这是我做全栈架构时的一类典型工作:把后端的权限校验,从「散落在每个接口里的 if」收拢成一条声明 + 校验 + 对齐 + 兜底的链路。它体现的是用机制替代人记的工程判断。
权限体系最怕的不是「没做」,而是「散着做」。
「散着做」到底贵在哪
我接手过一个运营后台,权限校验是这种画风:这个接口开头一个 if (user.hasRole("admin")),那个接口中间塞一段 if (!user.can("edit")),还有几个接口压根没校验,靠「前端按钮不显示」硬撑。
老实讲,这种代码最致命的不是「能不能跑」,而是谁都不敢动。一段判断摆在接口里,三个月后你想删它,第一反应不是「这判断对不对」,而是「删了会不会越权」------因为没人知道这段判断是踩了哪个坑加的,删了出了事算谁的。于是它就赖在那儿,越来越多,越来越乱。
代价是具体的:
- 谁也不敢删那段判断,因为谁也不知道删了会不会越权。 最后代码里堆满「祖传 if」,谁动谁背锅。
- 前端按钮不显示,不等于后端没校验漏洞。 按钮显示是前端逻辑,接口鉴权是后端职责。黑客根本不经过你的前端,直接打接口。把安全寄托在「按钮藏起来了」,等于没做。
- 几个接口漏校验,纯靠运气没出事。 接口多了之后,「哪个加了哪个没加」全靠人记。今天没出事,是因为没人想到去打那个接口;明天被人扫到,就是事故。
- 权限和业务逻辑搅在一起,改一个判断得读懂整个方法。 这段判断嵌在业务代码中间,你要重构这个方法,就得先把权限逻辑摘出来------但摘出来的过程中,你怎么知道没摘错?
所以判断标准很简单:如果你问「这个接口的权限规则是什么」,得去翻业务代码才能回答,那就是散着做。 真正该有的状态是,看一眼注解就知道。
推倒重做时,核心思路就一句话------权限跟着接口走,不跟着人记。
注解声明,让权限长在接口上
定义一个注解,大概长这样:
java
@RequirePermission("ops:order:refund")
@PostMapping("/order/refund")
public Result refund(...) { ... }注意那个权限 key:ops:order:refund。它不是随手写的字符串,而要在迁移脚本的权限种子数据里先注册过。这一条最关键,后面要出事就出在这。
key 的命名是有规范的,我们整个团队统一用「资源:动作」的三段式:{系统}:{资源}:{动作},比如 ops:order:refund(运营后台 / 订单 / 退款)、ops:order:export、fin:bill:audit。规范本身不复杂,但它解决三件事:
- key 在种子数据里必须先注册。 没注册的 key 走到运行期要么报错要么放行,两种结果都不好。所以 key 是「先在种子表里声明,再在注解里引用」,顺序不能反。
- 和接口绑死,新人不用通读业务。 新人看接口签名就知道「这接口吃什么权限」,不需要去翻业务逻辑、不需要去问老人。这点对团队扩张特别值钱。
- 权限信息和接口定义不再分家。 改接口的人顺手就能看到权限要求,删接口的人知道顺手把种子 key 也清掉。
有了注解,接口要什么权限就是声明出来的:
- 新人不用通读业务逻辑,也能知道「这个接口吃
ops:order:refund」。 - 权限信息和接口定义绑在一起,不再散落在代码各处。
- 改接口的人顺手就能看到权限要求,删接口的人知道该把种子 key 也清掉。
- Code review 时,「这个接口有没有权限」从「翻业务代码」变成「看注解有没有」。
比满屏 if 清爽太多。注解本身的定义也就几行:
java
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface RequirePermission {
