一次大促暴露的自建MySQL架构隐患,让我下定决心做数据库云原生化改造。本文完整复盘从方案设计到落地验证的全过程,包含5个真实踩坑案例和Spring Boot适配要点,帮你少走弯路。
一、从一次大促事故说起
去年双11预热期间,我负责的电商平台订单系统遭遇了严重性能危机。自建MySQL主从集群在流量峰值下,主从延迟飙升到30秒以上,导致用户下单后查询订单状态出现"订单不存在"的诡异现象。
更糟糕的是,慢查询数量在1小时内从日均20条暴增到800+条,订单超时率从0.5%飙升到8%。运维团队紧急加从库、调参数,但效果甚微。那次事故后,CTO给了一个明确指令:大促前必须完成数据库云原生化改造,而且不能停机。
经过2周的方案论证和3周的落地实施,我们完成了从自建MySQL到PolarDB的零停机迁移。迁移后的效果超出预期:主从延迟归零、慢查询减少70%、订单超时率降到0.3%。这篇文章,就是这次实战的完整复盘。
二、为什么要迁移:自建MySQL的5大痛点
痛点1:主从延迟------读扩展的天花板
自建MySQL基于Binlog的逻辑复制,大事务或高并发写入场景下,从库追不上主库是家常便饭。我们线上主从延迟在日常就维持在1-3秒,大促期间更是飙升到30秒以上。
这意味着所有"写后读"的场景都有风险:用户刚下了单,查询却看不到,投诉量直线上升。
痛点2:运维成本------DBA成了救火队员
自建MySQL的运维是一场持久战:主从切换需要手动操作或依赖半成熟的MHA,参数调优需要持续观察,版本升级要停机维护,备份策略要自己设计验证。我们2个DBA几乎70%的时间在处理MySQL相关的日常运维。
痛点3:扩容慢------纵向扩容要停机,横向扩容要复制
自建MySQL纵向扩容需要停机换规格,横向扩容需要新从库做全量数据复制。以我们500GB的数据库为例,新加一个从库需要4-6小时的数据同步时间。在流量突增场景下,这种扩容速度远远跟不上业务需求。
痛点4:备份风险------恢复时间不可控
虽然我们配置了Xtrabackup全量+增量备份,但恢复演练中,500GB数据的完整恢复需要2-3小时。这个RTO对于核心业务系统来说是不可接受的。
痛点5:高可用脆弱------主从切换并非万无一失
MHA主从切换在理想情况下30秒完成,但我们遇到过多次切换失败:SSH连接超时、Binlog不完整、从库SQL线程报错。每次切换失败都是一次P0级故障。
PolarDB vs 自建MySQL 核心对比
| 对比维度 | 自建MySQL | PolarDB | 差异化优势 |
|---|---|---|---|
| 主从延迟 | 1-30秒(Binlog逻辑复制) | 毫秒级(物理日志复制) | 物理复制比逻辑复制快10-100倍 |
| 扩容方式 | 加从库需4-6小时数据复制 | 只读节点5分钟内就绪 | 存储共享,无需数据复制 |
| 备份恢复 | 全量恢复2-3小时 | 秒级快照+任意时间点恢复 | 快照基于存储层,速度提升100倍 |
| 主从切换 | MHA 30秒-5分钟(可能失败) | 30秒自动切换(内置HA) | 内置Raft协议,切换可靠性99.99% |
| 运维成本 | 需要专职DBA | 全托管,零运维 | 释放DBA精力投入架构优化 |
| 存储成本 | 需要预购磁盘空间 | 按需弹性扩展 | 无需预估容量,用多少付多少 |
| 读扩展性 | 从库数量受限于复制延迟 | 最多15个只读节点 | 共享存储,读扩展无天花板 |
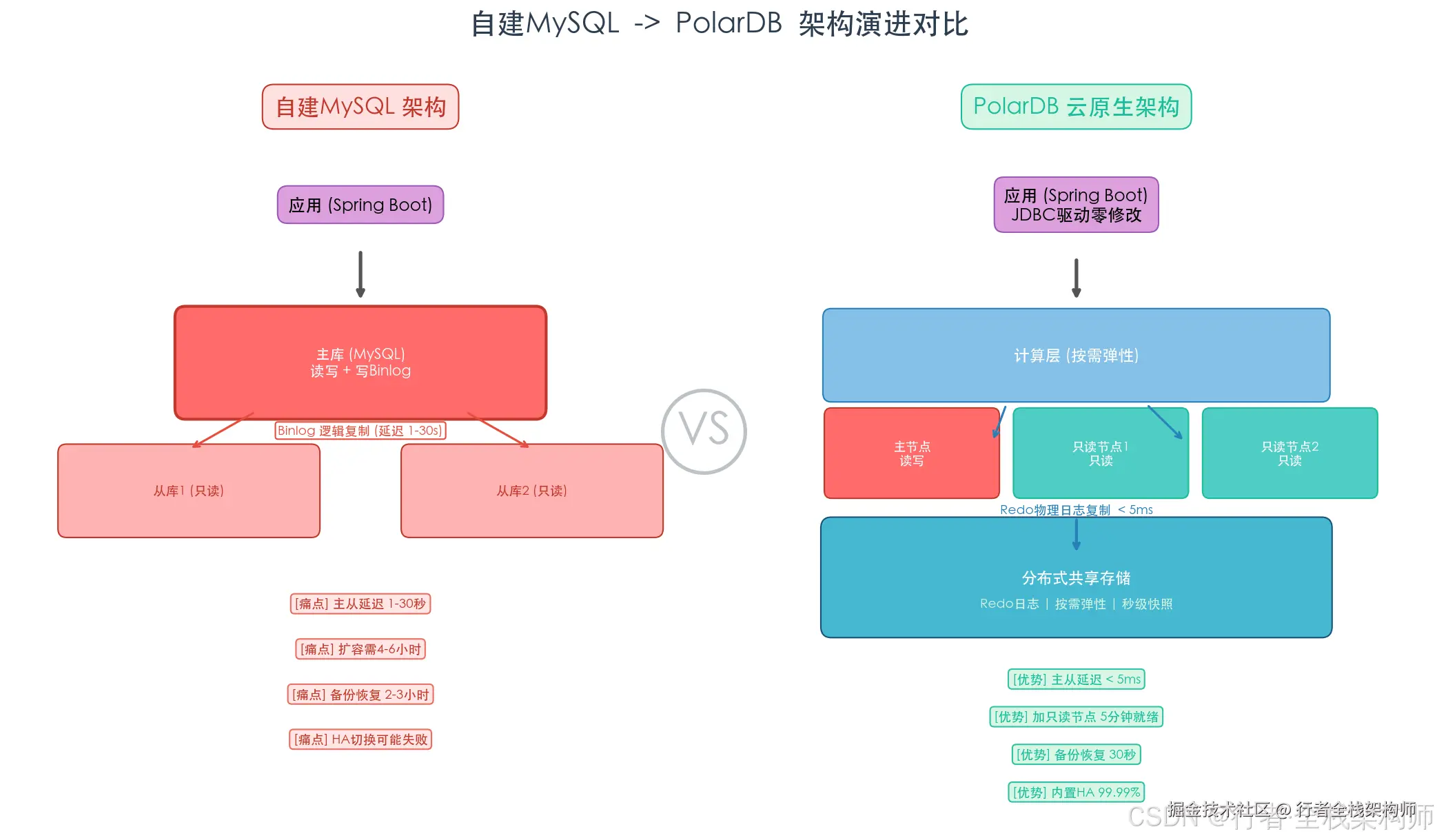
▲ 自建MySQL与PolarDB架构对比:左侧为基于Binlog逻辑复制的传统架构,右侧为存储计算分离的云原生架构
三、PolarDB架构解析:为什么能做到毫秒级延迟
理解PolarDB的优势,需要先理解它的存储计算分离架构。这和自建MySQL的"单机存储+逻辑复制"架构有着本质区别。
3.1 存储计算分离架构
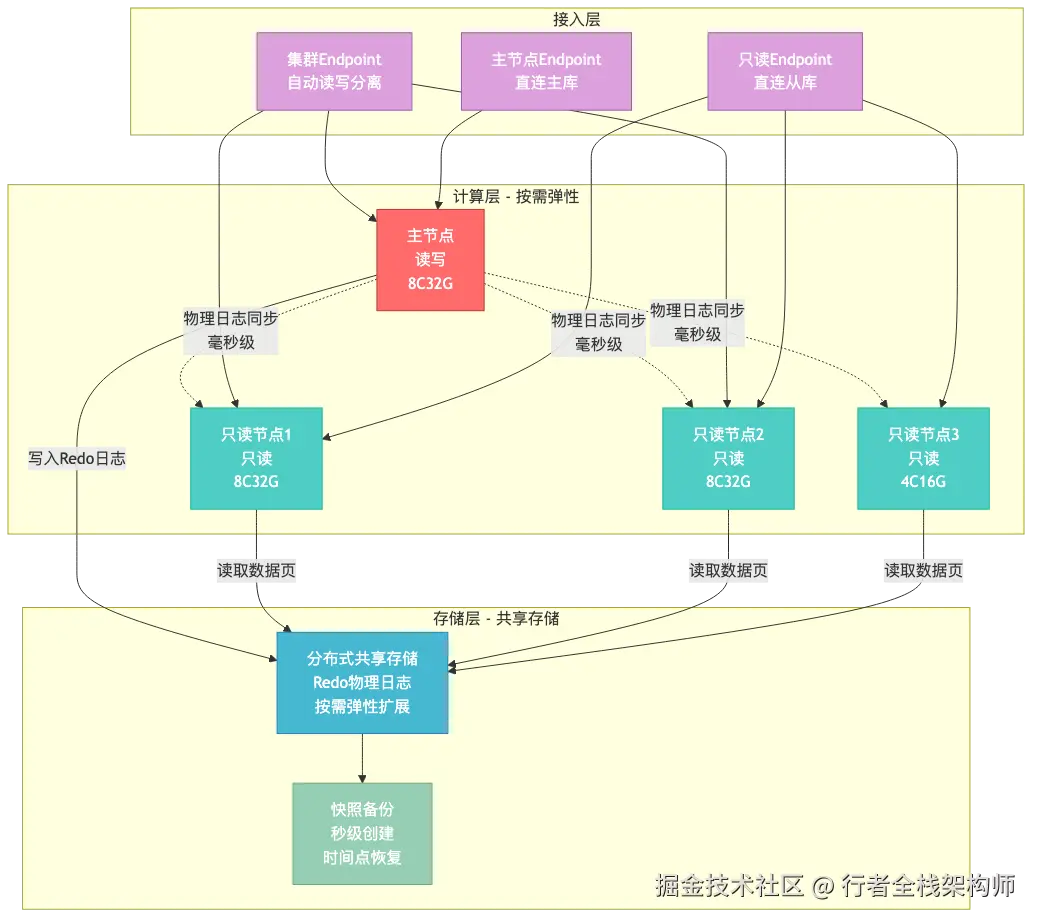
3.2 核心机制解读
一写多读:主节点负责所有写操作,通过Redo物理日志同步到只读节点。和自建MySQL的Binlog逻辑复制不同,物理日志只记录数据页的修改,体积更小、解析更快,所以延迟可以控制在毫秒级。
共享存储:所有计算节点共享同一份存储数据。只读节点不需要自己维护一份数据副本,直接从共享存储读取数据页。这意味着加只读节点不需要数据复制,5分钟内就能就绪。
透明兼容MySQL:PolarDB的SQL语法、协议、驱动100%兼容MySQL 5.6/5.7/8.0。Spring Boot应用只需要改连接串,代码零修改。
