultralytics 基于多年的计算机视觉和人工智能基础研究,创建了最先进的 (SOTA) YOLO 模型。我们的模型不断更新性能和灵活性,快速、准确且易于使用。他们擅长对象检测、跟踪、实例分割、语义分割、图像分类和姿势估计任务。
前提条件
- 熟悉Python、Pytorch
实验环境
bash
Package Version
------------------------ ------------
Python 3.11.8
absl-py 2.4.0
accelerate 1.13.0
annotated-doc 0.0.4
anyio 4.13.0
calflops 0.3.2
certifi 2026.4.22
charset-normalizer 3.4.7
click 8.3.3
colorama 0.4.6
contourpy 1.3.3
cycler 0.12.1
filelock 3.29.0
flatbuffers 25.12.19
fonttools 4.62.1
fsspec 2026.4.0
grpcio 1.80.0
h11 0.16.0
hf-xet 1.5.0
httpcore 1.0.9
httpx 0.28.1
huggingface_hub 1.14.0
idna 3.15
Jinja2 3.1.6
kiwisolver 1.5.0
Markdown 3.10.2
markdown-it-py 4.2.0
MarkupSafe 3.0.3
matplotlib 3.10.9
mdurl 0.1.2
ml_dtypes 0.5.0
mpmath 1.3.0
networkx 3.6.1
numpy 1.26.4
nvidia-cublas-cu12 12.8.3.14
nvidia-cuda-cupti-cu12 12.8.57
nvidia-cuda-nvrtc-cu12 12.8.61
nvidia-cuda-runtime-cu12 12.8.57
nvidia-cudnn-cu12 9.7.1.26
nvidia-cufft-cu12 11.3.3.41
nvidia-cufile-cu12 1.13.0.11
nvidia-curand-cu12 10.3.9.55
nvidia-cusolver-cu12 11.7.2.55
nvidia-cusparse-cu12 12.5.7.53
nvidia-cusparselt-cu12 0.6.3
nvidia-nccl-cu12 2.26.2
nvidia-nvjitlink-cu12 12.8.61
nvidia-nvtx-cu12 12.8.55
onnx 1.19.0
onnxruntime-gpu 1.26.0
onnxslim 0.1.94
opencv-python 4.6.0.66
packaging 26.2
pillow 12.2.0
pip 24.0
polars 1.40.1
polars-runtime-32 1.40.1
protobuf 7.34.1
psutil 7.2.2
pycocotools 2.0.11
Pygments 2.20.0
pyparsing 3.3.2
python-dateutil 2.9.0.post0
PyYAML 6.0.3
regex 2026.5.9
requests 2.34.1
rich 15.0.0
safetensors 0.7.0
scipy 1.16.0
setuptools 65.5.0
shellingham 1.5.4
six 1.17.0
sympy 1.14.0
tabulate 0.10.0
tensorboard 2.20.0
tensorboard-data-server 0.7.2
tokenizers 0.22.2
torch 2.7.1+cu128
torchaudio 2.7.1+cu128
