自定义类作为Key的map编程技法与原理
什么类型可以作为map的Key?
想要明白这一点,首先要知道STL中的map是怎样的一种数据结构。map是基于红黑树实现的数据结构,谈到"红黑树"可能会让不少同学望而却步,红黑树不懂,那二叉搜索树可否理解?如果单单要搞懂这篇博客,知道红黑树也是一种搜索树即可啦!
那么,什么是基于"红黑树"实现呢?其实就是说,它的Key是存储在红黑树上面的!好吧,不说红黑树了,咱们下面就用搜索树去替代这个词吧~
众所周知,搜索树的定义就是:"左子树中的最大值小于根节点、根节点小于右子树的最小值"!如此一来,大家看出搜索树需要能够进行什么操作了吗?没错,就是比较操作!所以,自带重载小于(<)运算符的类型,可以作为map的Key!
普通类型作为map的Key
(一)数值型类型
众所周知,数值型是可以直接根据数值的大小来完成比较的,所以数值型类型可以作为map的Key。
举个例子,记录出现最多的数,比如1 2 2 3 3 3 4 5 6 6 6 7,如果答案不唯一就输出较小的那一个,怎么做呢?
cpp
#include <iostream>
#include <map>
#include <algorithm>
using namespace std;
int main() {
int val, maxCnt = 0, ans;
map<int, int> cnt;
while (cin >> val) {
if (cnt.find(val) == cnt.begin())
cnt[val] = 1;
else
++cnt[val];
}
for (map<int, int>::iterator it = cnt.begin(); cnt.end() != it; ++it) {
if (maxCnt < it->second) {
maxCnt = it->second;
ans = it->first;
}
}
cout << ans << endl;
return 0;
}测试结果:

(二)其他stl容器类型
map经常用来做一些容器的关系映射,例如字符串,这个很常见!还是给一个例子帮助大家理解:
词频统计问题,需要给出若干个单词,来计算它们分别出现的次数。各个单词出现的次数除以总次数称之为词频,请输出词频最大的单词。
输入:
bash
hello
my
father
and
my
mother
hello
my
motherland
and
my
love输出:
bash
and 0.166667
father 0.0833333
hello 0.166667
love 0.0833333
mother 0.0833333
motherland 0.0833333
my 0.333333参考程序如下:
cpp
#include <iostream>
#include <map>
#include <algorithm>
using namespace std;
int main() {
string word;
map<string, int> wordCount;
map<string, double> wordFreq;
int totalCount = 0;
while(getline(cin, word)) {
if (wordCount.find(word) == wordCount.end())
wordCount[word] = 1;
else
++wordCount[word];
++totalCount;
}
for (map<string, int>::iterator it = wordCount.begin(); wordCount.end() != it; ++it) {
wordFreq[it->first] = it->second * 1.0 / totalCount;
}
for (map<string, double>::iterator it = wordFreq.begin(); wordFreq.end() != it; ++it) {
cout << it->first << ' ' << it->second << endl;
}
return 0;
}如何设计自定义的类型,作为map的Key呢?
