GPU Direct DMA RDMA 技术文档
参考 https://docs.nvidia.com/cuda/gpudirect-rdma/index.html
1. 技术原理
1.1 什么是 GPU Direct RDMA
GPU Direct RDMA(Remote Direct Memory Access)是 NVIDIA 提供的一种高性能数据传输技术,允许第三方 PCIe 设备(如 FPGA、网卡、视频采集卡)绕过 CPU 和系统内存,通过 PCIe 总线直接与 GPU 显存进行数据交换。
传统数据路径(FPGA → GPU):
FPGA ──DMA──→ CPU内存 ──cudaMemcpy──→ GPU显存
↑ ↑
PCIe传输 内存总线拷贝
(第1次) (第2次)GPU Direct RDMA 路径(FPGA → GPU):
FPGA ──PCIe DMA──→ GPU显存
↑
仅一次PCIe传输
零CPU拷贝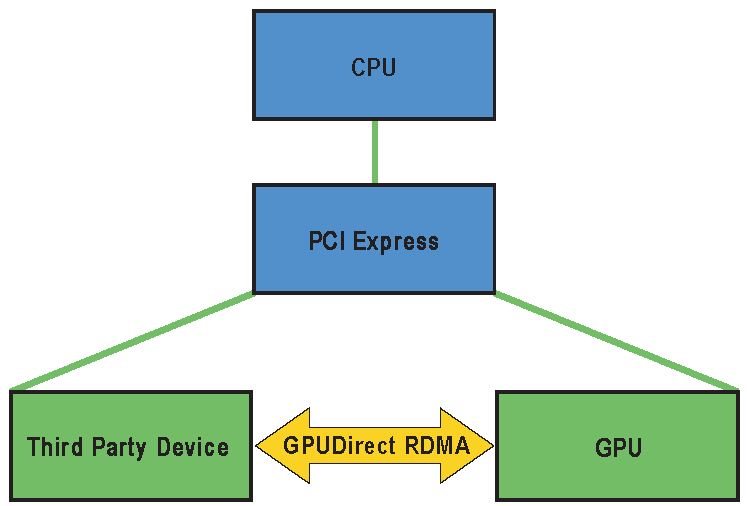
1.2 核心优势
| 优势 | 说明 |
|---|---|
| 延迟降低 | 消除 CPU 中间拷贝,端到端延迟减少约 50% |
| 带宽提升 | 避免内存总线争用,有效带宽提升 1.5x~2.5x |
| CPU卸载 | DMA 传输期间 CPU 完全空闲,可处理其他任务 |
| 零拷贝 | 数据直达 GPU,无需系统内存中转缓冲 |
| 确定性延迟 | 无 CPU 调度干扰,适合实时系统 |
1.3 适配设备与平台
| 平台 | 支持状态 | GPU 类型 | 备注 |
|---|---|---|---|
| NVIDIA Jetson Orin (Tegra) | ✅ 已验证 | 集成 GPU (统一内存) | 通过 nvidia-p2p 内核接口 |
| NVIDIA Jetson Xavier | ✅ 可适配 | 集成 GPU | 同 Orin 架构 |
| x86 + NVIDIA 独立显卡 | ✅ 可适配 | Tesla/Quadro | 需 nvidia-peermem 模块 |
| FPGA(Xilinx Kintex/Artix) | ✅ 已验证 | N/A | 通过 XDMA IP 核 + 自定义驱动 |
| 其他 PCIe DMA 设备 | ✅ 可扩展 | - | 需实现 Pin/Unpin/Transfer ioctl |
1.4 工作流程
1. GPU 缓冲区分配 (cudaHostAlloc / cudaMalloc)
2. Pin 操作: 将 GPU 虚拟地址映射为物理页面,锁定在内存中
3. DMA 传输: FPGA 直接读写 GPU 物理页面(通过 PCIe BAR)
4. Unpin 操作: 释放页面锁定关键点:Pin 操作仅需执行一次,后续可无限次复用同一 Handle 进行 DMA 传输,避免了传统方式中每次传输都需要的地址转换开销。
2. 测试环境
2.1 硬件平台
星测电子JetKU 硬件,FPGA 与 Jetson NX 之间是PCIe Gen3x4, FPGA 有2GB 缓存,使用XIlinx XDMA IP
| 组件 | 规格 |
|---|---|
| 嵌入式平台 | NVIDIA Jetson Orin (aarch64) |
| GPU | Orin 集成 Ampere GPU, 统一内存架构 |
| FPGA | Xilinx 系列, PCIe Gen3 x4 |
| FPGA 端内存 | DDR4 2GB |
| PCIe 链路 | Gen3 x4 (理论峰值 ~4GB/s) |
| 系统内存 | LPDDR5 (统一内存) |
2.2 软件环境
| 组件 | 版本 |
|---|---|
| OS | Ubuntu 22.04 (aarch64) |
| CUDA | 12.6 |
| 内核驱动 | HelloFPGA XDMA 自定义驱动 (v2020.2.2) + GPU Direct 扩展 |
