文章目录
- 概述
- 环境
- 服务器安装GPU
- 安装操作系统
- 安装Nvidia驱动
- Nvidia-fabricmanager安装(可选)
- [安装CUDA Toolkit](#安装CUDA Toolkit)
-
- [CUDA Toolkit 说明](#CUDA Toolkit 说明)
- [CUDA Toolkit 安装](#CUDA Toolkit 安装)
- [Docker GPU 说明](#Docker GPU 说明)
- [Docker GPU 安装](#Docker GPU 安装)
- 下载模型
- 安装Python虚拟环境
-
- 安装pyenv
- [安装 Python 3.12.2(vLLM 兼容的稳定版本)](#安装 Python 3.12.2(vLLM 兼容的稳定版本))
- 创建vLLM独立虚拟环境
- 安装vLLM
-
- [确认 CUDA 环境变量正确](#确认 CUDA 环境变量正确)
- [验证 CUDA 13.0 可用性(≤13.2)](#验证 CUDA 13.0 可用性(≤13.2))
- 清除之前的错误安装包(可选)
- [安装 vLLM(自动匹配 CUDA 13.0)](#安装 vLLM(自动匹配 CUDA 13.0))
- 验证安装
- 启动项目
- 验证测试
概述
华为服务器安装单卡3090,部署千问3量化版模型,记录部署过程。
环境
- 服务器
- 华为2288H V5
- 2颗 CPU
- 256G 内存
- 300G 15K*2(RAID1)系统盘
- 1T SSD*2(RAID1)服务和模型存储盘
- RTX 3090 24G
- 900W电源*2(冗余)
- 操作系统
- Ubuntu22.04
- Python
- pyenv python3.12
- Nvidia驱动
- NVIDIA-SMI 595.71.05
- Cude
- cuda_13.0
- vLLM
- vllm 0.24
- 大模型
- Qwen3-14B-AWQ (当前使用)
- Qwen3-8B-AWQ
- Qwen3-4B
- Qwen3.5-4B
服务器安装GPU
- 华为服务器安装3090显卡,需要Riser转接卡(需要带供电口的),配合服务器电源使用。
- Riser转接卡供电口是8P的,请配好显卡 - Riser卡的电源线
- 华为服务器最多可以插入2块GPU,一定要核算好服务器电源功率
安装操作系统
安装Ubuntu22.04(步骤略)
安装Nvidia驱动
检查显卡驱动
- ubuntu-drivers命令需要用aplay
bash
# 安装aplay
sudo apt install alsa-utils- 检查可用驱动
bash
sudo ubuntu-drivers devices
bash
== /sys/devices/pci0000:3a/0000:3a:00.0/0000:3b:00.0 ==
modalias : pci:v000010DEd00002204sv00001458sd0000403Bbc03sc00i00
vendor : NVIDIA Corporation
model : GA102 [GeForce RTX 3090]
......
driver : nvidia-driver-535 - third-party non-free
driver : nvidia-driver-595 - distro non-free
driver : nvidia-driver-580-server - distro non-free
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-595-open - distro non-free recommended
driver : nvidia-driver-580-server-open - distro non-free
......
driver : xserver-xorg-video-nouveau - distro free builtin- 安装推荐驱动(recommended)
bash
sudo apt install nvidia-driver-595-open- 禁用自动升级
bash
sudo apt-mark hold nvidia-driver-595-open- 安装后重启
bash
reboot
# init 6Nvidia-fabricmanager安装(可选)
- nvidia-fabricmanager 是专门管理多张通过NVLink或NVSwitch互连的NVIDIA GPU的软件。
- 如果只有单卡安装,服务启动会报错提示(本例中可以禁止启动)
查看当前驱动版本
- Driver Version: 595.71.05,支持最高CUDA Version 13.2
bash
root@xunku:~# nvidia-smi
Fri Jul 3 09:42:36 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 595.71.05 Driver Version: 595.71.05 CUDA Version: 13.2 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:3B:00.0 Off | N/A |
| 30% 31C P8 22W / 350W | 20878MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 35736 C VLLM::EngineCore 20868MiB |
+-----------------------------------------------------------------------------------------+下载对应版本fabricmanager
1.下载和驱动版本一样的fabricmanager软件。这里是595.71.05
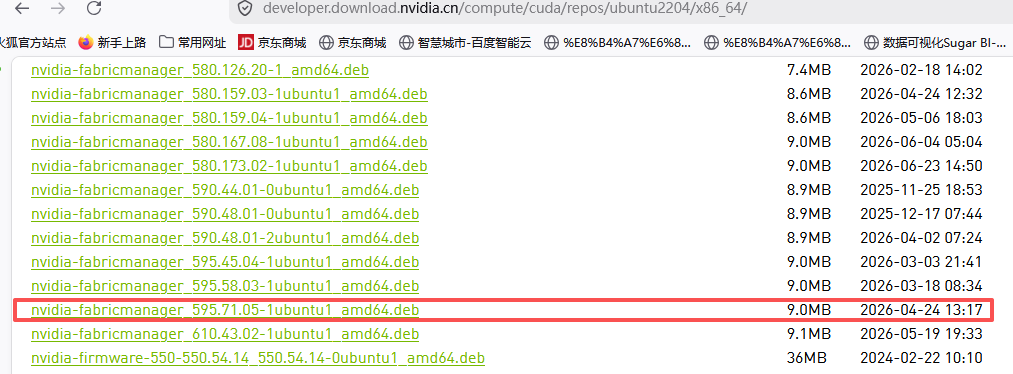
-
nvidia-fabricmanager_*.deb:这是主软件包,运行服务所必需。
-
nvidia-fabricmanager-dev_*.deb:这是开发包(头文件等),仅在你需要编译基于该组件的软件时才需要。请忽略它们。
bash
# 示例
export DRIVER_VERSION=595.71.05
