内容参考于:图灵AI大模型全栈
在线模型
这里还是使用千问的模型,下载指令如下
pip install llama-index-embeddings-dashscope
执行完指令,如下图红框就有了千问的模型
效果图:
python
# 前置依赖安装命令:需要先安装 LlamaIndex 官方的通义千问嵌入模型适配包
# pip install llama-index-embeddings-dashscope
# 导入操作系统交互模块,用来读取系统环境变量中的 API 密钥
import os
# 从 LlamaIndex 的通义千问适配包中导入嵌入模型类
# 作用:LlamaIndex 官方封装的阿里云通义千问文本向量生成工具
# 直接调用通义千问的在线嵌入接口生成文本向量,中文语义匹配效果优秀,无需本地部署大模型
from llama_index.embeddings.dashscope import DashScopeEmbedding
# 导入 dotenv 环境变量加载函数,用来读取 .env 文件里的配置
from dotenv import load_dotenv
# 执行加载 .env 文件,把文件里的 DASHSCOPE_API_KEY 等配置写入系统环境变量
# 好处:敏感的 API 密钥不写死在代码里,更安全,换环境只需要改 .env 文件
load_dotenv()
# 初始化通义千问嵌入模型实例,后续所有向量生成都通过这个对象调用
embed_model = DashScopeEmbedding(
# 指定使用的嵌入模型名称,text-embedding-v3 是通义千问的第三代文本嵌入模型
# 特点:中文语义理解能力强,向量维度适中,适合 RAG 检索场景
model_name="text-embedding-v3",
# 从环境变量中读取通义千问的 API 密钥,对应 .env 文件里的 DASHSCOPE_API_KEY
api_key=os.getenv("DASHSCOPE_API_KEY")
)