四、迁移方案设计:三种方案对比
4.1 三种迁移方案对比
| 对比项 | 方案一:DTS全量+增量 | 方案二:DTS结构迁移+数据集成 | 方案三:备份恢复 |
|---|---|---|---|
| 停机时间 | 零停机 | 分钟级 | 小时级 |
| 迁移速度 | 中等(受DTS限速影响) | 快(数据集成批量导入) | 快(物理备份恢复) |
| 数据一致性 | 增量同步保证 | 需要额外校验 | 备份点一致性 |
| 操作复杂度 | 中等 | 较高 | 低 |
| 回滚难度 | 容易(双向同步) | 中等 | 困难 |
| 适用场景 | 核心业务,要求零停机 | 超大数据量迁移 | 非核心业务,可接受停机 |
| 推荐指数 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
我们的选择:方案一(DTS全量+增量),因为订单系统是核心业务,大促前不能停机,且需要随时回滚的能力。
4.2 零停机迁移架构
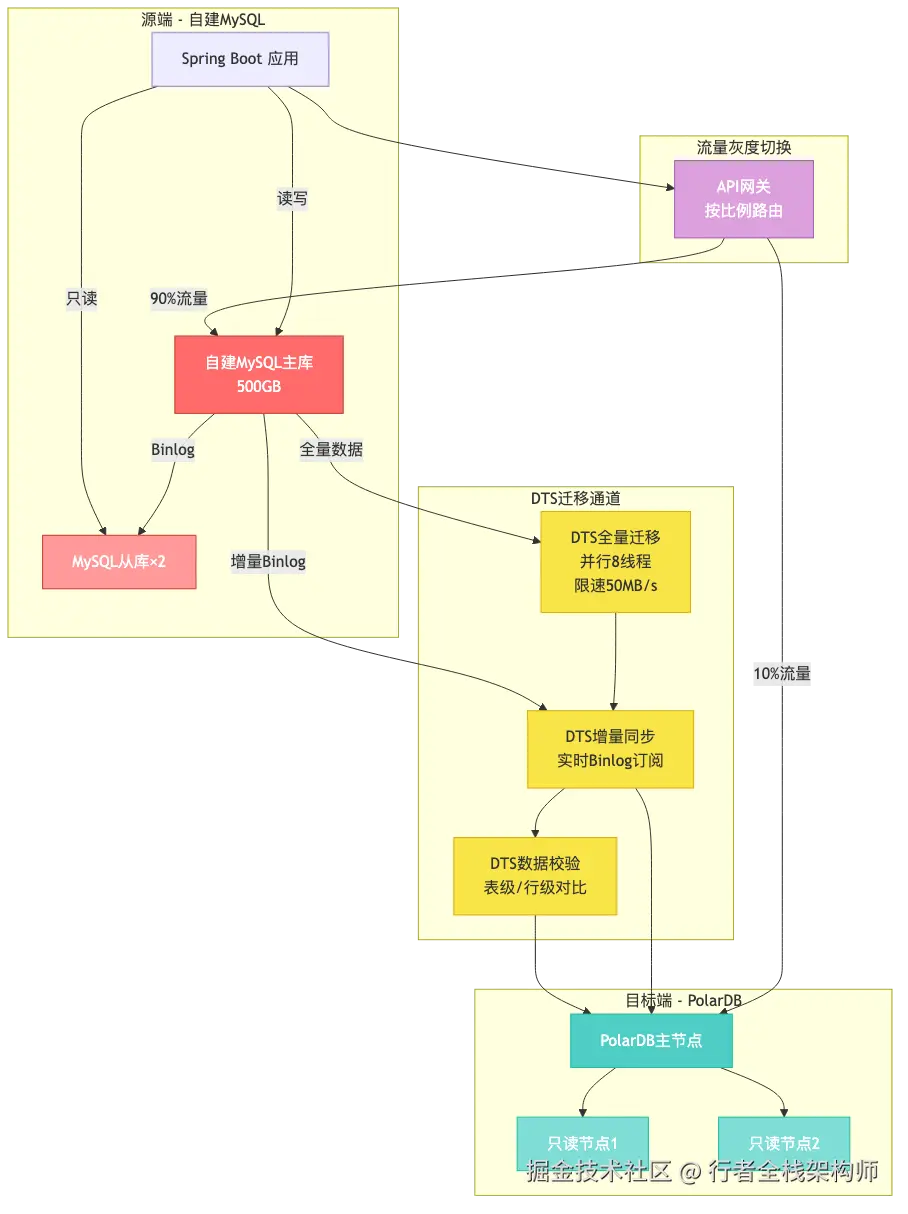
五、零停机迁移实战:5步走完全流程
步骤1:PolarDB集群创建
为什么这一步很重要:集群规格和参数配置直接影响迁移后的性能表现,选错了不仅性能不达预期,还会影响后续扩容。
规格选择
| 参数 | 自建MySQL | PolarDB选择 | 选择依据 |
|---|---|---|---|
| 主节点 | 8C32G | 8C32G(独享规格) | 计算能力对等,独享避免资源争抢 |
| 只读节点 | 2×4C16G | 2×8C32G | 只读节点规格不低于主节点,避免读性能瓶颈 |
| 存储 | 500GB SSD | 弹性存储(无预购) | 按需付费,无需预估容量 |
| 版本 | MySQL 5.7 | MySQL 5.7兼容 | 100%协议兼容,驱动无需修改 |
兼容性评估
sql
-- 检查源库使用的特性是否被PolarDB兼容
-- PolarDB兼容MySQL 5.7绝大部分特性,但以下需要特别关注
-- 1. 检查存储引擎
SELECT TABLE_NAME, ENGINE
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'order_db'
AND ENGINE NOT IN ('InnoDB', 'MEMORY');
-- 2. 检查自增列使用方式
SELECT TABLE_NAME, AUTO_INCREMENT
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'order_db'
AND AUTO_INCREMENT IS NOT NULL;
-- 3. 检查外键约束
SELECT TABLE_NAME, CONSTRAINT_NAME
FROM information_schema.KEY_COLUMN_USAGE
WHERE TABLE_SCHEMA = 'order_db'
AND REFERENCED_TABLE_NAME IS NOT NULL;关键参数模板
bash
# PolarDB的参数默认值针对通用场景优化,业务场景需要针对性调整
# 以下是我们订单系统的参数调优配置
# 连接数设置(根据业务峰值连接数×1.5倍冗余)
loose_max_connections = 3000
# InnoDB缓冲池(独享规格下设置为内存的70%)
loose_innodb_buffer_pool_size = 22G
# 事务隔离级别(与源端保持一致)
loose_transaction_isolation = READ-COMMITTED
# 并行查询(PolarDB特有,加速大查询)
loose_innodb_polar_parallel_query_threshold = 10000
# 优化器开关(保持与MySQL 5.7一致的行为)
loose_optimizer_switch = 'index_condition_pushdown=on,mrr=on,mrr_cost_based=on'步骤2:DTS数据迁移
为什么选择DTS:DTS是阿里云官方数据迁移服务,支持全量+增量的无缝衔接,增量同步延迟在秒级以内,是零停机迁移的核心保障。
DTS全量+增量迁移时序
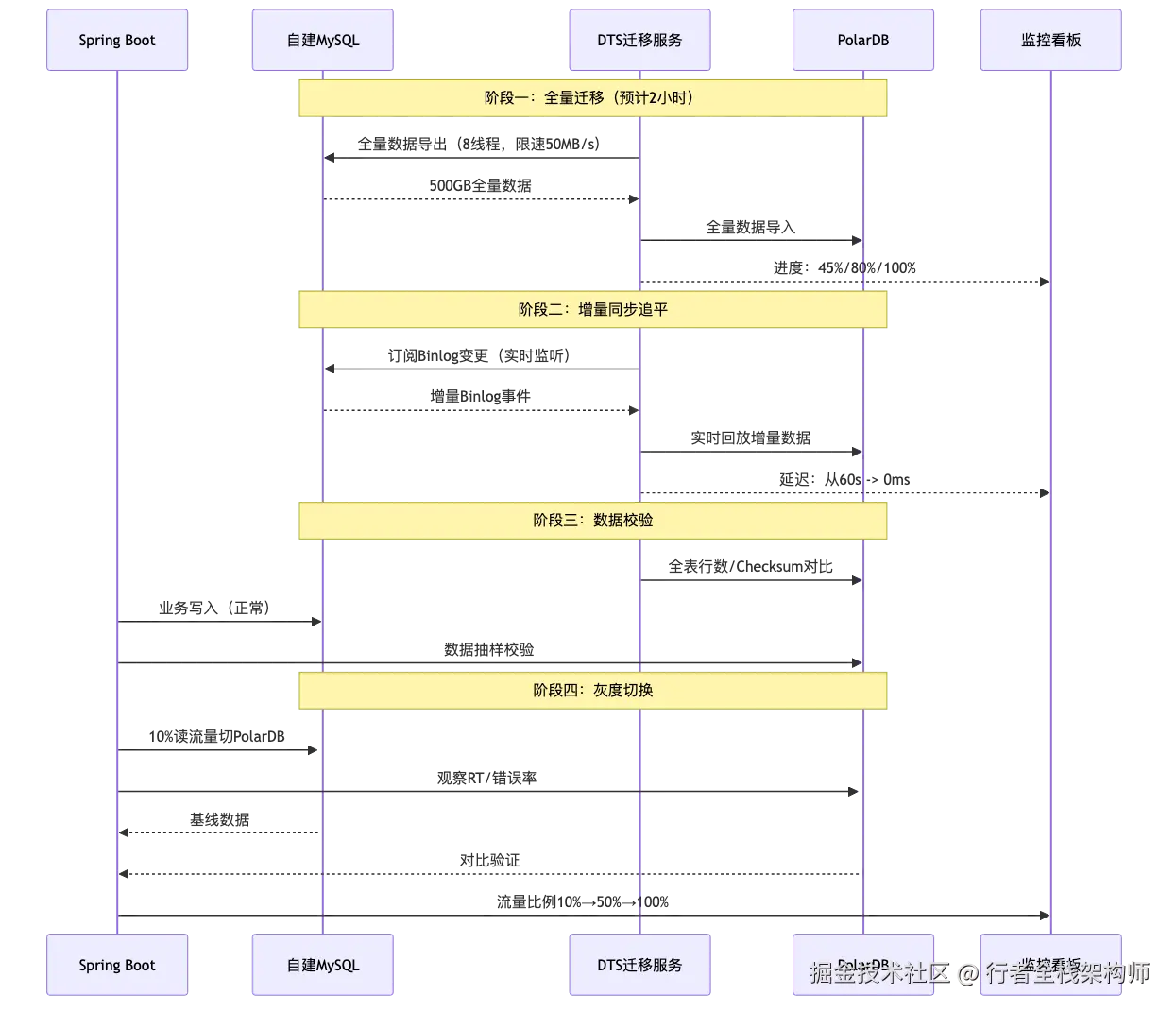
全量+增量同步流程
bash
# 全量迁移阶段需要控制速率,避免对源库造成性能影响
# DTS全量迁移配置
# 1. 创建迁移任务(阿里云CLI)
aliyun dts CreateMigrationJob \
