做过几年架构的人都遇到过这个场面:某天 code review,发现一个 Controller 直接 @Autowired 了 JdbcTemplate 在查数据库,绕过了 Service。问起来,答「这次比较急,先这么写」。
架构图贴在墙上,分层写得清清楚楚。可代码是活的,它会随每一次「图方便」悄悄偏移。等你发现时,Controller 已经散落在各处直连数据库、两个业务模块缠成了死结、循环依赖改都改不动。
靠人盯,盯不住的。 这篇就讲我怎么把架构边界写成测试,让机器来盯。
一、架构腐化的三种典型
不是有人故意搞破坏,都是「这一次图方便」累积出来的。我见得最多的三种:
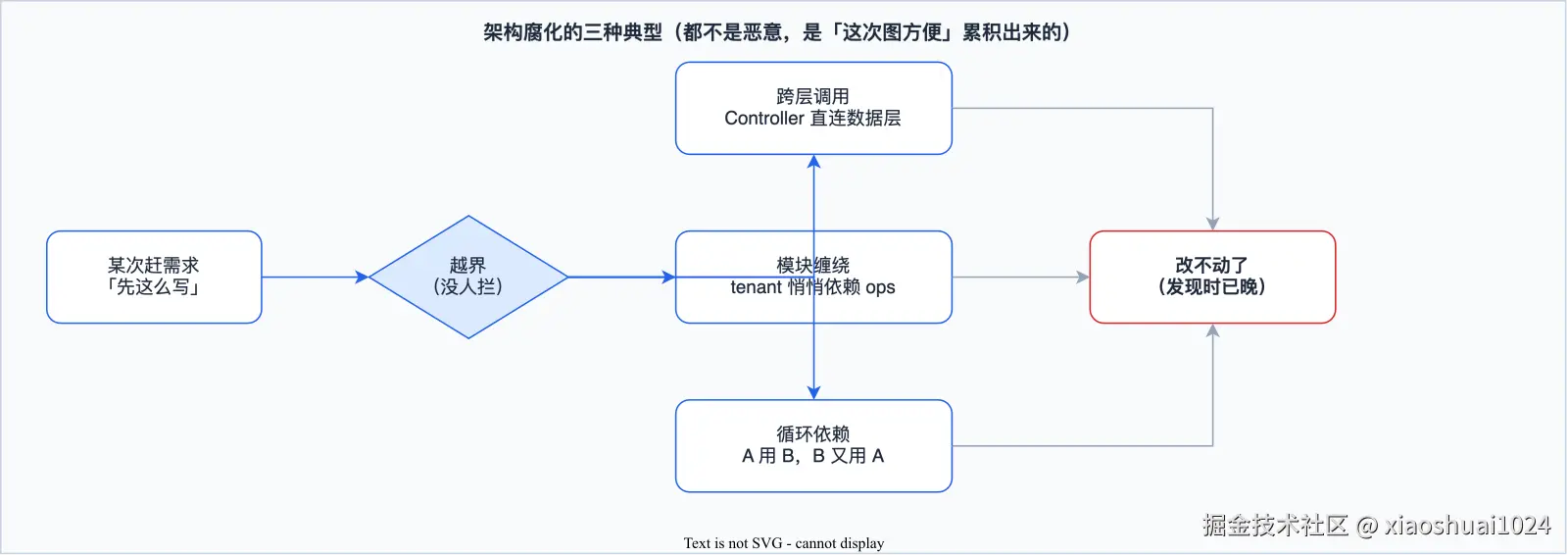
跨层调用最常见。Controller 本来只该做路由和参数校验,但有人嫌 Service 套一层麻烦,直接把 JdbcTemplate 拉进来查库。一次两次没事,等这个模式扩散开,分层就成了摆设。
模块缠绕更要命。康豆有十几个业务模块------tenant、trade、circle、marketing...本来该各管各的。但今天 tenant 模块需要算一笔佣金,顺手 import 了 trade 的 Repository;明天 trade 又用了 tenant 的工具类。半年后想拆微服务,发现拆不动,因为没人记得清谁依赖谁。
循环依赖是缠绕的极端形态。A 依赖 B,B 又反过来依赖 A,编译能过(运行时可能爆),但删一个就崩一串。这种债最难还。
这三种,你写进规范文档没人看,写进周会强调没人记。唯一管用的,是让它编译不过、测试不过。
二、先解决一个现实问题:存量怎么办
引入架构测试,第一个拦路虎是存量。
康豆引入 ArchUnit 的时候,代码已经写了两个月了。一跑,Controller 直连数据层的违规 467 处,业务层用 SQL 注解的 84 处。要是让测试直接 fail,CI 当场全红,谁也推不动。
