今天给大家看一个好玩的。
我给大家介绍过许多AI视频创作工具,这些视频生成模型都是需要先生成视频,然后才能观看。
这已经成为大家的共识。
但大家看看下面这个AI视频模型,我刚开始生成,大概过了三秒,视频就直接播放了:

而且视频在播放的过程中,我可以随时介入修改视频的内容,比如让人物说话更亢奋一些:
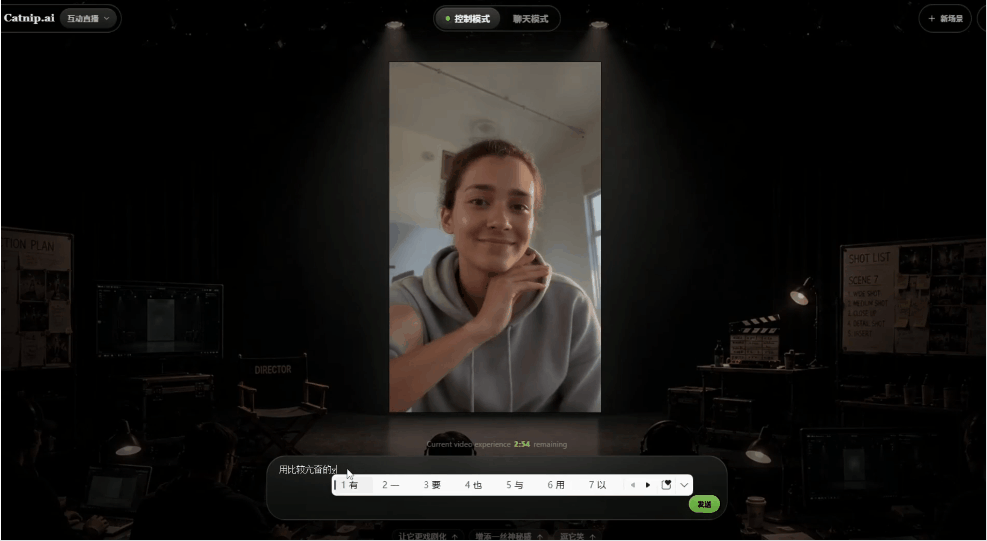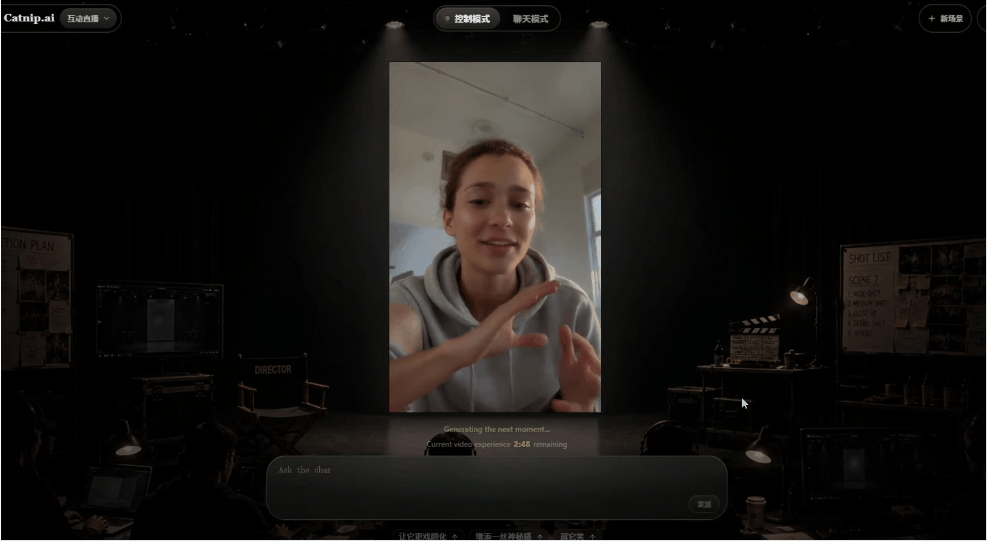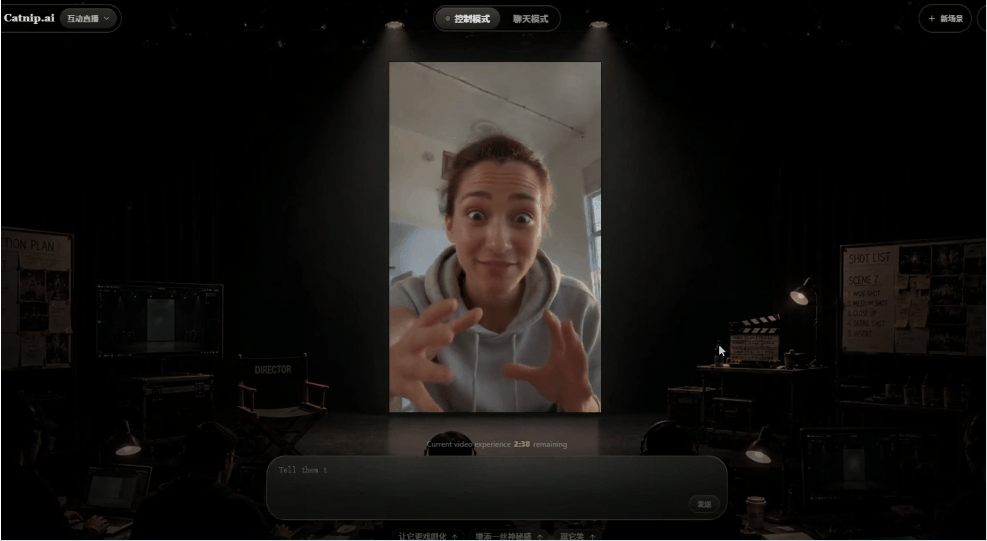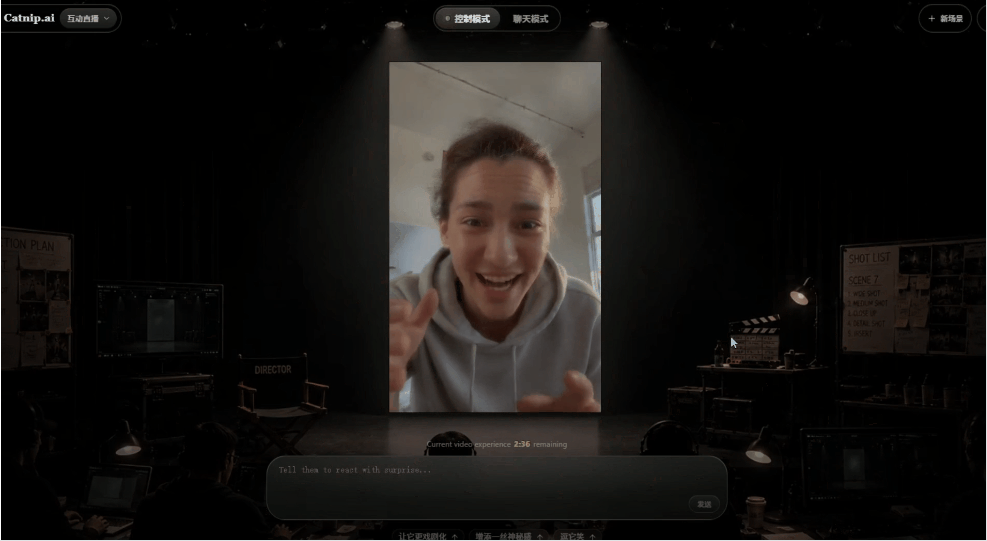
可以明显看出,视频中的角色说话方式变了,然后我输入一个问题,让对方跟我们对话:
对方也会接着我输入的问题继续对话,看起来不像AI视频,更像是一个能跟你实时互动的视频角色。
这是最近一个叫做Catnip.AI的团队发布的视频生成模型「MaineCoon」,我也是幸运得拿到了邀请码,以上都是我初次尝试时看到的效果。
它和我以前给大家介绍的AI视频模型都不同,它是一款流式音视频模型。啥叫流式生成呢?简单说就是:边生成,边播放。