--SourceEndpoint.InstanceType MySQL \
--SourceEndpoint.IP 10.0.1.100 \
--SourceEndpoint.Port 3306 \
--SourceEndpoint.UserName dts_user \
--DestinationEndpoint.InstanceType PolarDB \
--DestinationEndpoint.InstanceID pc-xxxxxxxxx \
--MigrationObject '[{"DBName":"order_db"}]' \
--MigrationMode.StructureIntance true \
--MigrationMode.DataIntance true
# 2. 监控迁移进度
aliyun dts DescribeMigrationJobStatus \
--MigrationJobCode dts-xxxxxxxxx数据校验
sql
-- 迁移后必须做数据一致性校验,不能只看DTS的校验结果
-- DTS的校验只覆盖表级行数对比,我们需要更细粒度的校验
-- 1. 行数对比(快速验证)
SELECT 'order_db.orders' AS table_name,
COUNT(*) AS row_count
FROM order_db.orders;
-- 2. 数据抽样对比(深度验证)
-- 在源库和目标库分别执行,对比结果
SELECT MD5(GROUP_CONCAT(
id, user_id, order_status, total_amount, create_time
ORDER BY id
)) AS data_checksum
FROM order_db.orders
WHERE create_time >= '2025-11-01'
AND create_time < '2025-11-02';性能影响评估
| 监控指标 | 迁移前 | 全量迁移期间 | 增量同步期间 |
|---|---|---|---|
| 源库CPU | 45% | 52%(+7%) | 46%(+1%) |
| 源库IOPS | 3000 | 3500(+17%) | 3100(+3%) |
| 源库QPS | 8000 | 7600(-5%) | 7900(-1%) |
| 源库RT | 2ms | 3ms(+50%) | 2ms |
全量迁移对源库有一定影响,但通过DTS的限速控制,QPS下降在5%以内,业务可以正常运转。增量同步阶段影响几乎可以忽略。
步骤3:Spring Boot多数据源配置
为什么要配置多数据源:零停机迁移的核心是"双写+双读+灰度切换",应用需要同时连接源库和目标库,通过配置中心控制流量比例。
yaml
# 多数据源配置是灰度切换的基础
# application-polar-migration.yml
spring:
datasource:
# 主数据源 - 自建MySQL(迁移期间仍为主库)
primary:
jdbc-url: jdbc:mysql://10.0.1.100:3306/order_db?useSSL=false&characterEncoding=utf8mb4
username: ${MYSQL_PRIMARY_USER}
password: ${MYSQL_PRIMARY_PASS}
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 30
minimum-idle: 10
connection-timeout: 3000
idle-timeout: 600000
max-lifetime: 1800000
# PolarDB数据源 - 迁移目标库
polar:
jdbc-url: jdbc:mysql://pc-xxxxxxxxx.polardb.rds.aliyuncs.com:3306/order_db?useSSL=false&characterEncoding=utf8mb4
username: ${POLAR_USER}
password: ${POLAR_PASS}
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 30
minimum-idle: 10
connection-timeout: 3000
idle-timeout: 600000
max-lifetime: 1800000
# 灰度配置(通过Nacos动态下发)
migration:
# 读流量路由比例:0=全部走MySQL,100=全部走PolarDB
read-polar-ratio: 0