# ========== 方法1:查询专用向量转换 ==========
# get_query_embedding:专门用于生成「用户查询问题」的向量
# 作用:把用户的自然语言问题转换成向量表示,后续用来和文档向量做语义相似度匹配
# 设计逻辑:部分嵌入模型对「查询」和「文档」做了差异化训练
# 查询向量更聚焦检索意图,和文档向量匹配时召回准确率更高,是 RAG 场景的标准做法
query_emb = embed_model.get_query_embedding('你好')
# 打印查询向量,输出是一组浮点数数组,代表这段文本的语义特征
print(query_emb)
# ========== 方法2:单条文档向量转换 ==========
# get_text_embedding:用于生成「单条文档文本」的向量
# 作用:把单段文档内容转换成向量,一般用于文档片段入库时生成向量,存入向量数据库
# 场景:处理单个文本块、小批量内容时使用
text_emb = embed_model.get_text_embedding('你好')
# 打印单条文本向量
print(text_emb)
# ========== 方法3:批量文档向量转换 ==========
# get_text_embedding_batch:批量生成多条文本的向量
# 作用:一次性处理多条文本,批量返回对应的向量数组
# 优势:比循环调用单条方法的 API 请求次数更少、生成速度更快、更节省接口配额
# 是文档批量入库、构建知识库时的首选方式
text_emb = embed_model.get_text_embedding_batch(['你好', '你好'])
# 打印批量生成的向量列表,每个元素对应一条输入文本的向量
print(text_emb)调用本地向量模型
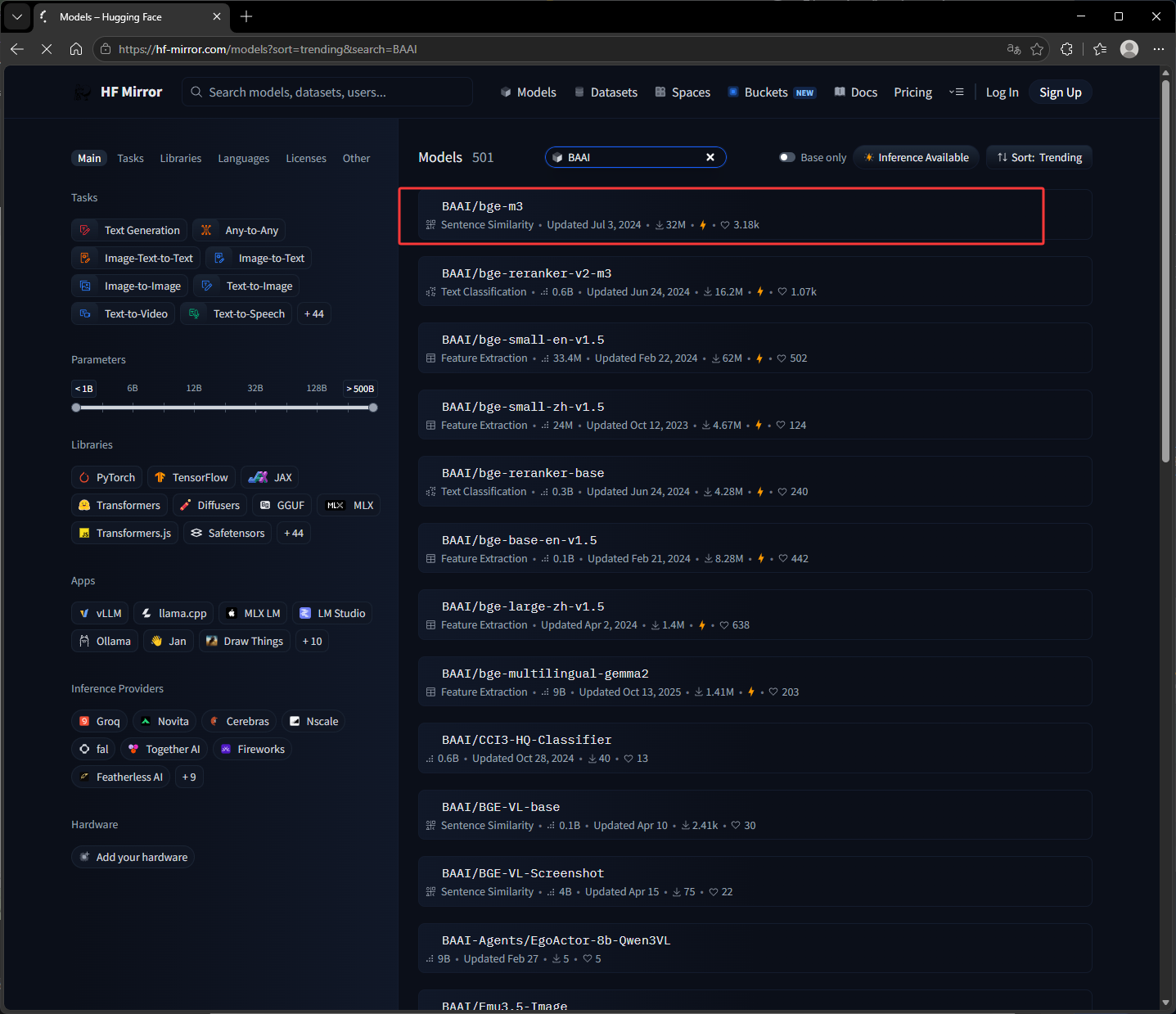
- 国内的镜像地址:https://hf-mirror.com/models
- 魔塔: https://www.modelscope.cn/models/maidalun/bce-embedding-base_v1
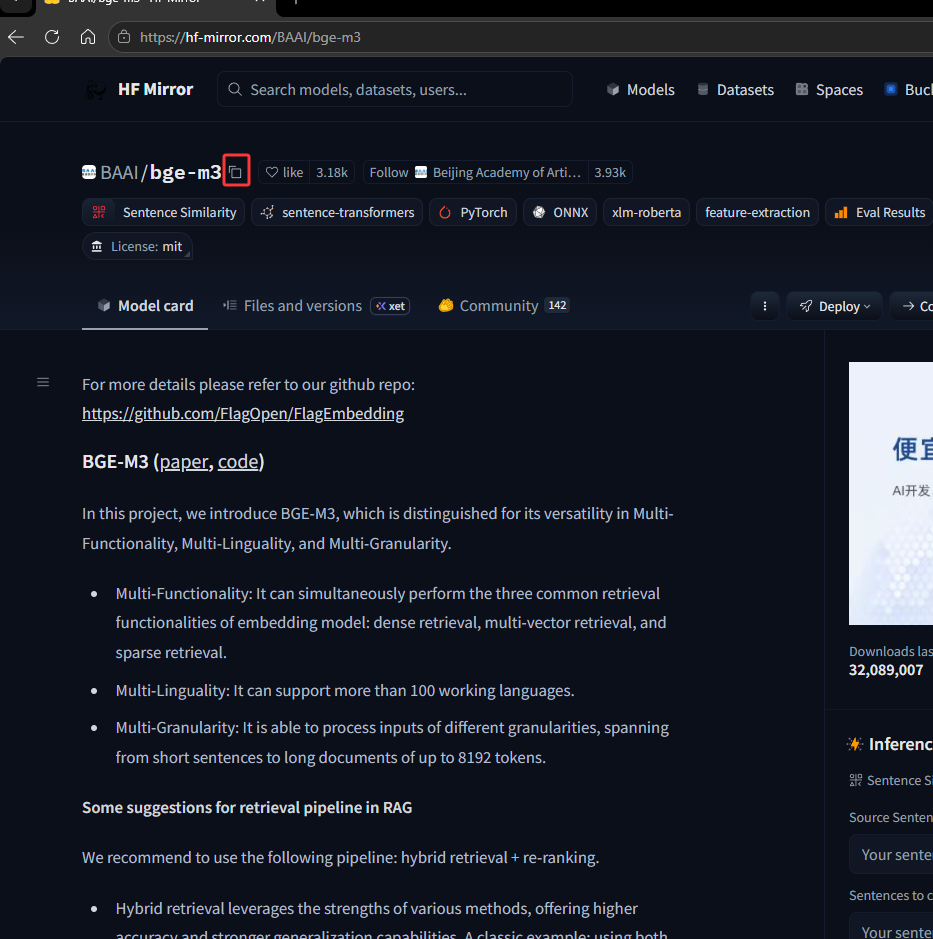
