【深度学习入门 Day 4】PyTorch 自动求导:用 loss.backward() 训练 XOR
本文记录深度学习学习第 4 天的内容:把昨天用 NumPy 手写的 XOR 两层 MLP 改写成 PyTorch 版本,重点理解
Tensor、requires_grad、loss.backward()、.grad、torch.no_grad()和zero_()。今天的核心目标不是追求复杂模型,而是看懂 PyTorch 如何自动完成反向传播。
文章目录
- 一、从 NumPy 手写反向传播到 PyTorch 自动求导
- 二、准备 XOR 数据
- 三、手动创建可求导参数
- 四、前向传播:计算预测值
- 五、计算 BCE 损失
- 六、核心一步:loss.backward()
- 七、一个重要细节:leaf tensor
- 八、更新参数为什么要用 torch.no_grad()
- 九、为什么每轮都要 zero grad
- 十、完整训练代码
- 十一、今日总结
- 十二、课后自测
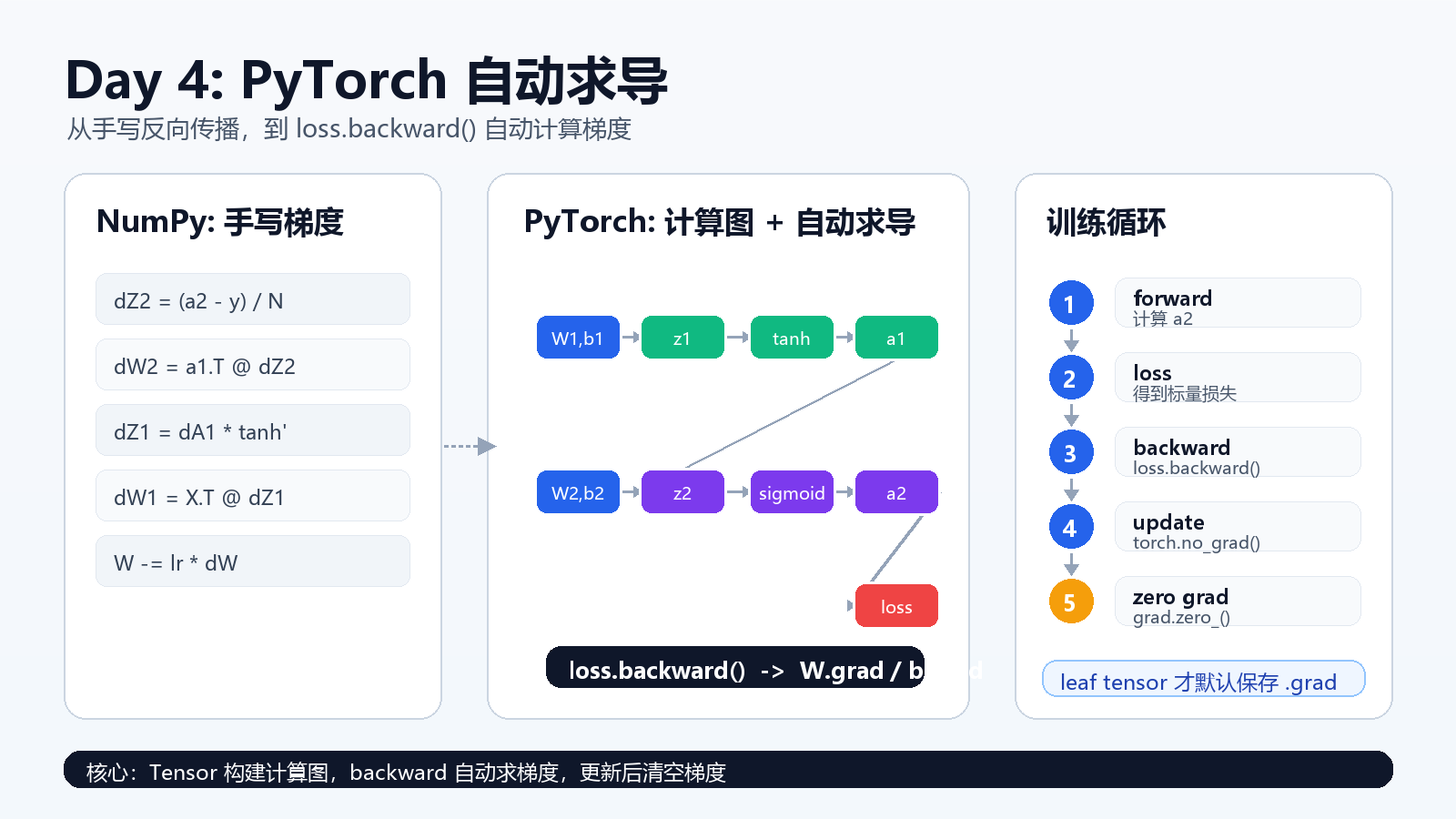
一、从 NumPy 手写反向传播到 PyTorch 自动求导
昨天我们用 NumPy 手写了两层 MLP:
text
X -> tanh hidden -> sigmoid output并且手动推了梯度:
python
dZ2 = (a2 - y) / N
dW2 = a1.T @ dZ2
db2 = np.sum(dZ2, axis=0, keepdims=True)
dA1 = dZ2 @ W2.T
dZ1 = dA1 * (1 - a1 ** 2)
dW1 = X.T @ dZ1
db1 = np.sum(dZ1, axis=0, keepdims=True)这非常重要,因为它让我们知道反向传播到底在算什么。
但真实项目里,我们不会每次都手写这些导数。PyTorch 的核心价值之一就是:
只要用 tensor 搭出前向计算图,PyTorch 就能自动反向传播,计算每个参数的梯度。
今天要记住三个关键词:
text
requires_grad
loss.backward()
zero_()它们分别对应:
text
requires_grad=True 告诉 PyTorch:这个参数需要求梯度
loss.backward() 从 loss 开始自动反向传播
grad.zero_() 清空上一轮留下的梯度二、准备 XOR 数据
先导入 PyTorch:
python
import torch准备 XOR 数据:
python
X = torch.tensor([
[0.0, 0.0],
[0.0, 1.0],
[1.0, 0.0],
[1.0, 1.0],
])
y = torch.tensor([
[0.0],
[1.0],
[1.0],
[0.0],
])打印形状:
python
print("X shape:", X.shape)
print("y shape:", y.shape)输出:
text
X shape: torch.Size([4, 2])
y shape: torch.Size([4, 1])这和 NumPy 版一样:
text
4 个样本
每个样本 2 个特征
每个样本 1 个标签三、手动创建可求导参数
今天先不用 nn.Module,而是手动创建参数。这样最容易看清自动求导的过程。
python
torch.manual_seed(42)
W1 = (torch.randn(2, 4) * 0.1).requires_grad_()
b1 = torch.zeros(1, 4, requires_grad=True)
W2 = (torch.randn(4, 1) * 0.1).requires_grad_()
b2 = torch.zeros(1, 1, requires_grad=True)这里的网络结构是:
text
输入层:2 个特征
隐藏层:4 个神经元
输出层:1 个神经元所以参数形状是:
text