其实很简单,只需要你的类能够进行比较运算即可!来看看map的源码吧:
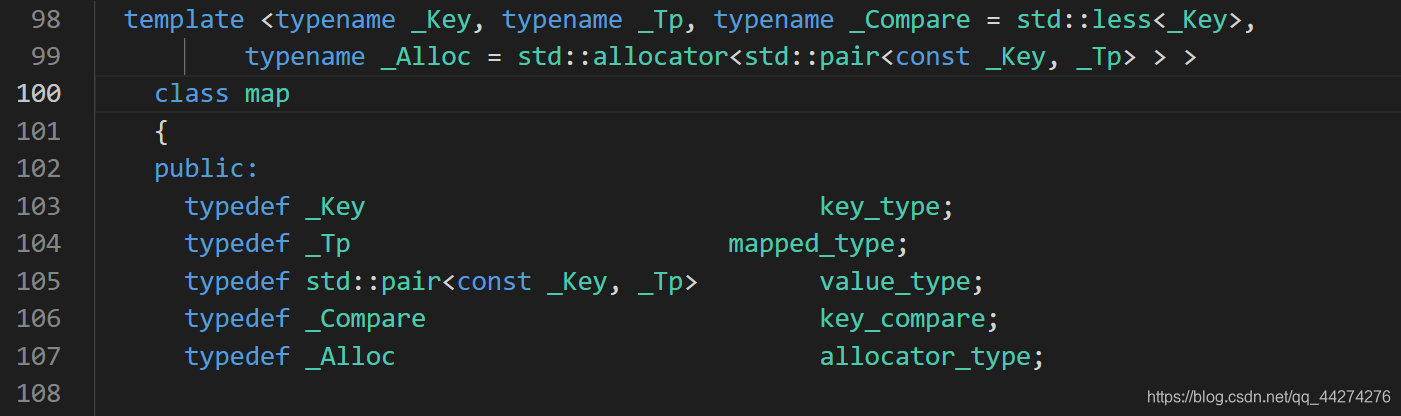
从中可以看到,它需要一个比较器!这个比较器的实现方法就非常多了!什么仿函数、函数指针、lambda表达式、重载小于运算符什么的,都是可以的!我一般喜欢用重载运算符来做,个人比较喜欢!
举个例子:
加入有N个学生,学生有两个属性分别是姓名和考试分数,需要对考试分数进行划分,然后输出学生信息。规定大于等于90分的是A等,大于等于60分的是B等,其余是C等。输出的时候,要求分数高的先输出,如果分数相同,则按照名字的字典序输出。
输入:
bash
5
zuozy 98
zhangwj 67
lifl 86
jiangzl 48
jiangjy 98输出:
bash
Name : jiangjy, score : 98 rank : A
Name : zuozy, score : 98 rank : A
Name : lifl, score : 86 rank : B
Name : zhangwj, score : 67 rank : B
Name : jiangzl, score : 48 rank : C参考程序如下:
cpp
#include <iostream>
#include <map>
#include <string>
#include <algorithm>
using namespace std;
class Student {
friend ostream& operator<<(ostream& out, const Student& res);
private:
string name;
int score;
public:
Student(string name_, int score_) : name(name_), score(score_) {
}
bool operator<(const Student& obj) const {
if (score != obj.score)
return score > obj.score;
return name < obj.name;
}
};
ostream& operator<<(ostream& out, const Student& res) {
out << "Name : " << res.name << ", score : " << res.score;
return out;
}
char getRank(int score) {
if (score >= 90)
return 'A';
else if (score >= 60)
return 'B';
else
return 'C';
}
int main() {
map<Student, char> stuRank;
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
string curName;
int curScore;
cin >> curName >> curScore;
stuRank[Student(curName, curScore)] = getRank(curScore);
}
for (auto it : stuRank) {
cout << it.first << "\trank : " << it.second << endl;
}
return 0;
}方法论:如何理解对小于运算符的重载?
众所周知,在搜索树中,左子树、根节点、右子树是一种升序关系,所以在重载小于运算符的时候,例如上面的程序:
cpp
bool operator<(const Student& obj) const {
if (score != obj.score)
return score > obj.score;
return name < obj.name;
}调用这个运算符重载函数的时候,this是左操作数,也就当前对象,而obj是右操作数,也就是和当前对象来比较的对象。既然搜索树是一种升序的关系,那么肯定最终的结果是this排在obj的前面!!!
那么,可以把重载小于运算符理解为:什么样的对象排在前面!比如我们这里,因为已经知道this是排在前面的了,于是我们要求分数不相等时,分数高的排在前面。如果分数相等,则是名字字典序较小的排在前面!而谁满足这个条件,谁就排在前面!你想想,如果当前的this对象不满足条件会怎样?它会插入到搜索树的另一侧! 因此,可以把逻辑抽象成:
bash
if (obj1 < root)
{
obj1 插入到root的左侧
}
else
{
obj1 插入到root的右侧
}你可以发现,不管怎样,都是让小于运算符为True的对象,排在前面!这样,我相信你就一定理解了如何设计重载运算符,也明白了map的原理!