所以我们用了 ArchUnit 的 FreezingArchRule------冻结存量、只拦新增。
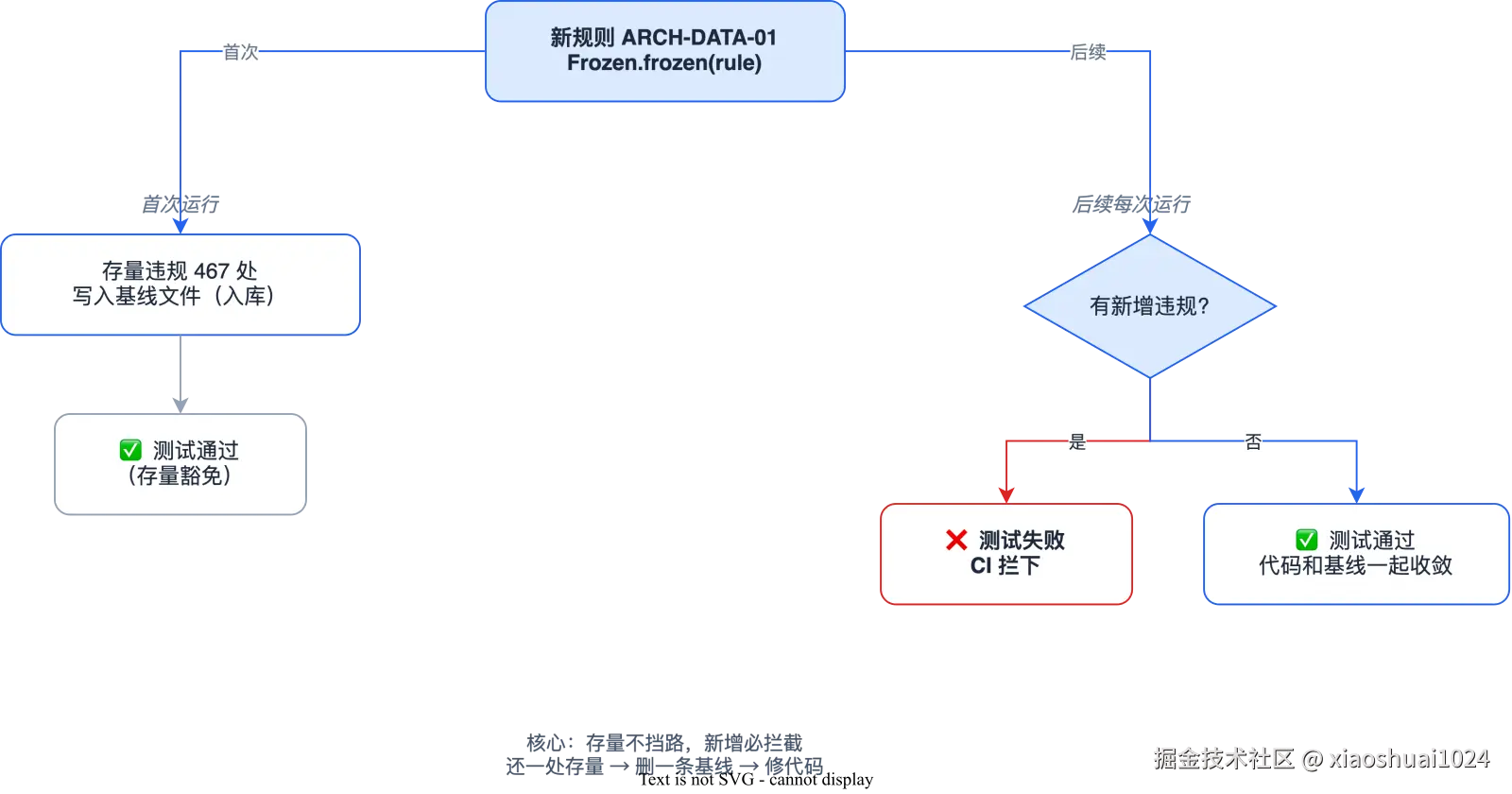
机制很简单:把规则包一层 Frozen.frozen(rule),首次运行时把所有存量违规记进一个基线文件(入库),之后只对新增违规报错。这样老代码不挡路,但谁再写新的越界代码,CI 立刻拦下来。
java
public final class Frozen {
public static ArchRule frozen(ArchRule rule) {
return FreezingArchRule.freeze(rule);
}
}我们那次首跑冻结了 551 处存量违规 ,基线文件入库。从那以后,存量违规只能减不能增------还一处就删一处基线,代码和基线一起收敛。这是老项目引入架构守护唯一可行的姿势:不追求一步到位,先把增量锁死。
这个思路也写进了项目约束:「新增违规由 ArchUnit 自动拦截;存量通过 freeze 基线豁免,修复存量时从基线删除对应条目并修代码。」
三、后端 ArchUnit:五类规则守住边界
康豆的后端,架构规则分五类,共 14 条。我挑关键的讲。
第一类,分层依赖(ARCH-LAYER)。 最核心的两条:
java
// Controller 不得直接访问 Repository / Mapper / JdbcTemplate
@ArchTest
static final ArchRule ARCH_LAYER_01Controller不访问数据层 =
Frozen.frozen(noClasses()
.that().haveSimpleNameEndingWith("Controller")
.should().accessClassesThat(
simpleNameEndingWith("Repository")
.or(simpleNameEndingWith("Mapper"))