别的视频模型做不到吗?
这个时候就有同学要问了:不就是一边生成一边播放吗,其它视频模型做不到吗?
说实话,还真做不到。
因为现在的主流视频模型的方向都是向着"增强画面"这个方向走的,画面越好,自然生成所需要使用的时间就越多。
大家想想,一段10秒钟的视频,都需要5分钟左右才能生成完,自然也做不到边生成边播放了。
而开发MaineCoon模型的这个团队,为了达成这个效果也是做了许多努力。
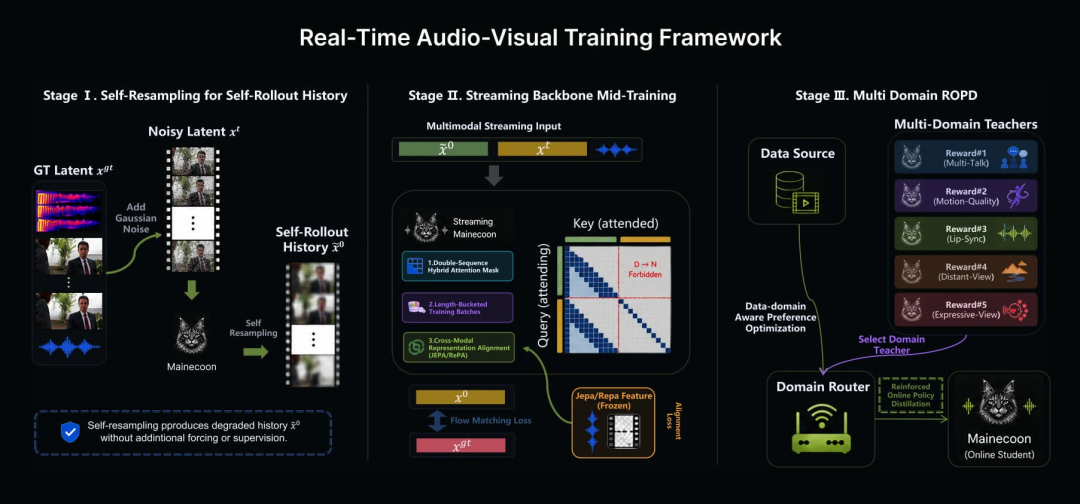
流式媒体更像是即兴演员,只能根据上一帧画面来判断接下来该怎么演,所以需要极强的临场应变能力。
这个过程中如果出现一点小误差,下一帧就可能基于这个误差继续生成,继续按照错误的方式演下去,最终误差会像滚雪球一样越滚越大。
同时,它还要足够快,往往需要每秒稳定生成几十帧,并保证画面不崩,本身就是一件很矛盾的事情。
而且流式是实时发生的,生成后直接就呈现给用户,没有回炉重造的余地,任何一帧画面都会被用户立刻看到。
这样的内容连续生成十几分钟,真的很难保持稳定。
正是因为这些难点堆在一起,行业里才久久没有出现这样的模型,而一个只有10人的团队却做到了。
具体效果怎么样?
