这才看到, Firecrawl 官方发了一条推。
从今天起,用 Firecrawl 不用申请 Key、不用配 env,直接调接口就行。
每月还白送 1000 次免费额度。
Firecrawl 是一个专门给 AI 用的网页数据接口。
它能把任何网页,变成 AI 能直接读取的干净 Markdown 或结构化数据。
你给它一个网址,它返回给你:
- 干干净净的正文 Markdown(去掉了导航栏、广告、页脚这些杂碎)
- 或者结构化的 JSON(你定义 schema,它按结构提取)
- 想要截图、HTML、元数据也可以。
而且还支持网页爬取、本地文件解析、arXiv 语义搜索、 异步浏览器研究 Agent 、 搜 GitHub 仓库信息等。
01
开源项目简介
其实这个开源项目已经是整个社区 Top 100 的仓库之一了,现在有 130K+ Star。
有 15 万+ 家公司在用,包括 Apple、Canva、Lovable、Stanford、Zapier、Replit 啥的。
因为是开源的,很受欢迎。
它提供的 MCP 已经被安装过 40 多万次了。应该是世界上安装过最多的 MCP 之一。
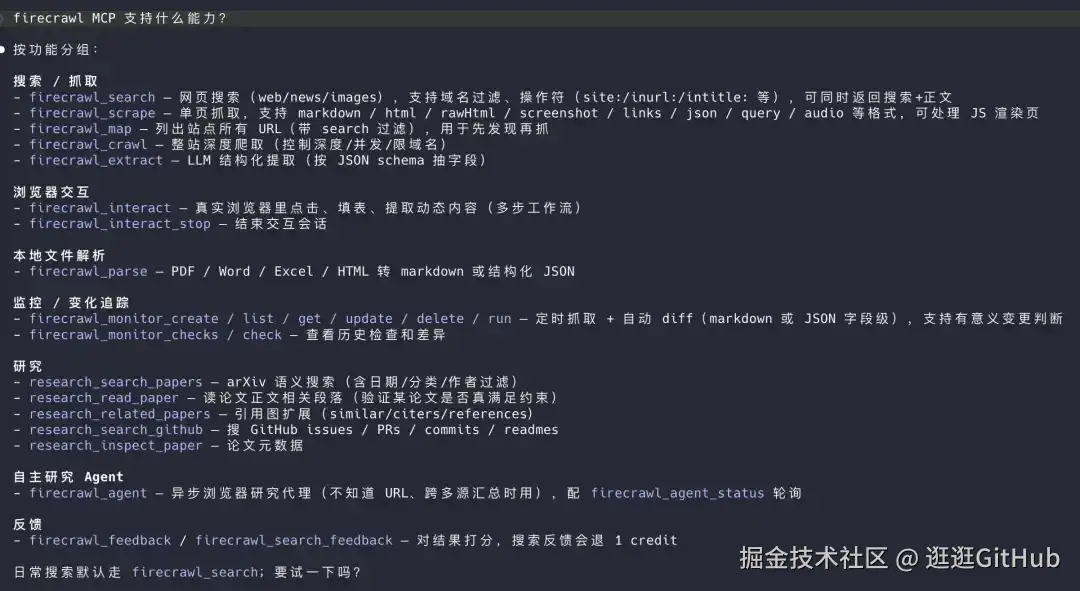
它有三个核心能力:
Search: 搜索整个互联网,每个结果直接带完整网页内容
Scrape: 抓单个页面,JS 渲染、动态加载都能搞定
Interact: 能让 AI 在网页上点击、填表、翻页、走登录流程
它是 AI Agent 的眼睛和手,让 Agent 能看见网页、能操作网页。
Firecrawl 在 AI 联网 这个赛道里,基本已经是事实标准级别了。
这次更新主推的就是无 Key 模式。三个入口同时上线:
第一个:MCP
如果你在用 Claude Code、Codex 这些支持 MCP 的工具,一行命令搞定:
bash
# 加到 Claude Code 里,不需要任何 Key
claude mcp add --transport http firecrawl https://mcp.firecrawl.dev/v2/mcpAgent 自己就能完成接入,根本不需要你在中间手动传 Key。