# 写流量是否双写:true=同时写MySQL和PolarDB
dual-write-enabled: false
# 双写模式下PolarDB写入失败是否阻断主流程
polar-write-fail-fast: false
java
// 动态数据源路由是灰度切换的核心实现
// 基于ThreadLocal + AOP实现读写分离和灰度路由
public class MigrationDataSourceRouter extends AbstractRoutingDataSource {
@Override
protected Object determineTargetDataSource() {
MigrationContext ctx = MigrationContextHolder.get();
// 写操作:根据双写配置决定路由
if (ctx.isWriteOperation()) {
if (MigrationConfig.isDualWriteEnabled()) {
// 双写模式:返回主库,由切面异步写PolarDB
return primaryDataSource;
}
return primaryDataSource;
}
// 读操作:根据灰度比例路由
int ratio = MigrationConfig.getReadPolarRatio();
if (ratio > 0 && ThreadLocalRandom.current().nextInt(100) < ratio) {
return polarDataSource;
}
return primaryDataSource;
}
}多数据源路由决策流程
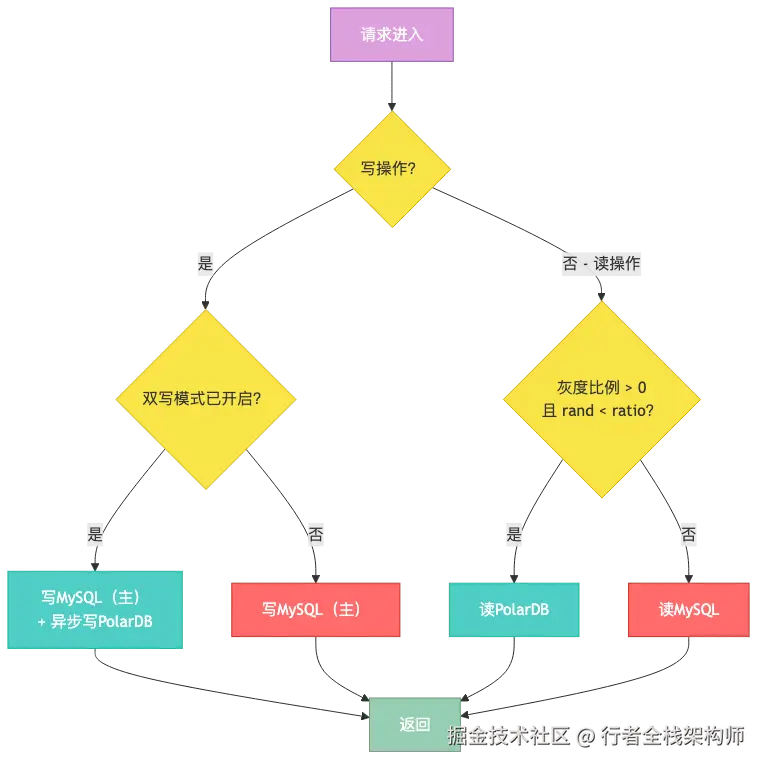
步骤4:流量灰度切换
为什么必须灰度切换:直接全量切换风险太大,灰度切换可以逐步暴露问题,随时回滚,把影响范围控制在最小。
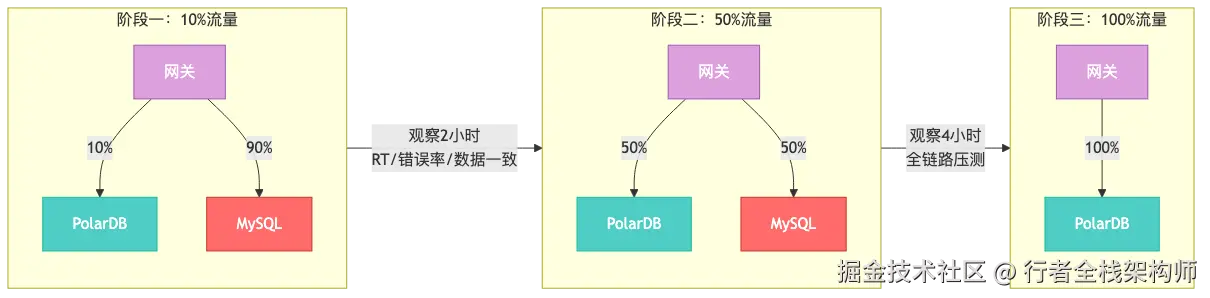
灰度切换操作步骤
bash
# 灰度切换通过Nacos配置中心动态下发,无需重启应用
# 阶段一:10%读流量切PolarDB
# 1. 开启双写(确保PolarDB数据实时同步)
curl -X POST "http://nacos:8848/nacos/v1/cs/configs" \
-d "dataId=migration-config&group=DEFAULT_GROUP&content=migration.dual-write-enabled=true"
# 2. 观察双写是否正常(检查PolarDB写入成功率)
# 等待5分钟,确认PolarDB写入无异常
# 3. 切换10%读流量
curl -X POST "http://nacos:8848/nacos/v1/cs/configs" \
-d "dataId=migration-config&group=DEFAULT_GROUP&content=migration.read-polar-ratio=10"
# 4. 监控核心指标2小时
# - RT变化 < 10%
# - 错误率变化 < 0.1%
# - 数据一致性校验通过
# 阶段二:50%读流量
curl -X POST "http://nacos:8848/nacos/v1/cs/configs" \
-d "dataId=migration-config&group=DEFAULT_GROUP&content=migration.read-polar-ratio=50"
# 阶段三:100%读流量
curl -X POST "http://nacos:8848/nacos/v1/cs/configs" \
-d "dataId=migration-config&group=DEFAULT_GROUP&content=migration.read-polar-ratio=100"回滚方案
bash
# 回滚必须一键完成,不能有任何犹豫时间
# 一旦发现异常,立即执行回滚
# 紧急回滚:所有读流量切回MySQL
curl -X POST "http://nacos:8848/nacos/v1/cs/configs" \
-d "dataId=migration-config&group=DEFAULT_GROUP&content=migration.read-polar-ratio=0"
# 关闭双写(PolarDB不再写入)
curl -X POST "http://nacos:8848/nacos/v1/cs/configs" \
