GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
一、Motivation
现代图像生成模型(如 Stable Diffusion、FLUX、Nano Banana Pro 等)的生成质量已经很强,但开放式图像生成远不是一个简单的"prompt → 图像"问题。真实的用户请求往往涉及以下挑战:
- 外部知识缺口:用户可能要求画一个特定的历史文物(如安提基特拉机械),生成器本身可能不知道它长什么样。
- 参考图选择:需要搜索合适的视觉参考,并判断哪些值得信任。
- 内部知识激活:即使生成器有相关知识,也需要知道何时激活(比如何时需要空间布局指导、何时需要文字渲染指导)。
- 多信号综合:将搜索到的事实、选中的参考图、激活的生成知识综合成一个生成器能理解的指令方案。
现有的 agentic 生成系统(如 GenAgent、Gen-Searcher、Mind-Brush 等)已经开始用搜索、工具、记忆等方式增强图像生成,但它们通常只解决了生成过程中的某一环(获取外部证据、包装黑盒生成器、推理时优化prompt),没有将整个过程作为一个统一的可学习对象来训练。
GenEvolve 的核心动机就是:把图像生成建模为一个完整的多步决策轨迹(trajectory),让 agent 学会协调外部工具和内部知识,并通过自进化不断改进决策策略。
二、Related Work
2.1 图像生成模型
从 Latent Diffusion、DiT 到 FLUX、Nano Banana Pro,生成模型的保真度和文本理解能力不断提升。统一多模态模型(如 Chameleon、Emu3、BAGEL 等)探索了理解与生成的联合架构。但这些模型本质上仍是生成器------它们不会主动决定何时搜索、信任哪些参考、激活哪些知识。
2.2 Agentic 图像生成
| 方法 | 核心特点 | 局限 |
|---|---|---|
| GenAgent | 多轮推理、工具调用、判断与反思 | 没有统一训练工具使用与生成策略 |
| Gen-Searcher / ORIG | 搜索/检索增强生成 | 侧重外部证据获取 |
| GEMS / Mind-Brush | 引入记忆、可复用技能、研究式工作流 | 侧重单一组件 |
| Maestro / CRAFT | 批评者反馈、约束驱动纠正 | 在推理时迭代优化,未端到端训练 |
这些方法的共同局限:通常只优化了生成过程的某一部分,或是在黑盒生成器外面包了一层工作流,没有将工具使用、参考选择、知识激活和 prompt 构造作为统一的可学习目标。