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/nvidia-fabricmanager-$(echo $DRIVER_VERSION | awk -F '.' '{print $1}')_${DRIVER_VERSION}-1_amd64.deb
bash
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/nvidia-fabricmanager_595.71.05-1ubuntu1_amd64.deb安装fabricmanager
- 安装 fabricmanager
bash
# 示例
dpkg -i nvidia-fabricmanager-$(echo $DRIVER_VERSION | awk -F '.' '{print $1}')_${DRIVER_VERSION}-1_amd64.deb
bash
dpkg -i nvidia-fabricmanager_595.71.05-1ubuntu1_amd64.deb- 查看是否正常运行
bash
systemctl status nvidia-fabricmanager
bash
(base) root@Ubuntu22:~# systemctl status nvidia-fabricmanager
● nvidia-fabricmanager.service - NVIDIA fabric manager service
Loaded: loaded (/lib/systemd/system/nvidia-fabricmanager.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2025-09-16 18:06:03 CST; 9 months 15 days ago
Main PID: 3290 (nv-fabricmanage)
Tasks: 19 (limit: 629145)
Memory: 21.2M
CPU: 3h 55min 53.453s
CGroup: /system.slice/nvidia-fabricmanager.service
└─3290 /usr/bin/nv-fabricmanager -c /usr/share/nvidia/nvswitch/fabricmanager.cfg
Notice: journal has been rotated since unit was started, output may be incomplete.- 检查已安装的Fabric Manager版本
bash
dpkg -l | grep nvidia-fabricmanager
bash
(base) root@Ubuntu22:~# dpkg -l | grep nvidia-fabricmanager
ii nvidia-fabricmanager-595 595.71.05-1ubuntu0.22.04.1 amd64 Fabric Manager for NVSwitch based systems.- 禁止nvidia-fabricmanager自动升级
bash
sudo apt-mark hold nvidia-fabricmanager-595
bash
nvidia-fabricmanager-595 set on hold.- 查看已禁用版本,有输出则为已禁用
bash
sudo apt-mark showhold
bash
nvidia-fabricmanager-595安装CUDA Toolkit
CUDA Toolkit 说明
- 这是由NVIDIA提供的、用于开发和运行GPU加速应用程序的完整软件平台。它包含了编译器、数学库、调试工具等。具体如下:
- CUDA 驱动(nvidia-driver):已经安装了 nvidia-driver-595-open。
- CUDA 运行时(CUDA Runtime)及开发工具(nvcc编译器、cuBLAS等库):这是CUDA Toolkit软件包的主体。
- 如果需要:编译或运行任何直接调用GPU的C++/Python程序(例如,从源码编译PyTorch/TensorFlow,运行CUDA C++项目),那么必须安装CUDA Toolkit。
CUDA Toolkit 安装
- 查看当前安装版本(如果安装过)
bash
nvcc -V
bash
(base) root@ubuntu:/public/software# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:20:09_PST_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0- 删除已安装的CUDA Toolkit 包
bash
apt remove --purge cuda-toolkit-*- 安装指定版本的CUDA Toolkit 包
选择:Linux -> x86_64 ->Ubuntu -> 22.04 -> deb (network)

严格按照网页上给出的命令行指令执行即可。网络安装方式会自动配置源,并确保安装与系统驱动兼容的版本。
bash
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
bash
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update- 查看可安装的版本
bash
apt-cache search cuda-toolkit
nvidia-cuda-toolkit - NVIDIA CUDA development toolkit
nvidia-cuda-toolkit-doc - NVIDIA CUDA and OpenCL documentation
nvidia-cuda-toolkit-gcc - NVIDIA CUDA development toolkit (GCC compatibility)
......
cuda-toolkit-12-9 - CUDA Toolkit 12.9 meta-package
cuda-toolkit-12-9-config-common - Common config package for CUDA Toolkit 12.9.