python# 安装模块 # pip install sentence_transformers from modelscope import snapshot_download # BAAI/bge-m3 模型名字 cache_dir:下载位置 model_dir = snapshot_download('BAAI/bge-m3', cache_dir=r"D:\LLM\Local_model")上方的代码就是下载的下图红框的向量模型
点击上图红框进入后,再点击下图红框,可以复制名字
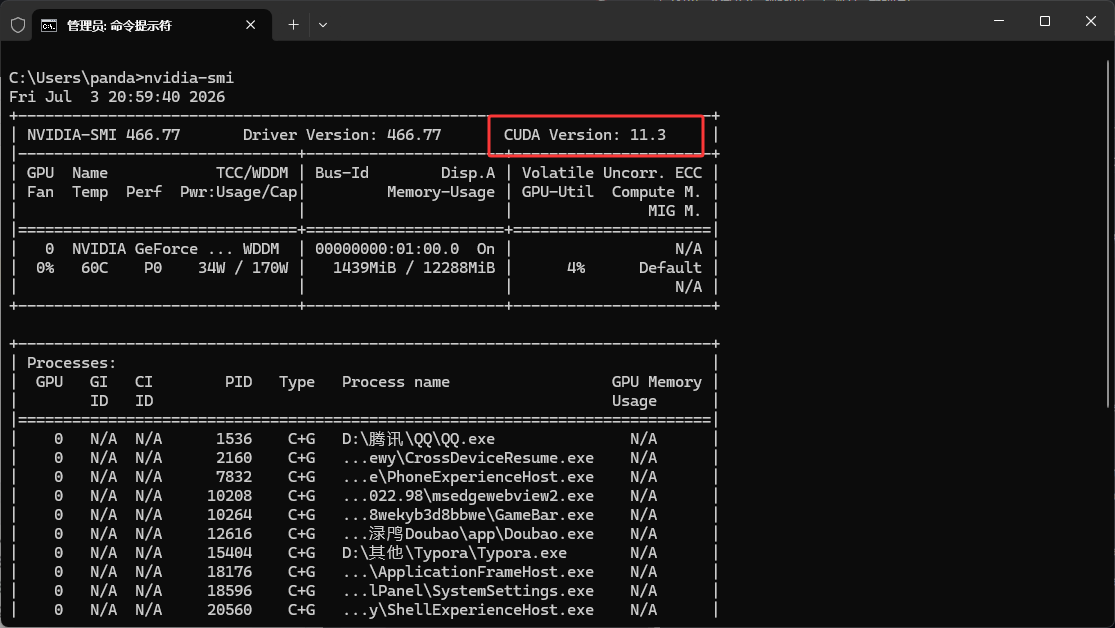
本地模型可以选择CPU运行和独立显卡运行,显卡运行需要安装一个pytorch,打开一个cmd输入nvidia-smi,查看下图红框位置,我的是11.3需要下载cu118,如果下图红框位置是12.x,就下载cu121
要英伟达的显卡,英伟达的显卡有CUDA,这个CUDA是专门用来驱动显卡芯片的,CUDA相当于是一个软件,可以用来操作显卡
下载cu
#12.x版本 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 #11.x版本 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118如果存在transformers版本冲突,就如下的指令降级
pip install "transformers==4.46.3" --force-reinstall代码,如果生成向量的内容很少,cpu和gpu的速度是差不多的
python# ========== 上方注释的是通义千问在线嵌入方案 ========== # 特点:调用阿里云在线接口生成向量,不用本地装模型,简单方便,但需要API密钥、消耗接口配额 # 本段代码是替代方案:本地加载开源嵌入模型生成向量,完全离线、不花钱、数据不外发 # 从 LlamaIndex 中导入 HuggingFace 嵌入模型类 # 作用:LlamaIndex 官方封装的本地嵌入模型适配工具,底层基于 sentence-transformers # 可以加载所有 HuggingFace 