第四章讲的都是时间的协调------程序/线程先运行谁?冲突怎么办?
这一节讲空间的协调------程序放在哪里,放不下怎么办?
程序如何布局,动态,隔离,虚拟内存,交换算法
内存的分配
程序内的分配
虚拟地址空间布局
-
逻辑布局(设计):
- 代码段(Code):存放指令。
- 数据段(Data):存放全局变量等。
- 堆与栈(Heap/Stack):这是动态变化的区域。
-
运行时布局(实现) :
当程序真正跑起来,操作系统会给它分配实际的虚拟地址。
- 只读段(.text/.rodata) :放在高地址,比如
0x08000000开始。 - 读写段(.rwdata/.bss):放在中间。
- 堆(.heap) :这是最大的段 ,也是我们要讲的主角。程序运行中所有的动态内存申请(比如
malloc),都是从这里切出来的。 - 栈(.stack):通常比较小,MB量级,用来存函数调用的局部变量。
- 只读段(.text/.rodata) :放在高地址,比如
为什么要"动态"分配?------对抗不确定性
- 功能的不确定性:用户可能只用软件的10%功能,如果一开始就把100%的内存分给它,剩下90%就浪费了。
- 阶段的不确定性:同一个功能,在不同阶段需要的内存也不一样。
- 对象的不确定性:处理100条数据和100万条数据,占用的空间天差地别。
结论 :必须按需分配 ,这就是动态内存分配存在的意义。
如何评价"在线算法"?------竞争比
理想情况(离线分配):假设可以预知未来,得到的最优方案
现实情况(在线分配):无法预知未来,当下能实现的最优方案
我们希望分配的堆正好满足需求。
竞争比 = S_ALG / S_OPT=在线空间/离线空间
如何分配内存
流程:分配-使用-释放
固定分区法------拿最大需求分配
内部碎片:要1MB,给100MB,剩下的99MB就白白浪费了,这就是内部碎片
多固定块法------桶分配
做不同大小的块池子。比如一个池子装1MB的块,一个池子装100MB的块。
不知道程序到底需要多少个1MB,多少个100MB。
外部碎片:如果100MB的池子空了,哪怕1MB的池子堆成山,你也无法满足100MB的请求。这叫外部碎片------内存总量够,但因为不连续、不匹配,就是没法用。
动态分区法
按需求的最大公约数切割内存,这样不会有内部碎片,但是会产生外部碎片
首次、最好、最坏适配
首次适配法(First-Fit)
逻辑:从头开始找,找到第一个能装下的空闲区就分配。
优点:简单、快。
缺点:容易在内存开头留下很多小碎片,而且不保留大块内存给未来的大请求。
最好适配法(Best-Fit)
逻辑:遍历所有空闲区,找那个"最紧凑"、最刚好能装下的。
优点:看起来最节省,试图保留大块内存。
缺点:会产生大量无法利用的极小碎片("劫小济大"),而且遍历所有空闲区非常慢(O(n))。
最坏适配法(Worst-Fit)
逻辑:反其道而行之,找最大的空闲区来分配。
优点:试图避免产生极小碎片,保留中等大小的块。
缺点:很快就把大块内存消耗光了,未来遇到大请求时就傻眼了("劫大济小")。
简单分配策略的共性问题
- 遍历开销大:每次分配都要遍历空闲列表,程序跑久了,列表越来越长,速度越来越慢。
- 策略单一:把所有请求混在一起分配,大小请求互相干扰。
- 粒度问题:太粗有内部碎片,太细有管理开销。
程序间的分配
- 虚张声势(Over-allocation):很多程序为了保险,会申请比实际需求大得多的内存。
- 心中无数(Unknown Size):有些程序(比如处理大数据的AI模型)根本不知道自己最后需要多少内存。给少了,程序会崩溃;给多了,又是浪费。
☆ 考点 内外部碎片
内部碎片(分多了用不完) 外部碎片(太碎了拼不起来)
程序内内部碎片
定义 :已经分配给程序的内存块,但程序实际上用不到,被"浪费"在块内部的空间。
程序内外部碎片
定义 :系统中空闲的内存满足需求,但由于内存不连续,无法满足大块连续内存的请求。
程序间的内部碎片
- 定义 :指操作系统已经分配给某个程序,但该程序逻辑上无法利用的内存。
程序间的外部碎片
- 定义:操作系统手里还有空闲内存,但因为这些内存不连续,无法满足某个程序的大块连续内存请求。
进程
权能:由管理者下发的许可证
保护域 :许可证限制的空间,赋予进程合法操作资源,限制非法操作资源,实现隔离。
类比线程,是空间的分配对象。
进程是---种特殊的保护域,其特殊在它是常见保护域中最小的---种。
进程控制块(PCB)
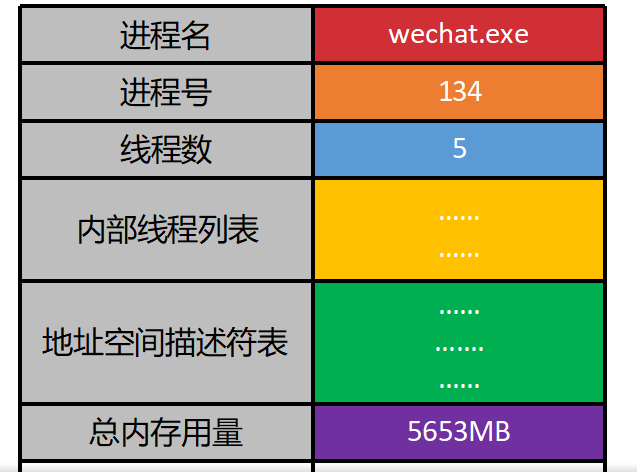
☆ 考点 静态与动态------可执行文件与进程
一句话记住:exe 是硬盘上的 "程序文件",进程是内存里 "正在跑的程序实例"。
核心区别
-
存在位置不同
- exe:硬盘 / 磁盘上的静态文件(.exe)
- 进程:内存中运行的动态实体
-
状态不同
- exe:静止的代码和数据
- 进程:活动的,占用 CPU、内存、句柄等资源
-
数量关系
- 一个 exe 可以启动多个进程(比如开多个微信、多个浏览器)
- 一个进程 只对应一个正在运行的程序
-
生命周期
-
exe:长期存在,删了才没
-
进程:启动才有,关闭就消失
-
进程与线程与指令流
线程通过在进程里运行, 将CPU时间 转化为对地址空间 的---个访问操作次序 ,从而实现应用程序的功能。
进程是一个资源空间,不具备执行能力,运行的是进程中线程中的指令流。
进程可以不包含任何线程,而是等线程迁移进来
线程在进程中运行,且可以在多个进程中穿行,共享---份时间预算
关系
-
一对一关系(最常见):
- 模式:一个进程对应一个线程。
- 本质:一个内存空间对应一个CPU执行流。
-
一对多关系(现代主流):
- 模式:一个进程对应多个线程(多线程进程)
- 本质:一堆程序指令流在同一块内存上用,这样非常方便快速访存。
如何实现一个进程------内存隔离
【对应第三章 内存管理的进化史------减少内存浪费】
隔离的作用 :操作系统给每个程序提供一个独立的虚拟地址空间,也就是进程,防止交叉访问。
权能:由管理者下发的许可证
保护域 :许可证限制的权限空间,赋予进程合法操作资源,限制非法操作资源,实现隔离。
进程是---种特殊的保护域,其特殊在它是常见保护域中最小的---种。
如何实现内存隔离
分段
把程序的逻辑地址转换成物理地址,由段式内存管理单元(S-MMU)维护一个段表。
核心逻辑:基址 + 偏移
- 段号:告诉MMU这是哪个段(代码段?数据段?)。
- 段基址:段在物理内存里的起始位置。
- 虚拟地址(偏移量):在这个段里跑了多远。
- 公式:物理地址 = 段基址 + 偏移量。
流程:
每次访问内存,它都要做三次检查:
- 段存在吗?(查段号有没有)
- 越界了吗?(偏移量有没有超过段长度?)
