算法入门(二):前缀和 / 差分数组 (Leetcode 1109 / 560 / 974 /523)
- [前缀和 / 差分数组](#前缀和 / 差分数组)
- [1109. 航班预订统计](#1109. 航班预订统计)
- [560. 和为K的子数组](#560. 和为K的子数组)
- [974. 和可被K整除的子数组](#974. 和可被K整除的子数组)
- [523. 连续的子数组和](#523. 连续的子数组和)
前缀和 / 差分数组
| 概念 | 核心操作 | 数学表达 |
|---|---|---|
| 前缀和 | 前面所有元素的和 | prefixi = arr0 + ... + arri |
| 差分数组 | 相邻元素的差 | diffi = arri - arri-1 |
前缀和 和 差分数组,两者是一对互逆操作,参考以下例子:
cpp
// 前缀和的差分 = 原数组
原数组 arr = [1, 3, 2, 5, 4]
前缀和 pref = [1, 4, 6, 11, 15]
对 pref 求差分 = [1, 3, 2, 5, 4] = 原数组 arr
// 差分数组的前缀和 = 原数组
原数组 arr = [1, 3, 2, 5, 4]
差分数组 diff = [1, 2, -1, 3, -1]
对 diff 求前缀和 = [1, 3, 2, 5, 4] = 原数组 arr 理解整个循环:原数组 → 求差分 → 差分数组 → 求前缀和 → 原数组
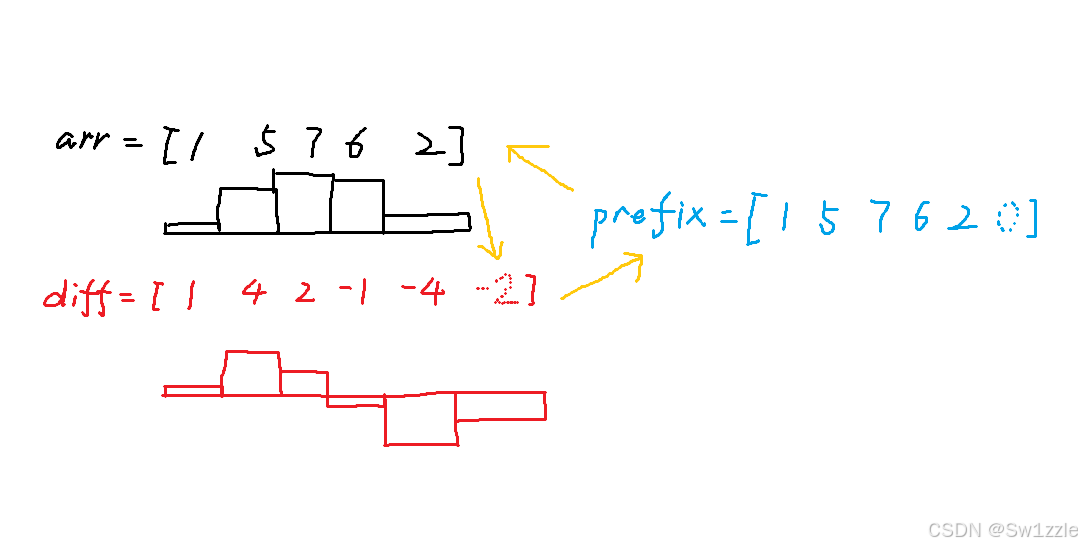
我们从这个循环可以有以下感受:
- 从第二个数开始,也就是5,包括随后的7和6,差分数组只需要在第二个数抬高4格,而后面的数只需要在小范围波动。
- 于是我们可以思考:如果想要把 5 7 6 同时抬高3,对arr应该怎么操作?对diff只需要什么操作?
- 这个问题的答案也就是为什么要使用差分,而不是使用暴力求和。
1109. 航班预订统计
这道题是前缀和 / 差分的入门题目,首先我们来体会一下暴力法:
cpp
vector<int> corpFlightBookings(vector<vector<int>>& bookings, int n) {
vector<int> res(n);
for(int i = 0;i<bookings.size();i++){
//注意数组的下标是从0开始的,但是bookings数组的航班信息是从1开始的!
