文章目录
- 完整代码一览
- 安装依赖库
- [中文标注函数 cv2AddChineseText](#中文标注函数 cv2AddChineseText)
- 准备训练数据
- 设置标签与读取测试图像
- [创建 FisherFace 识别器并训练](#创建 FisherFace 识别器并训练)
- 预测与输出结果
- 在测试图上绘制中文结果
- [区分FisherFace 与EigenFace](#区分FisherFace 与EigenFace)
完整代码一览
c
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
"""向图片中添加中文"""
if (isinstance(img, np.ndarray)):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8")
draw.text(position, text, textColor, font=fontStyle)
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
images = []
def image_re(image):
a = cv2.imread(image, flags=0)
a = cv2.resize(a, dsize=(120, 180))
images.append(a)
image_re('qzl1.png')
image_re('qzl2.png')
image_re('pyy1.png')
image_re('pyy2.png')
labels = [0, 0, 1, 1]
pre_image = cv2.imread('pyy.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))
recognizer = cv2.face.FisherFaceRecognizer_create(threshold=5000)
recognizer.train(images, np.array(labels))
label, confidence = recognizer.predict(pre_image)
dic = {0: '胡歌', 1: '彭于晏', -1: '无法识别'}
print('这人是:', dic[label])
print('置信度为:', confidence)
image = cv2AddChineseText(cv2.imread('pyy3.png').copy(), dic[label], (30, 10), (255, 0, 0))
cv2.imshow('xx', image)
cv2.waitKey(0)安装依赖库
c
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFontFisherFace 识别器属于 cv2.face 模块,你需要安装 opencv-contrib-python:
c
pip install opencv-contrib-python中文标注函数 cv2AddChineseText
定义一个中文标记函数,主要是将OpenCV图片转PIL,写中文,再转回。
c
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判断输入是否是 OpenCV 的 NumPy 数组
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 如果是,则用 cv2.cvtColor 将 BGR 转为 RGB,然后用 Image.fromarray 转换为 PIL 图像对象
draw = ImageDraw.Draw(img)
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8")
draw.text(position, text, textColor, font=fontStyle)
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)这个函数专门解决 OpenCV 不能写中文的问题。
if判断结束后在 PIL 图像上创建一个绘图对象 draw,加载中文字体文件 "simsun.ttc"(宋体),大小 textSize。
draw.text 在指定位置写入文字,颜色用 RGB 格式,最后将 PIL 图像转回 NumPy 数组,并转换回 BGR 格式,以便 OpenCV 显示。
准备训练数据
c
images = []
def image_re(image):
a = cv2.imread(image, flags=0)
a = cv2.resize(a, dsize=(120, 180))
images.append(a)
image_re('qzl1.png')
image_re('qzl2.png')
image_re('pyy1.png')
image_re('pyy2.png')定义一个函数 image_re,它读取一张灰度图(flags=0),然后 resize 到 宽 120,高 180,最后存入 images 列表。
FisherFace 同样要求所有训练图像尺寸完全一致,所以我们统一缩放。
依次读取 4 张图片:qzl1.png、qzl2.png(属于"权志龙")、pyy1.png、pyy2.png(属于"彭于晏")。
设置标签与读取测试图像
c
labels = [0, 0, 1, 1]
pre_image = cv2.imread('pyy.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))标签与训练图像一一对应:前两张(qzl1, qzl2)标签 0,后两张(pyy1, pyy2)标签 1。
读取待识别图像 pyy.png,同样转为灰度并 resize 到 120×180,保持尺寸一致。
创建 FisherFace 识别器并训练
c
recognizer = cv2.face.FisherFaceRecognizer_create(threshold=5000)
recognizer.train(images, np.array(labels))cv2.face.FisherFaceRecognizer_create(threshold=5000):创建 FisherFace 识别器。threshold=5000 是识别阈值,当预测的置信度大于 5000 时,会返回 -1(表示不认识)。FisherFace 的置信度通常范围较广,5000 是常用值,实际使用中可根据测试调整。
预测与输出结果
c
label, confidence = recognizer.predict(pre_image)
dic = {0: ' 权志龙', 1: '彭于晏', -1: '无法识别'}
print('这人是:', dic[label])
print('置信度为:', confidence)predict 返回预测标签和置信度。置信度越小,匹配度越高。
用字典 dic 将标签映射为中文名,便于打印。
在测试图上绘制中文结果
c
image = cv2AddChineseText(cv2.imread('pyy3.png').copy(), dic[label], (30, 10), (255, 0, 0))
cv2.imshow('xx', image)
cv2.waitKey(0)读取另一张测试图 pyy3.png(是彭于晏的另一张照片),用 cv2AddChineseText 在左上角(30, 10)位置写上识别出的中文名,颜色蓝色
运行结果:
c
这人是: 彭于晏
置信度为: 1164.2549649833468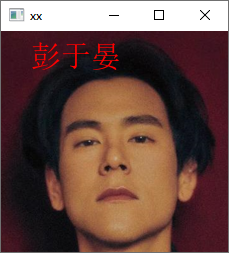
区分FisherFace 与EigenFace
FisherFace 与 EigenFace 不同之处在于:
EigenFace 使用 PCA(主成分分析),只考虑如何最大化整体数据的方差,不考虑类别信息。
FisherFace 使用 LDA(线性判别分析),它寻找一个投影方向,使得不同类别的人脸之间的距离尽可能大,同一类别内部的距离尽可能小。因此,它在识别任务中通常比 EigenFace 更准确,尤其在光照、表情变化时表现更稳健。