文章目录
- 一、前言
-
- [1、LangChain4j 简介](#1、LangChain4j 简介)
- [2、LangChain4j 中的常见术语](#2、LangChain4j 中的常见术语)
- 3、向量数据与向量数据库
- 二、ai-report的系统设计
- 三、ai-report创建项目
- 四、创建项目相关数据库和数据结构
- 五、langchain4j的java-api测试
- 六、langchain4j整合ai-report服务
- 七、向量数据
- 八、本系统知识库导入向量数据库(pinecone)
- 九、ai报表接口的完成(实现)
tex
想一下:你的web系统能够根据用户的提问自动生成报表么?
例如:
- 小米品牌手机在各个城市的销售情况是怎样
- 北京地区最畅销的各种手机或电脑品牌是哪些
- 目前系统商品销售情况怎样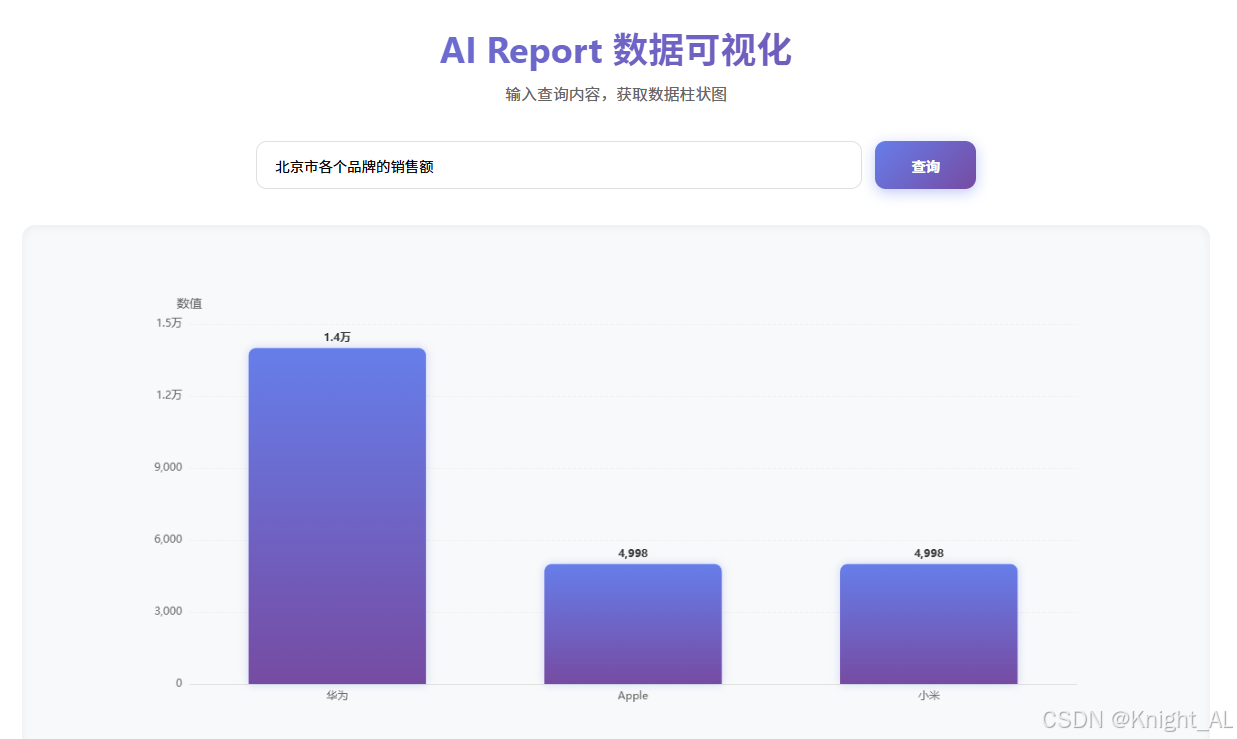
一、前言
1、LangChain4j 简介
LangChain4j 是一个 基于 Java 的大语言模型(LLM)应用开发框架 。
在实际使用中,它主要作为 业务程序与大语言模型之间的桥梁,帮助我们更方便地调用和管理各种大模型能力。
简单来说:
👉 LangChain4j = 用 Java 更轻松地接入和使用大语言模型
LangChain4j 的主要特点
1、统一的 API 接口
不同的大模型平台(如 OpenAI、Google Vertex AI)以及向量数据库,都有各自不同的 API。
LangChain4j 对这些 API 进行了统一封装,开发者只需要进行简单配置,就可以自由切换不同的模型或存储方案,而无需重写代码。
好处:
- 降低学习成本
- 提高开发效率
- 更方便后期更换模型或平台
2、功能完善的工具支持
LangChain4j 提供了从基础到高级的一整套工具,包括:
- 提示词模板(Prompt)
- 聊天记忆管理
- 结果解析
- RAG(检索增强生成)能力
这些工具可以帮助我们快速构建 聊天机器人、知识问答系统或 RAG 应用。
3、示例丰富,上手简单
官方提供了大量示例代码,覆盖常见使用场景,适合新手快速入门,也方便在实际项目中直接参考使用。
2、LangChain4j 中的常见术语
1、LLM(Large Language Model)
大语言模型,是基于深度学习的自然语言处理模型,能够理解和生成文本。
我们向 LLM 发送问题(Prompt),它会返回对应的回答。
2、RAG(Retrieval-Augmented Generation)
检索增强生成,是一种 "先查资料,再让模型回答" 的技术。
工作流程很简单:
- 先从外部知识库中检索相关内容
- 将检索到的内容与用户问题一起发送给 LLM
- 由模型生成更准确、更贴合业务场景的回答
RAG 可以有效解决模型 知识不准确或不及时 的问题。
3、API(应用程序接口)
在调用大语言模型时,需要配置对应的 API 信息,例如:
- 模型平台
- 模型名称
- API Key
这些配置决定了我们具体使用哪一个模型以及如何访问它。
4、Embedding Store(向量存储)
Embedding Store 用于存储 文本向量,通常由向量数据库实现。
核心作用是:
👉 相似度搜索
基本思路:
- 将文本转换成向量
- 存入向量数据库
- 用户提问时,将问题也转换成向量
- 在数据库中查找最相似的文本
- 将这些文本作为 Prompt 的一部分发送给 LLM
3、向量数据与向量数据库
向量数据库(Vector Database)是一种 以向量形式存储数据的数据库 。
与传统数据库通过"精确匹配"不同,向量数据库更擅长做 相似度搜索。
简单理解就是:
👉 不是找一模一样的内容,而是找"最像"的内容
向量数据库能做什么?
当用户输入一个词或一句话时,向量数据库会返回与其 语义最接近 的数据。
举个简单的例子
- 输入 "北京" ,可能返回:
中国、首都、华北、奥运会 - 输入 "沈阳" ,可能返回:
东北、辽宁、重工业、雪花
具体返回什么内容,取决于数据库中已经存储的数据,以及查询时设置的参数(如返回数量、相似度阈值等)。
什么是数据向量化?