cuda-toolkit-13-0 - CUDA Toolkit 13.0 meta-package
cuda-toolkit-13-0-config-common - Common config package for CUDA Toolkit 13.0.
cuda-toolkit-13-config-common - Common config package for CUDA Toolkit 13.
cuda-toolkit-13-1 - CUDA Toolkit 13.1 meta-package
cuda-toolkit-13-1-config-common - Common config package for CUDA Toolkit 13.1.
cuda-toolkit-13-2 - CUDA Toolkit 13.2 meta-package
cuda-toolkit-13-2-config-common - Common config package for CUDA Toolkit 13.2.
cuda-toolkit-13 - CUDA Toolkit 13 meta-package
cuda-toolkit - CUDA Toolkit meta-package
cuda-toolkit-13-3 - CUDA Toolkit 13.3 meta-package
cuda-toolkit-13-3-config-common - Common config package for CUDA Toolkit 13.3.
bash
apt list | grep -E "cuda-toolkit-[0-9]{2}-[0-9]{1,2}"
WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
......
cuda-toolkit-12-8/unknown 12.8.2-1 amd64
cuda-toolkit-12-9-config-common/unknown 12.9.79-1 all
cuda-toolkit-12-9/unknown 12.9.2-1 amd64
cuda-toolkit-13-0-config-common/unknown 13.0.96-1 all
cuda-toolkit-13-0/unknown 13.0.3-1 amd64
cuda-toolkit-13-1-config-common/unknown 13.1.80-1 all
cuda-toolkit-13-1/unknown 13.1.2-1 amd64
cuda-toolkit-13-2-config-common/unknown 13.2.75-1 all
cuda-toolkit-13-2/unknown 13.2.1-1 amd64
cuda-toolkit-13-3-config-common/unknown,now 13.3.29-1 all [installed,auto-removable]
cuda-toolkit-13-3/unknown 13.3.1-1 amd64- 安装指定版本
- ** 注意,不是安装最新版本就好 **
- ** 安装vLLM 默认预编译版本 **(当前是13.0,后续会随vLLM发展而变化)
- nvidia-smi 命令右上角显示驱动支持最高的CUDA版本(当前是13。2,后续会随发展而变化)
bash
apt install cuda-toolkit-13-0 cuda-toolkit-13-0-config-common- 添加环境变量
bash
vim /etc/profile
bash
export PATH="/usr/local/cuda-13.0/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-13.0/lib64:$LD_LIBRARY_PATH"
bash
source /etc/profile- 查看结果
bash
nvcc -V
bash
(vllm-env) root@xunku:/public/vLLM# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Aug_20_01:58:59_PM_PDT_2025
Cuda compilation tools, release 13.0, V13.0.88
Build cuda_13.0.r13.0/compiler.36424714_0- 禁止自动升级
bash
sudo apt-mark hold cuda-toolkit-13-0 cuda-toolkit-13-0-config-commonDocker GPU 说明
Docker GPU 支持 (NVIDIA Container Toolkit),是一个让Docker容器能够访问和使用宿主机(Host)NVIDIA GPU的工具集。它实质上是创建了一个兼容层,将宿主机的GPU驱动映射到容器内部。具体如下:
- 主要是 nvidia-container-toolkit 这个包,它会修改Docker的配置。
- 如果需要:在Docker容器内运行任何需要GPU的镜像(例如,运行 docker run --gpus all nvidia/cuda:12.1.1-base-ubuntu24.04 或官方的PyTorch/TensorFlow Docker镜像),那么必须安装此工具包。
Docker GPU 安装
- 官方安装指南
- 前提条件,已安装好Docker
- 安装工具
bash
sudo apt-get update && sudo apt-get install -y --no-install-recommends curl gnupg2- 配置仓库
bash
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list- 更新仓库
bash
sudo apt-get update- 安装工具包
bash
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.18.1-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}- 配置容器
bash
sudo nvidia-ctk runtime configure --runtime=docker
bash
INFO[0000] Loading config from /etc/docker/daemon.json
INFO[0000] Wrote updated config to /etc/docker/daemon.json
INFO[0000] It is recommended that docker daemon be restarted. - 重启容器
bash
sudo systemctl restart docker- 运行测试容器
- 找了半天,终于找到了一个可以下载的镜像
bash
docker pull nvidia/cuda:13.0.1-runtime-ubuntu22.04
13.0.1-runtime-ubuntu22.04: Pulling from nvidia/cuda
60d98d907669: Pulling fs layer
......