- 权限对吗?
段表放哪里?
放CPU寄存器:
提供一组寄存器存放段表,进程切换时需要取出新进程的段表,拷贝到寄存器中。
优点:无需访问外部
缺点:无法支持比寄存器组数量更多的段
放内存:
CPU里只放一个指针指向它
优点:这样能支持无限的段
缺点:要访问两次内存,首先访问段表,再访问内存本身。
用快表缓存:
工作集:程序在一段时间内,频繁访问的内存
☆ 考点 局部性:
- 时间局部性 :如果你访问了一个数据,大概率过一会儿还会访问它。
- 空间局部性 :如果你访问了一个数据,大概率接下来会访问它旁边的数据。
工作流程:
- CPU给出一个虚拟地址。
- 查快表 :快表里有没有这个段号?
- 命中:直接拿到物理基址
- 没命中:去内存里查段表,查到了之后,顺便把这个条目"复制"一份到快表里,以备下次使用。
怎么把数据填进快表?
软件填充
产生内存管理异常,进入处理程序后,操作系统读取段表,将段描述符 填充到CPU段寄存器组中
- 优点:灵活。段表长什么样,替换策略自定义。
- 缺点 :太慢! 每次触发"异常",从用户态切到内核态,开销大。
硬件填充
CPU内置专门电路表查找器。硬件发现快表没数据,自己去内存里查,填进去
- 优点 :极快。纯硬件电路操作,没有软件切换的开销。
- 缺点:不灵活。段表的格式被硬件写死了。
快表的维护与副作用
清空TLB Flush
切换线程 重新填充
删除TLB Shootdown
不清空 仅删一条
锁定TLB Lockdown
硬件填充下由软件填充并锁定的表项。这些表项会无条件保留
替换
分页
再把内存切为4MB的小块,减少碎片。
把程序的逻辑地址转换成物理地址,由页式内存管理单元(P-MMU)维护一个页表。
核心逻辑:基址 + 偏移
- 段号:告诉MMU这是哪个页(代码段?数据段?)。
- 段基址:段在物理内存里的起始位置。
- 虚拟地址(偏移量):在这个段里跑了多远。
- 公式:物理地址 = 段基址 + 偏移量。
流程:
每次访问内存,它都要做三次检查:
- 段存在吗?(查段号有没有)
- 越界了吗?(偏移量有没有超过段长度?)
- 权限对吗?
但是这样页表就太大了。
页表很大怎么办?如何组织
页表是稀疏的
我们需要一种特殊的数据结构来存储,使得复杂度O(1)
基数树/桶排序
原理:
- 把虚拟地址切分成几段(比如一级页号、二级页号、页内偏移)。
- 一级页表(母桶):只负责索引"区域"。如果某个区域完全没用,一级页表里对应的项就是空的,根本不需要创建二级页表。
- 二级页表(子桶):只有在真正用到某个区域时,才分配二级页表。
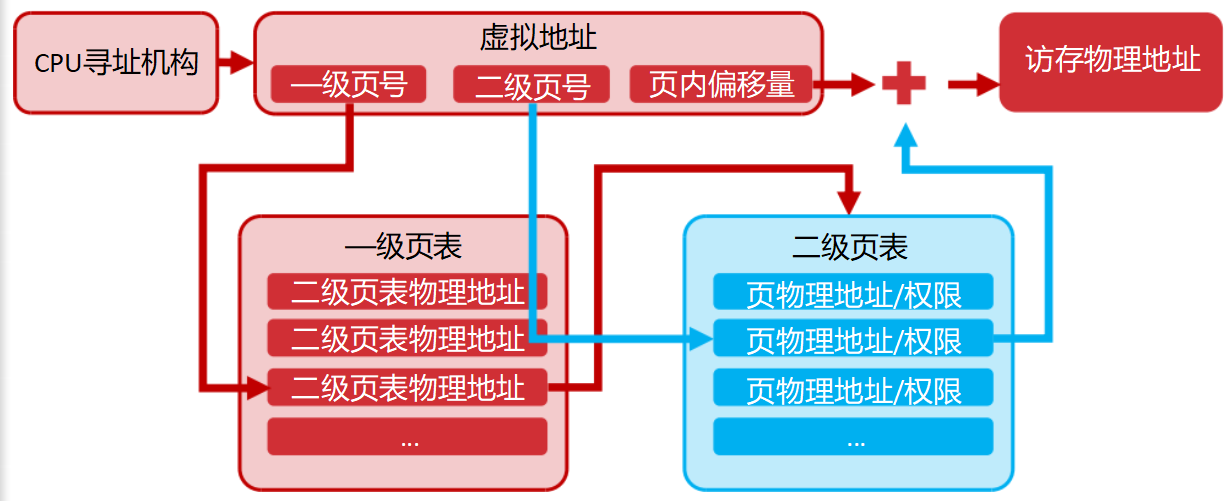
外部碎片消失,但是内部碎片变多
Q:什么是超级页,为什么要引入超级页?