| 用户空间库 | libHelloFPGACore.so (含 GPU Direct 兼容层) |
| 编译器 | nvcc (CUDA 12.6) + GCC |
2.3 驱动架构
用户空间: HelloFPGACore.so (TransferMode API)
│
├─ CPU模式: open(/dev/HelloFPGA0_c2h_*) → read/write
│
└─ GPU Direct模式: open → ioctl(XDMA_IOC_GPU_PIN/XFER/UNPIN)
│
内核空间: HelloFPGA.ko (XDMA + xdma_gpu_direct + xdma_gpu_tegra)
│
硬件: FPGA XDMA IP ←──PCIe──→ GPU BAR (物理地址直通)3. 测试方法
3.1 测试工具
测试程序: gpu_direct_api_test.cu
支持两种运行模式:
- 快速功能测试: 验证 API 正确性 + 性能对比(约 2 分钟)
- 长稳态压力测试 : 12 小时持续运行,每 10 分钟记录数据(
--long参数)
3.2 测试对比方案
| 路径编号 | 方案名称 | 数据流向 | 说明 |
|---|---|---|---|
| A | CPU DMA 仅 | FPGA → CPU 内存 | 传统 DMA,数据停留在 CPU 侧 |
| B | FPGA→CPU→GPU 全路径 | FPGA → CPU → GPU | 传统方式将数据送达 GPU 的完整路径 |
| C | GPU Direct Handle | FPGA → GPU 直达 | 预 Pin + DMA 直传,无 CPU 中转 |
3.3 测试项目
| 测试项 | 内容 |
|---|---|
| API 功能验证 | GetStatus / Pin / ReadC2H / WriteH2C / Unpin |
| 数据正确性 | 写入 pattern → 回读 → 逐字节比对 |
| 多尺寸性能 | 4KB ~ 8MB,6 种尺寸全覆盖 |
| 2GB 地址空间 | 遍历 FPGA 0~2GB 全范围,验证无地址死角 |
| 多缓冲区轮转 | 4 帧 GPU 缓冲区循环采集,对比单缓冲区 |
| TransferMode 兼容 | 老接口零修改,内部自动路由至 GPU Direct |
| 12 小时稳定性 | 72 次采样,功耗/性能/抖动全记录 |
3.4 关键参数
- 传输块大小: 4MB(长测试) / 4KB~8MB(快速测试)
- FPGA 地址步进: 64MB(遍历 0~2GB,32 个测试点/轮)
- 采样频率: 每 10 分钟(长测试)
- 每采样点迭代: 5 次取平均
- 功耗采集: INA3221 传感器 (VDD_IN 通道)
4. 测试结果
4.1 多尺寸性能对比(快速测试)
时延对比 (μs,越小越好)
| 数据大小 | CPU DMA 仅 | FPGA→CPU→GPU 全路径 | GPU Direct | 加速比 (vs CPU) | 加速比 (vs 全路径) |
|---|---|---|---|---|---|
| 4KB | 82.6 / 58.4 | 232.8 / 86.2 | 54.4 / 45.4 | 1.52x / 1.29x | 4.28x / 1.90x |
| 64KB | 87.8 / 80.4 | 122.4 / 195.2 | 70.2 / 74.4 | 1.25x / 1.08x | 1.74x / 2.62x |
| 512KB | 341.8 / 301.6 | 635.2 / 740.2 | 292.0 / 243.4 | 1.17x / 1.24x | 2.18x / 3.04x |
| 1MB | 638.4 / 574.6 | 1016.0 / 1219.2 | 521.2 / 412.6 | 1.22x / 1.39x | 1.95x / 2.95x |