f1e29f967bcf: Pull complete
48feaf8fd5bd: Pull complete
8006ce821e80: Pull complete
Digest: sha256:e4511e846c49e5495ef3d80c82b8f5dd597c6ef5c7f355601ead776ae3e96c67
Status: Downloaded newer image for nvidia/cuda:13.0.1-runtime-ubuntu22.04
docker.io/nvidia/cuda:13.0.1-runtime-ubuntu22.04
bash
docker run --rm --gpus all nvidia/cuda:13.0.1-runtime-ubuntu22.04 nvidia-smi
bash
==========
== CUDA ==
==========
CUDA Version 13.0.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Tue Jan 20 13:37:44 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:03:00.0 Off | N/A |
| 30% 26C P8 10W / 350W | 4MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+下载模型
安装modelscope
- 使用系统自带Python 3.10.12
bash
root@xunku:/public# which python3
/usr/bin/python3
bash
root@xunku:/public# python3 --version
Python 3.10.12
bash
apt install -y python3-pip
bash
root@xunku:/public# pip3 --version
pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)- 安装 modelscope
bash
pip3 install modelscope -i https://mirrors.aliyun.com/pypi/simple/
bash
root@xunku:/public/model# modelscope --version
_ .-') _ .-') _ ('-. .-') _ (`-. ('-.
( '.( OO )_ ( ( OO) ) _( OO) ( OO ). ( (OO ) _( OO)
,--. ,--.).-'),-----. \ .'_ (,------.,--. (_)---\_) .-----. .-'),-----. _.` \(,------.
| `.' |( OO' .-. ',`'--..._) | .---'| |.-') / _ | ' .--./ ( OO' .-. '(__...--'' | .---'
| |/ | | | || | \ ' | | | | OO )\ :` `. | |('-. / | | | | | / | | | |
| |'.'| |\_) | |\| || | ' |(| '--. | |`-' | '..`''.) /_) |OO )\_) | |\| | | |_.' |(| '--.
| | | | \ | | | || | / : | .--'(| '---.'.-._) \ || |`-'| \ | | | | | .___.' | .--'
| | | | `' '-' '| '--' / | `---.| | \ /(_' '--'\ `' '-' ' | | | `---.
`--' `--' `-----' `-------' `------'`------' `-----' `-----' `-----' `--' `------'
modelscope-hub 0.1.5下载模型
bash
mkdir -p /public/model && cd /public/model
modelscope download --model Qwen/Qwen3-14B-AWQ --local_dir ./models/Qwen3-14B-AWQ
modelscope download --model Qwen/Qwen3-8B-AWQ --local_dir ./models/Qwen3-8B-AWQ
modelscope download --model Qwen/Qwen3-4B --local_dir ./models/Qwen3-4B
modelscope download --model Qwen/Qwen3.5-4B --local_dir ./models/Qwen3.5-4B
bash
root@xunku:/public/model# du -sh ./models/*
9.4G ./models/Qwen3-14B-AWQ
7.6G ./models/Qwen3-4B
5.7G ./models/Qwen3-8B-AWQ
8.8G ./models/Qwen3.5-4B安装Python虚拟环境
安装pyenv
- 准备依赖包
bash
sudo apt update
sudo apt install -y make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev- 安装 pyenv
bash
curl https://pyenv.run | bash- 将以下内容添加到 ~/.bashrc
bash
echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init --path)"' >> ~/.bashrc
echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.bashrc
source ~/.bashrc安装 Python 3.12.2(vLLM 兼容的稳定版本)
- 安装
bash
pyenv install 3.12.2
bash
Downloading Python-3.12.2.tar.xz...
-> https://www.python.org/ftp/python/3.12.2/Python-3.12.2.tar.xz
Installing Python-3.12.2...