为了兼顾两者,现代CPU支持"超级页"(比如2MB或1GB的大页),专门给大块连续内存使用,既减少了页表项,又提高了TLB效率。
单层存储模型
计算机上所有的存储器都被抽象成一种逻辑模型。
数据存储的逻辑模型向最上层的存储器靠近;数据存储的物理特性向最下层的存储器靠近
存哪由OS决定
分页解决了内存"怎么放"(碎片)的问题,但没有解决内存"不够放"(容量)的问题。
☆ 考点 请求分页的流程
物理内存有限。当所有物理页占满,而新页面又需要进来时,该怎么办?
页也具有时刻局部性。
为什么要用请求分页:1. 突破物理内存的"硬限制"(容量问题)
在普通的分页管理(也叫纯分页)中,虽然内存被切成了固定大小的页,但依然要求程序在运行前,必须把所有页面一次性全部装
入物理内存。
- 痛点:假设你的物理内存只有 8GB,但你突然想玩一个 20GB 的 3A 大作,或者同时打开几十个网页和大型软件。在纯分页机制下,因为 20GB > 8GB,程序根本启动不了,系统会直接报错"内存不足"。
- 请求分页的解法 :它引入了虚拟内存 的概念。系统不再强求一次性把 20GB 全塞进 8GB 的内存里,而是**"按需加载"**(懒加载)。程序启动时只把当前要用的几页代码(比如主界面)加载进来,剩下的 99% 先留在硬盘上。等你真正玩到某个关卡时,再把那个关卡的数据页从硬盘"请求"调入内存。
缺页异常的处理:
0.懒加载:操作系统在启动程序时,根本不把代码全读进内存。页表里先留空,标记为"不在内存"。
1.触发缺页异常,暂停执行
2.处理缺页异常,从用户态进入内核态
3.写回换出页,如果满了要腾出空间,如果没被修改过就扔掉,否则要存入
4.读入换入页:从外存读入刚刚请求的页
5.修改页表,将存在页设为1
6.重新执行,PC不变
怎么做?
☆ 考点 页面置换算法
理想算法:最长前向距离(LFD/OPT) 最久要用
替换"最晚才会被再次用到"的页面
现实算法
-
先进先出(FIFO):
- 逻辑:谁先进来的,就先踢谁。
- 缺陷:太傻了。最早进来的可能是主函数代码,一直被用到,结果被踢出去了。
-
最近最少使用(LRU):最久未用
- 逻辑:利用"时间局部性",认为"过去很久没用的,未来大概率也不用"。踢掉那个"最久没被访问"的页面。
- 优点:比FIFO聪明,符合程序运行规律。
- 缺点:硬件实现成本高(需要记录每个页面的访问时间戳)。
-
最不频繁使用(LFU):
- 逻辑:踢掉那个"访问次数最少"的页面。
- 缺陷:有些页面刚开始访问频繁,后来不用了,但计数器很高,导致它赖在内存里不走。
内存管理的"终极形态"------内存映射
讲完了怎么管内存,这几页提出了一个更宏大的愿景:消除内存和硬盘的界限。
- 直接把硬盘上的文件 映射到进程的虚拟地址空间
- 怎么做 :
- 进程直接对着一段虚拟内存地址进行读写。
- 硬件发现这页不在内存(缺页),触发中断。
- 操作系统一看,哎,这页对应的是硬盘上的文件啊,于是直接从硬盘把文件内容读入内存。
- 结果:程序员感觉像是在操作内存,实际上是在操作文件!
好处
- 高效:不用多次拷贝。
- 共享:多个进程可以映射同一个文件,共享内存。
考点☆ 具体怎么做?
硬件机制:
缺页异常
当页表中没有某个页时,产生操作系统可截获并处理的异常。
访问位****A
当某个页被访问,其页表的访问位会被硬件置位。
脏位****D
当某个页被实际写入(内容遭修改),其页表的脏位会被硬件置位。
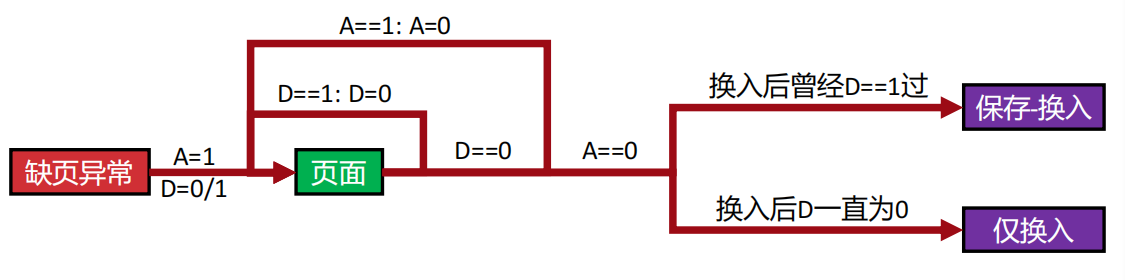
给 FIFO 加点"智慧"------利用访问位 二次机会法CLOCK法

淘汰页面时找到一个访问位A不为0的页面,其余A=1都置为0.进入下一轮逃杀
利用脏位
修改过的页面需要保存再换入,时间长

改进的clock算法 三次机会法
先清除D脏位再清除A访问位
承接上文:
上一页我们讲到了 CLOCK 算法以及通过访问位 A 和脏位 D 来优化置换。
本部分核心:
但在真实的操作系统(如 Linux)中,内存管理远比单纯的 CLOCK 算法复杂。因为内存里的页面不仅仅是"程序的数据",还有"共享的库"、"刚退出的缓存"、"文件映射"等。
这几页 PPT 将告诉你:操作系统是如何利用"共享"和"缓存"来减少缺页,又是如何利用"多队列"来给不同类型的页面定优先级的。
这组 PPT 的逻辑非常连贯,它将我们之前讨论的**"页面置换算法"** (怎么踢人)进一步升维,结合了**"页面共享"** (怎么省人)和**"页面缓存"**(怎么留人),最终形成了一个现代操作系统复杂的内存管理策略。
以下是这几页 PPT 的串联讲解,逻辑上承接了之前的"页面置换算法":
逻辑衔接:从"单一算法"到"复杂生态"
承接上文:
上一页我们讲到了 CLOCK 算法(二次机会法)以及通过访问位 A 和脏位 D 来优化置换。
本部分核心:
但在真实的操作系统(如 Linux)中,内存管理远比单纯的 CLOCK 算法复杂。因为内存里的页面不仅仅是"程序的数据",还有"共享的库"、"刚退出的缓存"、"文件映射"等。
这几页 PPT 将告诉你:操作系统是如何利用"共享"和"缓存"来减少缺页,又是如何利用"多队列"来给不同类型的页面定优先级的。
第一页:省钱(共享)与 捡漏(缓存)
核心逻辑:
在讨论怎么"踢"页面之前,先讨论怎么少踢 甚至不踢。
页面共享
- 原理 :既然很多程序都用同样的代码,而且是只读的,无需在内存中存储多次
- 做法 :让这些进程的页表指向同一块物理内存。
- 好处:极大地节省了物理内存。
页面缓存
- 原理:当一个进程退出了,它占用的内存(特别是那些加载好的动态库)通常不会立刻被清空。
- 做法:操作系统把这些页面标记为"备用"或"缓存"。如果过一会儿又启动了一个新进程(或者重启了刚才那个进程),发现需要的库已经在缓存里了,直接拿来用,连硬盘都不用读了。
- 好处 :极大地提高了启动速度,减少了强制缺页异常。
第二页:置换策略的进化------谁该先走?