2.3 On-Policy Distillation
On-policy distillation 是一种后训练范式:让 student 模型自己生成输出,然后让拥有额外特权信息的 teacher 对这些输出进行指导,student 从中学习。核心循环是:student 生成 → teacher 用特权信息纠正 → student 更新参数 → 重复。
各变体的区别在于 teacher 的特权信息是什么:
| 方法 | Teacher 的特权信息 |
|---|---|
| OPSD | 标准答案、额外背景信息等特权上下文 |
| OPCD | prompt 中的 few-shot 示范、chain-of-thought |
| SDPO | 多维度的丰富反馈信号 |
| Skill-SD | 多步 agent 轨迹的技能摘要 |
| GenEvolve | 从好坏轨迹对比中提取的结构化视觉经验 |
GenEvolve 的特权信息不是标准答案或推理轨迹,而是"好轨迹和差轨迹的对比总结"------哪些搜索策略更好、哪些技能该调用、参考图怎么选、prompt 怎么构造。
三、Method
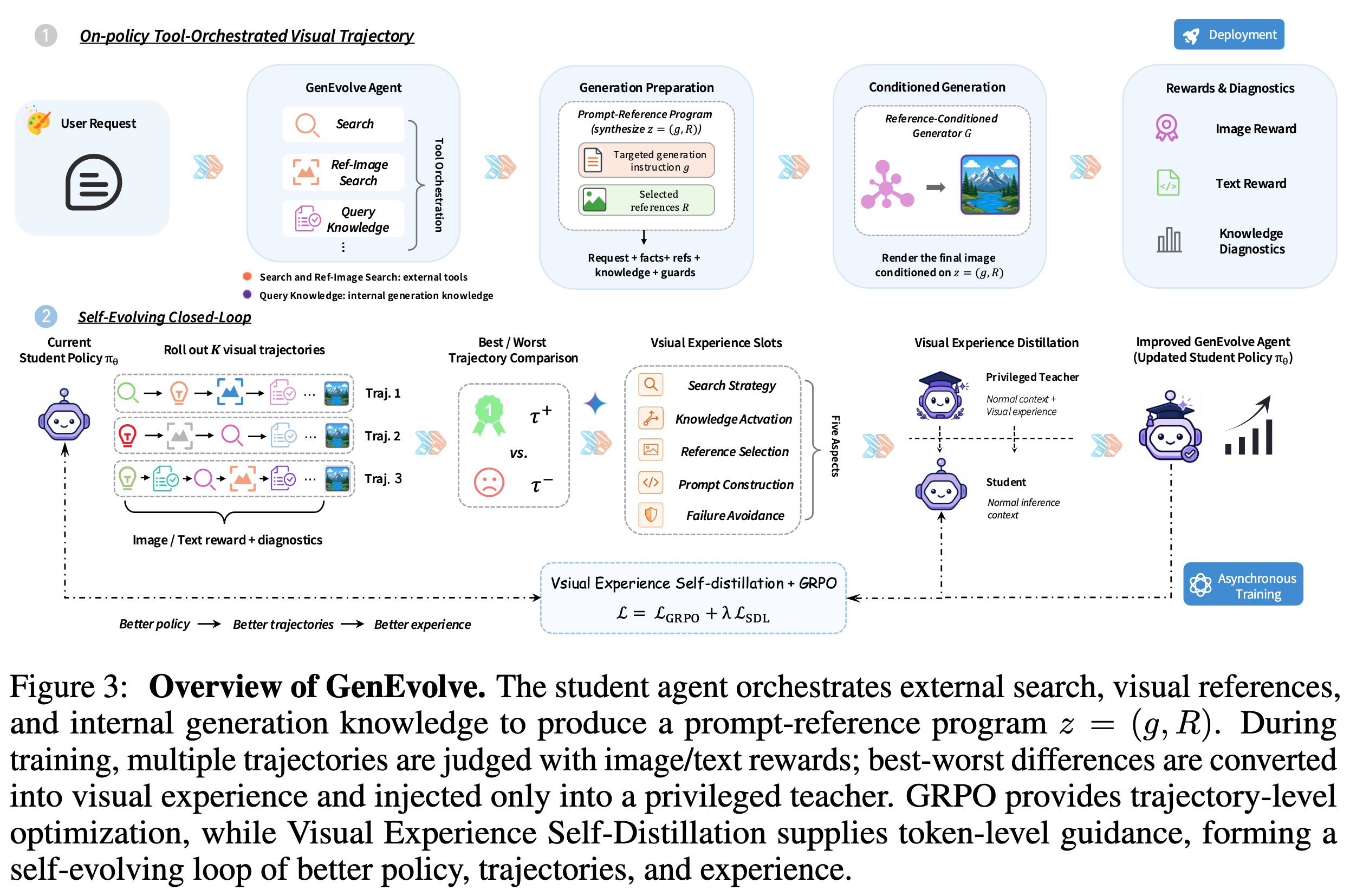
3.1 Tool-Orchestrated Visual Trajectory Formulation
GenEvolve 将每次图像生成建模为一条工具编排的视觉轨迹。给定用户请求 xxx,agent 不是直接生成图像,而是执行多步决策循环:
ht=(x,a1,o1,...,at−1,ot−1),at∼πθ(a∣ht),ot∼T(o∣ht)h_t = (x, a_1, o_1, \ldots, a_{t-1}, o_{t-1}), \quad a_t \sim \pi_\theta(a|h_t), \quad o_t \sim T(o|h_t)ht=(x,a1,o1,...,at−1,ot−1),at∼πθ(a∣ht),ot∼T(o∣ht)
每一步 agent 根据历史 hth_tht 选择一个动作 ata_tat(调用工具或给出最终答案),环境返回观察 oto_tot(搜索结果、参考图等)。
最终输出的不是图像本身,而是一个 prompt-reference 生成方案:
z=(g,R)z = (g, R)z=(g,R)
其中 ggg 是精心构造的生成 prompt,RRR 是选中的参考图集合。然后由参考条件生成器 GGG 渲染出最终图像 y^=G(g,R)\hat{y} = G(g, R)y^=G(g,R)。