Installed Python-3.12.2 to /root/.pyenv/versions/3.12.2- 验证
bash
pyenv versions # 应显示 * system 和 3.12.2
bash
* system (set by /root/.pyenv/version)
3.12.2创建vLLM独立虚拟环境
创建项目虚拟环境
bash
# 创建项目目录
mkdir -p /public/vLLM && cd /public/vLLM
# 创建专属虚拟环境(名称可自定义)
pyenv virtualenv 3.12.2 vllm-env
# 激活环境(仅当前目录生效,避免污染全局,注意当前目录是/public/vLLM)
pyenv local vllm-env
# 验证 Python 版本
python --version # 必须输出 Python 3.12.2进入项目目录,环境自动激活
项目目录在 /public/vLLM,pyenv 保持默认,退出当前终端或soure ~/.bashrc,以后每次进入项目目录,虚拟环境自动激活。
bash
cd /public/VLLM
python --version # 自动显示 Python 3.12.2
bash
# 进入项目目录
root@xunku:/public# cd /public/vLLM/
# 验证python版本
(vllm-env) root@xunku:/public/vLLM# python --version
Python 3.12.2
# 验证pip版本
(vllm-env) root@xunku:/public/vLLM# pip --version
pip 24.0 from /root/.pyenv/versions/3.12.2/envs/vllm-env/lib/python3.12/site-packages/pip (python 3.12)安装vLLM
确认 CUDA 环境变量正确
bash
(vllm-env) root@xunku:/public/VLLM# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Aug_20_01:58:59_PM_PDT_2025
Cuda compilation tools, release 13.0, V13.0.88
Build cuda_13.0.r13.0/compiler.36424714_0
bash
(vllm-env) root@xunku:/public/VLLM# echo $LD_LIBRARY_PATH | grep cuda-13.0
/usr/local/cuda-13.0/lib64:验证 CUDA 13.0 可用性(≤13.2)
bash
(vllm-env) root@xunku:/public/VLLM# nvidia-smi
Thu Jul 2 16:54:08 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 595.71.05 Driver Version: 595.71.05 CUDA Version: 13.2 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:3B:00.0 Off | N/A |
| 30% 26C P8 11W / 350W | 1MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+清除之前的错误安装包(可选)
- 清除之前的错误安装包(如果存在)
bash
(vllm-env) root@xunku:/public/VLLM# pip uninstall -y torch torchvision torchaudio vllm- 清理缓存
bash
pip cache purge安装 vLLM(自动匹配 CUDA 13.0)
- 注意,只需要安装vLLM,它会自己安装依赖包(PyTorch)。不要去手动安装PyTorch
- vLLM-安装文档
bash
pip install vllm --no-cache-dir
# 若遇网络问题,可指定国内镜像
#pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir
bash
......
Successfully installed aiohappyeyeballs-2.7.1 aiohttp-3.14.1 aiosignal-1.4.0 annotated-doc-0.0.4 annotated-types-0.7.0 anthropic-0.115.1 anyio-4.14.1 apache-tvm-ffi-0.1.9 astor-0.8.1 attrs-26.1.0 blake3-1.0.9 cachetools-7.1.4 cbor2-6.1.2 certifi-2026.6.17 cffi-2.0.0 charset_normalizer-3.4.7 click-8.4.2 cloudpickle-3.1.2 compressed-tensors-0.17.0 cryptography-49.0.0 cuda-bindings-13.3.1 cuda-core-1.0.1 cuda-pathfinder-1.5.6 cuda-python-13.3.1 cuda-tile-1.3.0 cuda-toolkit-13.0.2 depyf-0.20.0 detect-installer-0.1.0 dill-0.4.1 diskcache-5.6.3 distro-1.9.0 dnspython-2.8.0 docstring-parser-0.18.0 einops-0.8.2 email-validator-2.3.0 fastapi-0.136.3 fastapi-cli-0.0.27 fastapi-cloud-cli-0.22.1 fastar-0.11.0 fastsafetensors-0.3.2 flashinfer-cubin-0.6.12 flashinfer-python-0.6.12 frozenlist-1.8.0 googleapis-common-protos-1.75.0 grpcio-1.81.1 h11-0.16.0 