核心逻辑:
有了共享和缓存,置换算法就不能"一视同仁"了。
- 直觉 :
- 共享页面 (比如系统库):非常重要,一旦被踢出,所有用到它的进程都会缺页,代价极大。所以尽量不踢。
- 缓存页面 (比如刚退出的程序):本来就是闲置资源,没人引用了。所以优先踢它。
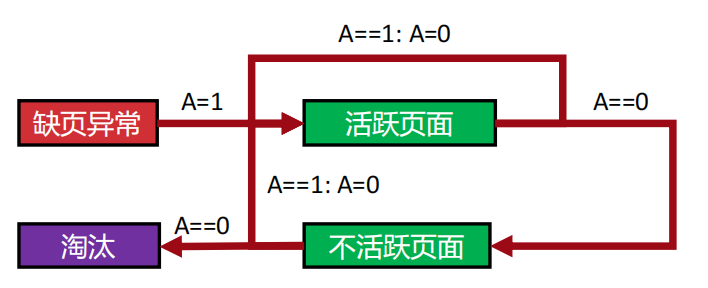
第三页:双队列 PLRU------给页面分等级
核心逻辑:
为了实现上面的策略,Linux 使用了**双队列(甚至多队列)**机制。
- 机制 :
- 活跃队列:存放正在频繁使用的页面。
- 不活跃队列:存放偶尔使用或暂时不用的页面。
- 流程 :
- 新进来的页面先放入活跃队列。
- 如果页面在活跃队列里很久没被访问(A位=0),它会被降级到不活跃队列。
- 置换发生时,只在不活跃队列里找受害者。
- 如果不活跃队列里的页面突然又被访问了,它会被立刻提拔回活跃队列(这就避免了频繁置换抖动)。
第四页:多级反馈队列------Linux 的真实面貌
核心逻辑:
Linux 的内核代码(vmscan.c)比双队列更细致,它维护了一个分层级的页面链表。
- 分层逻辑 :
- 最活跃页面(比如正在运行的程序代码)。
- 比较活跃页面。
- 不甚活跃页面(比如文件映射)。
- 最不活跃页面(比如无用的缓存)。
- 动态调整:页面会根据访问频率在这些队列之间"升级"或"降级"。
- 目的 :确保共享页面 和关键代码 永远留在最上面的队列,而缓存页面永远在最下面等着被回收。
第五页:Swap 文件 vs 分区 & 内存压缩
核心逻辑:
当页面真的被踢出内存后,它们去哪了?
存放位置
- Windows :使用分页文件,即在文件系统里建一个大文件。优点是灵活(想多大建多大),缺点是文件系统本身有开销,稍慢。
- Linux :传统上使用交换分区,即硬盘上专门划出一块连续区域。优点是直接读写磁盘,速度快;缺点是不灵活(分区大小固定)。
内存压缩
- 新思路:有些页面数据重复性很高(比如全是 0,或者全是某种结构)。
- 做法 :与其把页面写到慢速的硬盘,不如在内存里把它压缩一下存着。
- 优势:CPU 解压速度 >>> 硬盘读取速度。用 CPU 换 I/O,整体性能反而提升了。
内存映射设备
硬件设备也可以被映射到内存地址。访问这些地址就像访问内存一样。
页面置换的其他内容
Belady异常:
在某些资源分配策略下,增加资源总量反而导致性能下降和效率降低的现象。
在这里是指, 对于某些替换算法, 允许的物理页数量越大,缺页率反而升高。
栈式性质:LFD、 LRU都含有"最"字, 满足;FIFO则没有这个性质。
抖动: 分配给进程的物理页数少于其工作集大小时,进程会频繁地发生缺页中断
分配策略的动态性
- 静态分配 一个进程的页数量可以是静态决定的也可以是动态调整的。如果工作集的大小已知,只要将页数量设置为那个固定值就好了;如果出现阶段性的需求,就需要动态决定进程需要多少页框。
- 动态分配
置换策略的全局性
- 局部置换:只在自己进程的页面里踢人。
- 全局置换:可以从任何进程的页面里踢人。
进程是什么------用于隔离空间的东西
如何实现一个进程------内存隔离
如何内存隔离------分段分页
有什么后果------页表太大------用基数树和桶排序
解决了如何存,要解决如何加载------请求分页
如何实现请求分页------懒加载-触发中断暂停执行-执行中断服务程序进入内核态-根据算法换出页,如果有修改需要修改外存对应的副本,否则直接丢弃-换入所需页-将页表对应项改为1-重新执行PC不变
具体算法------LFD 最久要用 LFU最低频次 LRU最久没用 FIFO
balady异常 资源阅读 性能越拉
抖动 分配的页不够
栈式性质 LFU LRU
分配动态性 进程的页数量可以是动态的,如果不同阶段有不同需求就调整
置换局部性 在哪里换
内存映射文件 用请求分页技术,将要访问的外存块通过缺页中断装入 访问外存和访问内存一样
- 分段解决了隔离,但带来了外部碎片。
- 分页通过"固定大小块"彻底消灭了外部碎片。
- 页表膨胀是分页的副作用。