Agent 的动作空间包含三类工具:
| 工具 | 功能 | 信息来源 |
|---|---|---|
search(q) |
搜索文本事实(名称、日期、规格等) | 外部互联网 |
image_search(q) |
检索候选视觉参考 | 外部互联网 |
query_knowledge(skill_name) |
激活内部生成知识 | 内部知识库 |
内部生成知识被实例化为 8 个可调用的 skill:text_rendering、spatial_layout、anatomy_body_coherence、aesthetic_drawing、attribute_binding、creative_drawing、physical_material_consistency、quantity_counting。
Agent 采用 ReAct 风格 (Reasoning + Acting)的交互格式:先 <think> 推理,再 <tool_call> 或 <answer>,每步决策都显式地记录为 token 序列,使其可观察、可训练。
3.2 GenEvolve-Data 构建流水线

数据构建分五个阶段:
① Prompt Pool:从结构化配方(recipe)生成约 20000 个 prompt,分 Knowledge-Anchored(60%,需要外部知识)和 Quality-Anchored(40%,侧重生成质量)两个 track,覆盖 16 个类别。配方字段(任务类型、知识缺口、视觉锚点、主要需求、难度)用于覆盖率控制和分层划分,但不暴露给 agent。
② Teacher Trajectory:用 Seed2.0 和 Gemini 3 Pro 作为 teacher 模型,对每个 prompt 跑真实的多轮工具交互循环,生成约 20000 条有效轨迹。
③ VLM Filtering:两层过滤。程序化检查去除格式和协议错误;VLM 裁判审查参考图是否支持视觉细节、证据是否被使用、最终方案是否整合了约束。保留约 70%。
④ GT Images & Splits:用 Nano Banana Pro 渲染高质量 GT 图像,再经视觉过滤,得到约 3200 个案例。数据导出为两种视图:
- SFT 视图:保留完整轨迹,不含 GT 图像(防止 student 抄答案)
- 视觉反馈视图:包含 prompt + GT 图像 + 元数据(用于 RL 和评测)