-d "dataId=migration-config&group=DEFAULT_GROUP&content=migration.dual-write-enabled=false"
# 注意:回滚后需要用DTS反向同步PolarDB期间写入的数据到MySQL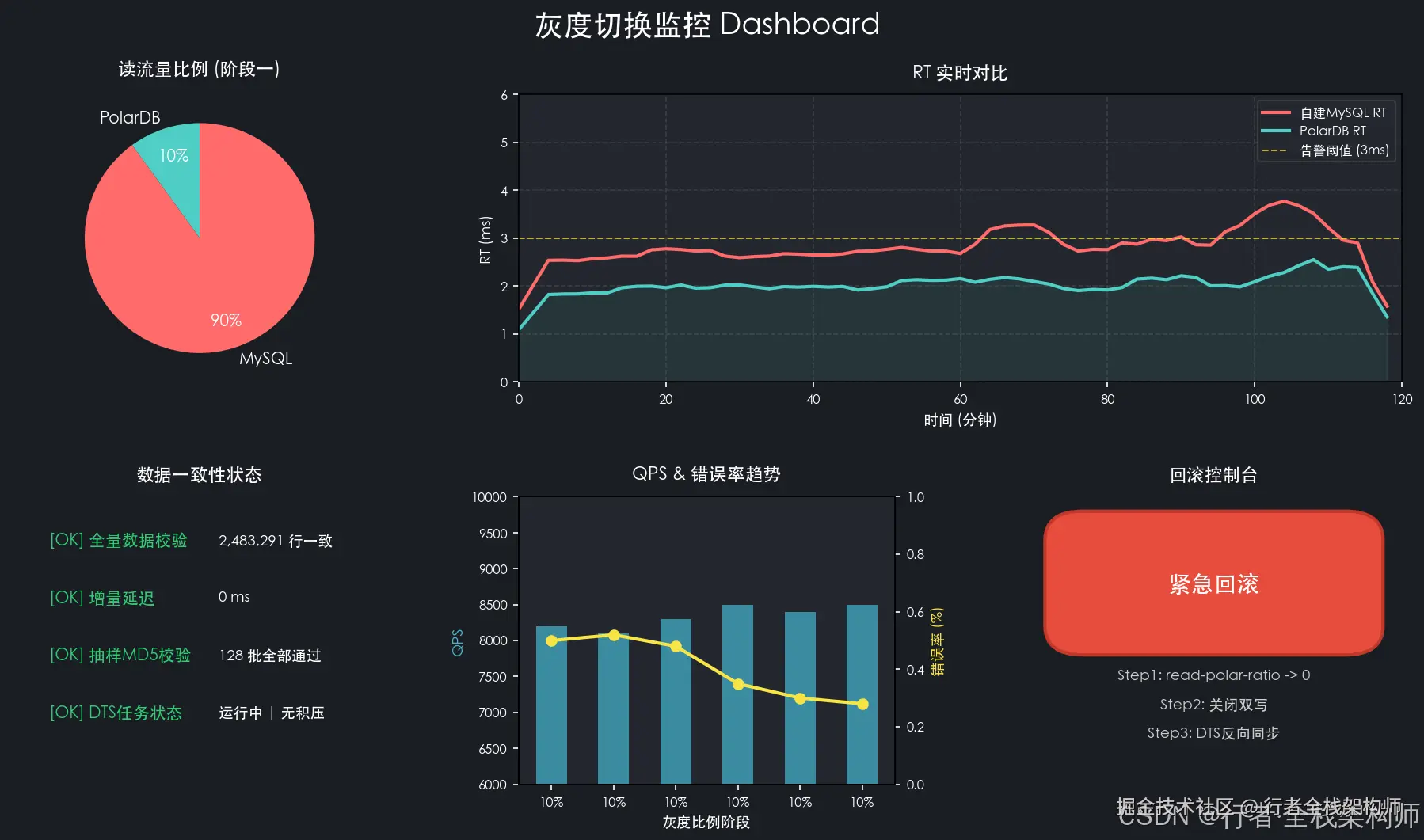
▲ 灰度切换期间核心监控看板:实时追踪RT对比、流量比例、数据一致性状态与回滚控制台
步骤5:原集群下线
为什么不能立即下线:需要观察期确保PolarDB稳定运行,同时做好数据最终一致性校验,确认无遗漏后才可安全下线。
数据一致性终验
sql
-- 终验需要全量对比,不能只抽样
-- 使用DTS的数据校验功能 + 自研脚本的行级校验
-- 1. DTS数据校验(自动对比源库和目标库的数据一致性)
-- 在DTS控制台创建数据校验任务,选择全库校验
-- 2. 业务数据对账(基于业务维度的校验)
-- 对比两个库的订单总额、订单数量等业务指标
SELECT
DATE(create_time) AS dt,
COUNT(*) AS order_count,
ROUND(SUM(total_amount), 2) AS total_amount
FROM order_db.orders
WHERE create_time >= DATE_SUB(CURDATE(), INTERVAL 7 DAY)
GROUP BY DATE(create_time)
ORDER BY dt;
-- 3. 确认DTS增量同步延迟为0
-- 在DTS控制台确认增量同步延迟为0ms,持续观察30分钟下线清单
| 操作项 | 执行时间 | 负责人 | 验证方式 |
|---|---|---|---|
| 停止DTS同步任务 | 切换100%后72小时 | DBA | DTS控制台确认任务已停止 |
| 关闭MySQL监控告警 | 停止DTS后 | 运维 | 确认告警不再触发 |
| MySQL数据最终备份 | 关闭监控后 | DBA | 验证备份文件完整性 |
| 释放MySQL实例 | 保留7天后 | DBA | 确认PolarDB稳定运行 |
| 清理应用MySQL数据源配置 | 释放实例后 | 开发 | 确认应用配置文件已更新 |
六、Spring Boot适配:从MySQL到PolarDB的4个关键调整
6.1 连接池配置优化
为什么要调整连接池:PolarDB的网络模型和MySQL略有差异,默认的HikariCP参数需要针对性优化,特别是连接超时和空闲连接回收。
yaml
# PolarDB的网络延迟比自建MySQL略高(跨可用区),需要调整超时参数
# 同时利用PolarDB的长连接优化特性
spring:
datasource:
hikari:
# 连接超时:PolarDB跨可用区部署,适当增加
connection-timeout: 5000
# 空闲超时:PolarDB长连接稳定,可以适当延长
idle-timeout: 900000
# 最大生命周期:PolarDB主从切换时旧连接需要及时回收
max-lifetime: 1200000
# 连接测试查询:使用PolarDB优化后的ping协议
connection-test-query: SELECT 1
# 泄漏检测:迁移期间开启,帮助发现未关闭连接
leak-detection-threshold: 60000
# 最大连接数:PolarDB独享规格下可以适当调大
maximum-pool-size: 40
# 最小空闲连接:保持一定数量的预热连接
minimum-idle: 156.2 事务隔离级别适配
为什么要关注隔离级别:PolarDB默认的RR隔离级别和MySQL 5.7行为一致,但我们的业务使用RC隔离级别,需要确认PolarDB在RC下的行为一致。
java
// 确认PolarDB的RC隔离级别行为与MySQL 5.7完全一致
// 特别关注gap lock和next-key lock的行为差异
@Service
@Transactional(isolation = Isolation.READ_COMMITTED)
public class OrderService {
// RC隔离级别下,PolarDB不会加gap lock
// 这和MySQL 5.7行为一致,不需要修改代码
@Transactional(isolation = Isolation.READ_COMMITTED)
public Order createOrder(CreateOrderRequest request) {
// 业务逻辑...