- **基数树(多级页表)**利用地址空间的稀疏性,完美解决了页表存储问题。
- TLB依然是加速地址转换的核心硬件。
进程的具体实现
系统中的进程总览:按来源划分
按照操作系统中的进程的来源,大致可以将它们分为如下三类

按照操作系统中的进程的特权,大致可以将它们分为如下两类。


这几页PPT把我们带入了内存管理的**"硬件落地"**环节。
刚才我们讲完了纯理论的"分段"、"分页"和"请求分页",但操作系统最终是要跑在CPU上的。x86架构(也就是我们电脑里最常用的CPU)是如何把这些理论变成现实的?这中间经历了从32位到64位的巨大跨越。
x86-32的"缝合怪"时代------段页式管理
- 为了兼容:不能把老的分段机制删了,否则以前的DOS程序就跑不了了。
- 结果 :段页式管理 。
- 先分段:逻辑地址通过段表转换成"线性地址"。
- 后分页:线性地址再通过页表转换成"物理地址"。
x86-64的"拨乱反正"------长模式
- 长模式:这是64位CPU的工作模式。
- 废除分段 :在长模式下,分段机制被基本禁用 。段基址强制为0,段长强制无限大。
- 结果 :
有效地址 = 线性地址。分段这一步被直接绕过了!
- 结果 :
- 扩展分页 :地址变长了,页表结构也变复杂了。
- 多级页表 :32位只需要2级页表,64位因为地址空间太大,需要4级页表(PML4 -> PDPT -> PD -> PT)甚至5级。
x86-64的"潜规则"------规范地址
虽然64位理论上有 2^64的地址空间,用不到。x86-64架构制定了一个**"规范地址"**的标准。
- 地址空间被劈成两半 :
- 低地址(用户空间) :从
0x0000...开始,最高位是0。这是给应用程序用的。 - 高地址(内核空间) :从
0xFFFF...开始,最高位是1。这是给操作系统内核用的。 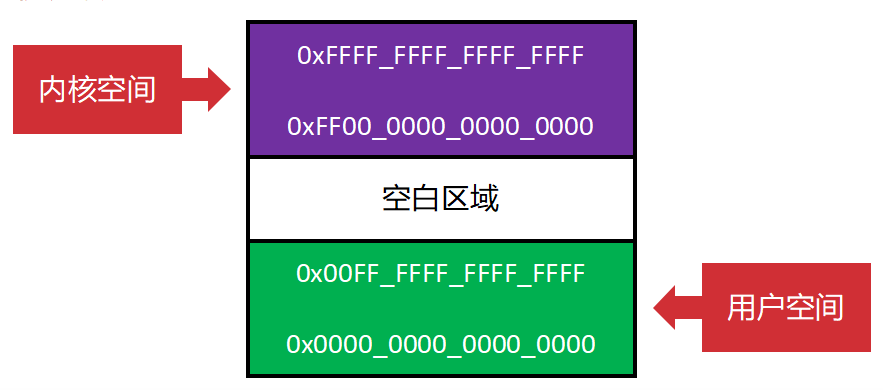
- 低地址(用户空间) :从
这样做的好处:
- 硬件检查简单:CPU只需要检查最高几位就能判断地址是否合法,不需要查页表,速度极快。
- 安全隔离:用户程序只能用低地址,内核用高地址,天然隔离。
第一幕:总开关与导航仪(CR0, CR3, CR4)
在操作系统启动时,CPU需要知道该用什么模式工作。这些设置都写在控制寄存器里。
CR0:最基础的总开关
- PE位(第0位):开启保护模式。这是现代操作系统的门槛,只有开了它,才有用户态和内核态之分。
- PG位(第31位):开启分页机制。如果不开这个,CPU就只能分段,不能分页。
- 逻辑:先开保护模式,再开分页。
CR3:进程切换的核心
- 作用 :它存着页目录基址。简单说,CR3就是"地图的地图"的起点。
- 进程切换的本质 :当操作系统要从进程A切换到进程B时,最关键的一步就是修改CR3寄存器。把CR3指向进程B的页表基址,CPU瞬间就换了一套地址翻译规则,A和B的内存就彻底隔离了。
CR4:功能的扩展包
- PAE(第5位):物理地址扩展。早期32位CPU只能寻址4GB内存,开了这个位,配合分页机制,就能访问超过4GB的物理内存。
- PGE(第7位):开启全局页。这是为了解决TLB刷新问题的(后面会细讲)。
- LA57(第12位):开启57位地址支持。这决定了是用4级页表还是5级页表。
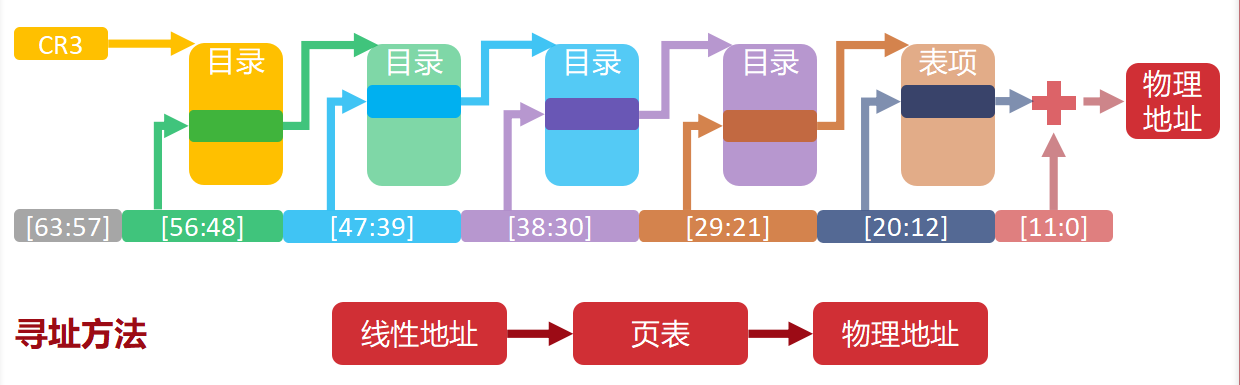
第二幕:五级地图结构(PML5 -> PML4 -> PDPT -> PGD -> PT)
既然开启了64位分页,CPU是如何一步步把"虚拟地址"翻译成"物理地址"的?这就是多级页表的结构。
PML5(第5级):顶层目录
- 只有在开启了LA57(57位地址)时才存在。
- 它负责管理巨大的地址空间。
PML4(第4级):次顶层
- 标准4级页表的起点。
PDPT(第3级):关键转折点
- 这里有一个非常重要的位:PS位(Page Size)。
- 如果PS=0:继续往下查下一级(PGD)。
- 如果PS=1:停止! 这里直接映射一个1GiB的超级页。不用再查下级表了,省事!