⑤ GenEvolve-Bench:Held-out 评测集,用 KScore 协议统一评估。
3.3 SFT Cold Start
用 teacher 轨迹做监督微调,初始化 agent 的基础能力:
LSFT(θ)=−1∑mi,t∑i∑tmi,tlogπθ(yi,t∗∣hi,t∗)\mathcal{L}{\text{SFT}}(\theta) = -\frac{1}{\sum m{i,t}} \sum_i \sum_t m_{i,t} \log \pi_\theta(y^*{i,t} | h^*{i,t})LSFT(θ)=−∑mi,t1i∑t∑mi,tlogπθ(yi,t∗∣hi,t∗)
只优化 assistant 侧的 token(thinking + tool call + final answer),user prompt 和 tool observation 作为上下文被 mask 掉。视觉编码器和多模态投影层冻结,只训练语言模型参数。
3.4 GRPO:轨迹级优化
对每个 prompt 采样 K=6 条轨迹,用混合 reward 评分:
R=0.5×Rimg+0.5×RtextR = 0.5 \times R_{\text{img}} + 0.5 \times R_{\text{text}}R=0.5×Rimg+0.5×Rtext
其中 RimgR_{\text{img}}Rimg 是 KScore 风格的图像评分(faithfulness、visual correctness、text accuracy、aesthetics 四个维度),RtextR_{\text{text}}Rtext 是方案充分性评分(检查方案是否包含足够的事实、参考绑定、知识激活和约束)。
然后做组内相对比较算 advantage:
Ai=Ri−RˉσR+ϵA_i = \frac{R_i - \bar{R}}{\sigma_R + \epsilon}Ai=σR+ϵRi−Rˉ
用 clipped surrogate objective 更新策略。GRPO 提供的是 轨迹级信号------"哪条轨迹更好",但不告诉模型"为什么更好"。
3.5 Visual Experience Extraction
GRPO 的标量 reward 只能说"好/坏",不能说"为什么好/为什么坏"。GenEvolve 通过对比好坏轨迹来提取结构化的视觉经验。
对同一 prompt 的 K 条轨迹,找出最好的 τ+\tau^+τ+ 和最差的 τ−\tau^-τ−,如果 reward 差距 Δ≥δmin\Delta \geq \delta_{\min}Δ≥δmin(0.20),则用 VLM judge 提取五个经验 slot:
| Slot | 内容 |
|---|---|
| MsearchM_{\text{search}}Msearch | 搜索策略差异(比如好轨迹搜了"winner nationality",差轨迹搜了"winner flag"导致错误) |
| MknowM_{\text{know}}Mknow | 技能激活差异(好轨迹调了 spatial_layout,差轨迹漏调了) |
| MrefM_{\text{ref}}Mref | 参考图选择差异 |
| MpromptM_{\text{prompt}}Mprompt | prompt 构造差异(好轨迹用深度分层,差轨迹堆在一起) |
| MfailM_{\text{fail}}Mfail | 失败教训(差轨迹犯的具体错误) |
经验以 bundle 为单位存储在 prompt-keyed 的缓冲区中(容量500)。检索时用 Qwen3-Embedding-0.6B 计算新 prompt 和历史 source prompt 的余弦相似度,取最相似案例的全套五个 slot。这种 bundle retrieval 保证取出的经验是连贯的,不会从不同案例里各取一条导致矛盾。
3.6 Visual Experience Distillation (SDL)
Visual Experience Distillation 是 GenEvolve 区别于普通 GRPO 的核心创新。
Student 看到正常的推理上下文 c(x)c(x)c(x),teacher 看到注入了视觉经验的特权上下文 cE(x)=Patch(c(x),Mx)c_E(x) = \text{Patch}(c(x), M_x)cE(x)=Patch(c(x),Mx)。Teacher 不生成单独的轨迹,而是对 student 生成的同一组 token 重新评估概率。
对每个 token yi,ty_{i,t}yi,t,计算 student 和 teacher 的 log 概率差,然后用 reverse-KL 估计器:
ℓi,t=logpi,t−logqi,t,k3(ℓi,t)=exp(−ℓi,t)−1+ℓi,t\ell_{i,t} = \log p_{i,t} - \log q_{i,t}, \quad k_3(\ell_{i,t}) = \exp(-\ell_{i,t}) - 1 + \ell_{i,t}ℓi,t=logpi,t−logqi,t,k3(ℓi,t)=exp(−ℓi,t)−1+ℓi,t