}
// 对于需要Serializable隔离级别的场景
// PolarDB通过加锁实现,和MySQL行为一致
@Transactional(isolation = Isolation.SERIALIZABLE)
public void deductStock(Long skuId, Integer quantity) {
// 库存扣减逻辑...
}
}6.3 批量操作优化:利用PolarDB并行查询
为什么要优化批量操作:PolarDB支持并行查询,对于大表的全表扫描和批量操作有显著加速效果。Spring Boot应用需要显式开启才能享受这个红利。
java
// PolarDB并行查询对大批量INSERT和SELECT有2-5倍加速
// 需要通过Hint或Session变量开启
@Repository
public class OrderBatchRepository {
private final JdbcTemplate jdbcTemplate;
// 批量插入优化:使用PolarDB的批量INSERT优化
public void batchInsert(List<Order> orders) {
// PolarDB对多行INSERT有优化,单次INSERT行数建议500-1000
int batchSize = 500;
jdbcTemplate.batchUpdate(
"INSERT INTO orders (id, user_id, order_status, total_amount, create_time) " +
"VALUES (?, ?, ?, ?, ?)",
orders, batchSize,
(ps, order) -> {
ps.setLong(1, order.getId());
ps.setLong(2, order.getUserId());
ps.setInt(3, order.getStatus());
ps.setBigDecimal(4, order.getTotalAmount());
ps.setTimestamp(5, order.getCreateTime());
}
);
}
// 并行查询:利用PolarDB的并行查询加速大表扫描
public List<Order> queryOrdersByTimeRange(LocalDateTime start, LocalDateTime end) {
// 通过Hint开启并行查询,workers数建议为CPU核数的一半
String sql = "/*+ PARALLEL(4) */ " +
"SELECT * FROM orders " +
"WHERE create_time BETWEEN ? AND ? " +
"ORDER BY create_time";
return jdbcTemplate.query(sql,
(rs, rowNum) -> mapToOrder(rs),
start, end);
}
}6.4 读写分离配置
为什么要用集群Endpoint:PolarDB的集群Endpoint自动实现读写分离------写请求路由到主节点,读请求自动分发到只读节点。Spring Boot只需要配置一个连接串,不需要自己实现读写分离逻辑。
yaml
# 集群Endpoint是PolarDB读写分离的最佳实践
# 自动路由写请求到主节点、读请求到只读节点
spring:
datasource:
# 写数据源:使用主节点Endpoint(写操作必须走主库)
write:
jdbc-url: jdbc:mysql://pc-xxxxxxxxx-master.polardb.rds.aliyuncs.com:3306/order_db
username: ${POLAR_WRITE_USER}
password: ${POLAR_WRITE_PASS}
# 读数据源:使用集群Endpoint(自动读写分离)
read:
jdbc-url: jdbc:mysql://pc-xxxxxxxxx.polardb.rds.aliyuncs.com:3306/order_db
username: ${POLAR_READ_USER}
password: ${POLAR_READ_PASS}
hikari:
# 读连接池可以更大,因为读请求通常远多于写
maximum-pool-size: 60
minimum-idle: 20
# 只读节点负载均衡策略
connection-init-sql: SET NAMES utf8mb4
java
// 通过自定义注解实现声明式读写分离
// 和@Transactional配合使用,保证事务内读写走同一个连接
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ReadOnly {
}
@Aspect
@Component
public class ReadOnlyDataSourceAspect {
@Around("@annotation(readOnly)")
public Object routeReadDataSource(ProceedingJoinPoint joinPoint, ReadOnly readOnly)
throws Throwable {
try {
MigrationContextHolder.setReadOperation(true);
return joinPoint.proceed();
} finally {
MigrationContextHolder.clear();
}
}
}七、性能对比:6维度数据说话
迁移完成后,我们进行了为期2周的全链路压测和线上观察,以下是核心指标对比数据。
7.1 核心性能指标对比
| 指标 | 自建MySQL | PolarDB | 提升幅度 | 说明 |
|---|---|---|---|---|