for(int j = bookings[i][0]-1;j<bookings[i][1];j++){
res[j] += bookings[i][2];
}
}
return res;
}
细心一些,注意下标,还是能通过的。
这篇文章毕竟是讲前缀和 / 差分,所以尝试以下优化:
cpp
class Solution {
public:
vector<int> corpFlightBookings(vector<vector<int>>& bookings, int n) {
vector<int> diff(n + 1, 0);
for (auto& booking : bookings) {
int l = booking[0] - 1;
int r = booking[1] - 1;
int seats = booking[2];
diff[l] += seats;
diff[r + 1] -= seats; // r+1 最大为 n,diff 大小是 n+1,安全
}
vector<int> res(n);
res[0] = diff[0];
for (int i = 1; i < n; i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
};对于diffl += seats这一行,可以理解为把左边界统一抬高;
对于diffr + 1 -= seats这一行,可以理解为把右边界统一降下;
这样就得到了差分数组。
再根据公式diffi = arri - arri-1,做逆运算前缀和,得到原数组。注意从1开始。
560. 和为K的子数组
同样的,我们首先尝试暴力双循环:
cpp
int subarraySum(vector<int>& nums, int k) {
//1 . 求前缀和
vector<int> prefix(nums.size());
prefix[0] = nums[0];
for(int i = 1;i<nums.size();i++){
prefix[i] = prefix[i-1]+nums[i];
}
int res = 0;
int n = nums.size();
//2 .计算前缀和差为k的次数
for(int i = 0;i<n;i++){
if(prefix[i] == k) res++;
for(int j = i+1;j<n;j++){
if(prefix[j] - prefix[i] == k) res++;
}
}
return res;
}可以看到,子数组之和=k被转换为了前缀和之差=k,时间复杂度为O(n^2)。
如何优化这个部分呢?
在内循环里,j反复+1,在进行prefixj-prefixi == k的判断,尝试移项:
得到 prefixi = prefixj-k 。
这样的改动有什么意义呢?观察prefixj - k ,这一步只需要一个循环。
也就是说,如果把遍历prefixi的时间转换为存储prefixi的空间,时间复杂度就能从O(n^2)变为O(n)!
并且能观察到,j是在i之后的,也就是说,如果在j之前添加一个位置,并且用prefixj去和之前的i位置的前缀和对比,就可以解决了。
所以我们需要一个hashMap,C++之中是unordered_map。他代表前缀和出现的次数。
我们来整理一下思路形成伪代码:
- 设置哈希表,并把hash0设置为1, 因为0出现过一次,后面任何一个前缀和取差的时候都需要0
- 设置一个循环
- 循环中有两件事,一是把前缀和存储hash,hash prefix\[j ]++;二是判断hash prefix\[j - k ]是否存在。
- 仔细思考,这两件事的前后顺序。如果先放入前缀和,k=0的情况下,hash前缀和 -0 是会等于1的,与前缀和之差为0相悖,所以顺序应该是先判断,再存入
cpp
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
vector<int> prefix(nums.size());
prefix[0] = nums[0];
for(int i = 1;i<nums.size();i++){
prefix[i] = prefix[i-1]+nums[i];
}
int res = 0;
//哈希表的 key = 前缀和的值,value = 这个值出现过多少次
unordered_map<int, int> cnt;
cnt[0] = 1;
for(int num:prefix){
res = res + cnt[num - k];
cnt[num]++;
}
return res;
}
};974. 和可被K整除的子数组
cpp
class Solution {
public:
int subarraysDivByK(vector<int>& nums, int k) {
int n = nums.size();
//1. 求前缀和
vector<int> prefix(n);
prefix[0] = nums[0];
for(int i = 1; i<n;i++){
prefix[i] = prefix[i-1] + nums[i];
}
//2. 哈希表
unordered_map<int,int> cnt;
cnt[0] = 1;
//3. 计算出现 可以整除k的 结果
int res = 0;
for(auto num:prefix){
int r = (num % k + k)% k;
res += cnt[r];
cnt[r]++;
}
return res;
}
};523. 连续的子数组和
cpp
class Solution {
public:
bool checkSubarraySum(vector<int>& nums, int k) {
int n = nums.size();
vector<long long > prefix(n);
prefix[0] = nums[0];
for (int i = 1; i < n; i++) {
prefix[i] = prefix[i - 1] + nums[i];
}
unordered_map<long long, int> cnt;
cnt[0] = -1;
for (int j = 0; j < n; j++) {
long long r = (prefix[j] % k + k) % k;
if (cnt.find(r) != cnt.end()) {
if (j - cnt[r] >= 2) {
return true;
}
}else{
cnt[r] = j;
}
}
return false;
}
};