由于向量数据库只能存储和计算向量,因此 所有文本在进入向量数据库之前,都需要先进行向量化。
数据向量化的过程是:
- 调用 AI 模型(Embedding 模型)
- 将文本转换为固定维度的数字向量
- 将向量存入向量数据库,或用于相似度查询
无论是 存数据 还是 查数据,都必须先经过这一步。
向量数据的本质
向量数据本质上是 人类语言在计算机中的数学表示。
通过把文本转换成高维向量:
- 计算机可以使用数学方法计算"相似度"
- 从而判断两段文字在语义上是否接近
也正是因为这样,计算机才能"理解"人类语言,并在大量数据中快速找到相关内容。
二、ai-report的系统设计
这里系统ai-report工作流程主要分为两步:
1 自然语言模型调用:用户通过自然语言描述自己想要看到的统计报表描述,该描述以参数形式传入sky-ai-report服务,然后sky-ai-report服务通过远程接口调用llm大模型服务器,对用户描述进行分析处理,sky-ai-report服务得到llm的反馈结果,根据用户的语义,提取出统计关键信息,如:以什么内容进行分组,以什么内容进行聚合统计。
2 向量数据库匹配:LLM的分析结果尚不能直接当作统计业务字段使用,这里需要使用向量数据库进行业务字段内容匹配,向量数据库是一种将信息通过ai算法转化为"高维向量数据"并且存储的数据库(这里需要学习向量数据的原理,暂不展开)。因为LLM对用户提问的解析结果中的关键词和sky-ai-report服务中的存储层的统计字段并不是完全一致的,这里需要使用向量数据库将解析结果中的关键词匹配成系统的业务字段。然后才能进行统计查询。
1、自然语言模型ai接口调用
目的是通过llm大模型对用户的提问的分析,提取用户的自然语言中与报表统计相关的关键词(用户语义解析),一般可以规定LLM以JSON格式返回结果。
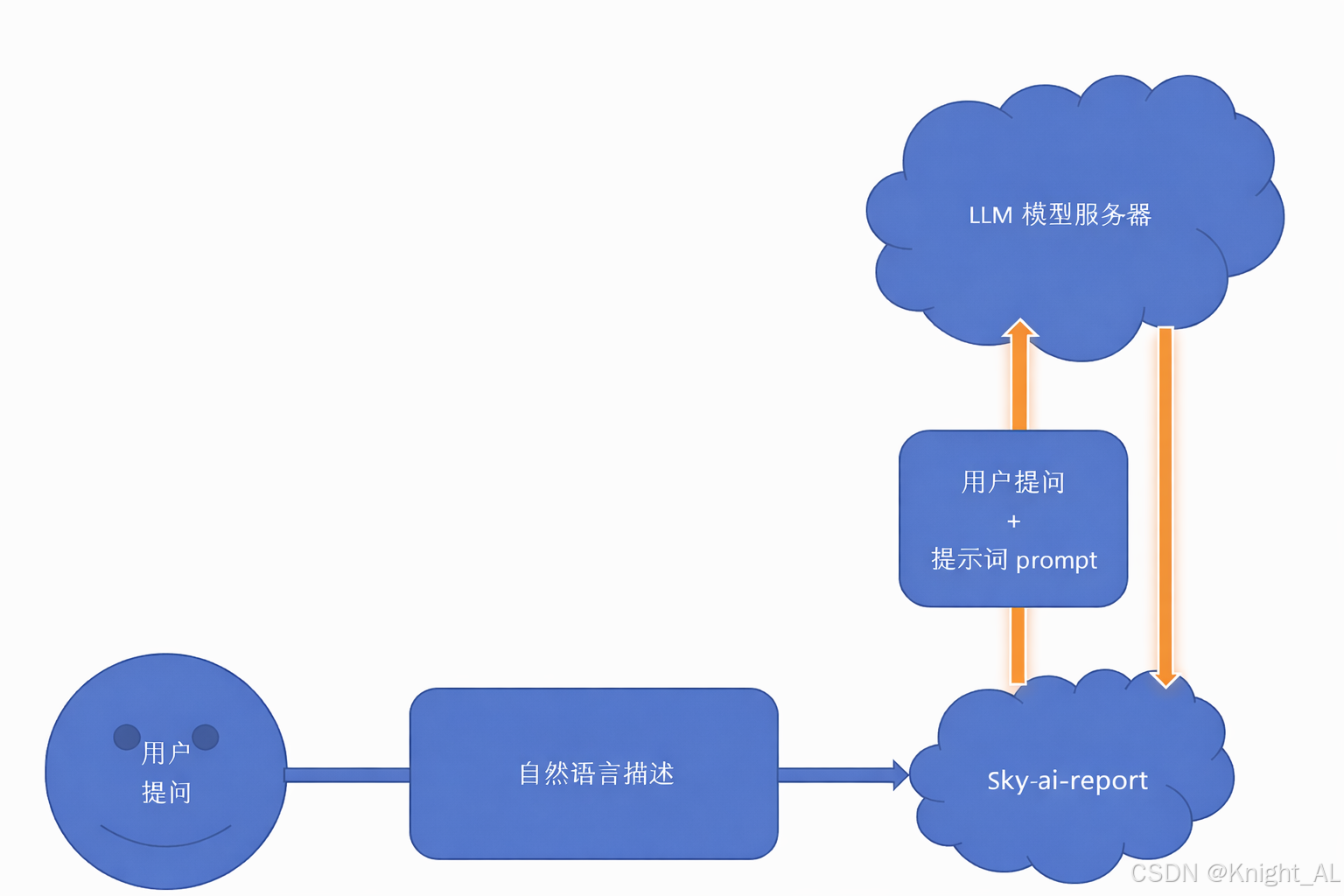
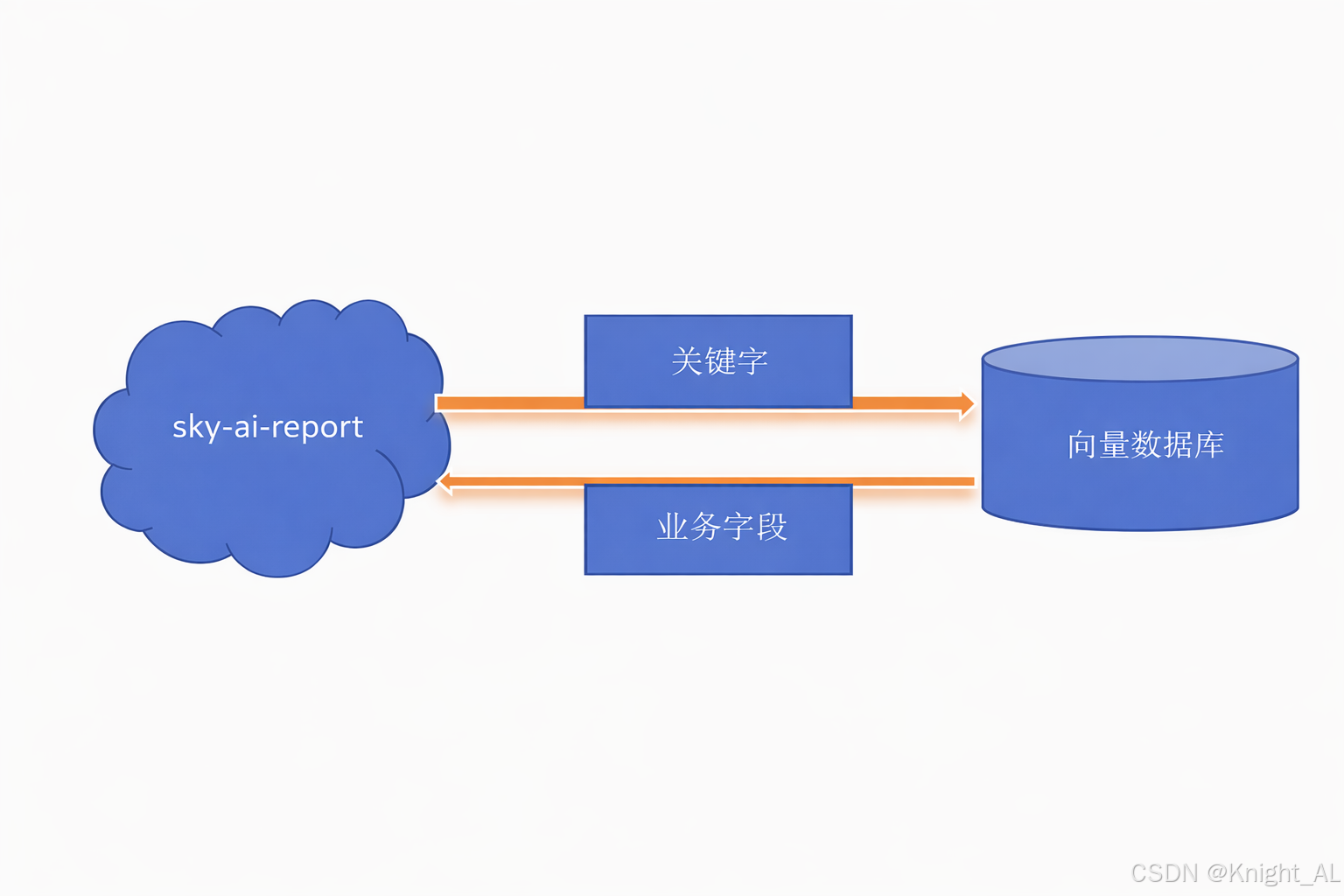
2、用向量数据库中的向量信息匹配处理结果
目的是将llm提取的报表关键词匹配成系统的数据业务字段,这里用到了向量匹配
-
1.什么是向量数据:LLM的向量数据是指大型语言模型(Large Language Model, LLM)将文本转换为高维数值向量的过程与结果。其核心是通过嵌入式技术(Embedding)把离散的文本符号(如词、短语或句子)映射为连续的向量空间中的点,从而捕捉语义、语法及上下文信息。简而言之:是将自然语言分解,并且转化成空间几何坐标,这样我们就可以用空间几何公式计算自然语言之间的关系了。
-
2.低维向量和高维向量:
三维向量:0.01231313,0.18293891,0.12738173
高维向量:如300个数值
"猫" → 0.25, -0.71, 0.43, ..., 0.08
"狗" → 0.28, -0.69, 0.41, ..., 0.12
"电脑" → -0.13, 0.45, -0.21, ..., -0.09
-
3.总结:高维向量通过提供充足的数学空间,使LLM能编码语言的复杂特性,是模型实现语义理解和推理的基础。
三、ai-report创建项目
1、项目pom依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>sky-modules</artifactId>
<groupId>com.sky</groupId>
<version>3.6.3</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>sky-aiReport</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
<version>1.0.0-beta4</version>
</dependency>
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-rc1</version>
</dependency>
<!--langchain4j高级功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-rc1</version>
</dependency>
<!-- apache远程工具-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.14</version>
</dependency>
<!-- JSON 解析器和生成器 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.18.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.18.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.18.0</version>
</dependency>
<!-- SpringCloud Alibaba Nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- SpringCloud Alibaba Nacos Config -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- SpringCloud Alibaba Sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- SpringBoot Actuator sba springboot admin-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Mysql Connector -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<!-- RuoYi Common Log -->
<dependency>
<groupId>com.spzx</groupId>
<artifactId>spzx-common-log</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>2、项目配置文件
yaml
server:
port: 9300
mybatis-plus:
mapper-locations: classpath*:mapper/**/*Mapper.xml
type-aliases-package: com.donglin.**.domain
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 查看日志
global-config:
db-config:
logic-delete-field: del_flag # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2)
logic-delete-value: 2 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
# spring配置
spring:
data:
redis:
host: 192.168.121.140
port: 6379
password:
datasource:
# type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.140:3306/spzx-report?characterEncoding=utf-8&useSSL=false&&allowPublicKeyRetrieval=true
username: root
password: 123456
hikari:
connection-test-query: SELECT 1
connection-timeout: 60000
idle-timeout: 500000
max-lifetime: 540000
maximum-pool-size: 10
minimum-idle: 5
pool-name: AiReportHikariPool3、项目启动类
java
package com.donglin.report;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class AiReportApplication {
public static void main(String[] args) {
SpringApplication.run(AiReportApplication.class,args);
}
}四、创建项目相关数据库和数据结构
1、数据结构设计
这里我们要设计四个数据结构,其中包括两张视图view和两个数据库表table
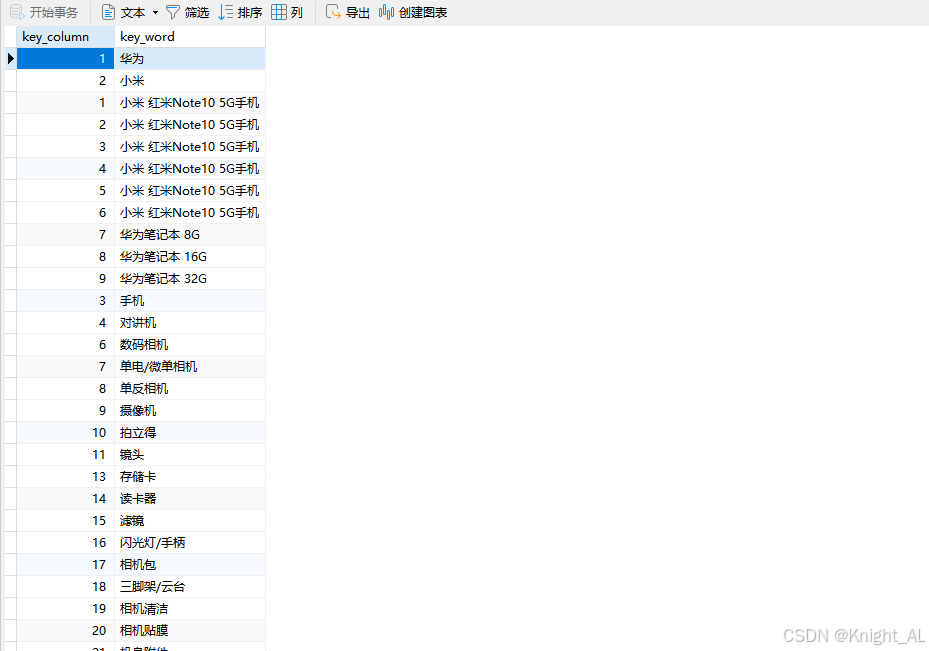
1 视图v_order_info:与订单相关的一个"宽表",涉及订单信息,订单详情,用户信息,商品spu和sku信息,以及分类信息
2 视图vector_select_key:系统中品牌,分类,地区信息的数据,将来会通过ai转化成向量数据存入向量数据库,做统计条件匹配
3 表vector_count_key:存储报表聚合统计字段和对应的用户所输入的关键信息,将来会通过ai转化成向量数据存入到向量数据库中,做统计标的匹配(一般的统计标的分为三个:订单个数order_id,订单总金额order_amount,以及下单人数user_id)
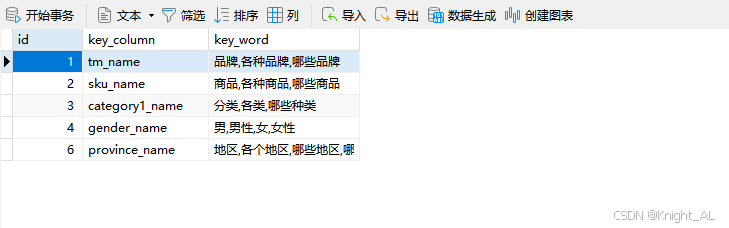
4 表vector_group_key:存储报表分组关键字段和用户所输入的关键信息,将来会通过ai转化成向量数据存入到向量数据库中,做统计分组字段的匹配
2、项目数据结构创建
1 vector_count_key