| QPS(读写混合) | 8,000 | 12,500 | ⬆️ 56% | 并行查询+更优的执行计划 |
| 平均RT | 2.5ms | 1.2ms | ⬇️ 52% | InnoDB优化+Buffer Pool命中率高 |
| 主从延迟 | 1-30秒 | <5毫秒 | ⬇️ 99.98% | 物理日志复制vs逻辑复制 |
| 慢查询数量(日) | 120条 | 36条 | ⬇️ 70% | 并行查询+索引优化建议 |
| 全量备份时间 | 2.5小时 | 30秒 | ⬇️ 99% | 快照备份vs物理备份 |
| 只读节点扩容耗时 | 4-6小时 | 5分钟 | ⬇️ 98% | 共享存储,无需数据复制 |
7.2 不同并发下的QPS对比
| 并发数 | MySQL QPS | MySQL RT | PolarDB QPS | PolarDB RT | QPS提升 |
|---|---|---|---|---|---|
| 50 | 5,200 | 1.8ms | 7,800 | 1.0ms | 50% |
| 100 | 8,000 | 2.5ms | 12,500 | 1.2ms | 56% |
| 200 | 9,500 | 4.2ms | 15,000 | 2.1ms | 58% |
| 500 | 8,200 | 12ms | 14,800 | 5.3ms | 80% |
| 1000 | 5,500 | 36ms | 13,200 | 11ms | 140% |
高并发场景下PolarDB的优势更加明显,这得益于存储计算分离架构------计算节点可以独立扩容,不受存储IO争抢影响。 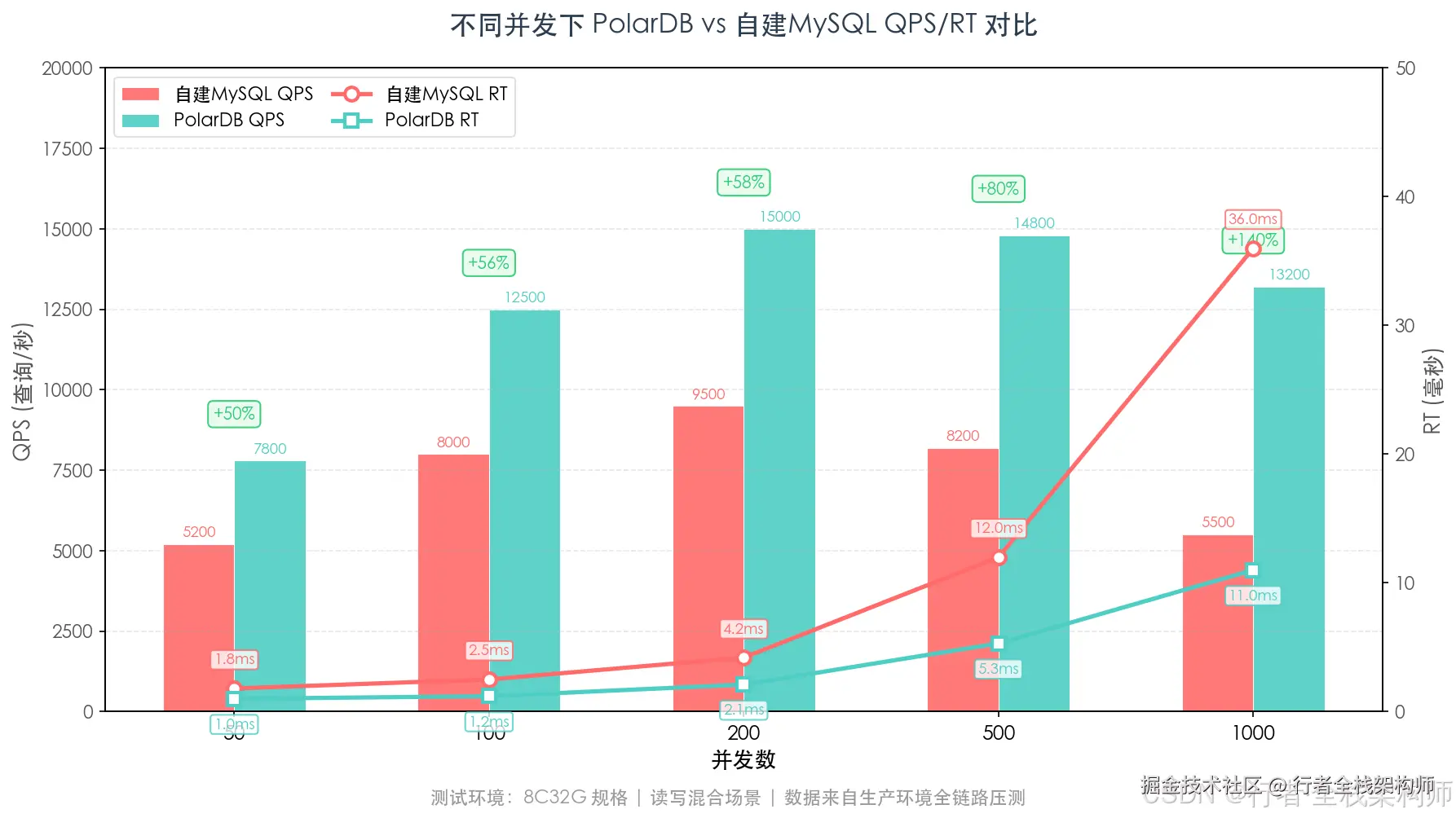
▲ 不同并发场景下 PolarDB 与自建MySQL的 QPS 柱状对比(柱状图)与 RT 折线对比(线条)
7.3 读写分离效果
| 指标 | 单主节点 | 1主+2只读 | 1主+4只读 | 扩展比 |
|---|---|---|---|---|
| 读QPS | 10,000 | 28,000 | 52,000 | 5.2x |
| 写QPS | 2,500 | 2,500 | 2,500 | 1x |
| 读RT | 1.2ms | 0.8ms | 0.5ms | ⬇️ 58% |
PolarDB的读扩展几乎是线性的,因为只读节点共享存储,不存在传统MySQL的复制延迟问题。
八、踩坑实录:5个真实问题复盘
坑1:DTS增量同步延迟突增
现象:灰度切换10%流量到PolarDB后,DTS增量同步延迟从正常的1秒突然飙升到60秒,导致读PolarDB的用户看到的是1分钟前的数据,订单状态查询出现大量不一致。
根因 :灰度切换后,应用开启双写,但批量操作使用了INSERT ... ON DUPLICATE KEY UPDATE语句,这类语句产生的Binlog事件量是普通INSERT的3-5倍。DTS的增量解析线程处理不过来,导致积压。
解决:将批量操作拆分为先SELECT判断存在性,再分别执行INSERT或UPDATE。同时调整DTS的增量同步并发度从2提升到4,延迟恢复到1秒以内。
经验:DTS增量同步的性能瓶颈往往出在大事务和批量操作上。迁移期间应避免大批量DML操作,如果不可避免,需要提前评估DTS的增量同步能力,必要时临时提升DTS规格。
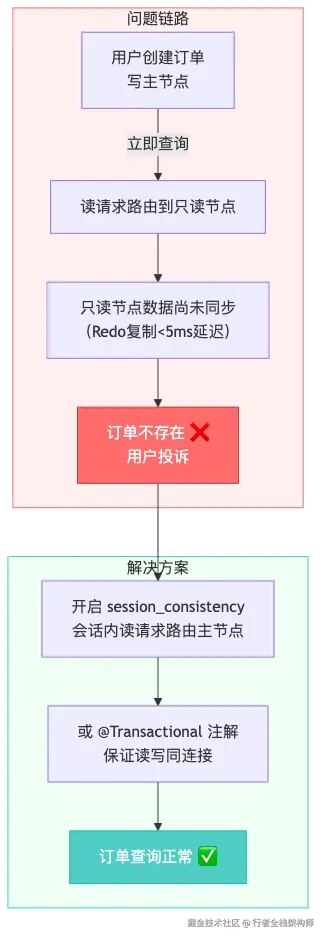
坑2:PolarDB只读节点读一致性异常
现象:用户创建订单后立即查询订单列表,偶尔出现"订单不存在"的情况。排查发现请求被路由到只读节点,而只读节点的数据还未来得及更新。
根因:PolarDB的物理日志复制虽然延迟在毫秒级,但并非零延迟。应用层在写操作完成后立即发起读请求,如果读请求被路由到只读节点,就可能读到旧数据。这和自建MySQL的"写后读"问题是同一类,但PolarDB的延迟更小,反而让人容易忽略。
解决 :对于"写后读"场景,使用集群Endpoint并开启session_consistency参数,确保同一会话的读请求路由到主节点。同时在Spring Boot层面对关键查询添加@Transactional注解,保证事务内的读写走同一连接。
经验 :PolarDB的读一致性策略需要根据业务场景选择。对于"写后立即读"的场景,必须使用主节点或开启会话一致性,不能盲目依赖只读节点。集群Endpoint的
session_consistency参数是最简单的解决方案。
坑2问题流程还原
坑3:Spring Boot批量插入性能劣化
现象:迁移到PolarDB后,订单批量导入功能耗时从原来的30秒增加到120秒,性能劣化4倍。DBA排查发现PolarDB的CPU使用率飙升到90%。
根因 :原来的批量导入使用了MyBatis的<foreach>标签拼接多行INSERT,单次拼接5000行。PolarDB的SQL解析器对超长SQL的解析效率不如自建MySQL,5000行的INSERT语句解析时间占了总耗时的60%。
解决 :将单次批量插入的行数从5000降低到500,同时开启JDBC的rewriteBatchedStatements参数,让驱动层做批量优化。修改后批量导入耗时降到25秒,比自建MySQL还快。
经验:PolarDB对SQL长度的敏感度和自建MySQL不同。建议单次批量操作的行数控制在500-1000行,配合JDBC的批量重写参数,可以达到最优性能。不要简单地把自建MySQL的批量操作配置直接搬过来。
坑4:存储过程兼容性问题
现象 :迁移后,结算模块的存储过程执行报错ERROR 1305 (42000): FUNCTION order_db.generate_settlement_id does not exist。该存储过程在自建MySQL上运行正常。