torchvision 0.22.1+cu128
tqdm 4.67.3
transformers 5.8.1
triton 3.3.1
typer 0.25.1
typing_extensions 4.15.0
ultralytics 8.4.58
ultralytics-thop 2.0.19
urllib3 2.7.0
Werkzeug 3.1.8DeformableTransformerDecoderLayer(可变形Transformer解码器层)
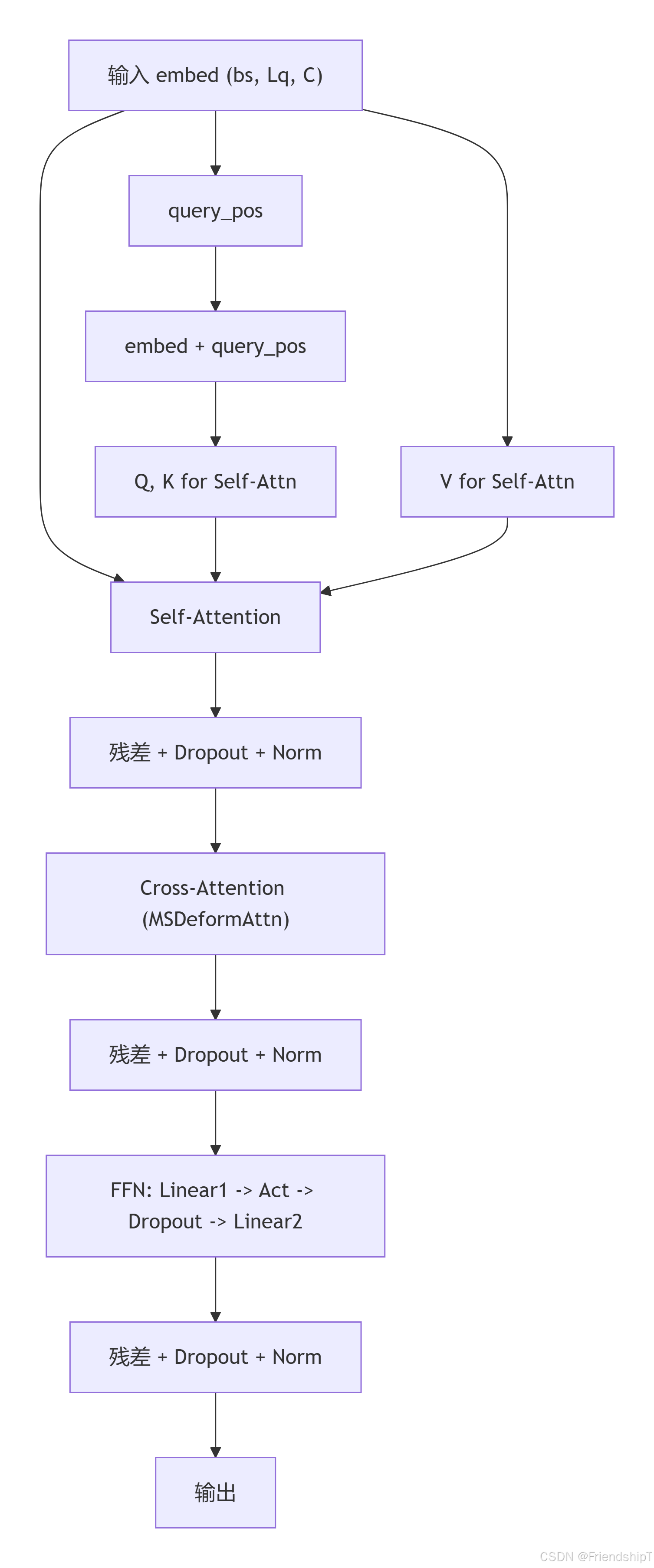
DeformableTransformerDecoderLayer 是 Deformable-DETR 解码器的核心组件,它由 自注意力(Self-Attention) 、多尺度可变形交叉注意力(MSDeformAttn) 和 前馈网络(FFN) 组成。相比标准 Transformer 解码器层,它使用可变形注意力替代了传统的交叉注意力,从而显著降低计算复杂度,并提升了对多尺度特征的聚合能力,尤其适用于目标检测任务。
代码实现
python
import cv2
import math
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
import torch.nn.functional as F
from torch.nn.init import constant_, xavier_uniform_
def multi_scale_deformable_attn_pytorch(
value: torch.Tensor,
value_spatial_shapes: list,
sampling_locations: torch.Tensor,
attention_weights: torch.Tensor,
) -> torch.Tensor:
"""Implement multi-scale deformable attention in PyTorch.
Folds the (num_levels, num_points) axes into a single num_total_points axis so every traced tensor stays at rank <=
5, the maximum rank supported by CoreML's MIL converter. Numerically equivalent to the rank-6 reference
implementation on CUDA and CPU.
Args:
value (torch.Tensor): Value tensor with shape (bs, num_keys, num_heads, embed_dims).
value_spatial_shapes (list): Per-level spatial shapes as [(H_0, W_0), ..., (H_{L-1}, W_{L-1})].
sampling_locations (torch.Tensor): Sampling locations with shape (bs, num_queries, num_heads, num_levels *
num_points, 2).
attention_weights (torch.Tensor): Attention weights with shape (bs, num_queries, num_heads, num_levels *
num_points).
Returns:
(torch.Tensor): Output tensor with shape (bs, num_queries, num_heads * embed_dims).
