目录
1.摘要
进化算法与强化学习结合在单目标 RL 中有效,但难直接用于带偏好条件策略的多目标强化学习,因为进化策略参数需要反复评估,代价很高。本文提出 E2MORL不进化策略参数,而进化经验中偏好权重,使经验更有利于 RL 训练。候选经验按特定偏好下的标量效用评估,无需大量环境交互;种群从 RL 智能体接收优质候选,并用拥挤距离保持多样性。连续和离散任务实验表明,E2MORL 优于多种先进 MORL 方法。
2.多目标强化学习
MORL 用 MOMDP 表示,奖励为向量 r = r 1 , ... , r m T r=r_1,\\ldots,r_m^T r=r1,...,rmT。目标是获得 Pareto 最优策略,最大化期望回报 J = J 1 , ... , J m T J=J_1,\\ldots,J_m^T J=J1,...,JmT:
J i = E ∑ t = 0 ∞ γ t r i ( t ) , i = 1 , 2 , ... , m . J_i=\mathbb{E}\left\\sum_{t=0}\^{\\infty}\\gamma\^t r_i\^{(t)}\\right,\quad i=1,2,\ldots,m. Ji=Et=0∑∞γtri(t),i=1,2,...,m.
以偏好条件 DDPG 为例,价值网络损失为:
L ( θ ) = N − 1 ∑ ( r + γ Q θ ′ ( s ′ , π ϕ ′ ( s ′ , w ) , w ) − Q θ ( s , a , w ) ) 2 . L(\theta)=N^{-1}\sum\left(r+\gamma Q_{\theta'}(s',\pi_{\phi'}(s',w),w)-Q_{\theta}(s,a,w)\right)^2. L(θ)=N−1∑(r+γQθ′(s′,πϕ′(s′,w),w)−Qθ(s,a,w))2.
在线性标量化下,策略网络通过最大化偏好权重与向量 Q 值内积更新:
L ( ϕ ) = − N − 1 ∑ w T Q θ ( s , π ϕ ( s , w ) , w ) . L(\phi)=-N^{-1}\sum w^TQ_{\theta}(s,\pi_{\phi}(s,w),w). L(ϕ)=−N−1∑wTQθ(s,πϕ(s,w),w).
**现有 MORL 大体分为多策略方法和偏好条件策略方法。**多策略方法如 PGMORL、PA2D-MORL、Meta-MORL,为不同偏好学习多个策略,但存储和计算压力大。偏好条件方法如 Envelope、PD-MORL、Q-Pensieve、GPI-PD、Hyper-MORL,用一个条件策略响应不同偏好,更具扩展性,但偏好间学习不均衡。
现有 ERL 多面向单目标直接扩展到偏好条件 MORL 代价高,因为策略个体需在大量偏好下评估,且参数级进化受高维空间限制。偏好条件策略在不同偏好上学习不均衡,直接随机替换经验偏好可能产生低质量经验并干扰训练。因此,本文让 EA 搜索经验偏好权重,以效用筛选优质经验,并用拥挤距离维护种群多样性。
3.提出的算法
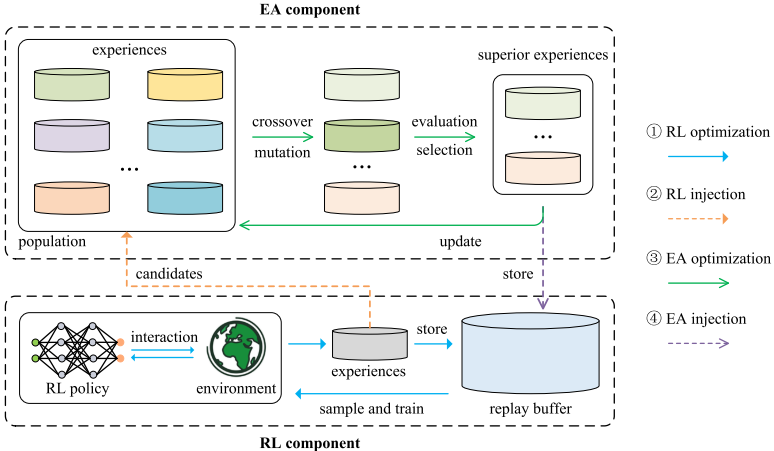
E2MORL 包含四步:RL 优化、RL 注入、EA 优化和 EA 注入。每个 episode 开始时,从分布 D D D 采样偏好 w w w 并按 L 1 L_1 L1 归一化;策略 π ϕ ( s , w ) \pi_{\phi}(s,w) πϕ(s,w) 与环境交互,经验同时存入回放池 R R R 和临时缓冲 R ′ R' R′。累计向量奖励 f R ′ f_{R'} fR′ 作为候选个体适应度,标量效用 w T f R ′ w^Tf_{R'} wTfR′ 用于更新当前智能体在该偏好区域的最好表现。
**经验级进化避免了策略参数高维搜索和个体评估需大量交互的问题。**一个个体 B p B_p Bp 存储一个 episode 经验,形式为 ( s 0 , a 0 , r 0 , s 1 , w p ) , ( s 1 , a 1 , r 1 , s 2 , w p ) , ... (s_0,a_0,r_0,s_1,w_p),(s_1,a_1,r_1,s_2,w_p),\\ldots (s0,a0,r0,s1,wp),(s1,a1,r1,s2,wp),...。因同一 episode 内偏好一致,可直接进化其偏好权重。

交叉从种群中随机选两个父代偏好 w p 1 = x 1 , ... , x m w_{p1}=x_1,\\ldots,x_m wp1=x1,...,xm 与 w p 2 = y 1 , ... , y m w_{p2}=y_1,\\ldots,y_m wp2=y1,...,ym,在位置 d d d 单点交叉:
w c 1 = x 1 , ... , x d , y d + 1 , ... , y m , w c 2 = y 1 , ... , y d , x d + 1 , ... , x m . w_{c1}=x_1,\\ldots,x_d,y_{d+1},\\ldots,y_m,\quad w_{c2}=y_1,\\ldots,y_d,x_{d+1},\\ldots,x_m. wc1=x1,...,xd,yd+1,...,ym,wc2=y1,...,yd,xd+1,...,xm.