hf-xet-1.5.1 httpcore-1.0.9 httptools-0.8.0 httpx-0.28.1 httpx-sse-0.4.3 huggingface-hub-1.21.0 humming-kernels-0.1.6 idna-3.18 ijson-3.5.0 interegular-0.3.3 jiter-0.16.0 jmespath-1.1.0 jsonschema-4.26.0 jsonschema-specifications-2025.9.1 lark-1.2.2 llguidance-1.7.6 llvmlite-0.47.0 lm-format-enforcer-0.11.3 loguru-0.7.3 markdown-it-py-4.2.0 mcp-1.28.1 mdurl-0.1.2 mistral_common-1.11.5 ml-dtypes-0.5.4 model-hosting-container-standards-0.1.16 msgspec-0.21.1 multidict-6.7.1 ninja-1.13.0 numba-0.65.0 numpy-2.3.5 nvidia-cublas-13.1.0.3 nvidia-cuda-cccl-13.3.3.4.1 nvidia-cuda-crt-13.3.73 nvidia-cuda-cupti-13.0.85 nvidia-cuda-nvcc-13.2.78 nvidia-cuda-nvrtc-13.0.88 nvidia-cuda-runtime-13.0.96 nvidia-cuda-tileiras-13.2.78 nvidia-cudnn-cu13-9.19.0.56 nvidia-cudnn-frontend-1.25.0 nvidia-cufft-12.0.0.61 nvidia-cufile-1.15.1.6 nvidia-curand-10.4.0.35 nvidia-cusolver-12.0.4.66 nvidia-cusparse-12.6.3.3 nvidia-cusparselt-cu13-0.8.0 nvidia-cutlass-dsl-4.5.2 nvidia-cutlass-dsl-libs-base-4.5.2 nvidia-cutlass-dsl-libs-cu13-4.5.2 nvidia-ml-py-13.610.43 nvidia-nccl-cu13-2.28.9 nvidia-nvjitlink-13.0.88 nvidia-nvshmem-cu13-3.4.5 nvidia-nvtx-13.0.85 nvidia-nvvm-13.2.78 openai-2.44.0 openai-harmony-0.0.8 opencv-python-headless-5.0.0.93 opentelemetry-api-1.43.0 opentelemetry-exporter-otlp-1.43.0 opentelemetry-exporter-otlp-proto-common-1.43.0 opentelemetry-exporter-otlp-proto-grpc-1.43.0 opentelemetry-exporter-otlp-proto-http-1.43.0 opentelemetry-proto-1.43.0 opentelemetry-sdk-1.43.0 opentelemetry-semantic-conventions-0.64b0 opentelemetry-semantic-conventions-ai-0.5.1 outlines_core-0.2.14 packaging-26.2 partial-json-parser-0.2.1.1.post7 prometheus-fastapi-instrumentator-8.0.2 prometheus_client-0.25.0 propcache-0.5.2 protobuf-7.35.1 psutil-7.2.2 py-cpuinfo-9.0.0 pybase64-1.4.3 pycountry-26.2.16 pycparser-3.0 pydantic-2.13.4 pydantic-core-2.46.4 pydantic-extra-types-2.11.1 pydantic-settings-2.14.2 pyelftools-0.33 pygments-2.20.0 pyjwt-2.13.0 python-dotenv-1.2.2 python-json-logger-4.1.0 python-multipart-0.0.32 pyyaml-6.0.3 pyzmq-27.1.0 quack-kernels-0.5.0 referencing-0.37.0 regex-2026.6.28 requests-2.34.2 rich-15.0.0 rich-toolkit-0.20.1 rignore-0.7.6 rpds-py-2026.6.3 safetensors-0.8.0 sentencepiece-0.2.1 sentry-sdk-2.64.0 setproctitle-1.3.7 setuptools-80.10.2 shellingham-1.5.4 six-1.17.0 sniffio-1.3.1 sse-starlette-3.4.5 starlette-1.3.1 supervisor-4.3.0 sympy-1.14.0 tabulate-0.10.0 tiktoken-0.13.0 tilelang-0.1.9 tokenizers-0.22.2 tokenspeed-mla-0.1.2 tokenspeed-triton-3.7.10.post20260531 torch-2.11.0 torch-c-dlpack-ext-0.1.5 torchaudio-2.11.0 torchvision-0.26.0 tqdm-4.68.3 transformers-5.12.1 triton-3.6.0 typer-0.25.1 typing-inspection-0.4.2 urllib3-2.7.0 uvicorn-0.49.0 uvloop-0.22.1 vllm-0.24.0 watchfiles-1.2.0 websockets-16.0 xgrammar-0.2.3 yarl-1.24.2 z3-solver-4.15.4.0