W1.shape = (2, 4)
b1.shape = (1, 4)
W2.shape = (4, 1)
b2.shape = (1, 1)requires_grad=True 的意思是:
这个 tensor 是需要训练的参数,请 PyTorch 记录它参与过的计算,并在反向传播时计算它的梯度。
对于 W1 和 W2,这里用了:
python
.requires_grad_()最后的下划线表示原地操作,也就是把当前 tensor 标记为需要梯度。
四、前向传播:计算预测值
前向传播和昨天的 NumPy 版几乎一模一样:
python
z1 = X @ W1 + b1
a1 = torch.tanh(z1)
z2 = a1 @ W2 + b2
a2 = torch.sigmoid(z2)打印形状:
python
print("z1 shape:", z1.shape)
print("a1 shape:", a1.shape)
print("z2 shape:", z2.shape)
print("a2 shape:", a2.shape)
print("a2:", a2)输出类似:
text
z1 shape: torch.Size([4, 4])
a1 shape: torch.Size([4, 4])
z2 shape: torch.Size([4, 1])
a2 shape: torch.Size([4, 1])
a2: tensor([[0.5000],
[0.5002],
[0.5013],
[0.5014]], grad_fn=<SigmoidBackward0>)这里最值得注意的是:
text
grad_fn=<SigmoidBackward0>它说明 a2 不是一个普通结果,而是由 sigmoid 计算得到的,PyTorch 记住了它的来源。
也就是说,PyTorch 在背后已经记录了这条计算链:
text
W1, b1, W2, b2
↓
z1 -> tanh -> a1 -> z2 -> sigmoid -> a2这就是自动求导的基础。
五、计算 BCE 损失
二分类任务使用 BCE:
python
loss = -(y * torch.log(a2 + 1e-8) + (1 - y) * torch.log(1 - a2 + 1e-8)).mean()
print("loss:", loss)
print("loss grad_fn:", loss.grad_fn)初始预测接近 0.5,所以 loss 通常接近:
text
0.693输出类似:
text
loss: tensor(0.6931, grad_fn=<NegBackward0>)
loss grad_fn: <NegBackward0 object at ...>loss.grad_fn 不是 None,说明这个 loss 也是通过一串可求导计算得到的。
换句话说,PyTorch 知道:
text
loss 来自 a2
a2 来自 sigmoid
sigmoid 来自 z2
z2 来自 a1、W2、b2
a1 来自 tanh
z1 来自 X、W1、b1六、核心一步:loss.backward()
现在进入今天最核心的一句:
python
loss.backward()它会从 loss 开始,沿着计算图反向传播,自动计算:
text
dLoss/dW1
dLoss/db1
dLoss/dW2
dLoss/db2这些梯度会被保存到参数的 .grad 属性里:
python
print("W1 grad:", W1.grad)
print("b1 grad:", b1.grad)
print("W2 grad:", W2.grad)
print("b2 grad:", b2.grad)打印形状:
python
print("W1 grad shape:", W1.grad.shape)
print("b1 grad shape:", b1.grad.shape)
print("W2 grad shape:", W2.grad.shape)