.or(type(JdbcTemplate.class)))
.as("Controller 不得直接访问 Repository / Mapper / JdbcTemplate")
.because("数据访问须经 Service 委托,Controller 仅负责路由与参数校验"));
// @Transactional 只能在 Service 层
@ArchTest
static final ArchRule ARCH_LAYER_02Transactional仅Service =
Frozen.frozen(noClasses()
.that().haveSimpleNameNotEndingWith("Service")
.should().beAnnotatedWith(Transactional.class)
.as("@Transactional 只能在 Service 层使用")
.because("事务边界统一在 Service 层管理"));注意每条规则都带 .as() 和 .because()。规则本身就是文档------违反时测试报告直接打印中文说明和理由,新人一看就懂为什么挂了,不用去翻规范文档。
第二类,模块隔离(ARCH-ISO)。 这类是为微服务拆分预留边界的:
java
// tenant 模块不得依赖 ops 模块(C 端与运营端解耦)
@ArchTest
static final ArchRule ARCH_ISO_01tenant不依赖ops =
Frozen.frozen(noClasses()
.that().resideInAPackage("com.kangdou.tenant..")
.and().resideOutsideOfPackage("com.kangdou.tenant..controller.ops..")
.should().dependOnClassesThat().resideInAPackage("com.kangdou.ops..")