以前你用这个开源项目的服务,想让 Agent 联网,你得先去注册、拿到 Key、再配置到 MCP 里。
现在 Agent 想用,自己就接上了。
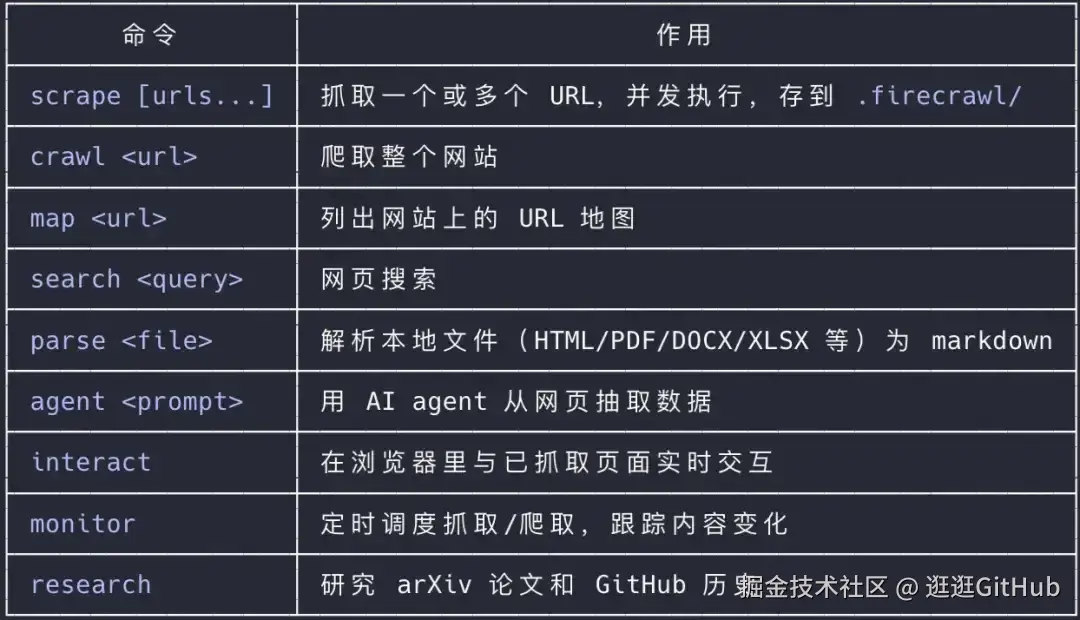
第二个:CLI
css
npx firecrawl-cli@latest也支持 CLI 的方式,相比 MCP 我更喜欢 CLI 的方式。
第三个:REST API
这个更离谱,连 HTTP 请求里的 Authorization header 都不用写了。
以前调 API:
bash
curl -H "Authorization: Bearer fc-xxxxxx" https://api.firecrawl.dev/v2/scrape现在:
bash
curl https://api.firecrawl.dev/v2/scrape就这样。
每月 1000 次免费额度是自动给的,不用做任何操作。 用超了再去注册账号、升级付费 plan。
02
这波操作背后的逻辑
表面上看,Firecrawl 只是去掉了 API Key 这一个步骤。但仔细想想,他们可能想的很清楚。
就是在 Agent 吞没整个数字世界之前,先把 Agent 接入互联网这个基建啃下来。
他们认为 Agent 时代范式会转移。
以前 API Key 是给人的:开发者注册、付费、管理 Key。
但 Agent 不会注册账号,也不会自己绑邮箱。 它只会调用接口。
所以当 AI Agent 越来越多地成为 API 的主要消费者时,无 Key 调用就会从特权变成默认。
Firecrawl 这一步,等于是提前押注了这个趋势。
这跟它一直以来开源、免费送额度的策略是一脉相承的:先把开发者心智占住,规模化阶段再变现。
这是典型的基础设施卡位战打法。
互联网正在从人浏览的资源 变成 AI 调用的接口。
Firecrawl 这一波 Keyless,给这个趋势又加了一把火。