SDL loss:
LSDL=1∑mi,tE∑i,tmi,tEmin(ρi,ton⋅k3(ℓi,t),ctok)\mathcal{L}{\text{SDL}} = \frac{1}{\sum m^E{i,t}} \sum_{i,t} m^E_{i,t} \min(\rho^{\text{on}}{i,t} \cdot k_3(\ell{i,t}), c_{\text{tok}})LSDL=∑mi,tE1i,t∑mi,tEmin(ρi,ton⋅k3(ℓi,t),ctok)
实践中只保留 teacher 和 student 分歧最大的 top 10% token,集中在关键决策点上。
3.7 总训练目标
LGenEvolve=LGRPO+λSDLLSDL\mathcal{L}{\text{GenEvolve}} = \mathcal{L}{\text{GRPO}} + \lambda_{\text{SDL}} \mathcal{L}_{\text{SDL}}LGenEvolve=LGRPO+λSDLLSDL
其中 λSDL=2.0\lambda_{\text{SDL}} = 2.0λSDL=2.0。两个 loss 的角色互补:
| GRPO | SDL | |
|---|---|---|
| 信号粒度 | 轨迹级 | Token 级 |
| 回答的问题 | 哪条轨迹更好 | 为什么更好(具体哪些 token 的决策应该改变) |
| 监控指标 | 看 reward 曲线是否上升 | 看 SDL loss 曲线是否下降 |
四、Experiments
4.1 实验设置
- Agent 骨干:Qwen3-VL-8B-Instruct
- 训练流程:SFT cold start → GRPO + SDL self-evolution
- 生成器:Qwen-Image-Edit(开源)和 Nano Banana Pro(闭源强生成器)
- 评测:GenEvolve-Bench(自建)+ WISE(外部公开 benchmark)
4.2 GenEvolve-Bench 主要结果(Table 1)
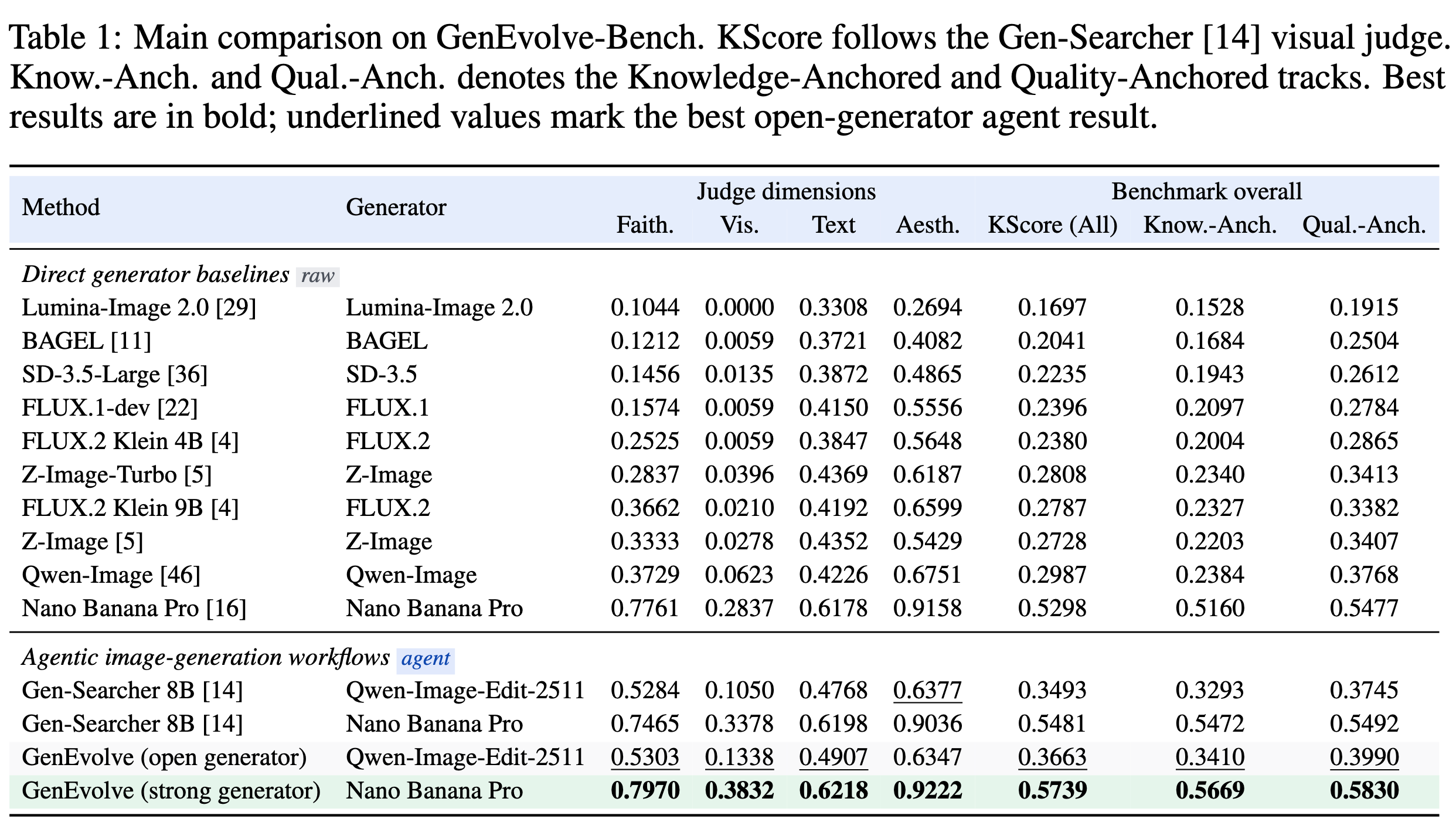
| 方法 | 生成器 | KScore |
|---|---|---|
| Qwen-Image(裸跑) | Qwen-Image | 0.2987 |
| Nano Banana Pro(裸跑) | Nano Banana Pro | 0.5298 |