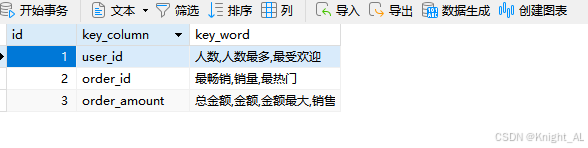
sql
CREATE TABLE `vector_count_key` (
`id` int NOT NULL AUTO_INCREMENT,
`key_column` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`key_word` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of vector_count_key
-- ----------------------------
INSERT INTO `vector_count_key` VALUES (1, 'user_id', '人数,人数最多,最受欢迎');
INSERT INTO `vector_count_key` VALUES (2, 'order_id', '最畅销,销量,最热门');
INSERT INTO `vector_count_key` VALUES (3, 'order_amount', '总金额,金额,金额最大,销售额,销售额最高,销售情况');2 vector_group_key
sql
CREATE TABLE `vector_group_key` (
`id` int NOT NULL AUTO_INCREMENT,
`key_column` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`key_word` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of vector_group_key
-- ----------------------------
INSERT INTO `vector_group_key` VALUES (1, 'tm_name', '品牌,各种品牌,哪些品牌');
INSERT INTO `vector_group_key` VALUES (2, 'sku_name', '商品,各种商品,哪些商品');
INSERT INTO `vector_group_key` VALUES (3, 'category1_name', '分类,各类,哪些种类');
INSERT INTO `vector_group_key` VALUES (4, 'gender_name', '男,男性,女,女性');
INSERT INTO `vector_group_key` VALUES (6, 'province_name', '地区,各个地区,哪些地区,哪些省,各个省,各个城市,哪些城市');3 v_order_info

sql
CREATE VIEW v_order_info AS
SELECT
DISTINCT
oi.order_id,
o.order_no,
oi.sku_price * oi.sku_num AS order_amount,
oi.sku_num,
oi.sku_name,
o.user_id,
d.dict_sort AS gender,
d.dict_label AS gender_name,
r.id AS province_id,
r.name AS province_name,
c1.id AS category1_id,
c1.name AS category1_name,
c2.id AS category2_id,
c2.name AS category2_name,
c3.id AS category3_id,
c3.name AS category3_name,
b.id tm_id,
b.name tm_name,
o.order_status,
oi.update_time create_date
FROM `sky-order`.order_item oi
JOIN `sky-order`.order_info o ON oi.order_id = o.id
JOIN `sky-user`.user_address ua ON o.user_id = ua.user_id
JOIN `sky-user`.user_info ui ON ua.user_id = ui.id
JOIN `sky-user`.region r ON r.code = ua.province_code
JOIN `sky-product`.product_sku ps ON ps.id = oi.sku_id
JOIN `sky-product`.product_spec psp ON ps.product_id = psp.id
LEFT JOIN `sky-system`.sys_dict_data d ON ui.sex = d.dict_code
LEFT JOIN `sky-product`.category c3 ON psp.category_id = c3.id
LEFT JOIN `sky-product`.category c2 ON c3.parent_id = c2.id
LEFT JOIN `sky-product`.category c1 ON c2.parent_id = c1.id
JOIN `sky-product`.product p ON p.category3_id= c3.id
JOIN `sky-product`.brand b ON b.id = p.brand_id
WHERE c1.parent_id = 0;4 vector_select_key
sql
CREATE VIEW vector_select_key AS
SELECT
`b`.`id` AS `key_column`,
`b`.`name` AS `key_word`
FROM
`sky-product`.`brand` `b` UNION ALL
SELECT
`ps`.`id` AS `key_column`,
`ps`.`sku_name` AS `key_word`
FROM
`sky-product`.`product_sku` `ps` UNION ALL
SELECT
`c`.`id` AS `key_column`,
`c`.`name` AS `key_word`
FROM
`sky-product`.`category` `c`
WHERE
`c`.`parent_id` IN (
SELECT
`sky-product`.`category`.`id`
FROM
`sky-product`.`category`
WHERE
`sky-product`.`category`.`parent_id` IN (
SELECT
`sky-product`.`category`.`id`
FROM
`sky-product`.`category`
WHERE
( `sky-product`.`category`.`parent_id` = 0 ))) UNION ALL
SELECT
`r`.`id` AS `key_column`,
`r`.`name` AS `key_word`
FROM
`sky-user`.`region` `r`
WHERE
(
`r`.`level` = 1)3、启动测试
这里我们要构建对应的mybatis-plus的映射实体和mapper
然后启动测试,可以创建一个测试接口,调通整个项目
五、langchain4j的java-api测试
1、注册和登录阿里云
2、选择百炼平台
百炼平台是阿里的ai服务,在模型广场选择deepseek-v3作为测试用例。
3、平台服务的连接和测试
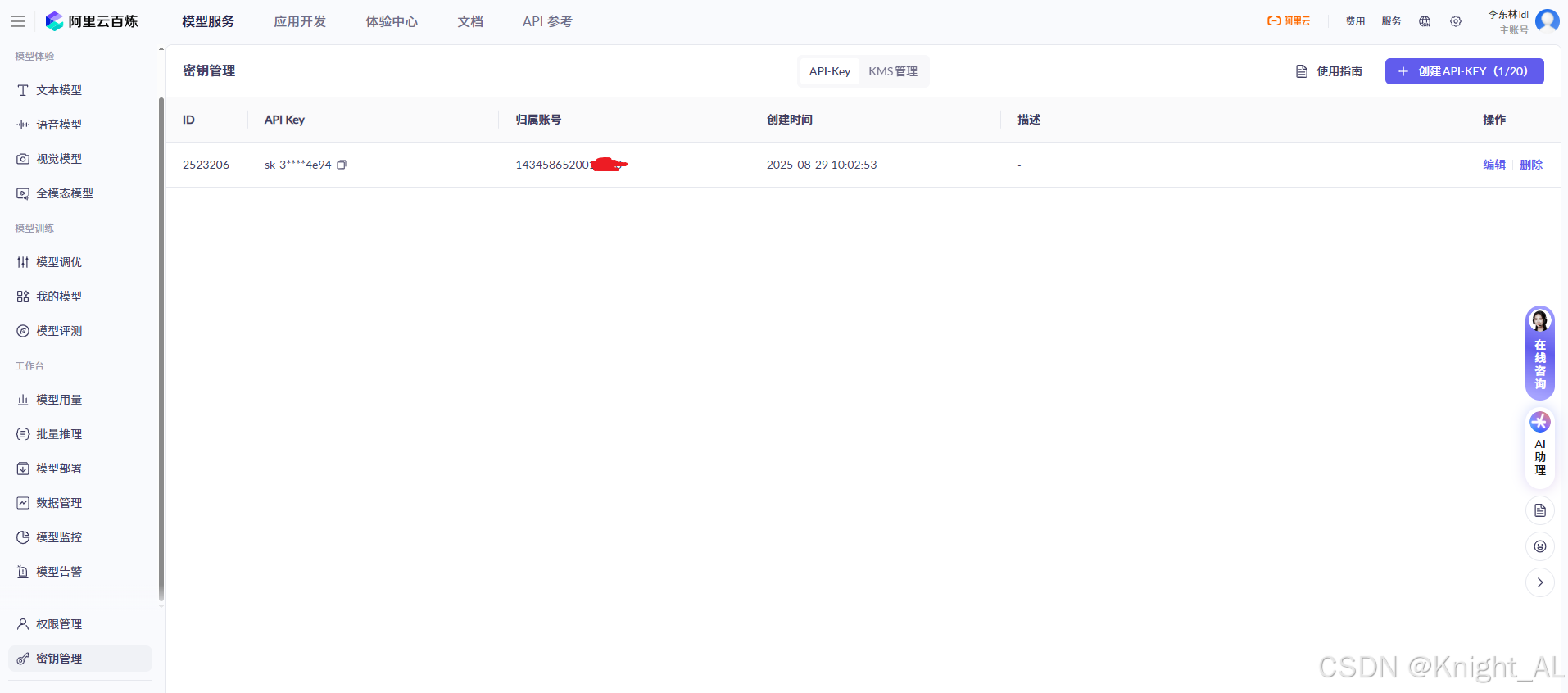
1 创建api-key,在平台广场的左下角选择api-key
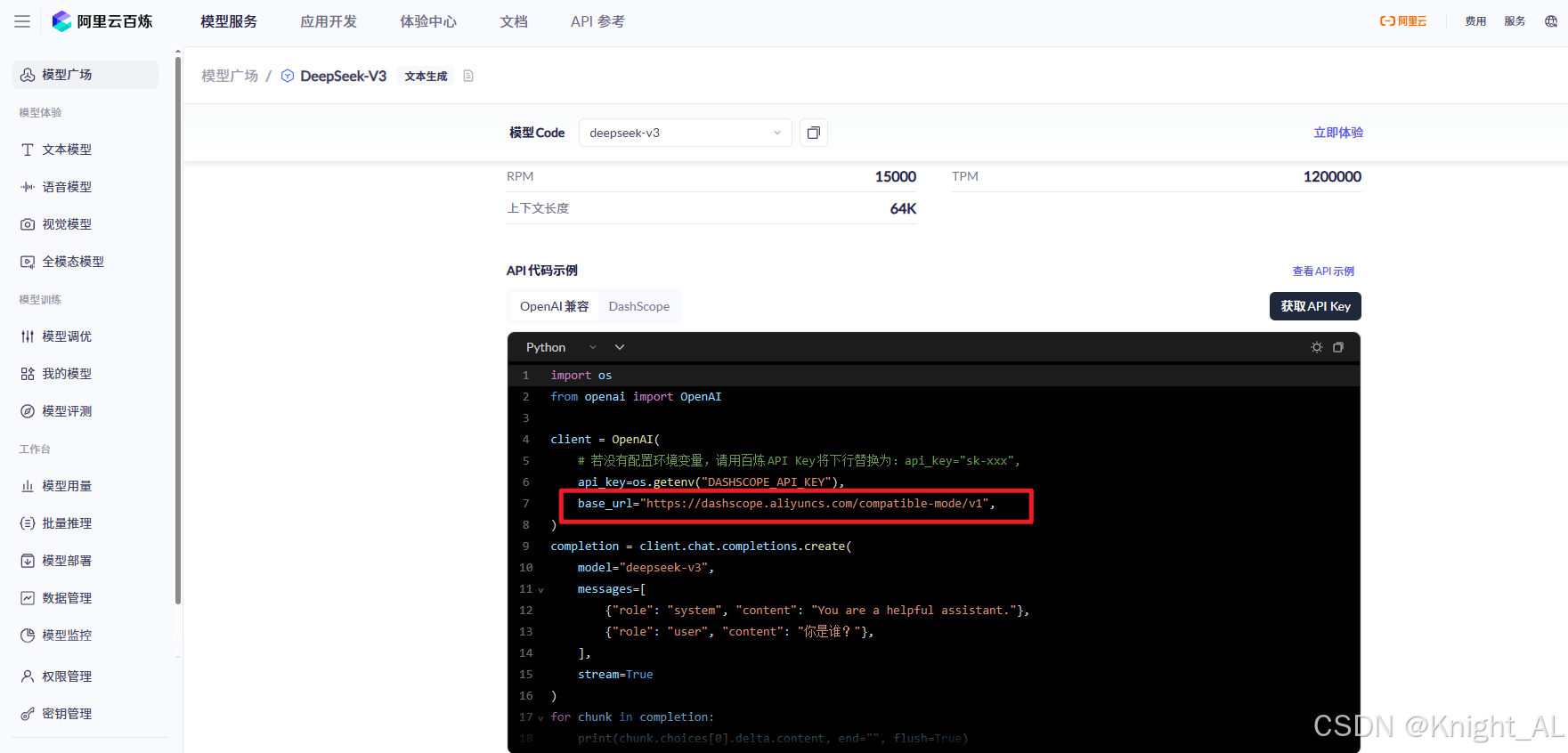
2 找到模型名的url连接地址
url地址连接:
3 模型名:deepseek-v3
4、调用测试
LangChain4j作用主要就是通过阿里百炼平台API去调用大语言模型,因此需要引入一些LangChain4j的基本依赖。
有两种方式都可以引入依赖,1 可以直接引入,2 在父工程中先引入依赖管理清单,然后再引入依赖,此时不用写版本号,类似springcloud的管理方式。
1 依赖管理清单模式,类似于springcloud的引入方式,此种方式因为与若依框架版本有冲突,如果使用则需要对若依框架进行较大改动,所以不建议使用
第一步:在parent中引入
xml
<properties>
...
<langchain4j.version>1.0.0-beta3</langchain4j.version>
</properties>
<!--引入langchain4j依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>第二步:在项目中引入
xml
<!--langchain4j基础功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<!--langchain4j高级功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>2 直接在项目中引入依赖,在ai-report中直接引入带有版本号的依赖,此种方式与若依框架没有直接冲突,建议使用
xml
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-rc1</version>
</dependency>
<!--langchain4j高级功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-rc1</version>
</dependency>写一个测试类,连接大模型,并且向其提问,这里我们直接使用main方法就可以
java