String value(); // 权限 key,如 ops:order:refund
boolean required() default true; // 是否强制,false 时走宽松校验
}过滤器链统一校验,顺序是命门
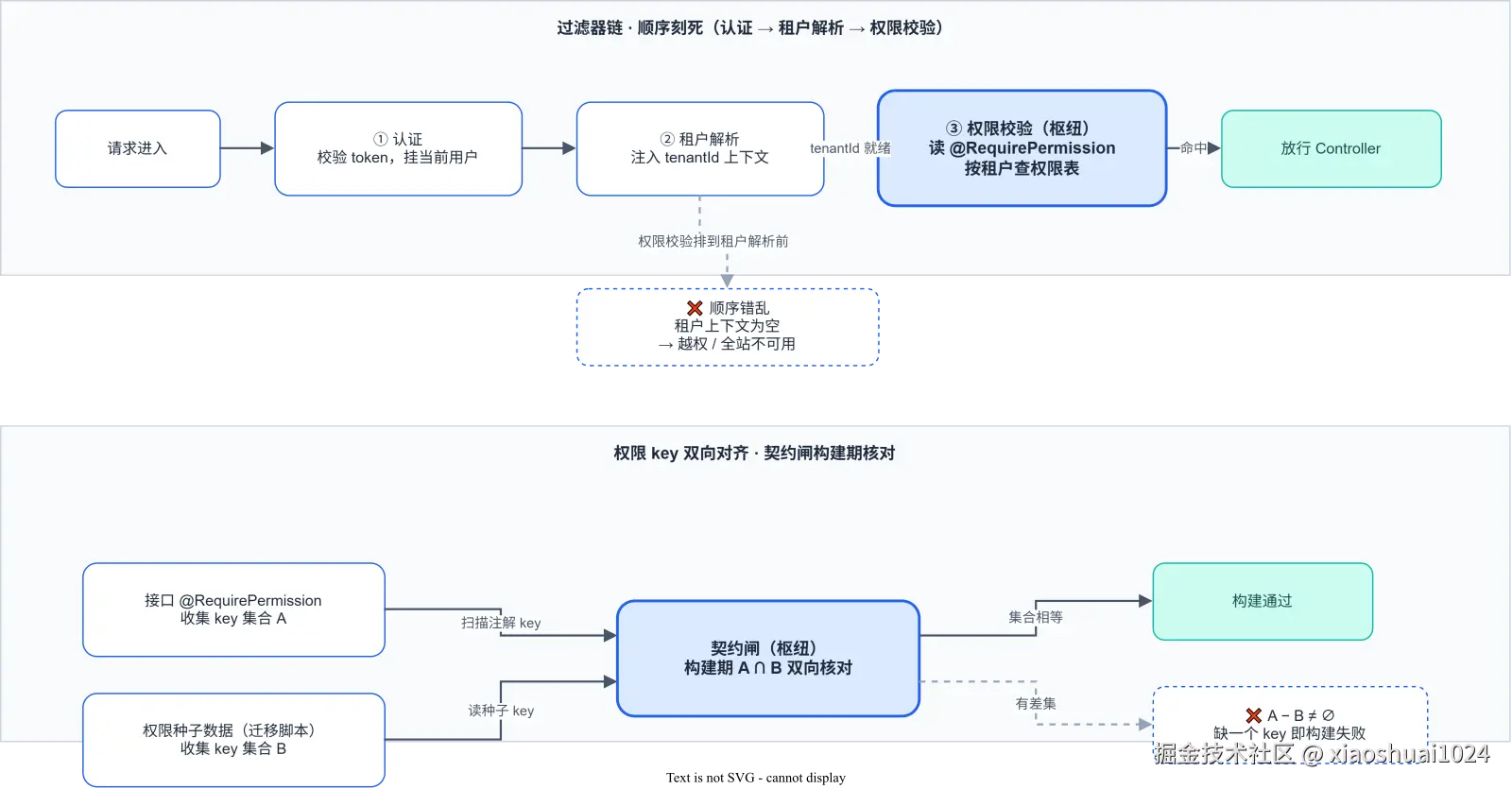
光有注解还不够,得有人去「读」它。这件事交给**过滤器链(filter chain)**统一做。请求进来,一路过:
认证 → 租户解析 → 权限校验
这个顺序必须刻死。问题的本质在于:权限校验这一步,要拿「当前用户属于哪个租户」去查权限表。如果它排在租户解析前面,租户上下文还没注入,拿到的永远是空,鉴权逻辑整个乱套。
顺序错乱的具体后果,都是事故级的:
- 权限校验排到租户解析前面,租户拿不到,查权限表查不到该用户的记录------要么一律放行(越权),要么一律拒绝(全站不可用)。
- 认证排到后面,你拿一个没校验过的 token 去解析租户,等于把黑客的输入当可信数据用,后面全白做。
所以我们把这套顺序白纸黑字写进文档,新加过滤器时必须按文档插位置 ,而不是凭感觉往链头一塞。顺序在过滤器链里是个隐式契约,不写下来迟早会乱。
java
// 过滤器顺序由 @Order 刻死,改顺序必须改文档
@Component
@Order(10) // 1. 认证:校验 token,挂上当前用户
public class AuthFilter implements Filter { ... }
@Component
@Order(20) // 2. 租户解析:注入 tenantId 到上下文
public class TenantContextFilter implements Filter { ... }
@Component
@Order(30) // 3. 权限校验:读 @RequirePermission,查租户权限表
public class PermissionFilter implements Filter {
// 伪代码:必须先从上下文拿 tenantId,再查权限
Long tenantId = TenantContext.get(); // ② 注入的
String key = method.getAnnotation(RequirePermission.class).value();
if (!permissionService.has(tenantId, userId, key)) {
throw new ForbiddenException(key + " not granted");
}
}这里的细节是:权限校验器自己不解析 token、不解析租户,它只消费前两步的结果。 职责单一,顺序才不会乱。
权限 key 和种子数据必须对齐
这是这类体系里最隐蔽的一类问题。
某次有人报:「这个资源我明明没给 create 权限,他怎么还能操作?」一查发现:代码里 @RequirePermission 写的是 create / edit / delete,但迁移脚本的权限种子数据里,这个资源只注册了一个 manage。
翻译成一句结论:接口要的权限 key,在权限表里压根不存在。
这种 bug 的危险在于它「静默地不安全」:
- 查不到对应 key 时,有的实现是「查不到就放行」------理由是「没配就是不限制」,直接越权。
- 它不崩、不报错,压测压不出来,QA 测不出来,只有真出事才知道。
为什么压测测不出?压测打的是流量和性能,它假设逻辑是对的。逻辑错了,流量再大也只是一个错误结果重复一万遍,日志里不会冒出一个 warn。QA 测不出同理------除非测试用例专门覆盖「key 不对齐」这条边角,否则就是一路绿灯通过。