PGD(第2级):
- 同样有PS位。
- 如果PS=1:这里直接映射一个2MiB的超级页。
PT(第1级):最底层
- 这里没有PS位了,因为已经到了尽头。
- 它负责映射最小的4KiB标准页。
逻辑总结 :地址翻译就像查字典,一级一级往下查。但是,如果在高层(PDPT或PGD)就发现"这有一大块连续内存",就可以直接通过超级页机制停下来,不用查到底。
允许映射 1GiB 大超级页的好处
简单来说,好处就是**"省"** 和**"快"**。
- 省 TLB 条目(最重要的原因)
- 条目少 缺页触发少 命中率高 更快
- 省页表内存
- 用小页页表多,占存储空间且多级查找时间长
- 减少缺页中断
- 访问新内存时,硬件不需要层层查表,直接命中超级页,减少了查表的开销。
- PML4/PML5 不支持 :是因为它们对应的地址空间太大(512GiB/256TiB),物理内存给不起,应用程序用不上。
第三幕:性能优化机制(超级页与全局页)
硬件设计者为了提升性能,在页表项里加入了很多"小心机"。
超级页:空间换时间
- 问题:如果所有内存都用4KB的小页,那页表会非常大,查起来很慢,TLB(快表)也容易满。
- 解决:引入超级页(1GB或2MB)。
- 好处 :
- 省空间:一个表项就能顶成千上万个小页,页表层级变少,甚至不需要下一级表。
- TLB命中率高:TLB里存一个超级页的条目,就能覆盖巨大的内存范围。
- 代价:超级页必须占用物理上连续的内存。如果内存碎成渣,就分配不出超级页了(外部碎片问题)。
全局页:避免无效刷新
- 背景:每次进程切换(修改CR3),CPU通常会把TLB(快表)里的内容全清空,因为新旧进程的地址映射不一样。
- 问题 :但是,内核代码是所有进程共用的!每次切换进程都清空内核的TLB条目,下一秒内核又要重新去查页表,这很浪费。
- 解决 :全局页 。
- 在页表项里设置G位。
- 告诉CPU:"这个页面(通常是内核代码)是全局的,切换进程时别删它的TLB条目!"
- 这大大提高了系统调用的效率。
操作系统内核层:负责"分段、分页、请求分页"
这一层关注的是**"宏观的虚拟地址到物理地址的映射"** 以及**"内存保护和隔离"**。
- 分段:把内存按逻辑功能(代码段、数据段)划分。
- 分页:把虚拟地址空间和物理内存都切成固定大小的块(页),建立映射关系。
- 请求分页:这是分页的一种优化。只有程序真正用到某一页时,才把它从硬盘调入内存。
它们解决的问题是:
- 如何让程序拥有连续的虚拟地址空间,而不管物理内存是否连续?
- 如何保护进程A不访问进程B的内存?
- 如何运行比物理内存还大的程序?
📦 用户层/库层:负责"内存分配"
这一层关注的是**"如何高效地把大块的内存切分给变量使用"**。
- 动态分区法 、伙伴系统 、dlmalloc 、slab分配器 等,这些才是真正的**"内存分配"**算法。
- 它们通常在一个进程内部 工作。它们会先向操作系统申请一大块内存(比如几兆),然后自己在这个大池子里切分,把小块分给
malloc或new。
进程内内存分配
第一幕:解决进程切换的性能损耗------ASID
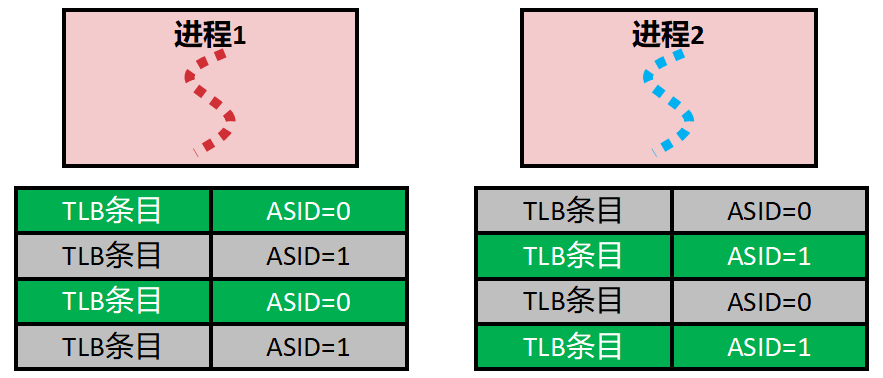
☆ 考点 在TLB中引入ASID的好处
在 TLB(Translation Lookaside Buffer,转换后备缓冲区)中引入 ASID(Address Space ID,地址空间标识符)主要是为了解决多任务操作系统中进程切换时的性能瓶颈。
简单来说,它的核心好处是极大地提高了进程切换的效率,避免了 TLB 的频繁清空。
以下是引入 ASID 的具体好处和原理:
1. 避免进程切换时的 TLB 全局刷新(核心优势)
- 没有 ASID 时 :每个进程都有自己独立的虚拟地址空间。切换进程时,为防止错误地址映射,必须清空TLB。导致进程刚开始运行时,TLB 是空的,每一次内存访问触发缺页,拖慢。