格式的开源嵌入模型(比如 bge 系列、m3e 系列) # 接口规范和在线嵌入模型完全一致,切换嵌入方案时业务代码不用改 from llama_index.embeddings.huggingface import HuggingFaceEmbedding # 初始化本地嵌入模型实例 embed_model = HuggingFaceEmbedding( # 指定模型路径:这里填你本地已经下载好的模型文件夹绝对路径 # 也可以直接填模型名(如 "BAAI/bge-m3"),会自动从 HuggingFace 下载 # 国内网络下载慢,所以一般提前把模型下到本地,直接填路径加载 # 路径前加 r 是 Python 原始字符串语法,避免 Windows 反斜杠被当成转义符 model_name=r"D:\huanjing\ai模型\BAAI\bge-m3", # 指定模型运行的设备 # device="cpu":用 CPU 运行,兼容性最好,所有电脑都能用,但生成速度慢 # device="cuda":用 NVIDIA(英伟达) 显卡运行,生成速度快很多,是推荐选项 # 注意:用 cuda 必须提前安装 CUDA 版本的 PyTorch,且电脑有 N 卡,否则会报错 device="cuda" ) # 生成「用户查询」专用向量 # 作用:把用户的问题转换成向量,RAG 场景下用来和文档向量做语义相似度匹配 # 设计逻辑:和在线版接口完全一致,部分嵌入模型对查询/文档做了差异化优化 # 统一用这个方法生成问题向量,检索准确率更高 query_emb = embed_model.get_query_embedding('你好') # 打印查询向量,输出是一组浮点数数组,代表这段文本的语义特征 print(query_emb) # 生成「单条文档」向量 # 作用:把单段文本转换成向量,一般用于文档片段入库时生成向量,存入向量数据库 # 接口和在线版的 get_text_embedding 完全一致,切换模型无感知 embedding = embed_model.get_text_embedding("你好") # 打印单条文本向量 print(embedding)