public static void main(String[] args) {
//初始化模型
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey("sk-3b4202468c534a1e8bab7063fcc34e94")
.modelName("deepseek-v3")
.build();
//向模型提问
String answer = model.chat("如果你变成了人类,你最想做的事情是什么?");
//输出结果
System.out.println(answer);
}
六、langchain4j整合ai-report服务
(此处不使用lc4j的springboot整合依赖,前面已经提到过)
1、三个基本参数
java
1 平台的api-key
// bK=百炼平台的key
static final String DASHSCOPE_API_KEY = "sk-3b4202468c534a1e8bab7063fcc34e94";
2 平台调用url
// burl = 百炼平台的Url
static final String DASHSCOPE_API_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1";
3 模型名
// DEEPSEEK_V3
static final String DEEPSEEK_V3 = "deepseek-v3";2、使用springboot依赖
spzx-aiReport依赖
xml
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-rc1</version>
</dependency>
<!--langchain4j高级功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-rc1</version>
</dependency>3、微服务测试接口
1 接口层
java
@RestController
public class ReportController {
@Autowired
private ReportService reportService;
@GetMapping("test1")
public String test1() {
String answer = reportService.test1();
return answer;
}
}2 业务层
java
@Service
public class ReportServiceImpl implements ReportService {
@Override
public String test1() {
// 初始化语言模型
ChatModel llmProc = OpenAiChatModel.builder()
.apiKey("sk-3b4202468c534a1e8bab7063fcc34e94")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") // SpzxAiConst.DASHSCOPE_API_BASE_URL;
.modelName("qwen-plus")// 通义千问
.build();
MyAssistAgent agent = AiServices.builder(MyAssistAgent.class)
.chatModel(llmProc)
.systemMessageProvider((ignored) -> "提示词模板")
.build();
//向模型提问
String answer = agent.chat("你好");
//输出结果
System.out.println(answer);
return answer;
}
}
csharp
package com.donglin.report.aitool;
//定义AI代理接口,处理用户提问
public interface MyAssistAgent {
public String chat(String userMessage);
}3 启动项目测试接口
4、封装ai的调用工具
现在,我们已经知道如何使用langchain4j的api调用大模型了,接下来,我们把调用过程封装一下,方便我们后续的项目业务的开发,这里我么你主要封装三部分内容,分别是:
1 公共参数,包括url,key,模型名
2 提示词,封装提示词的原因是需要将提示词写入到文本中
3 请求过程1 参数常量工具
新建常量类,公共参数集中封装
java
package com.donglin.report.constants;
public class AiConst {
// 1 平台的api-key
// bK=百炼平台的key
public static final String DASHSCOPE_API_KEY = "sk-3b4202468c534a1e8bab7063fcc34e94";
// 2 平台调用url
// burl = 百炼平台的Url
public static final String DASHSCOPE_API_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1";
// 3 模型名
public static final String DEEPSEEK_V3 = "deepseek-v3";
public static final String QWEN_PLUS = "qwen-plus";
}2 提示词文本读取工具
这里分为两步操作:
1 新建提示词文本
2 然后用工具类读取提示词1 在Resource下新建提示词文本 aiReportPrompt.txt
[角色设定] 您是我们电商平台的数据分析引擎
[任务目标] 解析用户自然语言查询并提取结构化字段:
- 地域(示例:北京、华东地区)
- 用户性别(示例:男性,女性)
- 商品品类(示例:电脑、服装)
- 时间范围(示例:2025/04/23以前、最近30天)
- 商品名称(示例:拯救者y700p、rog枪神4)
- 购买数量(示例:1、2)
- 品牌名称(示例:苹果apple、联想)
- 聚合内容(示例:人数、订单数,金额数)
- 分组条件(示例:各种品牌、各个城市,各个地区,不同性别,各种品类)
[输入示例]
"上海女性用户美妆品类最近三个月xx粉底液的最热门的各种品牌的信息"
[期望输出]
{
"provinceName":"上海",
"genderName":"女性",
"categoryKeyword":"美妆品类",
"createDate":2025/01/23,
"skuName":"xx粉底液",
"skuNum":3,
"tmName":"联想",
"countKeyword":"最热门的"
"groupKeyword":"各种品牌"
}
[输出规范]
1. 使用JSON格式输出
2. 未识别字段置为null
3. 如果用户未提及分组条件,默认以时间进行分组,将与时间有关的信息写入该字段,如果用户未提及时间默认为最近一周
4. 如果用户未提及聚合内容,最热门,销量最好等词语也可以做为聚合内容,如果全未提及,则默认为销售金额
5. 时间单位统一转换(周→7天、月→30天),时间直接计算好结果就行了,写"2025/04/16"这样的规范格式
6. 如果不符合任何条件所有字段置为null并返回json
7. 一定要返回json结果,且json结果有且只能有一个,不能出现一个以上的json字符串2 提示词工具类
java
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.util.FileCopyUtils;
import java.io.IOException;
import java.io.InputStreamReader;
import java.time.LocalDateTime;
// 提示词生成器核心类
public class PromptGenerator {
// 字符串提示词模板
public static final String PROMPT_TEMPLATE = "";// 简单的提示词可以直接字符串
// 文本提示词模板
public static String systemPrompt = "你是一个精通电商领域的助手,需要根据用户的要求准确回答问题。" + PromptGenerator.readPrompFile();// 系统提示词信息
public static String readPrompFile(){
try {
Resource resource = new ClassPathResource("aiReportPrompt.txt");
String content = FileCopyUtils.copyToString(new InputStreamReader(resource.getInputStream()));//此处读取提示词文本
return content;
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
public static String generatePrompot(String question) {
LocalDateTime now = LocalDateTime.now();
return PROMPT_TEMPLATE + "\n【当前问题】" + question + "\n【当前时间】" + now;
}
}3 接口调用工具
java
import com.donglin.report.aitool.MyAssistAgent;
import com.donglin.report.aitool.PromptGenerator;
import com.donglin.report.constants.AiConst;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