References:
https://github.com/IDEA-Research/detrex/blob/main/detrex/layers/multi_scale_deform_attn.py
"""
bs, _, num_heads, embed_dims = value.shape
_, num_queries, _, num_total_points, _ = sampling_locations.shape
num_points = num_total_points // len(value_spatial_shapes)
# (bs, num_keys, num_heads, embed_dims) -> tuple of (bs*num_heads, embed_dims, H*W) per level
value_list = value.permute(0, 2, 3, 1).flatten(0, 1).split([h * w for h, w in value_spatial_shapes], dim=-1)
# Map to grid_sample coords in [-1, 1] and split per level: tuple of (bs*num_heads, num_queries, num_points, 2)
sampling_grids = (2 * sampling_locations - 1).permute(0, 2, 1, 3, 4).flatten(0, 1).split(num_points, dim=-2)
sampling_value_list = []
for level, (h, w) in enumerate(value_spatial_shapes):
value_l = value_list[level].reshape(bs * num_heads, embed_dims, h, w)
sampling_value_list.append(
F.grid_sample(value_l, sampling_grids[level], mode="bilinear", padding_mode="zeros", align_corners=False)
)
attention_weights = attention_weights.permute(0, 2, 1, 3).reshape(bs * num_heads, 1, num_queries, num_total_points)
output = (
(torch.cat(sampling_value_list, dim=-1) * attention_weights)
.sum(-1)
.view(bs, num_heads * embed_dims, num_queries)
)
return output.transpose(1, 2).contiguous()
class MSDeformAttn(nn.Module):
"""Multiscale Deformable Attention Module based on Deformable-DETR and PaddleDetection implementations.
This module implements multiscale deformable attention that can attend to features at multiple scales with learnable
sampling locations and attention weights.
Attributes:
im2col_step (int): Step size for im2col operations.
d_model (int): Model dimension.
n_levels (int): Number of feature levels.
n_heads (int): Number of attention heads.
n_points (int): Number of sampling points per attention head per feature level.
sampling_offsets (nn.Linear): Linear layer for generating sampling offsets.
attention_weights (nn.Linear): Linear layer for generating attention weights.
value_proj (nn.Linear): Linear layer for projecting values.
output_proj (nn.Linear): Linear layer for projecting output.
References:
https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/ops/modules/ms_deform_attn.py
"""
def __init__(self, d_model: int = 256, n_levels: int = 4, n_heads: int = 8, n_points: int = 4):
"""Initialize MSDeformAttn with the given parameters.
Args:
d_model (int): Model dimension.
n_levels (int): Number of feature levels.
n_heads (int): Number of attention heads.
n_points (int): Number of sampling points per attention head per feature level.
"""
super().__init__()
if d_model % n_heads != 0:
raise ValueError(f"d_model must be divisible by n_heads, but got {d_model} and {n_heads}")
_d_per_head = d_model // n_heads
# Better to set _d_per_head to a power of 2 which is more efficient in a CUDA implementation
assert _d_per_head * n_heads == d_model, "`d_model` must be divisible by `n_heads`"
self.im2col_step = 64
self.d_model = d_model
self.n_levels = n_levels
self.n_heads = n_heads
self.n_points = n_points
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
self.value_proj = nn.Linear(d_model, d_model)
self.output_proj = nn.Linear(d_model, d_model)
self._reset_parameters()
def _reset_parameters(self):
"""Reset module parameters."""
constant_(self.sampling_offsets.weight.data, 0.0)
thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (
(grid_init / grid_init.abs().max(-1, keepdim=True)[0])
.view(self.n_heads, 1, 1, 2)
.repeat(1, self.n_levels, self.n_points, 1)
)
for i in range(self.n_points):
grid_init[:, :, i, :] *= i + 1
with torch.no_grad():
self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
constant_(self.attention_weights.weight.data, 0.0)
constant_(self.attention_weights.bias.data, 0.0)
xavier_uniform_(self.value_proj.weight.data)
constant_(self.value_proj.bias.data, 0.0)
xavier_uniform_(self.output_proj.weight.data)
constant_(self.output_proj.bias.data, 0.0)
def forward(
self,
query: torch.Tensor,
refer_bbox: torch.Tensor,
value: torch.Tensor,
value_shapes: list,
value_mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""Perform forward pass for multiscale deformable attention.
Args:
query (torch.Tensor): Query tensor with shape [bs, query_length, C].
refer_bbox (torch.Tensor): Reference bounding boxes with shape [bs, query_length, 1, 2 or 4], range in [0,
1], top-left (0,0), bottom-right (1, 1). The size-1 axis broadcasts across n_levels.
value (torch.Tensor): Value tensor with shape [bs, value_length, C].
value_shapes (list): List with shape [n_levels, 2], [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})].
value_mask (torch.Tensor, optional): Mask tensor with shape [bs, value_length], True for padding elements,
False for non-padding elements.