所以规矩是:权限 key 必须双向对齐。
- 接口里 check 的 key,种子数据里必须有。
- 种子数据里注册的 key,得有接口在用。
- 谁多出来,谁就是问题。
种子 SQL 大概长这样,和注解里的 key 一一对应:
sql
-- 种子数据:key 必须先注册,接口才能引用
INSERT INTO sys_permission(key, name, resource, action) VALUES
('ops:order:refund', '订单退款', 'order', 'refund'),
('ops:order:export', '订单导出', 'order', 'export'),
('ops:order:view', '订单查看', 'order', 'view');这层契约,靠契约闸兜
光靠「大家记得对齐」是不行的。人和 AI 都会忘------尤其是新加接口时,注解里随手写个 key,种子数据忘了补,review 时眼神一飘就过了。
我把这条对齐做进了契约闸 :构建阶段扫一遍,接口上 @RequirePermission 声明的所有 key,去权限种子数据里逐个核对,缺一个就构建失败。
契约闸怎么落?大致三步:构建期扫一遍所有 Controller 的 @RequirePermission 注解,把 key 收集成集合 A;读迁移脚本里的权限种子 key,收集成集合 B;算 A - B,有差集就 fail,exit code 非 0,流水线挂掉。新加接口没补种子的那一刻,代码根本进不了主干。
伪代码,真没多少行:
python
# verify_permission_keys.py · 构建期执行(mvn validate 阶段)
keys_in_code = scan_require_permission_annotations("src/main/java") # 集合 A
keys_in_seed = extract_keys_from_flyway_migrations("db/migration") # 集合 B
missing = keys_in_code - keys_in_seed # 接口要、种子没有 → 越权风险
orphan = keys_in_seed - keys_in_code # 种子有、接口没用 → 死权限
if missing:
print(f"❌ 缺失权限 key:{missing}"); sys.exit(1)
if orphan:
print(f"⚠️ 孤儿权限 key(可清理):{orphan}")missing 是硬失败,orphan 是软告警------前者会越权,后者只是种子表里多了几条没人用的 key,清不清都行,但留着一眼就能看出来。
这条兜底一上,「漏配 = 越权」的事故基本就绝迹了。日常做 AI 协同研发时(主力 Claude Code,其次 Cursor、OpenCode),契约闸同样是让 AI 不漏配权限的那道防线。AI 加接口比人快得多,注解里 key 写错了它自己不知道,但构建闸会挡住。
核心判断是:安全这种事,不能指望人记,得指望机制兜。 人会犯错,注解会写错,种子会漏配,但构建闸不会放水。
最后说两句
回头看这套 RBAC 的演进,主线就一条:把权限从「散落在每个接口里的 if」,收拢成「声明 + 统一校验 + 种子对齐 + 契约兜底」的一条链。
一个权限体系成熟度怎么看?我的答案是:看它有多「不靠人记」。
如果一个新人改个接口,不需要懂历史、不需要问老人、不需要记住一堆隐式规矩,只要照着模板写注解、补种子,就能保证权限正确------那这套体系就算成了。如果还停留在「这个接口忘了加判断」的程度,那就还早。
权限这事,做得好的标志是**「没故事可讲」**。出故事了,基本就是越权了。