public class AiQuest {
// 初始化组件
private static ChatModel llmProc;// 通义模型
private static ChatModel llmSum;// deepseek模型
private MyAssistAgent agent;// 我们自己的被代理函数式接口
public AiQuest(){
// 初始化语言模型
this.llmProc = OpenAiChatModel.builder()
.apiKey(AiConst.DASHSCOPE_API_KEY)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") // SpzxAiConst.DASHSCOPE_API_BASE_URL;
.modelName("qwen-plus")// 通义千问
.build();
this.llmSum = OpenAiChatModel.builder()
.apiKey(AiConst.DASHSCOPE_API_KEY)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("deepseek-v3")// ds
.build();
// 初始化 chatAgent 代理
this.agent = AiServices.builder(MyAssistAgent.class)
.chatModel(llmProc)
.systemMessageProvider((ignored) -> PromptGenerator.systemPrompt)
.build();
}
/***
* 控制层调用过程
* @param question
* @return
* @throws Exception
*/
public String processQuestion(String question) {
System.out.println("1 原始问题:"+question);
//组合提示词模板
System.out.println("2 组合提示词模板=============================================");
String questionMerge = PromptGenerator.generatePrompot(question);
System.out.println(questionMerge);
// 通义千问
System.out.println("3 提问:通义千问===============================================");
String answer = agent.chat(questionMerge);
int jsonStart = answer.lastIndexOf("{");
int jsonEnd = answer.lastIndexOf("}");
System.out.println("4 回答:通义千问===============================================");
System.out.println(answer);
String jsonAnswer = answer.substring(jsonStart, jsonEnd+1);
return jsonAnswer;
}
}4 上面的三项封装完成后,调用测试你的封装工具就可以了
java
public static void main(String[] args) throws Exception {
SpzxAiQuest spzxAiQuest = new SpzxAiQuest();
String answer = spzxAiQuest.processQuestion("北京地区最畅销的各种电脑品牌是什么");
System.out.println("==========================================");
System.out.println(answer);
}测试结果
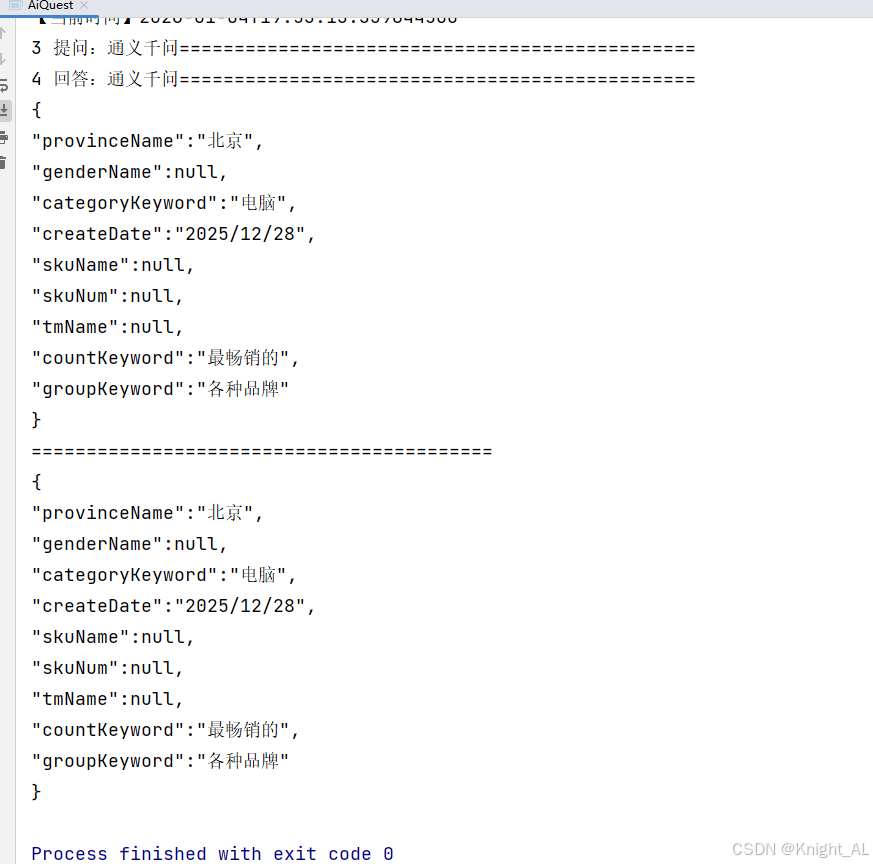
json
### 解析说明:
1. **provinceName**: 用户明确提到"北京地区"。
2. **genderName**: 未提及性别,置为`null`。
3. **categoryKeyword**: 用户明确提到"电脑"。
4. **createDate**: 默认最近一周时间范围,当前系统时间2025-05-09,因此计算出最近一周起始时间为2025-05-02
5. **skuName**: 未提及具体商品名称,置为`null`。
6. **skuNum**: 未提及购买数量,置为`null`。
7. **tmName**: 未提及具体品牌,置为`null`。
8. **countKeyword**: 用户提到"最畅销的",作为聚合内容。
9. **groupKeyword**: 用户明确提到"各种电脑品牌",分组条件为"各种品牌"。
==========================================
{
"provinceName": "北京",
"genderName": null,
"categoryKeyword": "电脑",
"createDate": "2025/05/02",
"skuName": null,
"skuNum": null,
"tmName": null,
"countKeyword": "最畅销的",
"groupKeyword": "各种品牌"
}解释说明
1 countKeyword,这个字段是统计字段,也就是mysql中报表语句用来聚合(count等)的字段,可以是订单数量,订单人数,订单总金额三个维度。
这里的"最畅销的"将来需要用向量数据库进行相似性匹配,对应成具体的统计字段order_id,user_id或者order_amount
2 groupKeyword,这个字段是分组字段,也就是mysql中报表语句用来进行group by的字段,可以是品牌,分类,地区,时间等。
这里的"各种品牌"将来需要用向量数据库进行相似性匹配,对应成具体的统计字段city_name,tm_name等。
3 其他字段,其他字段将来mysql进行条件判断where后面的具体内容5、ai报表接口(后续实现,缺少向量部分)
在SpzxReportController中增加接口方法"getAiReport/{question}",返回结果是HashMap,封装报表的x和y轴坐标数据,然后实现spzxReportService.getAiReport(question)业务层的部分代码
java
@RestController
public class ReportController {
@Autowired
private ReportService reportService;
@GetMapping("getAiReport/{question}")
public String getAiReport(@PathVariable String question) {
Map<String, Object> xyMap = new HashMap<>();
List<Object> xList = new ArrayList<>();
List<Object> yList = new ArrayList<>();
List<Map<String, Object>> reportMaps = reportService.getAiReport(question);
for (Map<String, Object> reportMap : reportMaps) {
String groups = reportMap.get("groupTag").toString();
Object count = reportMap.get("count");
xList.add(groups);
yList.add(count);
}
xyMap.put("xList", xList);
xyMap.put("yList", yList);
//转成json
HashMap<String, Object> map = new HashMap<>();
map.put("msg","操作成功");
map.put("code",200);
map.put("data",xyMap);
ObjectMapper objectMapper = new ObjectMapper();
String json;
try {
json = objectMapper.writeValueAsString(map);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
return json;
}
}在SpzxReportService业务层中增加接口方法"getAiReport(question)",返回结果是List<Map<String, Object>>,数据库报表统计查询结果
java
import com.alibaba.fastjson.JSON;
import com.donglin.report.aitool.AiQuest;
import com.donglin.report.domain.VOrderInfoJSONObject;
import com.donglin.report.service.ReportService;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
@Service
public class ReportServiceImpl implements ReportService {
@Override