我的总体评价是:效果很惊艳,体验很新奇,但还有许多值得提升的空间。
我初次打开MaineCoon的官网时,觉得官网效果做得真不错,向下滑动时,这个猫咪还会向一边走开。

后来深入了解了以后发现,这个官网和测试网站居然都是他们用vibe coding的方式做完的。
因为他们团队只有10个人,然后用了两个月的时间,搓出了缅因猫这个流式音视频模型,估计也没有多余人手手搓官网。
了解完这个,我只能说一句:牛逼。
测试网站倒是还挺简单的,输入提示词创建场景,然后就可以直接开始播放视频了。
不知道是不是这个背景图片的关系,使用过程中我总有一种导演看监视器的感觉,视频里是演员在演戏,而我发送的指令就是对演员下的指令,让演员改变情绪或者换台词。
实际上,缅因猫与传统AI视频模型对比的话,也确实是这个意思。
接下来我把实际测试中,发现的这个模型不错的地方,给大家罗列一下:
1.三秒出画面
MaineCoon的核心设计理念是原生流式生成,从数据基础设施、训练框架、注意力模式、KV-Cache使用到推理部署,全链路围绕"实时"重新设计,而不是把现有模型改得更快。
根据官方提供的数据,输入提示词后1到3秒就可以开始出画面,随后就会不间断生成,画面可以顺畅播放。
不过我目前测试的话,并不是每次都可以快速出现画面的。我第一次用,确实3秒出画面,后面用的时候,偶尔十秒左右才开始播放。