| Gen-Searcher 8B | Qwen-Image-Edit | 0.3493 |
| Gen-Searcher 8B | Nano Banana Pro | 0.5481 |
| GenEvolve | Qwen-Image-Edit | 0.3663 |
| GenEvolve | Nano Banana Pro | 0.5739 |
GenEvolve 在两种生成器下都超过了对应的 Gen-Searcher baseline,说明学到的决策能力是 生成器可迁移的。
4.3 WISE 外部评测(Table 2)
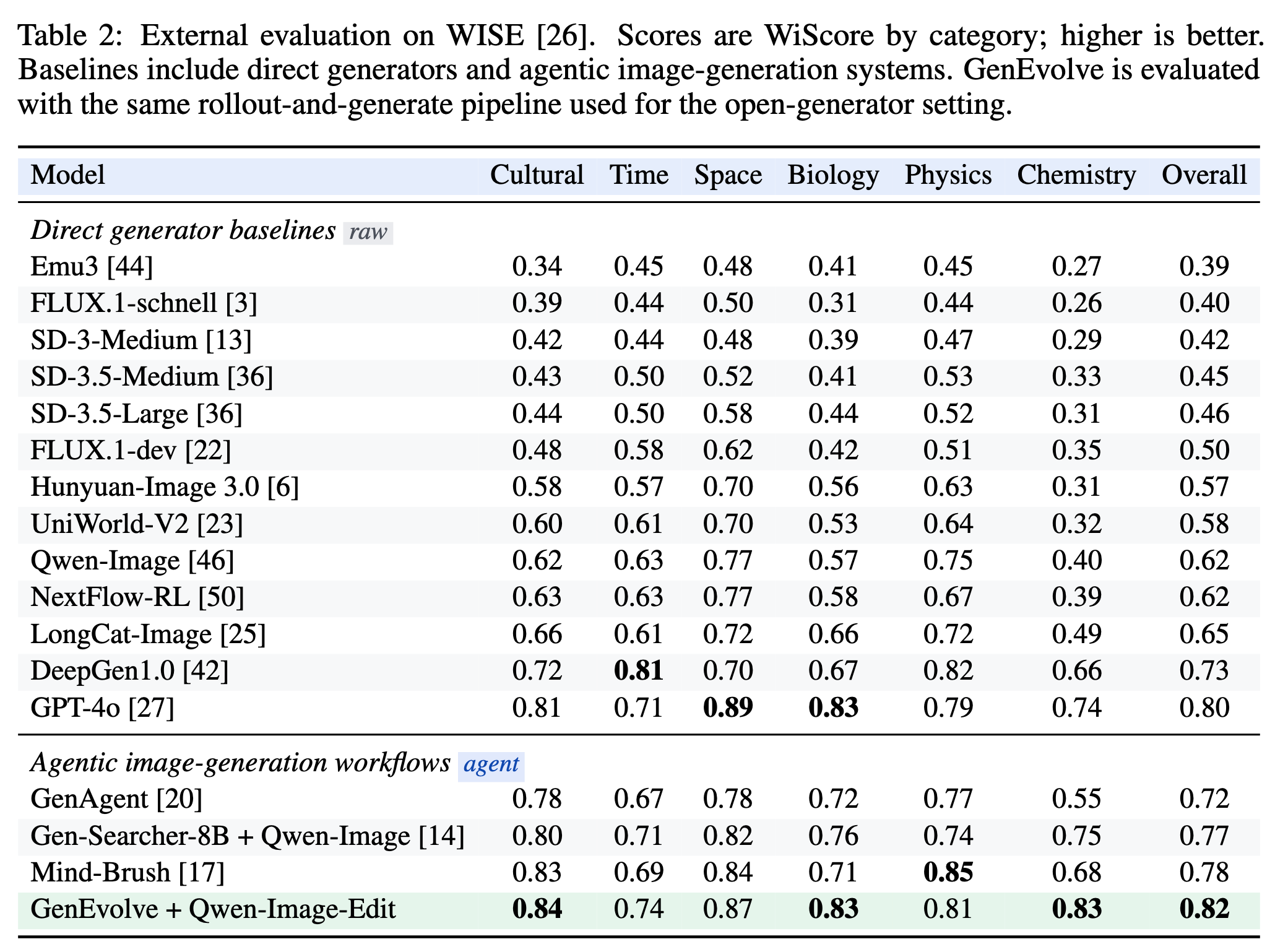
| 方法 | Overall WiScore |
|---|---|
| GPT-4o | 0.80 |
| Mind-Brush | 0.78 |
| Gen-Searcher-8B | 0.77 |
| GenEvolve + Qwen-Image-Edit | 0.82 |
GenEvolve 用开源生成器超过了 GPT-4o 的直接生成,在 Chemistry(0.83 vs 0.74)和 Biology(0.83 vs 0.83)上优势尤其明显------这些领域最需要外部知识补充,正是 agent 工具编排的强项。
4.4 消融实验(Table 3)
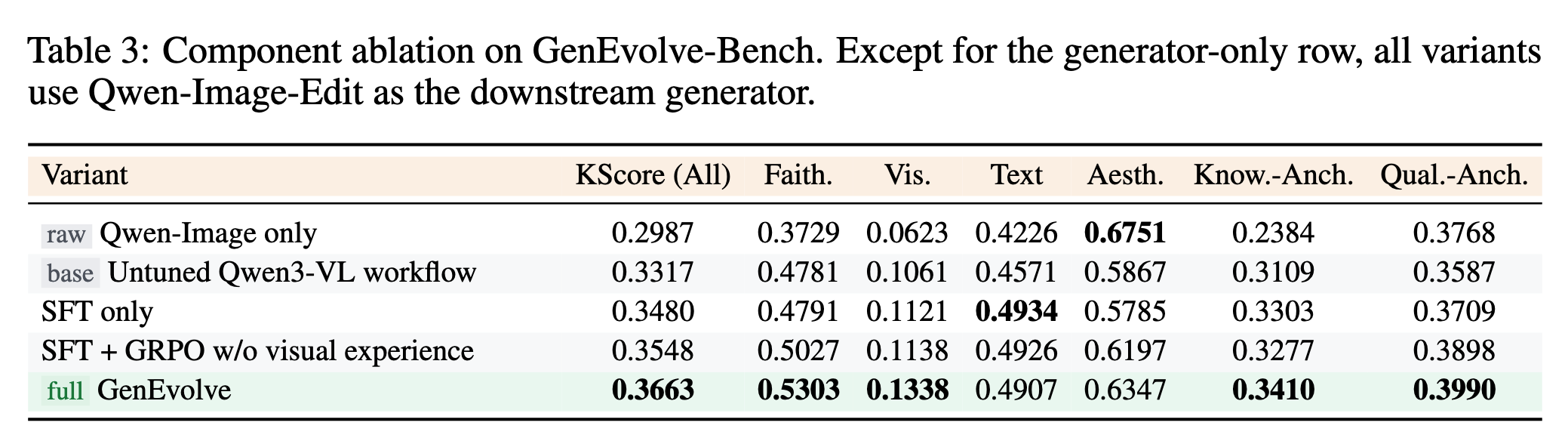
| 变体 | KScore |
|---|---|
| Qwen-Image 裸跑 | 0.2987 |
| 未训练的 Qwen3-VL 工作流 | 0.3317 |
| SFT only | 0.3480 |
| SFT + GRPO(无 SDL) | 0.3548 |
| Full GenEvolve | 0.3663 |
每个阶段都有增益:SFT 教会基础工具使用(+0.0163),GRPO 通过奖励信号优化轨迹(+0.0068),SDL 通过 token 级蒸馏进一步提升(+0.0115)。SDL 的增益甚至大于 GRPO 单独的增益,验证了 Visual Experience Distillation 提供了 GRPO 标量奖励之外的互补信号。
五、Conclusion
GenEvolve 将开放式图像生成建模为 agent 的多步决策轨迹学习问题,核心贡献包括:
- 轨迹建模:将工具使用、参考选择、知识激活、prompt 构造统一为可训练的轨迹决策。