- 引入 ASID 后 :给每个进程分配ASID。当进程切换发生时,CPU 只需要更新当前的 ASID 寄存器,不需要清空 TLB 。
- MMU 在查找 TLB 时,不仅比对虚拟地址,还会比对 ASID。
- 如果 TLB 中的条目 ASID 与当前进程不匹配,MMU 会直接忽略该条目
- 这意味着进程 B 可以利用 TLB 中原本属于它自己的旧条目,或者填入新条目
第二幕:进程内内存分配的原则与挑战
解决了硬件层面的地址翻译效率问题,接下来要看软件层面(用户程序)如何向系统申请内存。
指导原则
- 高效:少浪费空间(减少碎片)。
- 快速:少浪费CPU时间(分配算法要快)。
- 局部性:尽量把相关的内存放在一起,减少缺页和TLB Miss。
挑战
- 简单的动态分区法(如首次适应、最佳适应)很难同时满足"快"和"省"。因此,我们需要更高级的分配器------dlmalloc。
第三幕:dlmalloc的核心机制------分块与分级
dlmalloc是Linux glibc中malloc的实现
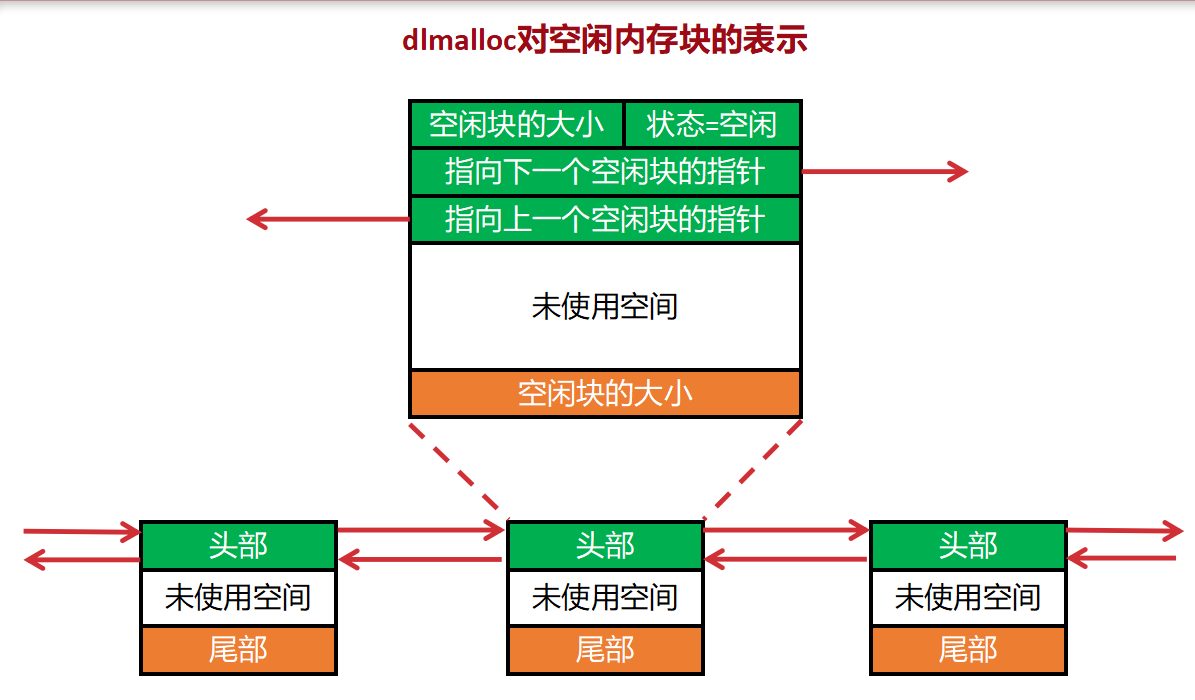
空闲块的结构
- 双向循环链表:为了快速插入和删除空闲块。
- 首尾各有一个"大小"字段 :
- 头部:用于查找和分割。
- 尾部 :为了快速合并 。当释放一个块时,可以通过尾部的大小字段,直接找到前一个块的头部,判断是否能合并,而不需要遍历整个链表。这是O(1)合并 的关键。
分级管理(Bin System)
- 最小粒度(16字节):小于16字节的请求,直接分配16字节。这是为了避免管理过小块的开销(管理数据比数据本身还大)。
- 多个队列(Bins) :
- 小队列(16-512字节) :按8字节等间距划分。目的是精确匹配,减少内部碎片。
- 大队列(576字节以上):按指数间距划分。因为大块内存请求少,不需要分得太细,指数划分可以减少队列数量,加快查找。
Q1: 为何使用双向循环链表?
- 双向链表(Bidirectional) :
- 核心目的 :高效空闲块合并。
- 原理:当释放一个内存块时,必须检查相邻的前后块是否空闲。双向链表允许我们在 O(1)时间内找到逻辑上的前驱和后继。
- 循环链表(Circular) :
- 核心目的 :简化边界处理,提高代码执行效率。
Q2: 空闲块的大小为何在首尾各出现一次?尾部那次可以不要吗?
- 核心目的 :为了在释放内存时,快速定位前一个块的头部。
- 原理 :
- 假设当前释放块的地址是
P。要检查前一个块(地址< P)是否空闲,我们需要找到前一个块的头部。 - 前尾紧邻当前块的头。通过读取当前块头部前4-8(前一块尾)算出前一个块的起始地址
- 假设当前释放块的地址是
- 结论 :不能去掉。如果没有尾部的大小字段,寻找前一个块将需要遍历整个堆
Q3: 为何放任比最小粒度小的内存块成为内部碎片?
- 空间开销权衡 :
- 如果太小,元数据占用的空间可能比实际有效数据还要大
- 管理成本 :
- 管理极小的块会导致空闲节点激增
Q4: 为何要设计多个队列,且小队列和大队列的规则不同?
- 核心目的 :加速查找 并 平衡碎片。
- 分队列:分配时直接去对应的队列查找,避免了遍历整个空闲链表。
- 规则不同(小队列 vs 大队列) :
- 小队列(16~512字节) :采用等间距 (如每 8 字节一个队列)。
- 原因:小块内存分配极其频繁,对性能要求极高。等间距可以保证查找速度极快。
- 大队列(>512字节) :采用指数间距 (如 2 的幂次)。
- 原因:大块内存分配较少,且大小差异巨大。指数间距可以用极少的队列覆盖巨大的地址空间。
- 小队列(16~512字节) :采用等间距 (如每 8 字节一个队列)。
Q5: 小队列的间距选择和最小队列的大小选择需要权衡什么因素?