我猜测是网络原因,因为之后测试时都是晚上了,用的人比较多,加上这个小团队也没啥成本购买更多服务器,有点慢也比较正常。
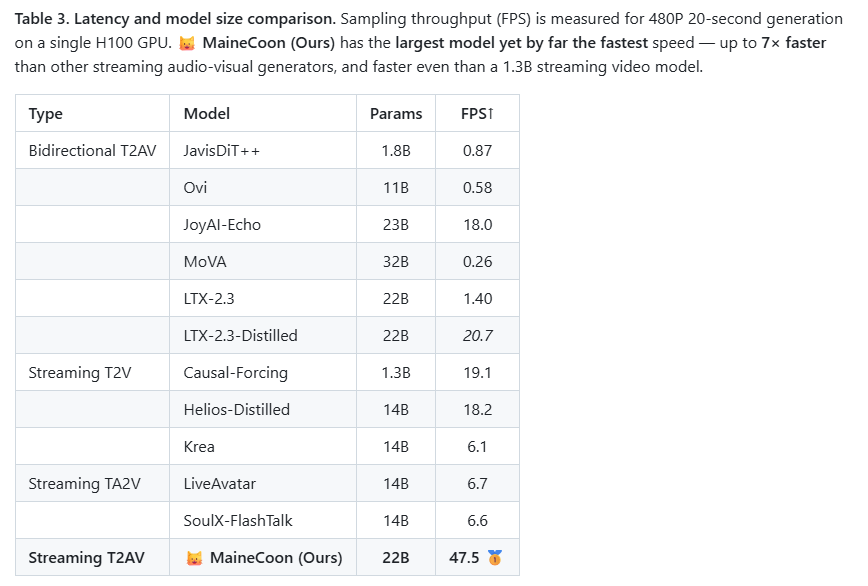
根据官方提供的信息得知,这个模型最高可以实现每秒47.5FPS。
而一般流媒体视频是每秒24到30帧,这个帧率已经超过了普通流媒体视频的播放帧率。
也就是只要跑起来,它理论上可以24小时不停歇地生成并播放。官方说目前只支持连续生成播放30分钟,但我觉得以后肯定可以实现24小时,只是稳定性上可能会有比较大的考验。
2.音画同步生成
这里我让角色从开心逐渐变得委屈,在情绪变化的情况下,声音仍然紧贴表情和嘴型。
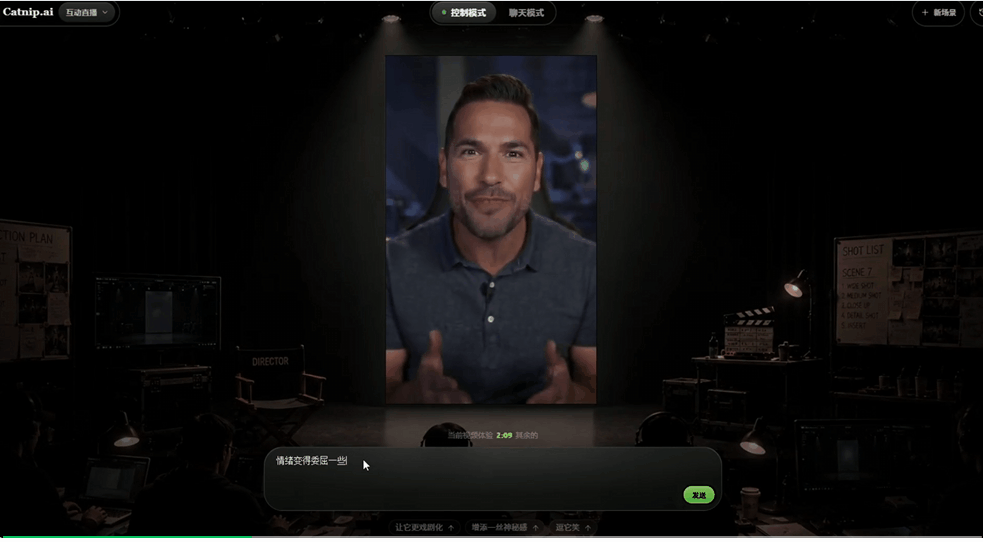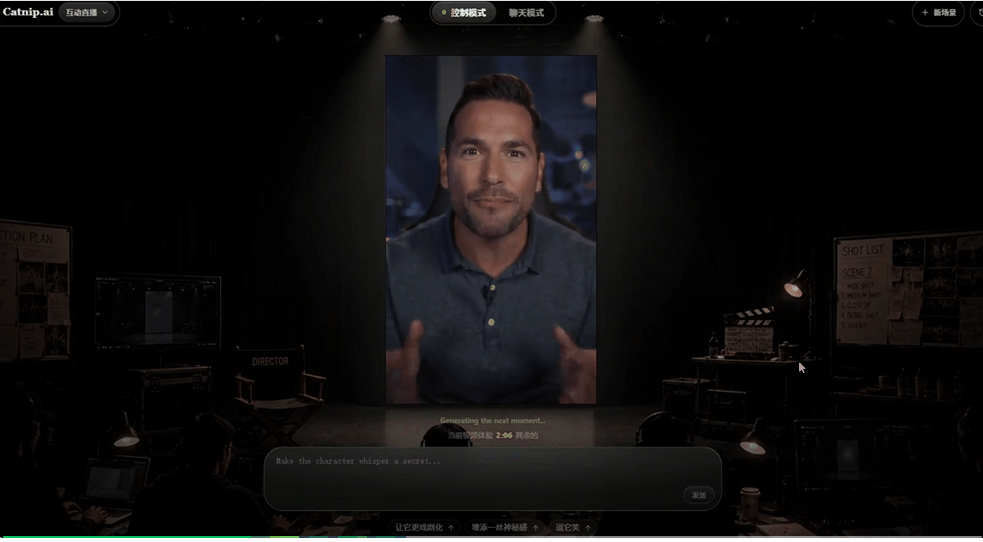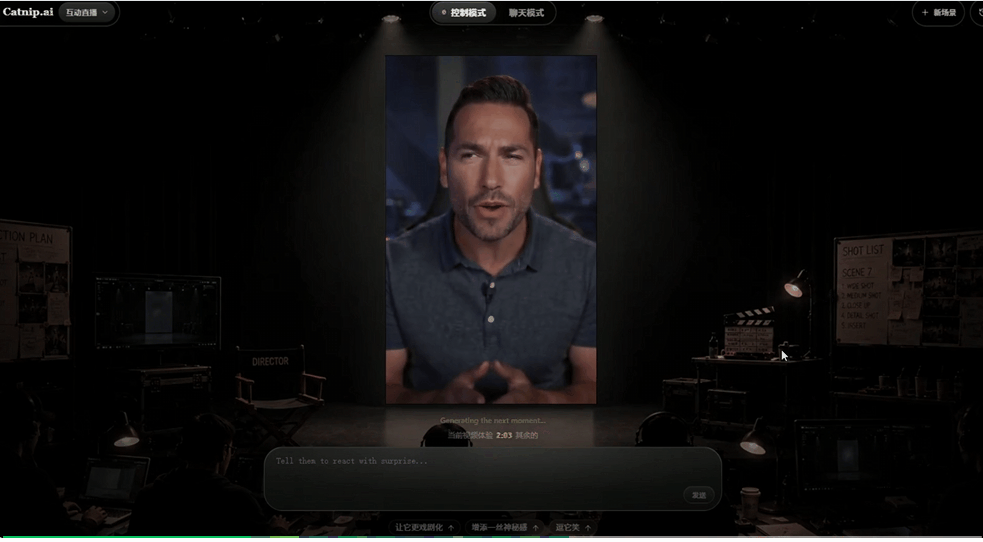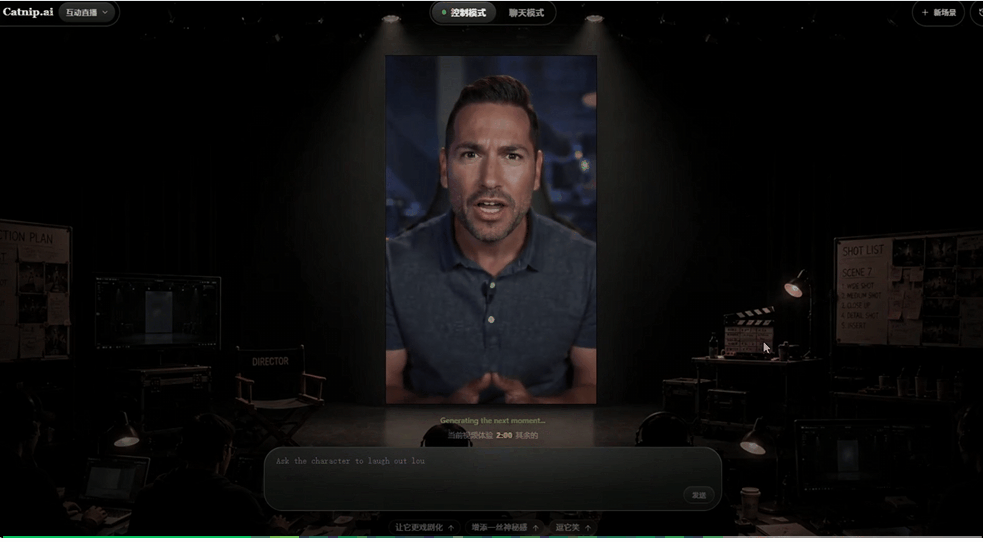
这种协同变化的能力,才是让视频有活人感的关键。
这个时候就有人要说了:很多传统的AI视频模型不是也能音画同步生成吗?这有啥新鲜的。
其实音画同步生成这个东西,也是去年才出现的,还算比较新鲜。更何况,我们要考虑到这是边生成边播放。