| 4MB | 2398.0 / 2102.8 | 3417.6 / 3522.2 | 1773.6 / 1487.0 | 1.35x / 1.41x | 1.93x / 2.37x |
| 8MB | 4888.2 / 4250.0 | 6564.8 / 6507.6 | 3557.4 / 2951.2 | 1.37x / 1.44x | 1.85x / 2.21x |
表格格式: Read / Write
带宽对比 (GB/s,越大越好)
| 数据大小 | CPU DMA 仅 | FPGA→CPU→GPU | GPU Direct |
|---|---|---|---|
| 512KB | 1.53 / 1.74 | 0.83 / 0.71 | 1.80 / 2.15 |
| 1MB | 1.64 / 1.82 | 1.03 / 0.86 | 2.01 / 2.54 |
| 4MB | 1.75 / 1.99 | 1.23 / 1.19 | 2.36 / 2.82 |
| 8MB | 1.72 / 1.97 | 1.28 / 1.29 | 2.36 / 2.84 |
GPU Direct 峰值带宽达 2.84 GB/s,逼近 PCIe Gen2 x4 理论极限
4.2 TransferMode 兼容模式性能
用户代码零修改 (仍调用 HelloFPGA_DMA_MM_*),仅通过 2 行配置切换模式:
| 数据大小 | CPU 模式 (μs) | GPU_PINNED 模式 (μs) | 加速比 |
|---|---|---|---|
| 4KB | 79.6 / 65.4 | 57.8 / 51.8 | 1.38x / 1.26x |
| 64KB | 140.4 / 123.2 | 69.8 / 75.0 | 2.01x / 1.64x |
| 256KB | 198.2 / 210.6 | 141.4 / 155.2 | 1.40x / 1.36x |
| 1MB | 607.0 / 677.8 | 417.2 / 487.6 | 1.45x / 1.39x |
| 4MB | 2183.2 / 2516.2 | 1491.8 / 1781.4 | 1.46x / 1.41x |
| 8MB | 4279.4 / 4977.4 | 2954.4 / 3541.0 | 1.45x / 1.41x |
格式: Write / Read
4.3 多缓冲区 vs 单缓冲区对比
模拟实际图像采集场景:4 个 GPU 缓冲区轮转 vs 单缓冲区重复读写(100 次迭代,1MB/帧)
| 指标 | 多缓冲区 (4帧轮转) | 单缓冲区 | 差异 |
|---|---|---|---|
| 平均时延 | 501.7 μs | 491.9 μs | - |
| 最小时延 | 460.0 μs | 455.0 μs | - |
| 最大时延 | 1124.0 μs | 660.0 μs | - |
| 平均带宽 | 2.09 GB/s | 2.13 GB/s | - |
| 等效帧率 | 1993 fps | 2033 fps | - |
| 比值 | - | - | 0.98x (基本一致) |
结论:多缓冲区地址查表匹配开销可忽略不计,不影响性能。
4.4 12 小时长稳态测试
- 测试时长: 12.00 小时
- 采样点数: 72 次(每 10 分钟)
- 传输块大小: 4MB
- 地址遍历: 0 ~ 2GB(完成 2 轮完整遍历)
性能统计
| 指标 | CPU DMA 仅 | FPGA→CPU→GPU | GPU Direct |
|---|---|---|---|
| 平均 Read (μs) | 2711.9 | 3518.3 | 1785.1 |
| 平均 Write (μs) | 2276.2 | 3701.2 | 1489.0 |
| 平均带宽 Read | 1.55 GB/s | 1.19 GB/s | 2.35 GB/s |