.as("tenant 不得依赖 ops(controller.ops 运营 Controller 白名单豁免)"));还有一条更狠的:13 个业务模块之间,不得访问对方的 repository/mapper 包。用自定义 ArchCondition 实现------遍历每个类的依赖,一旦发现跨模块调到别人的数据访问内部包,就报违规。这条规则等于在代码层画了 13 个圈,圈里的数据只能圈里的人碰。
第三类,数据访问纪律(ARCH-DATA)。 这是 Q4 阶段加的,为微服务拆分铺路:
java
// 业务层(非 Mapper/Repository)不得调用 JdbcTemplate
@ArchTest
static final ArchRule ARCH_DATA_01业务层不调JdbcTemplate =
Frozen.frozen(noClasses()
.that(BUSINESS_LAYER)
.should().accessClassesThat(type(JdbcTemplate.class))
.as("业务层不得调用 JdbcTemplate")
.because("JdbcTemplate 只能在数据访问层(为微服务拆分预留边界)"));这条第一次跑,命中 467 个文件。但用 freeze 冻结后,新写的业务类再想直连 JdbcTemplate,直接被拦。
第四类,命名规范(ARCH-NAMING)。 这类看着琐碎,但很有用------命名即契约:
@RestController的类必须以 Controller 结尾;- 以 Controller 结尾的类必须有
@RestController注解。
这两条是对称校验,双向堵:防止有人起名叫 XxxController 却忘了加注解,也防止有人加了注解却忘了改名字。
第五类,安全门禁(ARCH-SAFE)。 两条,都来自真实事故:
java
// 定时任务所在类不得调用 TenantContext.getTenantId
@ArchTest
static final ArchRule ARCH_SAFE_02定时任务不调TenantContext =
Frozen.frozen(noClasses()
.that(DECLARES_SCHEDULED_METHOD)
.should().callMethod(TenantContext.class, "getTenantId")
.as("@Scheduled 所在类不得调用 TenantContext.getTenantId")
.because("定时任务无 HTTP 上下文,getTenantId 必为 null"));这条是因为踩过坑:定时任务里调 TenantContext.getTenantId(),但定时任务没有 HTTP 上下文,拿到的是 null,导致一批数据写错了租户。踩过的坑固化成规则,这就是「事故即规范」的架构层落地。
四、前端:dependency-cruiser 守依赖方向
后端有 ArchUnit,前端对应的是 dependency-cruiser。它干的事一样------把依赖方向写成规则,让机器查。
前端的腐化方式和后端不太一样,最典型的是底层反向依赖业务层 。比如 src/api/(封装接口请求的底层)不知什么时候 import 了 src/pages/(业务页面),底层的就不再「底层」了,改一处动全身。