public List<Map<String, Object>> getAiReport(String question) {
// ai过滤关键词
AiQuest aiQuest = new AiQuest();
String answerJson = aiQuest.processQuestion(question);
VOrderInfoJSONObject vOrderInfoJSONObject = JSON.parseObject(answerJson, VOrderInfoJSONObject.class);
// 向量数据库的业务内容匹配(将ai分解出的关键字换成系统统计报表相关字段)
return null;
}
}七、向量数据
1、向量数据和向量数据库的介绍
说一下向量数据在项目中的作用,以及如何准备向量数据库,这里使用pinecone数据库。
使用向量数据库的目的是将我们项目中的业务数据进行向量化的处理(数据向量化是通过调用人工智能模型去将文本解析为设定好的维度的向量),然后将处理好的向量数据存入向量数据库。
因为向量数据库中的数据都是以向量的形式进行存储的,所以无论是要将数据集存入向量数据库,还是要进行数据的相似度匹配,都要将数据进行向量化,才能展开与向量数据库相关的交换。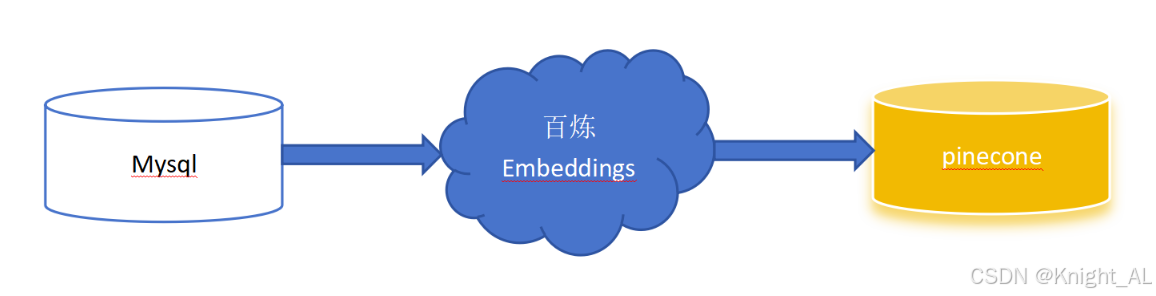
在这里我们只需要解决三个问题:
1 什么是embedding
2 如何选择embedding-model--向量模型
3 被向量化的数据如何存储--向量数据库
langchain4j官方技术文档:https://docs.langchain4j.dev/tutorials/rag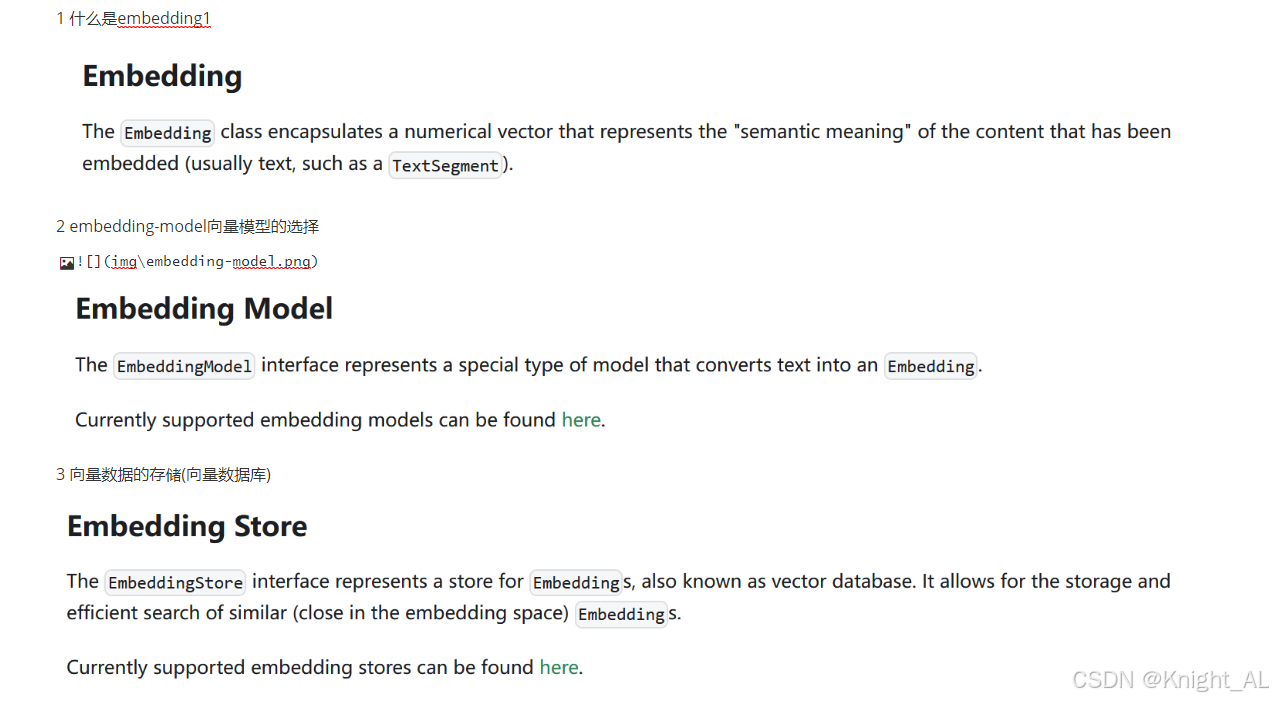
2 本系统业务数据的向量化
前面我们已经了解了向量化的概念,在这里,将向量化的技术引入我们的尚品甄选系统,我们要解决两个问题:
1 选择一个用来实现向量化的嵌入模型(百炼)
2 如何设计本系统的向量化数据1 选择嵌入模型(阿里百炼)
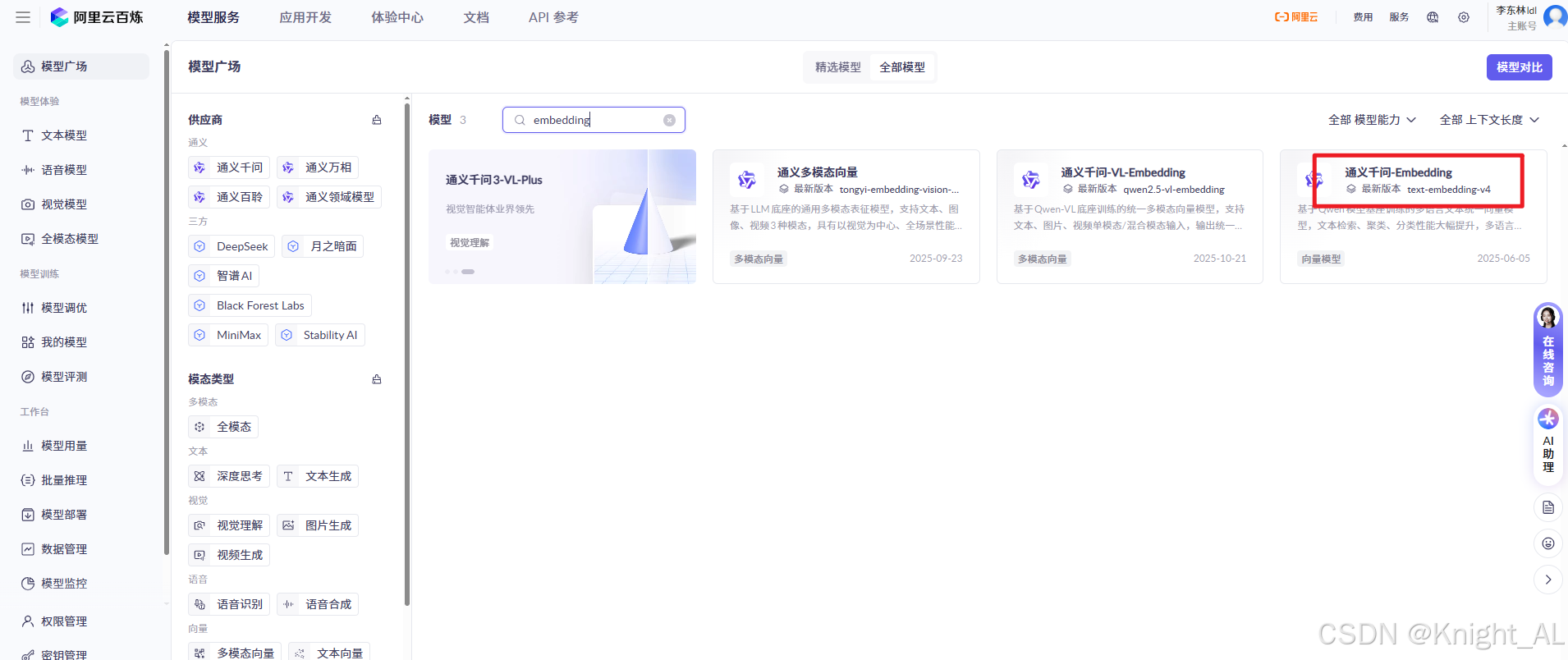
这里我们可以像之前调用llm模型一样,将调用的关键信息(三个重要参数)封装起来
java
public class EmbeddingConst {
// 通过阿里百炼ai对数据进行向量化处理
public static String ALI_API_KEY = "sk-3b4202468c534a1e8bab7063fcc34e94";
//public static String ALI_EMBEDDINGS_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings";// http
public static String ALI_EMBEDDINGS_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1";// sdk
public static String ALI_EMBEDDINGS_MODEL = "text-embedding-v2";
}langchain4j的嵌入模型调用工具
java
// 用langchain4j工具调用百炼平台的嵌入模型
public static void main(String[] args) {
EmbeddingModel embeddingModel = OpenAiEmbeddingModel
.builder()
.apiKey(EmbeddingConst.ALI_API_KEY)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("text-embedding-v2")
.build();
Response<Embedding> hello = embeddingModel.embed("你好");
System.out.println(hello);
}输出结果

调用工具封装
java
import com.donglin.report.constants.EmbeddingConst;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.model.output.Response;
public class EmbeddingTools {
public static Embedding getEmbedding(String text) {
EmbeddingModel embeddingModel = OpenAiEmbeddingModel
.builder()
.apiKey(EmbeddingConst.ALI_API_KEY)
.baseUrl(EmbeddingConst.ALI_EMBEDDINGS_BASE_URL)// https://dashscope.aliyuncs.com/compatible-mode/v1
.modelName(EmbeddingConst.ALI_EMBEDDINGS_MODEL) // text-embedding-v2
.build();
Response<Embedding> hello = embeddingModel.embed(text);
Embedding content = hello.content();
return content;
}
}2 如何设计本系统的向量化数据
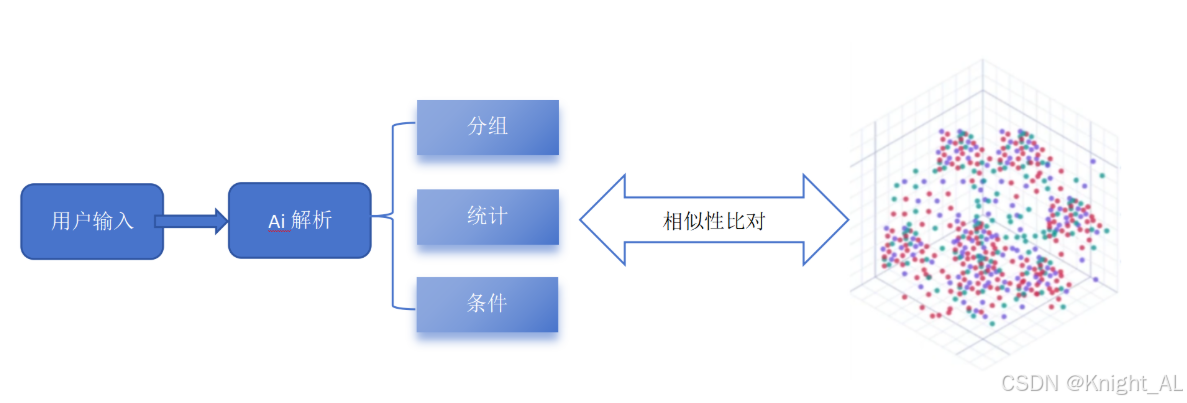
1 分组匹配数据
分组(自建vector_group_key): 品牌tm_name,商品sku_name,分类category1_name,性别gender,地区province_name
2 统计匹配数据
聚合(自建vector_count_key): 订单数量,用户人数,订单总金额
3 条件匹配数据
条件(自建vector_select_key): 品牌tm_name,商品sku_name,分类category1_name,地区province_name八、本系统知识库导入向量数据库(pinecone)
解决了数据向量化的问题,这里再来解决向量化数据如何保存到向量数据库中,这里选择pinecone数据库:
1 如何使用pinecone数据库
2 如何将系统业务数据导入pinecone数据库1、如何使用pinecone数据库
A、引入依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
<version>1.0.0-beta4</version>
</dependency>B、声明公共参数
java
public class PineconeConst {
// pinecone-key
public static final String PK1 = "pcsk_3nuSwS_C1yD1z1rLwZrwsg4KZzwapGtPF68EvHr6EPRYnEGpVtiici5it7X6RKfFJJRJ3R";
}C、langchain4j方法调用
这里的工具用main方法就可以调用,创建main方法,然后代码如下:
java
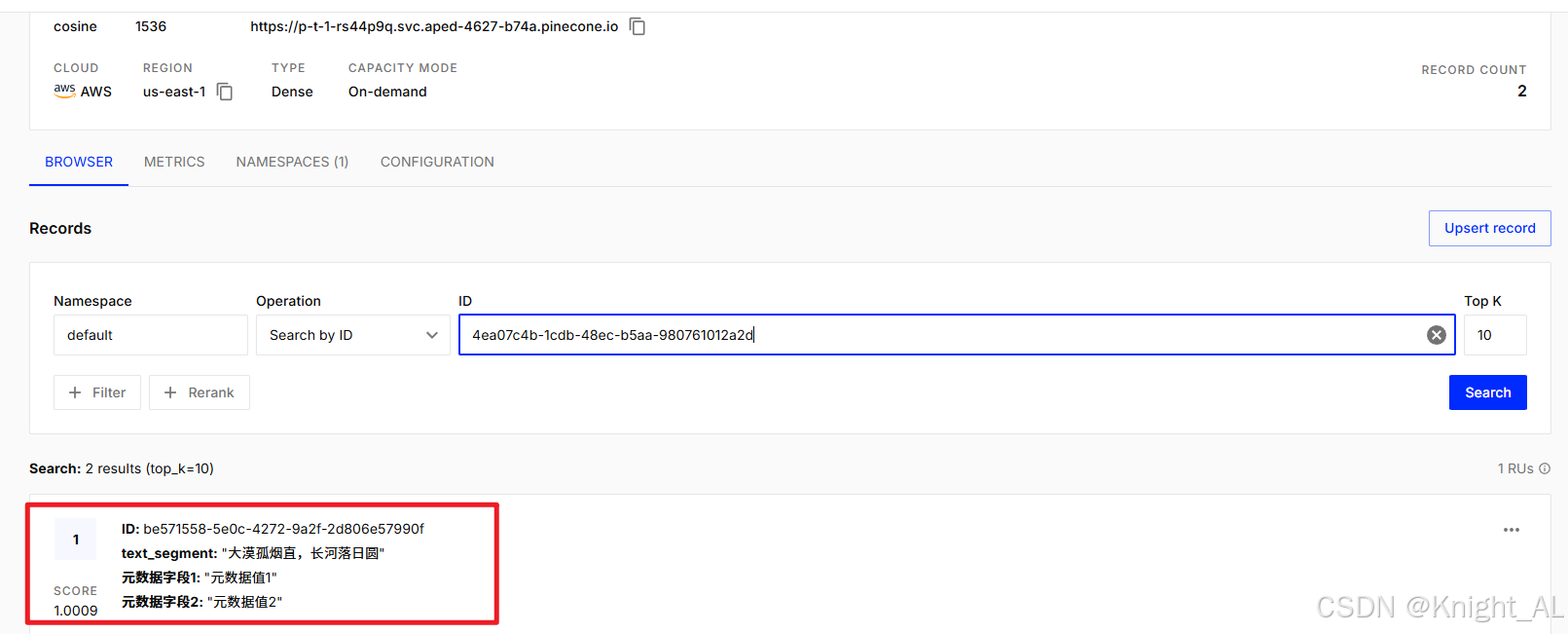
public static void main(String[] args) {
// 原始数据
String text = "大漠孤烟直,长河落日圆";
// 1 创建向量存储
EmbeddingStore embeddingStore = PineconeEmbeddingStore.builder()
.apiKey(PineconeConst.PK1)// pinecone的key
.index("p-t-1")//如果指定的索引不存在,将创建一个新的索引
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS") //指定索引部署在 AWS 云服务上。
.region("us-east-1") //指定索引所在的 AWS 区域为 us-east-1。
.dimension(1536) //指定索引的向量维度,该维度与 embeddedModel 生成的向量维度相同。
.build())
.build();
// 2 存入向量数据
// 向量数据
Embedding embedding = EmbeddingTools.getEmbedding(text);
// 构建元数据
TextSegment meta = TextSegment.from(text,
Metadata.metadata("元数据字段1", "元数据值1").put("元数据字段2","元数据值2")
);
// 存入
embeddingStore.add(embedding,meta);
}
D、http请求调用(新建工具类PineconeUploadUtil)
相关api文档出处:https://docs.pinecone.io/reference/api/introduction
java
package com.donglin.report.aitool;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class PineconeUploadUtil {
static ObjectMapper OBJECT_MAPPER = new ObjectMapper();
/***
* 通过集合上传,前期数据处理
* @param list
*/
public static void uploadListToPinecone(List<Map<String, Object>> list, String pineconeIndexKey, String pineconeKey) {
List<Map<String, Object>> batch = new ArrayList<>();// 分批