Returns:
(torch.Tensor): Output tensor with shape [bs, Length_{query}, C].
References:
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
"""
bs, len_q = query.shape[:2]
len_v = value.shape[1]
assert sum(s[0] * s[1] for s in value_shapes) == len_v
value = self.value_proj(value)
if value_mask is not None:
value = value.masked_fill(value_mask[..., None], float(0))
value = value.view(bs, len_v, self.n_heads, self.d_model // self.n_heads)
# Fold (n_levels, n_points) into one axis so every traced tensor stays at rank <= 5 (required for CoreML
# export); refer_bbox arrives as (bs, len_q, 1, 2 or 4) and its size-1 axis broadcasts implicitly.
n_total_points = self.n_levels * self.n_points
sampling_offsets = self.sampling_offsets(query).view(bs, len_q, self.n_heads, n_total_points, 2)
attention_weights = self.attention_weights(query).view(bs, len_q, self.n_heads, n_total_points)
attention_weights = F.softmax(attention_weights, -1)
num_points = refer_bbox.shape[-1]
if num_points == 2:
offset_normalizer = torch.as_tensor(value_shapes, dtype=query.dtype, device=query.device).flip(-1)
offset_normalizer = offset_normalizer[:, None, :].expand(-1, self.n_points, -1).reshape(n_total_points, 2)
sampling_locations = refer_bbox[:, :, None, :, :] + sampling_offsets / offset_normalizer
elif num_points == 4:
sampling_locations = (
refer_bbox[:, :, None, :, :2] + sampling_offsets / self.n_points * refer_bbox[:, :, None, :, 2:] * 0.5
)
else:
raise ValueError(f"Last dim of reference_points must be 2 or 4, but got {num_points}.")
output = multi_scale_deformable_attn_pytorch(value, value_shapes, sampling_locations, attention_weights)
return self.output_proj(output)
class DeformableTransformerDecoderLayer(nn.Module):
"""Deformable Transformer Decoder Layer inspired by PaddleDetection and Deformable-DETR implementations.
This class implements a single decoder layer with self-attention, cross-attention using multiscale deformable
attention, and a feedforward network.
Attributes:
self_attn (nn.MultiheadAttention): Self-attention module.
dropout1 (nn.Dropout): Dropout after self-attention.
norm1 (nn.LayerNorm): Layer normalization after self-attention.
cross_attn (MSDeformAttn): Cross-attention module.
dropout2 (nn.Dropout): Dropout after cross-attention.
norm2 (nn.LayerNorm): Layer normalization after cross-attention.
linear1 (nn.Linear): First linear layer in the feedforward network.
act (nn.Module): Activation function.
dropout3 (nn.Dropout): Dropout in the feedforward network.
linear2 (nn.Linear): Second linear layer in the feedforward network.
dropout4 (nn.Dropout): Dropout after the feedforward network.
norm3 (nn.LayerNorm): Layer normalization after the feedforward network.
References:
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/deformable_transformer.py
"""
def __init__(
self,
d_model: int = 256,
n_heads: int = 8,
d_ffn: int = 1024,
dropout: float = 0.0,
act: nn.Module = nn.ReLU(),
n_levels: int = 4,
n_points: int = 4,
):
"""Initialize the DeformableTransformerDecoderLayer with the given parameters.
Args:
d_model (int): Model dimension.
n_heads (int): Number of attention heads.
d_ffn (int): Dimension of the feedforward network.
dropout (float): Dropout probability.
act (nn.Module): Activation function.
n_levels (int): Number of feature levels.
n_points (int): Number of sampling points.
"""
super().__init__()
# Self attention
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# Cross attention
self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout2 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
# FFN
self.linear1 = nn.Linear(d_model, d_ffn)
self.act = act
self.dropout3 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout4 = nn.Dropout(dropout)
self.norm3 = nn.LayerNorm(d_model)
@staticmethod
def with_pos_embed(tensor: torch.Tensor, pos: torch.Tensor | None) -> torch.Tensor:
"""Add positional embeddings to the input tensor, if provided."""
return tensor if pos is None else tensor + pos
def forward_ffn(self, tgt: torch.Tensor) -> torch.Tensor:
"""Perform forward pass through the Feed-Forward Network part of the layer.
Args:
tgt (torch.Tensor): Input tensor.
Returns:
(torch.Tensor): Output tensor after FFN.