print("b2 grad shape:", b2.grad.shape)输出:
text
W1 grad shape: torch.Size([2, 4])
b1 grad shape: torch.Size([1, 4])
W2 grad shape: torch.Size([4, 1])
b2 grad shape: torch.Size([1, 1])可以看到:
text
W1.grad.shape == W1.shape
b1.grad.shape == b1.shape
W2.grad.shape == W2.shape
b2.grad.shape == b2.shape这和昨天 NumPy 手写的梯度完全对应:
text
NumPy: 手写 dW1、db1、dW2、db2
PyTorch: loss.backward() 自动得到 W1.grad、b1.grad、W2.grad、b2.grad七、一个重要细节:leaf tensor
一开始可能会写出这样的参数初始化:
python
W1 = torch.randn(2, 4, requires_grad=True) * 0.1
W2 = torch.randn(4, 1, requires_grad=True) * 0.1看起来没问题,但运行后可能会发现:
text
W1.grad = None
W2.grad = None并且 PyTorch 会提示:
text
The .grad attribute of a Tensor that is not a leaf Tensor is being accessed.原因是:
python
torch.randn(2, 4, requires_grad=True)这个原始 tensor 是 leaf tensor。
但后面又乘了:
python
* 0.1乘完以后得到的新 W1 已经不是 leaf tensor,而是由一次乘法运算生成的中间结果。
PyTorch 默认只把梯度保存到 leaf tensor 的 .grad 里,所以 W1.grad 会是 None。
正确写法之一是:
python
W1 = (torch.randn(2, 4) * 0.1).requires_grad_()
W2 = (torch.randn(4, 1) * 0.1).requires_grad_()今天要记住这句话:
PyTorch 默认只把梯度保存在 leaf tensor 的
.grad里;如果一个 tensor 是由别的 tensor 运算得到的,它通常不是 leaf tensor。
八、更新参数为什么要用 torch.no_grad()
有了梯度以后,就可以更新参数。
NumPy 里我们写:
python
W1 = W1 - lr * dW1
b1 = b1 - lr * db1
W2 = W2 - lr * dW2
b2 = b2 - lr * db2PyTorch 手动更新可以写成:
python
lr = 0.1
with torch.no_grad():
W1 -= lr * W1.grad
b1 -= lr * b1.grad
W2 -= lr * W2.grad
b2 -= lr * b2.grad这里必须理解:
python
with torch.no_grad():意思是:
这一段只是更新参数,不要把"参数更新"本身也记录进计算图。
如果不加它,PyTorch 会继续追踪:
text
W1 -> W1 - lr * W1.grad这会让计算图变复杂,也不符合训练逻辑。
训练时,我们希望 PyTorch 记录的是:
text
参数如何参与 forward 并产生 loss而不是记录:
text
参数更新这件事本身所以参数更新要放在 torch.no_grad() 里。
九、为什么每轮都要 zero grad
参数更新完以后,还要清空梯度:
python
W1.grad.zero_()
b1.grad.zero_()
W2.grad.zero_()
b2.grad.zero_()为什么?