[notice] A new release of pip is available: 24.0 -> 26.1.2
[notice] To update, run: python -m pip install --upgrade pip验证安装
- 验证PyTorch
bash
(vllm-env) root@xunku:/public/vLLM# python -c "import torch; assert torch.cuda.is_available(); print(f'PyTorch CUDA {torch.version.cuda} OK')"
PyTorch CUDA 13.0 OK
(vllm-env) root@xunku:/public/vLLM#
bash
(vllm-env) root@xunku:/public/vLLM# python -c "import torch; \
print(f'实际 CUDA 编译版本: {torch._C._cuda_getCompiledVersion()}'); \
print(f'版本号标识: {torch.version.cuda}'); \
print(f'驱动兼容性: {torch.cuda.is_available()}')"
实际 CUDA 编译版本: 13000
版本号标识: 13.0
驱动兼容性: True- 验证vLLM
bash
(vllm-env) root@xunku:/public/vLLM# python -c "import torch, vllm; print(f'vLLM {vllm.__version__} + CUDA {torch.version.cuda} OK')"
vLLM 0.24.0 + CUDA 13.0 OK- 验证GPU可用性
- True 代表可用
bash
(vllm-env) root@xunku:/public/vLLM# python -c "import torch; print(torch.cuda.is_available())"
True启动项目
- 命令解析
bash
# vllm启动模型
vllm serve /public/model/models/Qwen3-14B-AWQ \
# 监听端口
--port 8000 \
# 监听IP
--host 0.0.0.0 \
# 明确指定量化
--quantization awq \
# 单批次中可同时处理的最大请求数量,默认值1024,可观察KV Cache 利用率进行调整
--max-num-seqs 64 \
# 单个处理步骤(Iteration)中,所有请求的Token总数上限,默认值2048
--max-num-batched-tokens 8192 \
# PagedAttention机制中,每个KV Cache块能存储的Token数量,默认值16
--block-size 32 \
# 将长提示词(Prefill)分成小块处理,并与解码(Decode)请求混合在同一批次中,高版本默认开启
--enable-chunked-prefill \
# 显存利用率设为90%(24GB卡安全阈值),默认值0.9
--gpu-memory-utilization 0.9 \
# Qwen3 量化原生支持40K上下文。如果需要加大(比如hermes要求64K),请使用YaRN 技术,默认值4096
--max-model-len 32768 \
# 启用Qwen3思考模式解析
--reasoning-parser qwen3 \
# 工具调用解析器qwen3_xml
--tool-call-parser qwen3_xml \
# 启用自动工具选择
--enable-auto-tool-choice \
# 外部调用模型名,与 Hermes 配置严格一致的模型名
--served-model-name qwen3-14b-awq \
# 启用前缀缓存(例如系统提示词)
--enable-prefix-caching \
# 启用api-key,可选
#--api-key sk-env-test-20260703 \
# 模型含自定义代码需开启
--trust-remote-code
# 单卡不能设置 --tensor-parallel-size
# 多卡按数量设置,例如8卡 --tensor-parallel-size 8- 启动脚本
bash
cd /public/vLLM/ && vim restart.sh
bash
#!/bin/bash
# ===== 功能说明 =====
# 1. 检查并终止已有 vLLM 相关进程
# 2. 后台启动服务 + 日志轮转
# 3. 严格校验命令参数(移除非法注释)
# 4. 启动状态实时反馈
LOG_DIR="/public/vLLM/logs"
PID_FILE="/public/vLLM/vllm.pid"
mkdir -p "$LOG_DIR"
# ===== 步骤1:终止已有进程 =====
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 检查运行中的 vLLM 进程..."
EXISTING_PIDS=$(ps aux | grep -E 'vllm|EngineCore|APIServer' | grep -v 'grep' | awk '{print $2}')
if [ -n "$EXISTING_PIDS" ]; then
echo "检测到以下需终止的进程: $EXISTING_PIDS"
echo "$EXISTING_PIDS" | xargs kill -9 2>/dev/null
sleep 2 # 确保进程完全退出
# 二次检查
REMAINING=$(ps aux | grep -E 'vllm|EngineCore|APIServer' | grep -v 'grep' | wc -l)
if [ "$REMAINING" -gt 0 ]; then
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 错误: 无法完全终止旧进程,请手动检查!" >&2
exit 1
fi