康豆前端用 dependency-cruiser 守了 7 条,核心逻辑是给每个目录定一个层级,只许上层依赖下层,不许反过来:
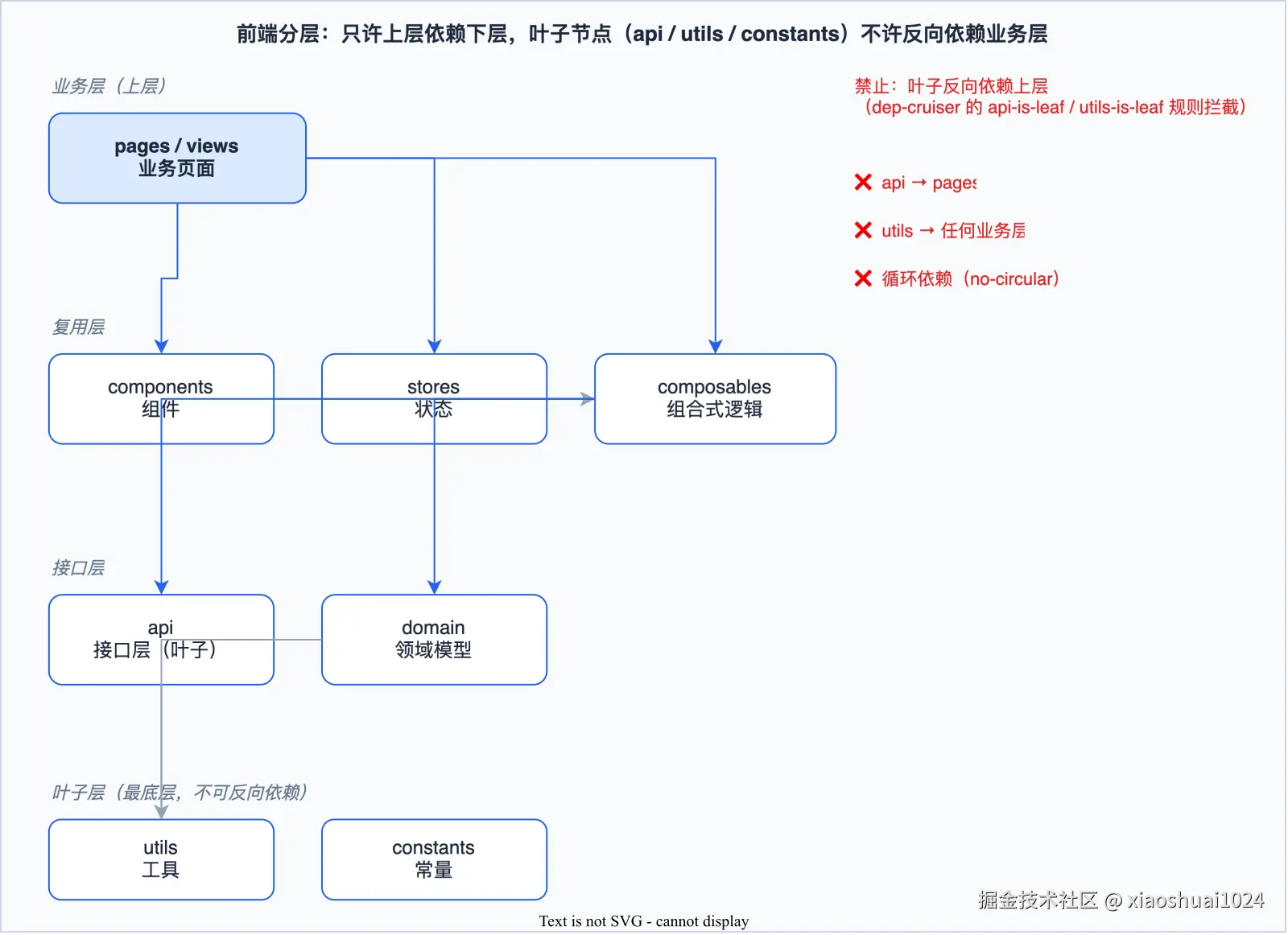
对应的规则很直白:
js
// api 是底层,禁止反向依赖业务层
{
name: 'api-is-leaf',
severity: 'error',
comment: 'src/api/ 是底层,禁止反向依赖业务层',
from: { path: '^src/api/' },
to: { path: '^src/(pages|components|stores|composables|domain)/' }
},
// 禁止循环依赖
{
name: 'no-circular',
severity: 'error',
from: {},
to: { circular: true }
}api、utils、constants 是叶子节点------它们不能反过来依赖业务层。composables 不能依赖页面。这些规则配上 no-circular(全局禁循环依赖),基本把前端的分层钉死了。
还有一条很妙的------E2E 双线隔离:
js
// e2e/h5 不能 import e2e/miniprogram,反之亦然
{
name: 'e2e-h5-not-miniprogram',
severity: 'error',
comment: 'e2e/h5 不能 import e2e/miniprogram',
from: { path: '^e2e/h5/' },
to: { path: '^e2e/miniprogram/' }
}康豆是同一套代码出 h5 和小程序两端,E2E 测试也分两套。这条规则防止 h5 的测试脚本偷偷引用了小程序的,导致测试串味。这种细分场景的规则,是真刀真枪用出来的,不是抄模板。
跑法上,前端用了 severity 分级模拟后端的 freeze:error 级拦新增(循环依赖、双线隔离),warn 级容存量(api-is-leaf)。配套命令 npm run arch:test 守护、arch:report 还能生成 dot 架构图可视化。
五、eslint 自定义规则:补 dependency-cruiser 管不到的
dependency-cruiser 管的是文件间依赖,但有些约定它管不了,得靠自定义 eslint 规则。康豆前端写了 5 条 kd/ 命名空间的规则:
kd/no-raw-uni-request:禁止直调uni.request,只能走统一的http.ts。白名单就两个文件。这是防接口调用散落各处、绕过统一鉴权和错误处理。kd/require-data-e2e:交互元素(button、带 @click 的)必须带data-e2e属性------给 E2E 测试留选择器。kd/no-chinese-class:禁止 CSS class 含中文。踩过坑,uni-app 的 WXSS 编译会直接失败。kd/no-emoji:全仓禁 emoji,UI 和标识符里都不能有。kd/max-vue-file-lines:.vue 文件不超过 500 行,超了就 warning。
这几条看着杂,但每条背后都是踩过的坑。架构守护不全是高大上的分层,也包括这些土但管用的小钉子。
六、为什么 AI 时代更需要架构守护
最后说个时机问题:为什么我现在特别强调架构守护?