- Visual Experience Distillation:从好坏轨迹对比中提取结构化视觉经验,作为特权信息蒸馏进 student,提供 GRPO 之外的 token 级指导。
- 数据与评测:构建了完整的数据流水线(GenEvolve-Data)和评测基准(GenEvolve-Bench)。
- 实验验证:在自建和公开 benchmark 上均超过强 baseline,且 agent 策略可跨生成器迁移。
六、个人思考
6.1 "弱生成器 + 强Agent" vs "强生成器直接用"
GenEvolve 最令人印象深刻的结果是:用开源的 Qwen-Image-Edit(裸跑 KScore 只有 0.2987)配上训练好的 agent,在 WISE 上超过了 GPT-4o 的直接生成(0.82 vs 0.80)。这说明 agent 的决策编排能力可以弥补生成器本身的不足,而且这种能力是可迁移的------同一个 agent 换上更强的生成器还能进一步提升。这个范式的意义可能比单纯提升生成器质量更大。
6.2 Visual Experience Distillation 的精妙设计
整篇论文最核心的创新在于 SDL 部分。GRPO 只提供"哪个好"的粗粒度信号,而 SDL 通过好坏轨迹对比提取出"为什么好"的细粒度经验,再通过蒸馏传递给 student。Appendix B.3 的三个 case study 展示了非常具体的失败模式:搜索 query 里加了"flag"导致检索结果偏差(Case 1)、漏调 text_rendering 导致文字堆叠(Case 2)、漏调 spatial_layout 导致建筑融合(Case 3)。这些都是 GRPO 的标量 reward 无法精确传递的信息。
6.3 GT 图像的合理性问题
GT 图像由 Nano Banana Pro 生成而非人工标注,这是一个潜在的局限。虽然论文做了多层过滤(生成后保留率 73.5%),但生成器的偏差仍可能传递到 reward 信号中。不过论文通过 text reward(评估方案本身,不看图像)来部分缓解了这个问题,使得 agent 即使在 GT 图像不完美的情况下,只要方案逻辑正确也能获得合理的奖励。
6.4 Skill 作为外挂知识的设计选择
GenEvolve 将内部生成知识实例化为 8 个可调用的 skill,本质上是预写好的生成指导文本。这种设计的好处是可解释、可扩展(加新 skill 不需要重训模型),但也意味着知识的质量依赖于 skill 文本的编写质量。未来可以探索让 agent 自己从经验中总结和更新 skill,而不是依赖人工预设。