也就是模型不仅要考虑画面,还要考虑音频,这其实就给模型增加了一个维度,会额外消耗性能,他们能在实现实时播放的同时还能解决音视频同步,本身就挺牛的。
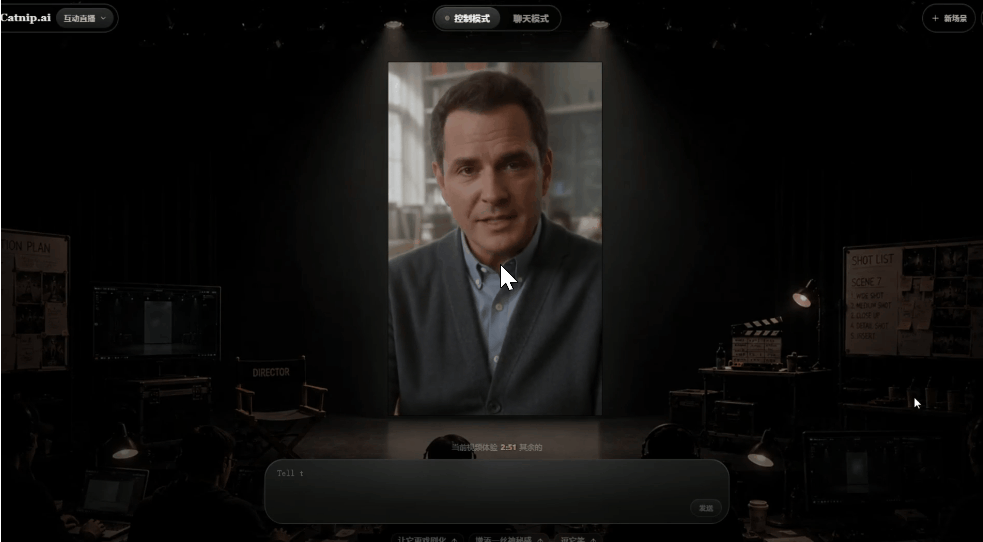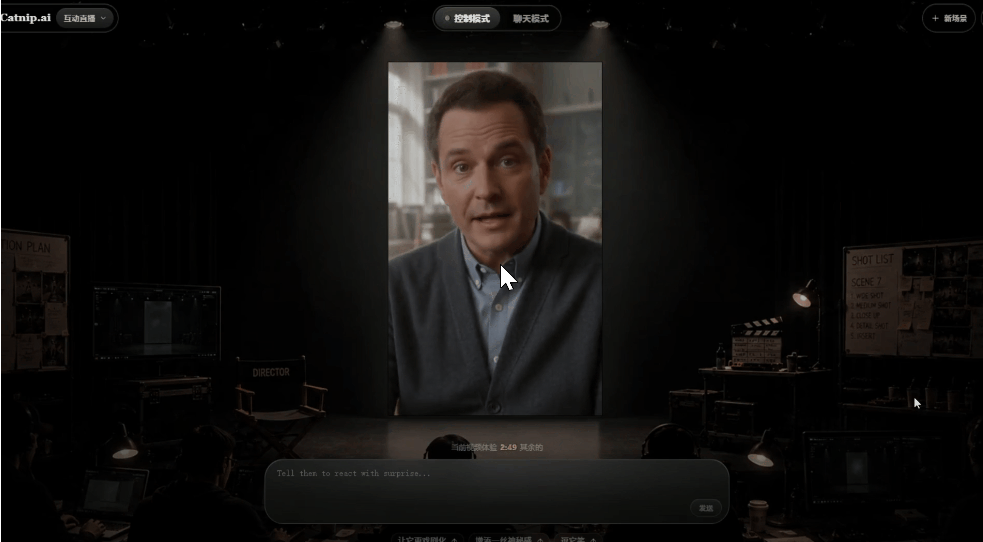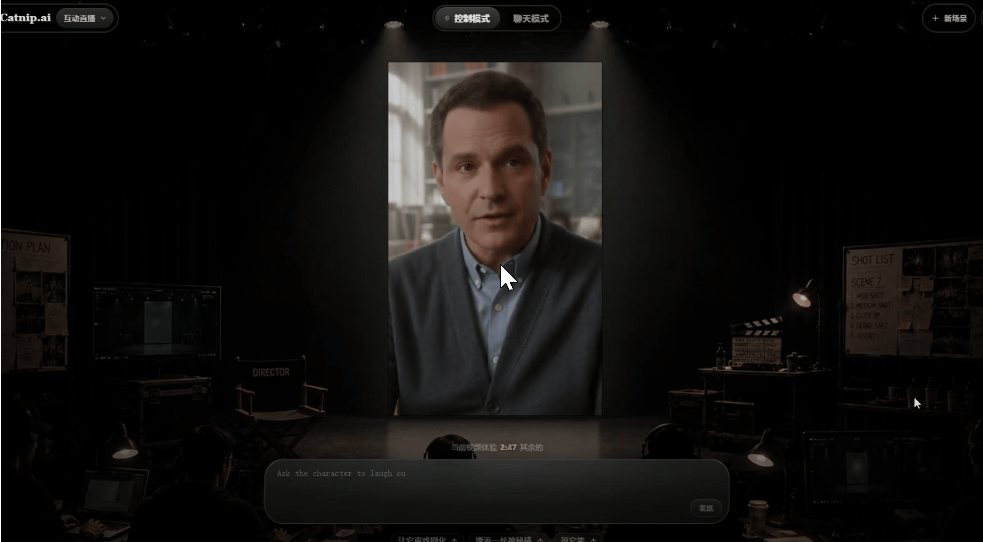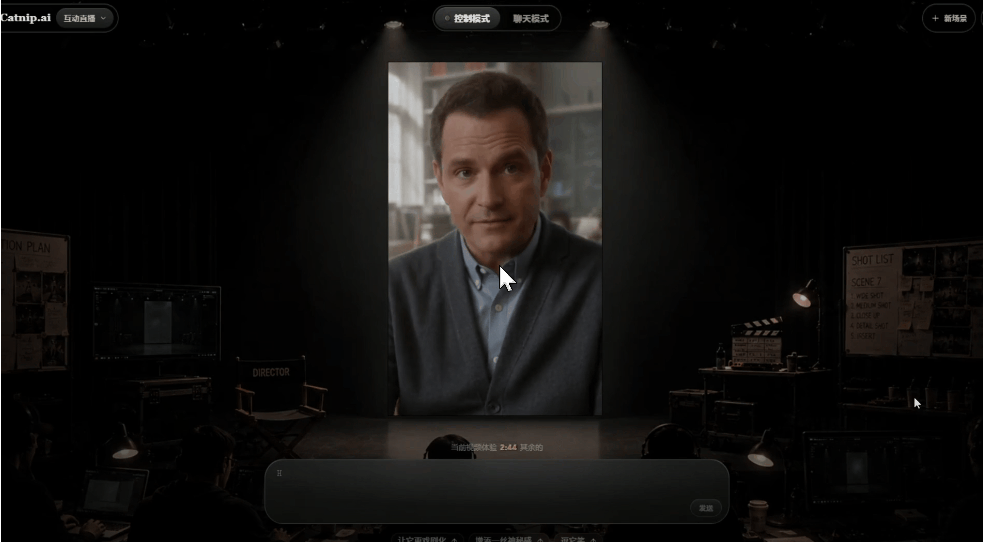
3.中途交互控制
这个视频播放过程中,我分别让角色"笑出来"、"转头看一下左边"、"变得紧张",视频都按照指令发生了改变。
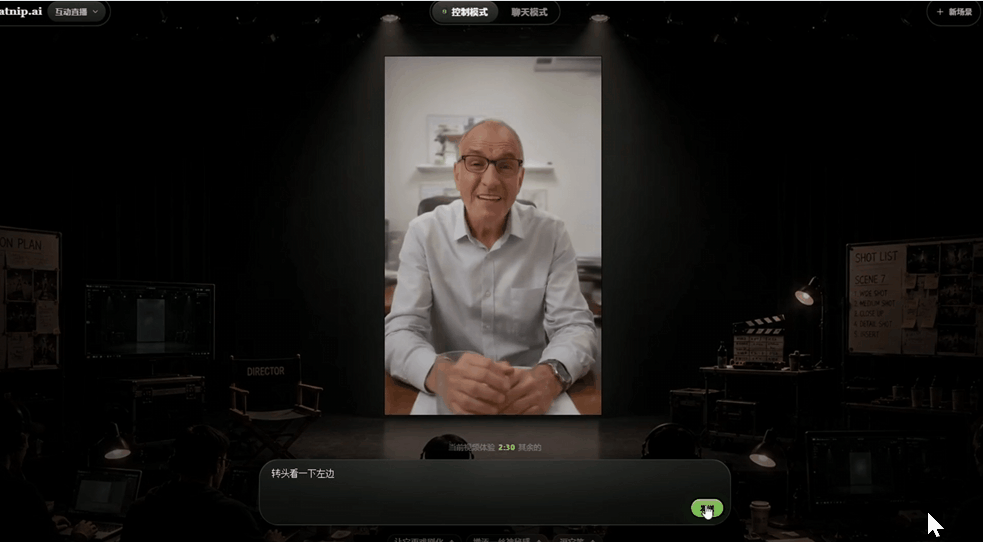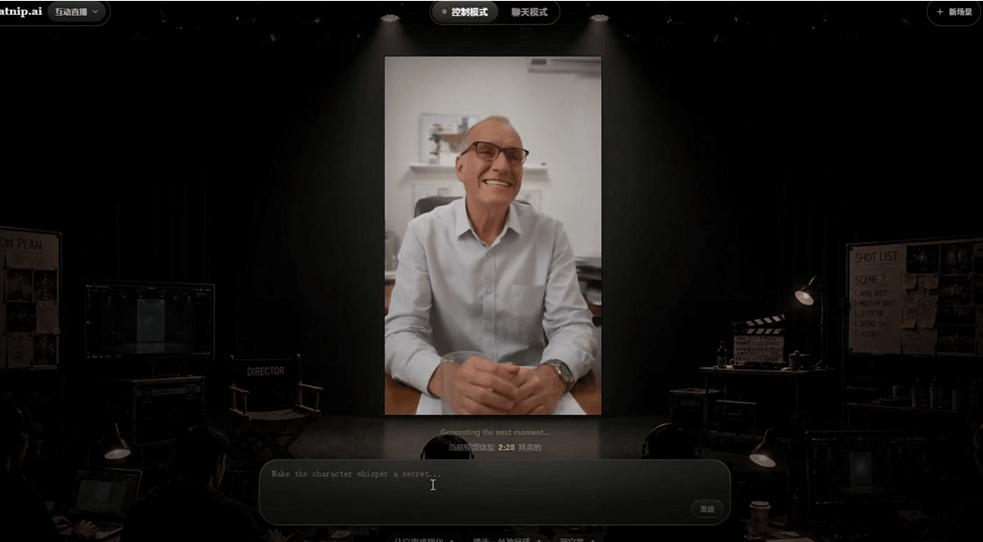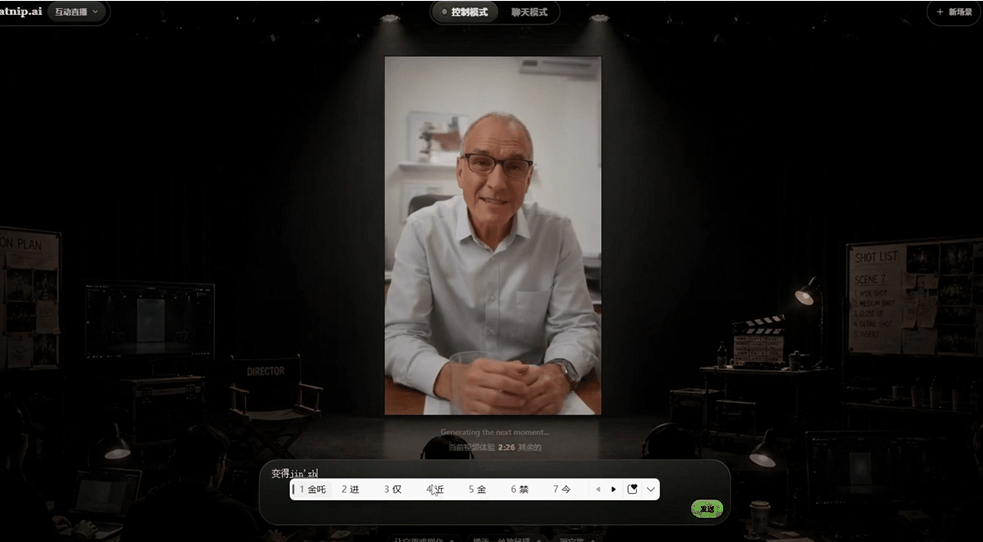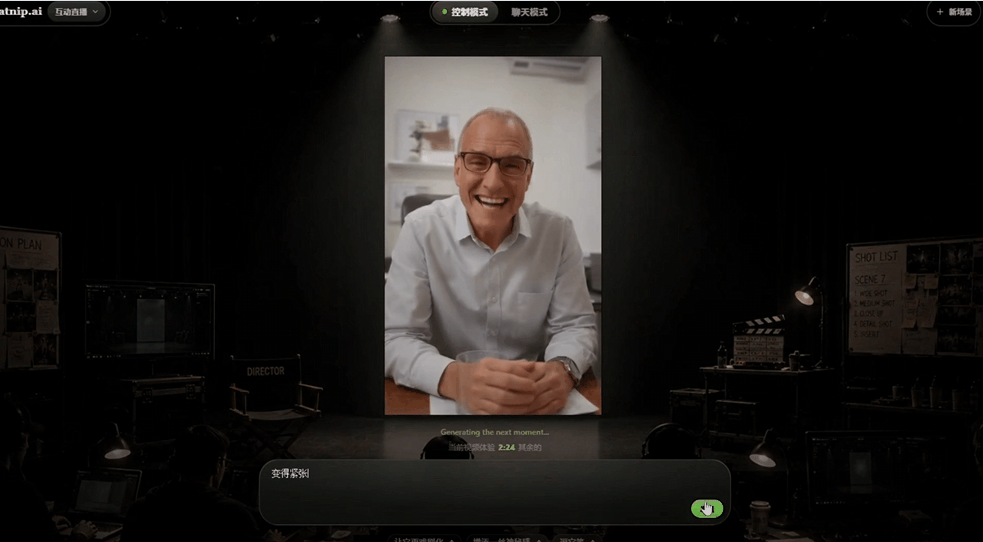
同时画面也很自然,不会突然变化,而是说完当前话题之后,再做出相应的变化。
这个延迟时间大概是六七秒钟左右这样,虽然有一点点的延迟感,但为了保证画面流畅和话题平稳转换,也是可以理解的事情。
4.生成稳定性