变异则对父代偏好加入高斯噪声并取绝对值避免负权重: w c 3 = w p 3 + ∣ ϵ ∣ , ϵ ∼ N ( 0 , σ ) w_{c3}=w_{p3}+|\epsilon|,\epsilon\sim\mathcal{N}(0,\sigma) wc3=wp3+∣ϵ∣,ϵ∼N(0,σ)。子代权重归一化后,若其效用 w c i T f p i w_{ci}^Tf_{pi} wciTfpi 超过对应偏好区域中 RL 智能体的记录 U w c i U_{w_{ci}} Uwci,则把该经验复制到临时缓冲供 RL 训练。若子代相对当前智能体的改进幅度超过父代,则用子代偏好替换父代偏好。
RL 注入不是无条件复制策略,而是比较候选经验与种群个体的目标向量和多样性。若 RL 候选在所有目标上支配某个个体,则替换该个体;若二者互不支配,则计算候选与所有个体的拥挤距离,候选若不是最拥挤者,则替换拥挤距离最小的个体。
4.实验结果
实验覆盖连续和离散多目标控制任务。连续任务来自 MuJoCo,包括 HalfCheetah、Walker、Hopper、Ant-2、Humanoid、Ant-3。多数任务有两个目标:前进奖励和控制代价。前进奖励为:
R 1 = x t + 1 − x t d t . R_1=\frac{x_{t+1}-x_t}{dt}. R1=dtxt+1−xt.
控制代价为:
R 2 = − w c ∑ i a i 2 . R_2=-w_c\sum_i a_i^2. R2=−wci∑ai2.
对比方法包括 Envelope MORL、PGMORL、PD-MORL、Q-Pensieve 和 Hyper-MORL。
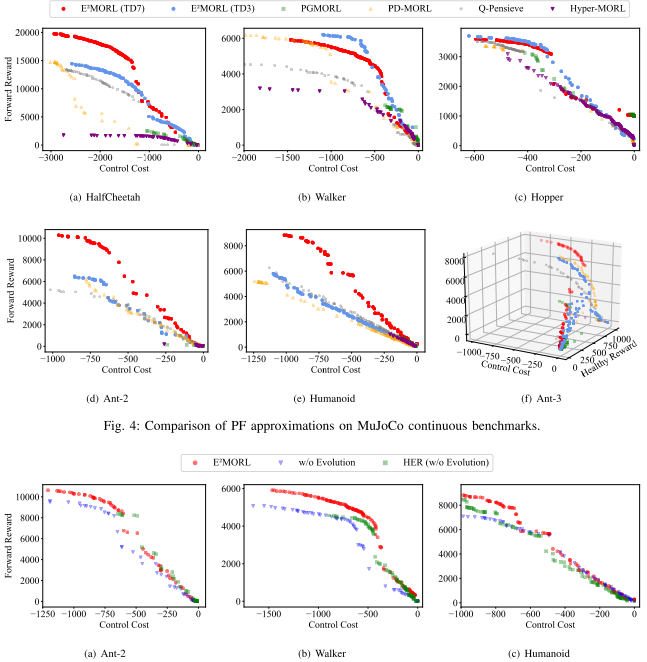
连续 MuJoCo 任务上,E2MORL 在多数环境取得最高 HV 和较低 SP。E2MORL(TD7) 与 E2MORL(TD3) 均表现优秀,说明框架可嵌入不同策略梯度算法。PGMORL 或 Hyper-MORL 在个别任务 SP 较低,但其点集中于目标空间小区域,HV 明显不足。
离散任务上,DST 中 E2MORL(DDQN) 与 PD-MORL 都能得到真实 Pareto 前沿;更难的六目标 FTN 中,E2MORL 在 HV 和 SP 上均优于 PD-MORL。结果说明经验级进化同样适用于价值型 RL。
5.结论
E2MORL方法不进化高维策略参数,而在经验层面搜索能促进 RL 学习的偏好权重;生成经验按标量效用筛选,无需大量交互评估种群;种群从 RL 智能体接收优质候选,并用拥挤距离保持多样性。E2MORL 可与策略型和价值型多目标 RL 结合,在连续与离散任务上均优于多种先进 MORL 方法。
6.参考文献
Wu X, Zhu Q, Lin Q, et al. Experience Evolution-Guided Multi-Objective Reinforcement LearningJ. IEEE Transactions on Evolutionary Computation, 2026.
7.算法辅导·应用定制·读者交流
xx