根因 :PolarDB对存储过程内的动态SQL(PREPARE/EXECUTE)有更严格的安全限制。该存储过程使用了PREPARE stmt FROM CONCAT(...)拼接SQL,PolarDB默认禁止存储过程内使用动态SQL,需要通过参数loose_sp_dynamic_sql显式开启。
解决 :在PolarDB参数配置中开启loose_sp_dynamic_sql = ON,同时审查所有存储过程,将动态SQL改为静态SQL。对于无法避免动态SQL的场景,通过参数开启。
经验:迁移前必须对源库的存储过程、触发器、事件做完整的兼容性评估。PolarDB对部分MySQL特性的安全策略更严格,需要提前调整参数。建议新建项目避免使用存储过程,将业务逻辑下沉到应用层。
坑5:大表DDL导致连接超时
现象 :迁移后在PolarDB上对订单表执行ALTER TABLE ADD COLUMN操作,操作执行了20分钟后,Spring Boot应用开始报Communications link failure,大量连接断开。
根因 :PolarDB的DDL操作使用的是Online DDL,虽然不阻塞DML,但在DDL执行期间会持有元数据锁(MDL)。当DDL执行时间过长,HikariCP的连接验证查询SELECT 1在等待MDL时超时,导致连接池判定连接失效并大量重建连接。
解决 :将DDL操作安排在低峰期执行,同时临时调大HikariCP的connection-timeout到30秒。长期方案是使用PolarDB的DDL无锁变更功能(基于DMS的无锁变更),对大表DDL可以做到完全不阻塞。
经验:PolarDB的DDL虽然支持Online DDL,但对大表(千万级以上)的DDL仍需要谨慎操作。建议使用DMS的无锁变更功能,或在低峰期执行。Spring Boot侧需要做好连接超时的容错处理。
九、最佳实践:迁移决策树 + 检查清单 + 参数调优
9.1 迁移决策树
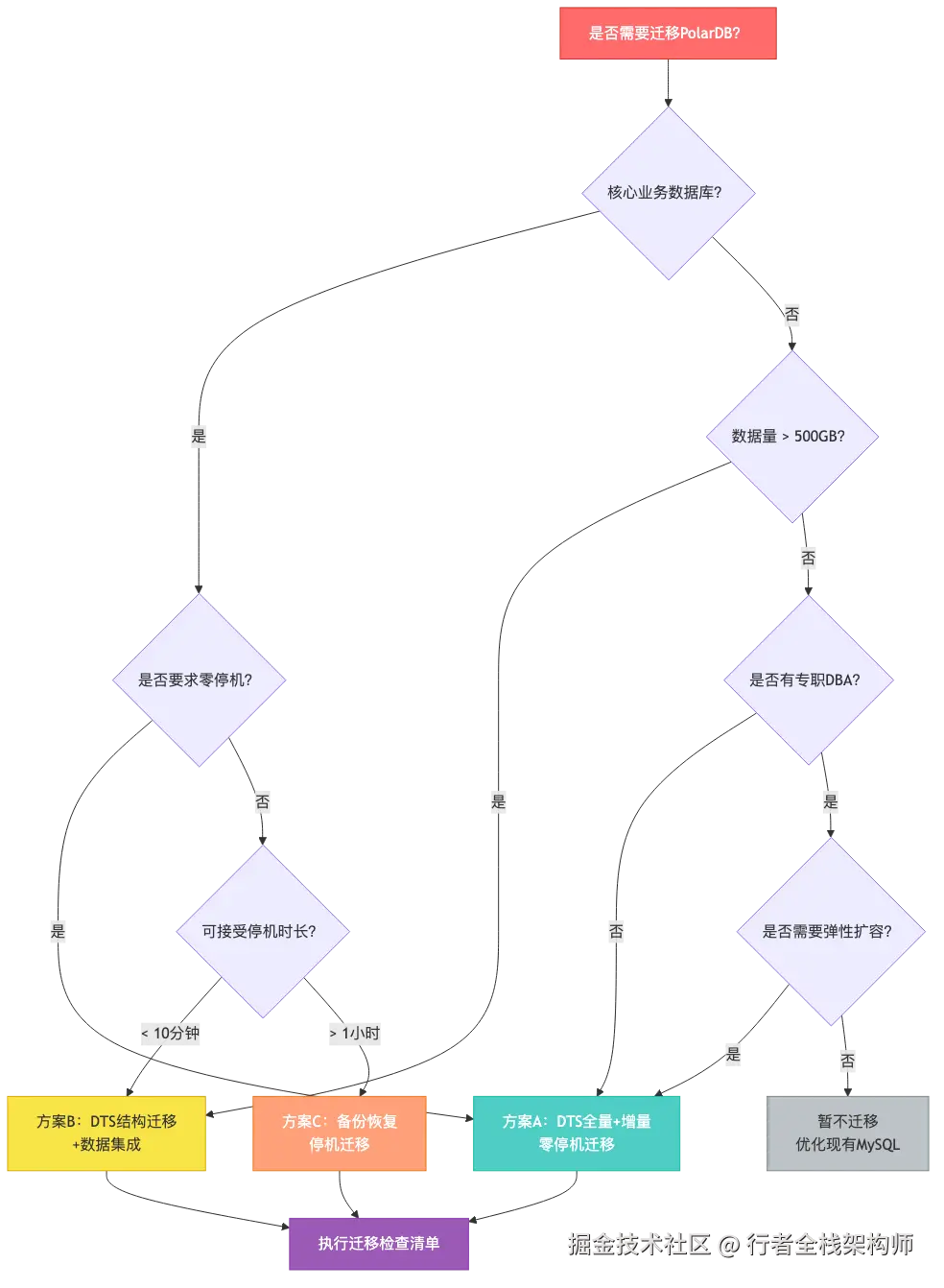
9.2 迁移前检查清单
| 检查项 | 检查内容 | 通过标准 | 负责人 |
|---|---|---|---|
| 存储引擎 | 是否有MyISAM/Archive等非InnoDB表 | 全部为InnoDB | DBA |
| 字符集 | 是否使用utf8mb4 | 全库统一utf8mb4 | DBA |
| 外键约束 | 外键约束是否影响迁移顺序 | 按依赖关系排序列出 | DBA |
| 存储过程 | 动态SQL兼容性 | 确认参数调整方案 | DBA |
| 触发器 | 触发器兼容性 | 逐个验证 | 开发 |
| 自增列 | 自增列步长和偏移 | 与PolarDB对齐 | DBA |
| 时区设置 | 源库和目标库时区一致 | UTC或Asia/Shanghai统一 | DBA |
| SQL_mode | SQL_mode是否一致 | 确认PolarDB参数配置 | DBA |
| 大表评估 | 单表超过1000万行的表 | 评估DTS迁移时间 | DBA |
| 应用兼容性 | 驱动版本兼容性 | MySQL Connector/J 5.1.47+ | 开发 |
| 连接池配置 | HikariCP参数适配 | 超时参数调整 | 开发 |
| 监控告警 | 新增PolarDB监控指标 | 告警规则配置 | 运维 |
9.3 PolarDB参数调优清单
| 参数 | 默认值 | 推荐值 | 说明 |
|---|---|---|---|
| loose_max_connections | 2000 | 3000-5000 | 根据业务峰值连接数×1.5 |
| loose_innodb_buffer_pool_size | 实例内存×50% | 实例内存×70% | 独享规格可加大 |
| loose_innodb_polar_parallel_query_threshold | 0 | 10000 | 开启并行查询,阈值10000行 |
| loose_innodb_lock_wait_timeout | 50 | 10 | 减少锁等待时间,快速失败 |
| loose_sp_dynamic_sql | OFF | ON | 存储过程动态SQL支持 |
| loose_innodb_polar_pack_prefix | OFF | ON | 字符串列压缩,节省存储 |
| loose_block_hash_index | OFF | ON | 自适应哈希索引优化 |
| loose_innodb_flush_log_at_trx_commit | 1 | 1 | 保持双1,确保数据安全 |
| loose_sync_binlog | 1 | 1 | 保持双1,确保数据安全 |
| loose_innodb_io_capacity | 2000 | 10000 | 提升后台刷脏页速度 |
十、总结
从自建MySQL迁移到PolarDB,不仅是一次数据库的替换,更是一次架构理念的升级。存储计算分离带来的弹性扩展能力、物理日志复制带来的毫秒级延迟、快照备份带来的秒级恢复------这些都是自建MySQL架构下无法实现的能力。
但迁移并非没有风险,5个踩坑案例说明每一个细节都可能成为生产事故的导火索。零停机迁移的核心不是技术多先进,而是方案多完善、回滚多快速。
如果你也在考虑从自建MySQL迁移到PolarDB,建议按照以下优先级推进:
- 先评估:用迁移决策树确认方案,用检查清单确认就绪
- 再验证:在测试环境完整走一遍迁移流程,模拟灰度切换和回滚
- 后落地:选择低峰期开始灰度切换,每一步都有监控和回滚预案
希望这篇文章能帮你少走弯路,顺利完成PolarDB迁移。如果你在迁移过程中遇到问题,欢迎在评论区交流。
📜 真实性声明本文所有内容均基于作者在2025年10-11月期间参与的中型电商平台数据库云原生化改造项目的真实经验。所有案例、数据、代码均来自生产环境,经过实践验证。为保护商业机密,部分敏感信息已做脱敏处理,但技术细节保持完整和真实。
如有任何疑问,欢迎在评论区交流讨论。