根据官方介绍,这个模型可以连续生成30分钟的视频。现在用来测试的网站只开放了最长三分钟的生成,更长的效果后续应该会逐步开放。
我用下来发现,只要场景提示词写得巧妙一些的话,这三分钟的视频播放过程中,画面可以从头到尾保持稳定。
这其实非常难得,因为你用传统AI视频模型生成,一个10秒钟的时候,可能都需要抽卡个两三次才能得到自己想要的画面。
当然,前提是得提示词要写得巧妙一点,比如画面中不要有多余的元素,尽量少的展现背景画面等等。
我在使用过程中就遇到画面崩掉的情况,比如下面这个角色还在说话,但同时也在喝水,以及手和杯子重叠等问题。

但是瑕不掩瑜,概率崩坏相较于模型表现出来的性能,其实是可以接受的。
另外,我分别用SoulX和LiveAvatar以及缅因猫跑了同一个场景,前两个虽然也是实时生成的视频模型,但都是数字人模型,主要是根据输入的音频来实现对口型的画面生成。

而缅因猫是更接近传统AI视频模型的纯生成的模型,只是在此基础上加入了同步播放的功能。
从视频里也能很明显的看出它与另外两个模型的对比,前两个模式是只有主角会有画面变化,背景几乎无变化,有一点微小的变化,背景人物还直接分裂了。
而缅因猫则是视频生成,背景也会有变化,而且画面更加稳定,崩坏的地方更少。