- 权衡因素 :内部碎片 vs 队列数量 队列间距 最小队列长度
第四幕:伙伴分配器------一种特殊的分级策略
PPT中提到的"伙伴分配器"其实是Linux内核中用于管理物理内存的算法,但这里用它来解释dlmalloc的分级思想。
核心思想
- 内存块大小都是2的幂次方。
- 分配:如果请求610字节,就找1024字节的块,切一半给512队列,剩下512再切...直到分出1024。
- 释放:检查"伙伴"(地址相邻、大小相同的块)是否空闲,如果空闲就合并,递归向上。
伙伴分配器的时间复杂度是多少(考虑分配和释放)?
- 分配和释放都是O(log n) ,但在实践中,由于队列数量有限,可以优化到接近O(1)。
为什么不用担心碎片?
- 内部碎片:低于某个最小大小的空闲块将作为内部碎片
- 外部碎片:通过分级队列和快速合并机制,dlmalloc能有效地将空闲块合并成大块,减少外部碎片。
问题三 小队列的间距选择和最小队列的大小选择需要权衡什么因素?
小队列:权衡因素:碎片率 vs. 链表数量
大队列:权衡因素:查找速度 vs. 可接受的浪费比例
问题四 考虑到内存分配器的这种特性,我们写程序需要注意什么?
对齐分配 减少分配频率 加快分配速度 注意释放顺序 尽量批量操作
第五幕:向系统要内存------sbrk与堆的增长
用户程序的内存(堆)不是一开始就全部分配好的,而是按需向操作系统申请。
程序断点(Program Break)
end_brk指针指向堆的顶部。- 当dlmalloc内部的空闲块不够用时,就调用
sbrk()系统调用,将end_brk向上移动,向操作系统申请更多虚拟内存。
为什么end_brk一般只上移不下移?
- 性能 :下移
end_brk需要操作系统回收页表,开销大。 - 局部性:刚释放的内存很可能马上又被分配,保留在堆里可以复用。
- 荒野保护 :只有最高地址的块才能扩张,所以分配器会尽量先用完低地址的空闲块,推迟向系统申请新内存,避免
end_brk不必要地增加。
第六幕:最后的优化------局部性与缓存
为了追求极致性能,dlmalloc还做了一些"投机取巧"的优化。
就近分配
- 如果上次分配的块还有剩余空间,优先从这里分配。这保证了时间上连续的分配在空间上也连续,提高了缓存命中率。
操作缓存
- 延迟合并:释放内存时,不立即合并相邻空闲块,而是等到空闲块积累到一定程度再合并。因为刚释放的块很可能马上又被分配,立即合并是浪费CPU。
- 预分配:分配小块时,一次切出多个小块,放入缓存,下次直接从缓存拿。
总结
这几页PPT完整地展示了从硬件地址翻译优化(ASID) 到用户态内存分配策略(dlmalloc) ,再到**系统调用接口(sbrk)**的全链路内存管理逻辑。
核心思想就是:用空间换时间,用局部性换性能,用分级管理平衡碎片和速度
进程内:ASID 如何分配:分块与分级(六道题) 伙伴分配器的原理 如果不够怎么办:向上级要内存sbrk
进程间内存分配
为了防止某个用户或程序把系统资源耗尽,Linux 提供了 limits.conf 这样的配置文件,给每个用户或进程划定"红线"。
物理内存总量有限,当无法执行sbrk后就会执行OOM-killer
杀谁:内存大 优先级低 数量少
性能优化与超级页
1.超级页
- 原理 :既然小页(4KB)管理起来太累,TLB 表项不够用,那不如直接用大页。
- 代价 :快,但容易产生内部碎片
- 实现:启动时就划出一块地专门做大页。
2. 内存紧缩
- 问题:随着系统运行,大页会被零散的小数据填满
- 解决:把正在使用的小页搬运到一起,腾出完整的大页空间。
物理内存的区域特性
32 DMA NORMAL是可以线性映射的 highmen区域必须选择映射
64未都可以映射到内核态
物理内存的不对称特性
非对称访问 Non-Uniform Memory Access,NUMA
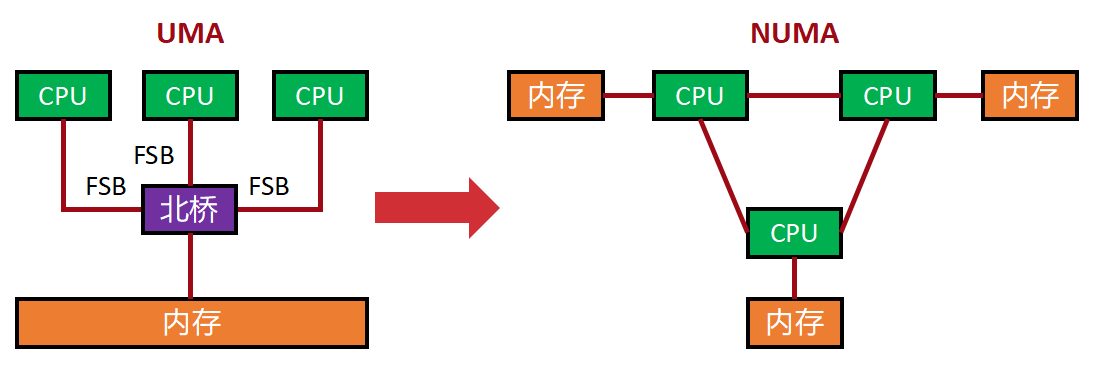
- UMA 时代:所有 CPU 访问内存的速度是一样的(通过北桥)。
- NUMA 架构 :现在每个 CPU 插槽都连着本地内存。
- 本地访问:CPU 访问自己连着的内存,速度极快。
- 远程访问:CPU 访问其他 CPU 连着的内存,需要跨总线,速度慢很多。
- 分配策略 :内存分配器会把内存分配在使用它的本地节点上,这就是所谓的"就近原则"