因为 AI 写代码,不认架构边界。
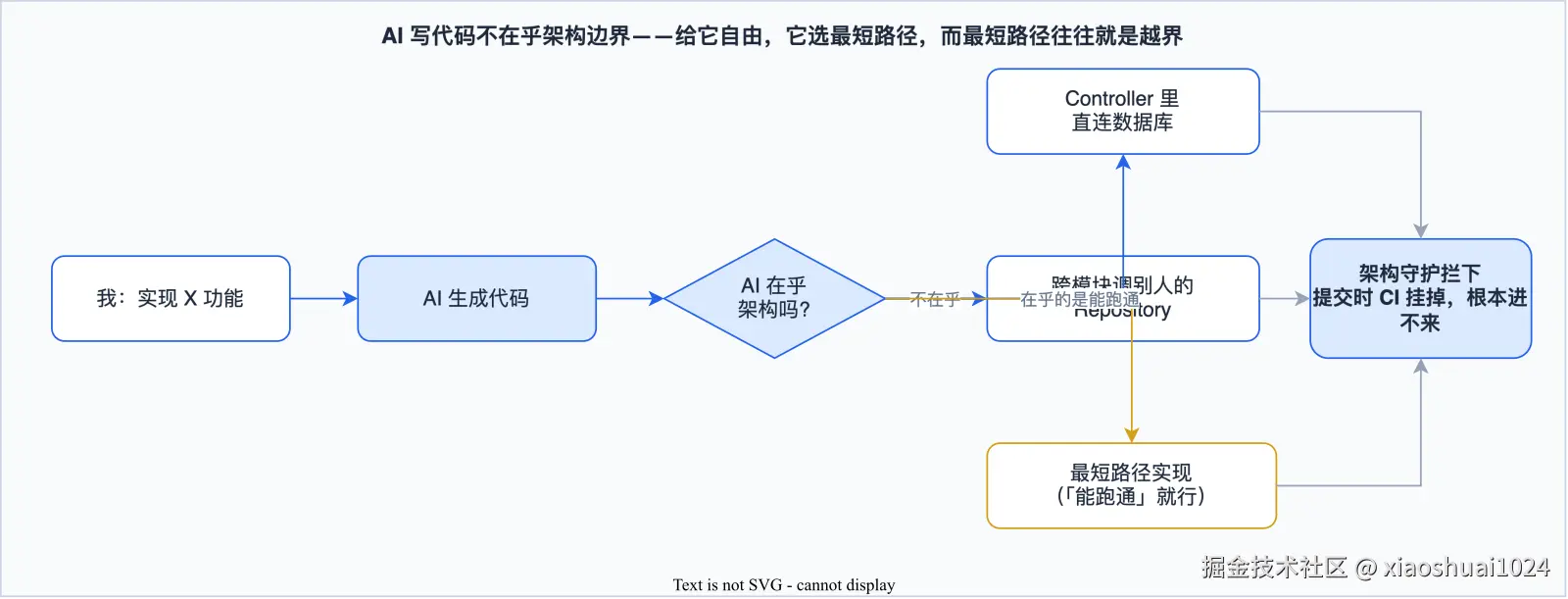
AI 优化的目标是「让这个功能跑通」,它不在乎 Controller 该不该碰数据库、不在乎 tenant 该不该依赖 ops。给它自由,它会选最短路径,而最短路径往往就是越界。
康豆 4 个人 + AI,日均 14 次提交。如果靠人 review,根本看不过来 AI 生成的东西越没越界。有了架构测试,AI 写的越界代码提交时 CI 就挂,根本进不来。 这是 AI 协同时代,架构守护从「锦上添花」变成「必需品」的原因。
七、收尾:约定要能被机器检查,才叫约定
回头看这套东西,核心就一句话:写进文档的约定会随时间失效,写进测试的约定不会。
架构图会过时,规范文档没人看,周会强调没人记。但 ArchUnit 测试和 dependency-cruiser 规则,每次 mvn verify、每次 npm run arch:test 都会跑。约定一旦变成机器能检查的规则,它就不会被人忘掉。
而且这套东西和团队大小无关------4 个人需要,40 个人更需要。区别只在于:团队越小,越没人力 review,越得靠机器盯。这套架构守护,与其说是技术决策,不如说是「让小团队能跑起来」的组织决策。
如果你也在为一个不断膨胀的项目头疼,我的建议是:别急着画新架构图,先把你最在意的边界写成一条架构测试。先拦住新增,再慢慢还存量。