放这个对比,也是为了展示一下,它和AI数字人视频生成的本质区别。一个是基于人物画像根据上传的音频来改变角色面部,一个是整幅画面都是完全生成的。
为什么要做"实时流式"视频模型?
这个时候就有同学要说了:做这个东西有什么意义吗,画质看起来也没现在的主流视频模型好啊。
确实,画质相比较主流模型要差一些,但它主打的本来就不是画质好,而是流式生成。
现在主流的AI视频模型都是先生成再播放,用户只能在生成前或生成后参与,在生成过程中就什么都做不了了。
这就好像在现实生活中拍戏,导演跟演员说演一下这段戏,然后导演就被锁在门外,等5分钟后门才打开,然后导演只能看表演的回放。
如果导演想要修改其中的某段戏,就只能让演员重新再演一遍。

实时流式生成更像真实的现场导戏场景,演员在表演过程中,你可以随时喊"表情更丰富些",或者让他立刻说某个台词,演员也可以立即调整。
通过实时流式生成这种方式,AI视频就不再是一个生成完之后再看的成品,而是一个可以持续被影响的实时画面。
虽然听起来都是 AI 视频生成,但其实这已经是另外一个东西,适用场景也不同。

传统AI视频生成可以用在电影、短剧、广告等视频制作中,而缅因猫这种流式生成的视频,可以实时影响角色情绪、语气、动作和剧情走向等,所以可以在下面这些领域得到应用:
**1.AI视频客服:**可以根据客户的问题实时生成画面并解答。
**2.虚拟主播:**可以持续与弹幕互动,而不只是按照预设脚本输出内容。
**3.实时互动内容:**比如互动短剧,可以根据用户输入实时改变角色反应和剧情走向。
**4.教育和培训:**语言陪练、销售培训、面试模拟、心理陪伴等等,都可以从文字对话升级到面对面的实时互动。
而这些场景,则是传统的AI视频生成模式做不到的。
因为反馈速度从几分钟变成了几秒,AI视频就产生了质变,蜕变出了新的形态,也诞生了更多的应用方向。
总结一下
过去几年,AI视频的核心叙事一直是让视频更好看,这个阶段其实更注重内容生产,是为了帮创作者更快产出更好的内容。
而从MaineCoon可以看到的方向,是消费侧的改变,AI视频不再只是生成工具,而是互动媒介。
未来某些行业或许会因为MaineCoon产生一些变化,让许多内容固定的领域,变得可以互动,根据用户的反馈随时改变。
比如现在和豆包语音通话,以后也许就可以变成视频通话,豆包可以在另一头根据你说话的内容,实时做出动态表情和动作
MaineCoon现在还只是起步阶段,目前这个模型也才做了两个月,阿枫非常期待后续的更新迭代,毕竟他们团队实力强劲,未来可期(听说他们还在做一个更厉害的全新实时互动模型)~
如果你对AI角色、互动视频、虚拟陪伴、AI视频客服这类方向感兴趣,这个模型值得拿邀请码试一下。但也要有心理预期,它现在还是早期版本,惊喜和bug都会同时存在~