| 平均带宽 Write | 1.84 GB/s | 1.13 GB/s | 2.82 GB/s |
加速比
| 对比基准 | Read | Write |
|---|---|---|
| GPU Direct vs CPU DMA | 1.52x | 1.53x |
| GPU Direct vs 传统全路径 | 1.97x | 2.49x |
性能稳定性
| 指标 | GPU Direct Read | GPU Direct Write |
|---|---|---|
| 最小时延 | 1749.6 μs | 1461.2 μs |
| 最大时延 | 2008.0 μs | 1554.6 μs |
| 抖动 (max-min) | 258.4 μs | 93.4 μs |
| 相对波动 | ±7.2% | ±3.1% |
时间趋势(无退化)
| 时段 | GPU Read 平均 | GPU Write 平均 | 功耗 |
|---|---|---|---|
| 0 ~ 4h | 1782 μs | 1483 μs | 18.38 W |
| 4 ~ 8h | 1784 μs | 1490 μs | 18.65 W |
| 8 ~ 12h | 1786 μs | 1488 μs | 18.78 W |
功耗统计
| 指标 | 数值 |
|---|---|
| 平均功耗 | 18.57 W |
| 最小功耗 | 18.23 W |
| 最大功耗 | 18.91 W |
| 波动范围 | 0.69 W (±1.8%) |
地址空间一致性
FPGA 全 2GB 地址范围(0MB ~ 1984MB,64MB 步进)的 GPU Direct 传输时延无显著差异(标准差 < 15μs),表明 FPGA 端 DDR 控制器对全地址空间性能一致。
5. 结论
5.1 性能结论
-
GPU Direct 相比传统全路径 (FPGA→CPU→GPU) 加速 ~2x
- Read 加速 1.97x,Write 加速 2.49x(4MB 块,12h 平均)
- 消除 cudaMemcpy 中间拷贝是主要收益来源
-
GPU Direct 相比 CPU DMA 仅加速 ~1.5x
- 即使不计算 cudaMemcpy,GPU Direct 仍因零拷贝架构优势快 50%
-
峰值带宽达 2.84 GB/s
- 接近 PCIe Gen2 x4 理论峰值(~2GB/s 实际可用约 3.2GB/s 含协议开销)
5.2 稳定性结论
- 12 小时无性能退化:前 4h 与后 4h 性能差异 < 0.3%
- 无内存泄漏:Pin/Unpin 生命周期管理正确
- 无热节流:功耗稳定在 18.2~18.9W,无过热降频
- 2GB 全地址空间一致:无 FPGA 端 DDR 热点
5.3 兼容性结论
- 完全向后兼容:老代码无需任何修改即可继续使用
- 最小侵入接入:仅需新增 2 行代码(SetGPUBuffer + SetTransferMode)
- 多缓冲区无开销:4 帧轮转性能与单帧一致,适合图像流应用
5.4 适用场景建议
| 场景 | 推荐方案 | 预期加速 |
|---|---|---|
| FPGA 图像采集 → GPU 推理 | GPU Direct (多缓冲) | 2.0x |
| FPGA 信号处理 → GPU 计算 | GPU Direct (单缓冲) | 1.5x~2.0x |
| FPGA ↔ CPU 数据交换(不涉及GPU) | 传统 CPU DMA | 无需切换 |
| 小数据包 (< 4KB) | 传统 CPU DMA | GPU Direct 优势不明显 |
5.5 建议与限制
- 最小传输块建议 ≥ 64KB:小数据包中 DMA 建立开销占比大,GPU Direct 优势有限
- Pin 操作仅需一次:应在初始化阶段完成,避免传输循环中频繁 Pin/Unpin
- 4K 对齐要求:GPU 缓冲地址和大小必须 4096 字节对齐
- 需 root 权限:GPU Direct ioctl 需要特权访问设备文件