"""
tgt2 = self.linear2(self.dropout3(self.act(self.linear1(tgt))))
tgt = tgt + self.dropout4(tgt2)
return self.norm3(tgt)
def forward(
self,
embed: torch.Tensor,
refer_bbox: torch.Tensor,
feats: torch.Tensor,
shapes: list,
padding_mask: torch.Tensor | None = None,
attn_mask: torch.Tensor | None = None,
query_pos: torch.Tensor | None = None,
) -> torch.Tensor:
"""Perform the forward pass through the entire decoder layer.
Args:
embed (torch.Tensor): Input embeddings.
refer_bbox (torch.Tensor): Reference bounding boxes.
feats (torch.Tensor): Feature maps.
shapes (list): Feature shapes.
padding_mask (torch.Tensor, optional): Padding mask.
attn_mask (torch.Tensor, optional): Attention mask.
query_pos (torch.Tensor, optional): Query position embeddings.
Returns:
(torch.Tensor): Output tensor after decoder layer.
"""
# Self attention
q = k = self.with_pos_embed(embed, query_pos)
tgt = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), embed.transpose(0, 1), attn_mask=attn_mask)[
0
].transpose(0, 1)
embed = embed + self.dropout1(tgt)
embed = self.norm1(embed)
# Cross attention
tgt = self.cross_attn(
self.with_pos_embed(embed, query_pos), refer_bbox.unsqueeze(2), feats, shapes, padding_mask
)
embed = embed + self.dropout2(tgt)
embed = self.norm2(embed)
# FFN
return self.forward_ffn(embed)功能
- 自注意力(Self-Attention):对解码器嵌入序列进行自注意力建模,捕获查询之间的依赖关系。
- 多尺度可变形交叉注意力 :利用
MSDeformAttn从多尺度特征图中自适应采样特征,替代标准交叉注意力,提升效率。 - 前馈网络(FFN):通过两层线性变换(中间含激活函数)增强非线性。
- 残差连接与层归一化:每个子层后均有残差连接和 LayerNorm,保证训练稳定性。
初始化参数
| 参数 | 类型 | 说明 |
|---|---|---|
d_model |
int | 模型维度(默认 256) |
n_heads |
int | 注意力头数(默认 8) |
d_ffn |
int | 前馈网络隐藏层维度(默认 1024) |
dropout |
float | Dropout 概率(默认 0.0) |
act |
nn.Module | 激活函数(默认 nn.ReLU()) |
n_levels |
int | 特征金字塔层级数(默认 4) |
n_points |
int | 每个头每层的采样点数(默认 4) |
前向方法
forward(embed, refer_bbox, feats, shapes, padding_mask=None, attn_mask=None, query_pos=None):embed:解码器嵌入([bs, num_queries, d_model])refer_bbox:参考框([bs, num_queries, 2]或[bs, num_queries, 4]),归一化坐标feats:多尺度特征拼接([bs, total_len, d_model])shapes:各层特征图尺寸列表[(H0,W0), ...]padding_mask:填充掩码([bs, total_len])attn_mask:自注意力掩码(可选)query_pos:查询位置编码([bs, num_queries, d_model])
输出 :形状为 [bs, num_queries, d_model] 的张量。
使用示例
python
if __name__ == '__main__':
# 参数设置
bs, num_query, d_model = 2, 100, 256
n_heads, d_ffn, dropout = 8, 1024, 0.1
n_levels, n_points = 4, 4
# 定义多尺度特征尺寸(例如从骨干网络输出的4层特征图)
shapes = [(32, 32), (16, 16), (8, 8), (4, 4)]
total_len = sum(h * w for h, w in shapes)
# 模拟输入
embed = torch.randn(bs, num_query, d_model)
refer_bbox = torch.rand(bs, num_query, 2) # 中心点坐标 [0,1]
feats = torch.randn(bs, total_len, d_model)
query_pos = torch.randn(bs, num_query, d_model)