int lineNum = 0; // 记录行号
int successCount = 0; // 成功上传的数量
int failedCount = 0; // 失败的数量
for (Map<String, Object> map : list) {
String cleanText = map.get("key_word").toString().trim();
// 生成文本向量
float[] vector = EmbeddingTools.getEmbedding(cleanText).vector();
if (vector.length == 0) {
System.err.println(" 向量化失败,跳过行 " + lineNum + ": " + cleanText);
failedCount++;
continue;
}
// 构造 Pinecone 记录
Map<String, Object> vectorEntry = new HashMap<>();
vectorEntry.put("id", "no_" + lineNum);
vectorEntry.put("values", vector);
// 添加 metadata
Map<String, String> metadata = new HashMap<>();
metadata.put("column", map.get("key_column").toString().trim());
metadata.put("word", map.get("key_word").toString().trim());
vectorEntry.put("metadata", metadata);
batch.add(vectorEntry);
// System.out.println(batch);
lineNum++;
// 批量上传
if (batch.size() >= 50) {// 批处理,每次上传50条
upsertToPinecone(batch,pineconeIndexKey,pineconeKey);
successCount += batch.size();
batch.clear();
}
}
// 处理剩余数据
if (!batch.isEmpty()) {
upsertToPinecone(batch,pineconeIndexKey,pineconeKey);
successCount += batch.size();
}
System.out.println("上传完成,共处理 " + lineNum + " 行");
System.out.println("成功上传:" + successCount);
System.out.println("失败上传:" + failedCount);
}
// 将数据上传至向量库
private static void upsertToPinecone(List<Map<String, Object>> vectors,String pineconeIndexKey,String pineconeKey) {
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpPost httpPost = new HttpPost(pineconeIndexKey);
httpPost.setHeader("Content-Type", "application/json");
httpPost.setHeader("Api-Key", pineconeKey);
// 构造 JSON 请求
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("vectors", vectors);
requestBody.put("namespace","default");
String jsonBody = OBJECT_MAPPER.writeValueAsString(requestBody);
// 设置 UTF-8 编码
//请注意!!!这里务必进行编码的设置,否则其默认不会将jsonBody中的中文数据成功发送,会乱码
httpPost.setEntity(new StringEntity(jsonBody, StandardCharsets.UTF_8));
// 发送请求
try (CloseableHttpResponse response = httpClient.execute(httpPost)) {
String responseString = EntityUtils.toString(response.getEntity());
System.out.println("Pinecone upsert response: " + responseString);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}2、如何将系统业务数据导入pinecone数据库
1、首先,前面我们已经了解如何使用pinecone向量数据库了,接下来,分别在pinecone中新建三个向量数据库:用来存储分组(vector_group_key),统计(vector_count_key),条件(vector_select_key)的向量化业务数据
2、然后,我们将业务数据导入上面创建的三个向量库中,简单来说就是分为两步,1 查询需要向量化的数据,2 存入pinecone。
java
package com.donglin.report.constants;
public class PineconeConst {
//pinecone-key
public static final String PK1 = "pcsk_2jm5jC_QvnLj2EsRUPbaP8yww2VMSdvfW4RrBpJHi1yA5bJ4qVNKEoK4aNwcRU3RfB3U3Q";
// pinecone-db group-key 上传upsert
public static final String PGK_INDEX_UPSERT_URL = "https://sky-report-group-key-1-rs44p9q.svc.aped-4627-b74a.pinecone.io/vectors/upsert";
// pinecone-db count-key 上传upsert
public static final String PCK_INDEX_UPSERT_URL = "https://sky-report-count-key-1-rs44p9q.svc.aped-4627-b74a.pinecone.io/vectors/upsert";
// pinecone-db select-key 上传upsert
public static final String PSK_INDEX_UPSERT_URL = "https://sky-report-select-key-1-rs44p9q.svc.aped-4627-b74a.pinecone.io/vectors/upsert";
// pinecone-db group-key 查询query
public static final String PGK_INDEX_QUERY_URL = "https://sky-report-group-key-1-rs44p9q.svc.aped-4627-b74a.pinecone.io/query";
// pinecone-db count-key 查询query
public static final String PCK_INDEX_QUERY_URL = "https://sky-report-count-key-1-rs44p9q.svc.aped-4627-b74a.pinecone.io/query";
// pinecone-db select-key 查询query
public static final String PSK_INDEX_QUERY_URL = "https://sky-report-select-key-1-rs44p9q.svc.aped-4627-b74a.pinecone.io/query";
public static final String PGK_INDEX_GROUP_KEY_1 = "sky-report-group-key-1";
public static final String PCK_INDEX_COUNT_KEY_1 = "sky-report-count-key-1";
public static final String PSK_INDEX_SELECT_KEY_1 = "sky-report-select-key-1";
}
java
public interface EmbeddingService {
public void embeddingGroupKeyToPinecone();
public void embeddingCountKeyToPinecone();
public void embeddingSelectKeyToPinecone();
}
@Service
public class EmbeddingServiceImpl implements EmbeddingService {
@Autowired
VectorCountKeyMapper vectorCountKeyMapper;
@Autowired
VectorSelectKeyMapper vectorSelectKeyMapper;
@Autowired
VectorGroupKeyMapper vectorGroupKeyMapper;
@Override
public void embeddingGroupKeyToPinecone() {