因为 PyTorch 的梯度默认是累加的,不是覆盖。
假设第一次反向传播后:
text
W1.grad = 0.3如果不清空,第二次调用:
python
loss.backward()假设新梯度是:
text
0.2那么 PyTorch 会得到:
text
W1.grad = 0.3 + 0.2 = 0.5而不是:
text
W1.grad = 0.2所以每一轮训练通常是:
text
1. forward 计算预测
2. loss 计算损失
3. backward 计算梯度,把梯度存到 .grad
4. update 用 .grad 更新参数
5. zero grad 清空 .grad,准备下一轮这里的:
python
zero_()下划线表示原地操作,直接把原来的梯度 tensor 改成 0。
以后使用优化器时,常见写法是:
python
optimizer.zero_grad()
loss.backward()
optimizer.step()其中:
python
optimizer.zero_grad()做的就是清空上一轮梯度。
十、完整训练代码
python
import torch
X = torch.tensor([
[0.0, 0.0],
[0.0, 1.0],
[1.0, 0.0],
[1.0, 1.0],
])
y = torch.tensor([
[0.0],
[1.0],
[1.0],
[0.0],
])
torch.manual_seed(42)
W1 = (torch.randn(2, 4) * 0.1).requires_grad_()
b1 = torch.zeros(1, 4, requires_grad=True)
W2 = (torch.randn(4, 1) * 0.1).requires_grad_()
b2 = torch.zeros(1, 1, requires_grad=True)
lr = 0.1
for step in range(10001):
# forward
z1 = X @ W1 + b1
a1 = torch.tanh(z1)
z2 = a1 @ W2 + b2
a2 = torch.sigmoid(z2)
loss = -(y * torch.log(a2 + 1e-8) + (1 - y) * torch.log(1 - a2 + 1e-8)).mean()
# backward
loss.backward()
# update
with torch.no_grad():
W1 -= lr * W1.grad
b1 -= lr * b1.grad
W2 -= lr * W2.grad
b2 -= lr * b2.grad
# zero grad
W1.grad.zero_()
b1.grad.zero_()
W2.grad.zero_()
b2.grad.zero_()
if step % 1000 == 0:
pred = (a2 >= 0.5).int()
print(
f"step={step:05d}, "
f"loss={loss.item():.6f}, "
f"a2={a2.detach().view(-1).numpy().round(3)}, "
f"pred={pred.view(-1).numpy()}"
)最终输出类似:
text
step=05000, loss=0.011665, a2=[0.014 0.992 0.99 0.014], pred=[0 1 1 0]
step=06000, loss=0.007604, a2=[0.009 0.995 0.994 0.009], pred=[0 1 1 0]
step=07000, loss=0.005605, a2=[0.007 0.996 0.995 0.007], pred=[0 1 1 0]
step=08000, loss=0.004423, a2=[0.006 0.997 0.996 0.005], pred=[0 1 1 0]
step=09000, loss=0.003645, a2=[0.005 0.998 0.997 0.004], pred=[0 1 1 0]
step=10000, loss=0.003094, a2=[0.004 0.998 0.997 0.004], pred=[0 1 1 0]可以看到模型已经成功学会 XOR:
text
[0, 0] -> 0
[0, 1] -> 1
[1, 0] -> 1
[1, 1] -> 0十一、今日总结
今天的核心内容可以压缩成 6 点:
- PyTorch 的
Tensor可以记录计算过程,并支持自动求导。 requires_grad=True表示这个参数需要计算梯度。- 前向传播得到的
a2和loss都带有grad_fn,说明它们属于计算图。 loss.backward()会沿计算图反向传播,自动把梯度存到参数的.grad中。- PyTorch 默认只把梯度保存在 leaf tensor 的
.grad里。 - 每轮更新后必须清空梯度,因为 PyTorch 的梯度默认会累加。
最终要记住这句话:
NumPy 让我们理解反向传播的细节,PyTorch 让我们把反向传播交给计算图和自动求导系统。
十二、课后自测
requires_grad=True的作用是什么?- 为什么
a2会显示grad_fn=<SigmoidBackward0>? loss.backward()到底做了什么?- 为什么
W1.grad.shape和W1.shape一样? - 为什么
torch.randn(..., requires_grad=True) * 0.1得到的W1.grad可能是None? - 什么是 leaf tensor?
- 为什么参数更新要放在
torch.no_grad()里面? - 为什么每轮训练后都要调用
zero_()?