# 创建解码器层
decoder_layer = DeformableTransformerDecoderLayer(
d_model=d_model,
n_heads=n_heads,
d_ffn=d_ffn,
dropout=dropout,
act=nn.ReLU(),
n_levels=n_levels,
n_points=n_points,
)
# 前向传播
with torch.no_grad():
out = decoder_layer(embed, refer_bbox, feats, shapes, query_pos=query_pos)
print("输入嵌入形状:", embed.shape) # [2, 100, 256]
print("输出形状:", out.shape) # [2, 100, 256]输出示例:
输入嵌入形状: torch.Size([2, 100, 256])
输出形状: torch.Size([2, 100, 256])流程示意图
代码解读
-
__init__:- 自注意力:
nn.MultiheadAttention(默认batch_first=False,输入需为(seq, batch, dim))。 - 交叉注意力:
MSDeformAttn,接受多尺度特征。 - FFN:两层线性层,中间用激活函数和 Dropout。
- 每个子层后添加 Dropout 和 LayerNorm。
- 自注意力:
-
with_pos_embed:静态方法,若位置编码不为空,则加到张量上。 -
forward_ffn:FFN 前向,包含残差和归一化。 -
forward:- 自注意力 :
q = k = embed + query_pos(若提供)。- 因
self_attn要求(seq, batch, dim),需转置:q.transpose(0,1)等。 - 注意力输出经 Dropout 后与原始
embed相加,再 LayerNorm。
- 交叉注意力 :
- 调用
self.cross_attn,传入带位置编码的嵌入、参考框、多尺度特征、形状和掩码。 - 输出经 Dropout 后与
embed相加,再 LayerNorm。
- 调用
- FFN :通过
forward_ffn完成。 - 返回最终输出。
- 自注意力 :
注意事项
- 输入格式 :
embed、feats、query_pos均应为(bs, seq_len, d_model)。refer_bbox最后一维为 2(中心点)或 4(矩形框),范围需在[0,1]。shapes必须与feats中的层级顺序一致,且所有面积之和等于feats的第二维。
- 自注意力格式 :由于
nn.MultiheadAttention默认batch_first=False,在forward中通过转置适应。 - 位置编码 :
query_pos通常由可学习或正弦编码生成,对解码器性能至关重要。 - 掩码 :
padding_mask:屏蔽feats中的无效位置。attn_mask:用于自注意力,例如避免查询看到未来信息(在解码器中不常用)。
- 计算效率 :
MSDeformAttn将总采样点数限制为n_heads * n_levels * n_points,远小于特征图总长度。
优缺点
优点
- 高效交叉注意力:相比标准 Transformer 交叉注意力(O(N²)),可变形注意力只采样少量点,大幅降低计算量。
- 多尺度融合:同时利用多个尺度的特征,提升检测精度。
- 可学习偏移:采样点位置可自适应调整,更好地匹配目标形状。
- 模块化设计:与标准解码器层结构相似,易于替换和扩展。
缺点
- 复杂度:实现较为复杂,涉及网格采样和多尺度拆分,代码维护成本高。
- 对初始化敏感 :采样偏移的初始化(
grid_init)影响收敛,需仔细设计。 - 额外参数 :
sampling_offsets和attention_weights增加了参数量。 - 内存占用 :
grid_sample操作需存储多个中间张量,对显存有较高要求。
在 Deformable-DETR 或 RT-DETR 等模型中,DeformableTransformerDecoderLayer 是解码器的基本构建块。使用时建议根据显存和精度需求调整 n_points 和 n_levels,并配合适当的学习率预热。
参考文献
1 https://docs.ultralytics.com/
2 https://github.com/ultralytics/ultralytics.git
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- YOLOs-CPP:一个免费开源的YOLO全系列C++推理库(以YOLO26为例)
- PaddleOCR:Win10上安装使用PPOCRLabel标注工具
- 目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 图像分割:PyTorch从零开始实现SegFormer语义分割
- 图像超分:使用自己的数据集微调Real-ESRGAN-x4plus进行超分重建
- 图像生成:PyTorch从零开始实现一个简单的扩散模型
- Stable Diffusion:使用自己的数据集微调 Stable Diffusion 3.5 LoRA 文生图模型
- 图像超分:使用自己的数据集微调Real-ESRGAN-x2plus进行超分重建
- Anomalib:使用Anomalib 2.1.0训练自己的数据集进行异常检测
- Anomalib:在Linux服务器上安装使用Anomalib 2.1.0
- 人工智能混合编程实践:C++调用封装好的DLL进行异常检测推理
- 人工智能混合编程实践:C++调用封装好的DLL进行FP16图像超分重建(v3.0)
- 隔离系统Python:源码编译3.11.8到自定义目录(含PGO性能优化)
- 在线机的Python环境迁移到离线机上
- Nuitka 将 Python 脚本封装为 .pyd 或 .so 文件
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)