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 旧进程已成功终止"
else
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 无冲突进程,直接启动服务"
fi
# ===== 步骤2:启动新服务 =====
nohup vllm serve /public/model/models/Qwen3-14B-AWQ \
--port 8000 \
--host 0.0.0.0 \
--quantization awq \
--max-num-seqs 64 \
--max-num-batched-tokens 8192 \
--block-size 32 \
--enable-chunked-prefill \
--gpu-memory-utilization 0.9 \
--max-model-len 32678 \
--enable-prefix-caching \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_xml \
--enable-auto-tool-choice \
--served-model-name qwen3-14b-awq \
--trust-remote-code > "$LOG_DIR/vllm_$(date +'%Y%m%d_%H%M%S').log" 2>&1 &
NEW_PID=$!
echo $NEW_PID > "$PID_FILE"
# ===== 步骤3:验证启动状态 =====
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 启动中... PID=$NEW_PID,等待服务就绪(最长300秒)"
START_TIME=$(date +%s)
while true; do
if curl -s http://localhost:8000/health > /dev/null; then
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 服务启动成功!访问地址: http://ip:8000/v1/models"
exit 0
fi
ELAPSED=$(( $(date +%s) - START_TIME ))
if [ $ELAPSED -gt 300 ]; then
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 错误: 服务启动超时,请检查日志 $LOG_DIR" >&2
kill -9 $NEW_PID 2>/dev/null
exit 1
fi
sleep 2
done- 启动
注意,必须显进入项目虚拟环境目录
bash
root@xunku:~# cd /public/vLLM/
(vllm-env) root@xunku:/public/vLLM# ls
logs restart.sh start.sh.orig vllm.pid
(vllm-env) root@xunku:/public/vLLM# ./restart.sh 验证测试
- 获取模型名称
- "id":"qwen3-14b-awq"
bash
(vllm-env) root@xunku:/public/vLLM# curl http://localhost:8000/v1/models
{"object":"list","data":[{"id":"qwen3-14b-awq","object":"model","created":1783058807,"owned_by":"vllm","root":"/public/model/models/Qwen3-14B-AWQ","parent":null,"max_model_len":32678 ,"permission":[{"id":"modelperm-ab87467a8a23f2c5","object":"model_permission","created":1783058807,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}- 测试调用
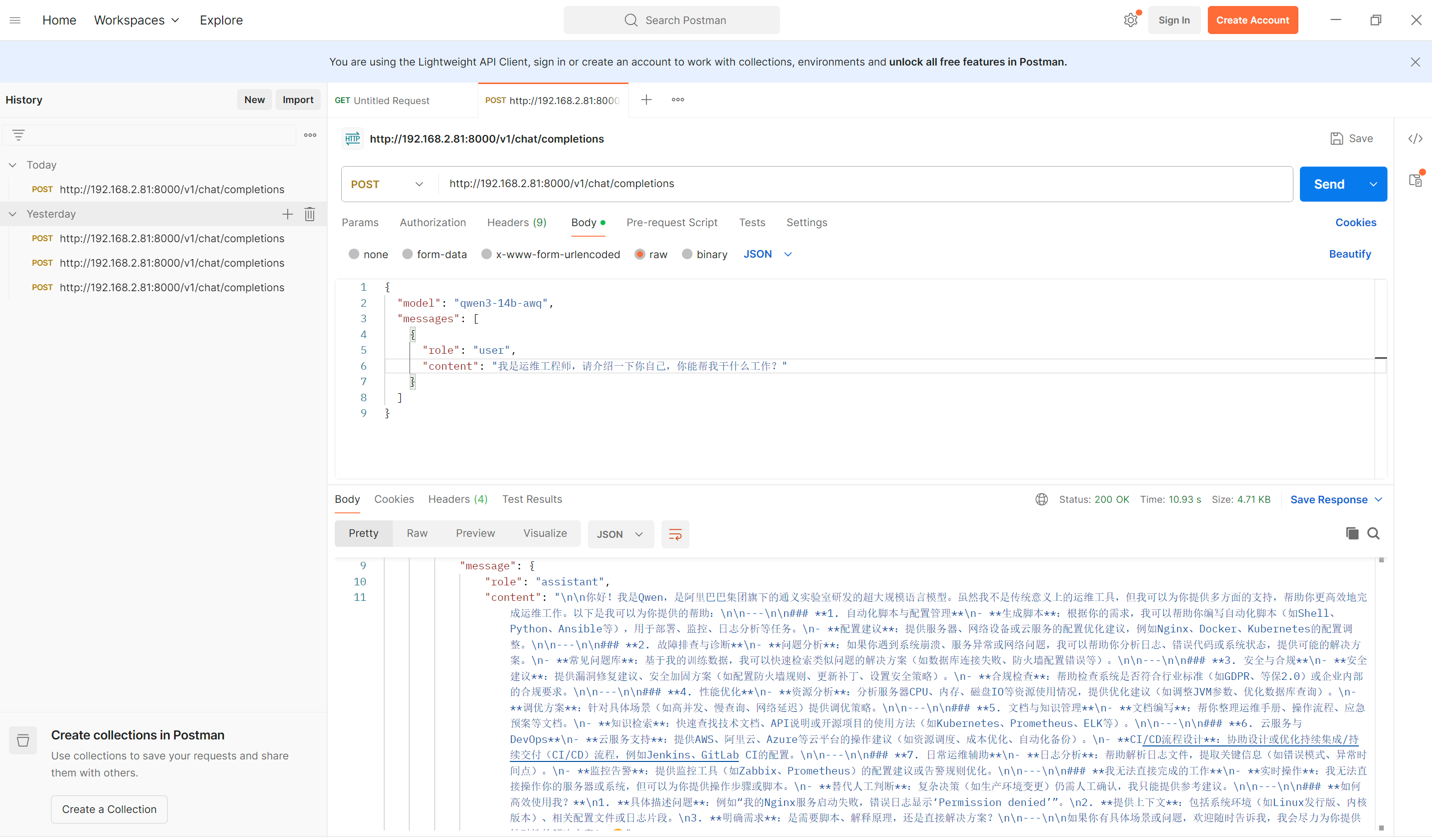
bash
(vllm-env) root@xunku:/public/vLLM# curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "qwen3-14b-awq",
"messages": [{"role": "user", "content": "你好"}]
}'
{"id":"chatcmpl-bcef4b2c5c3669ba","object":"chat.completion","created":1783001363,"model":"qwen3-14b-awq","choices":[{"index":0,"message":{"role":"assistant","content":"\n\n你好呀!😊 有什么我可以帮你的吗?","refusal":null,"annotations":null,"audio":null,"function_call":null,"reasoning":"\n好的,用户打招呼说"你好",我需要友好回应。首先,确认用户的需求,可能只是普通问候,也可能有后续问题。保持开放态度,用中文回复,简洁自然。可以加上表情符号增加亲切感,但不过度。确保没有格式错误,直接回应即可。\n"},"logprobs":null,"finish_reason":"stop","stop_reason":null,"token_ids":null,"routed_experts":null}],"service_tier":null,"system_fingerprint":"vllm-0.24.0-2702c72b","usage":{"prompt_tokens":9,"total_tokens":86,"completion_tokens":77,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"prompt_text":null,"kv_transfer_params":null}- Postman调用