// 1 查询需要向量化的输入
List<Map<String, Object>> list = vectorGroupKeyMapper.selectMaps(null);
// 2 存入pinecone
PineconeUploadUtil.uploadListToPinecone(list, PineconeConst.PGK_INDEX_UPSERT_URL, PineconeConst.PK1);
}
@Override
public void embeddingCountKeyToPinecone() {
// 1 查询需要向量化的输入
List<Map<String, Object>> list = vectorCountKeyMapper.selectMaps(null);
// 2 存入pinecone
PineconeUploadUtil.uploadListToPinecone(list, PineconeConst.PCK_INDEX_UPSERT_URL, PineconeConst.PK1);
}
@Override
public void embeddingSelectKeyToPinecone() {
// 1 查询需要向量化的输入
List<Map<String, Object>> list = vectorSelectKeyMapper.selectMaps(null);
// 2 存入pinecone
PineconeUploadUtil.uploadListToPinecone(list, PineconeConst.PSK_INDEX_UPSERT_URL, PineconeConst.PK1);
}
}3、最后,在junit单元测试中调用上面的业务层代码将数据向量化并存入向量库
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
java
@SpringBootTest
public class ImportDbReportToPinecone {
@Autowired
SpzxEmbeddingService spzxEmbeddingService;
@Test
public void testStore() {
spzxEmbeddingService.embeddingGroupKeyToPinecone();
spzxEmbeddingService.embeddingCountKeyToPinecone();
spzxEmbeddingService.embeddingSelectKeyToPinecone();
}
}3、向量数据的关联查询
1 接收请求获取问题,将问题转换为向量,在 Pinecone 向量数据库中进行相似度搜索,找到最相似的文本片段,并将其文本内容返回给客户端。
java
public static void main(String[] args) {
//创建向量存储
EmbeddingStore embeddingStore = PineconeEmbeddingStore.builder()
.apiKey(PineconeConst.PK1)// pinecone的key
.index(PineconeConst.PCK_INDEX_COUNT_KEY_1)//如果指定的索引不存在,将创建一个新的索引
.metadataTextKey("column")
.metadataTextKey("word")
.nameSpace("default")
.build();
// 先将要拿来匹配的文本向量化
Embedding queryEmbedding = SpzxEmbeddingTools.getEmbedding("最畅销的");
//创建搜索请求对象
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1) //匹配最相似的一条记录
//.minScore(0.8)
.build();
//根据搜索请求 searchRequest 在向量存储中进行相似度搜索
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(searchRequest);
//searchResult.matches():获取搜索结果中的匹配项列表。
//.get(0):从匹配项列表中获取第一个匹配项
EmbeddingMatch<TextSegment> embeddingMatch = searchResult.matches().get(0);
//获取匹配项
System.out.println(embeddingMatch);
}2 将其最做成工具PineconeSimilaryUtil,工具返回结果是HashMap,方便后面生成统计报表sql的时候取出对应值
java
import com.donglin.report.constants.PineconeConst;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class PineconeSimilaryUtil {
public static Map<String, String> getPineconeSimilarityEmbeddings(String question, String pname) {
//创建向量存储
EmbeddingStore embeddingStore = PineconeEmbeddingStore.builder()
.apiKey(PineconeConst.PK1)// pinecone的key
.index(pname)//如果指定的索引不存在,将创建一个新的索引
.metadataTextKey("column")
.metadataTextKey("word")
.nameSpace("default")
.build();
// 先将要拿来匹配的文本向量化
Embedding queryEmbedding = EmbeddingTools.getEmbedding(question);
//创建搜索请求对象
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1) //匹配最相似的一条记录
.minScore(0.6)
.build();
//根据搜索请求 searchRequest 在向量存储中进行相似度搜索
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(searchRequest);
System.out.println(searchResult);
//searchResult.matches():获取搜索结果中的匹配项列表。
//.get(0):从匹配项列表中获取第一个匹配项
List<EmbeddingMatch<TextSegment>> matches = searchResult.matches();
if(matches.size()>0){
EmbeddingMatch<TextSegment> embeddingMatch = searchResult.matches().get(0);
//获取匹配项
String column = embeddingMatch.embedded().metadata().getString("column");
String word = embeddingMatch.embedded().metadata().getString("word");
// 返回结果
Map<String,String> resultMap = new HashMap<>();
resultMap.put("column",column);
resultMap.put("word",word);
return resultMap;
}else {
// 返回结果
Map<String,String> resultMap = new HashMap<>();
resultMap.put("column","");
resultMap.put("word","");
return resultMap;
}
}
}九、ai报表接口的完成(实现)
java
public static final String PGK_INDEX_GROUP_KEY_1 = "sky-report-group-key-1";
public static final String PCK_INDEX_COUNT_KEY_1 = "sky-report-count-key-1";
public static final String PSK_INDEX_SELECT_KEY_1 = "sky-report-select-key-1";
java
package com.donglin.report.controller;
import com.alibaba.fastjson.JSON;
import com.donglin.report.domain.ReportResult;
import com.donglin.report.service.ReportService;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@RestController
public class ReportController {
@Autowired
private ReportService reportService;
@GetMapping("getAiReport/{question}")
public String getAiReport(@PathVariable("question") String question) {
Map<String, Object> xyMap = new HashMap<>();
List<Object> xList = new ArrayList<>();
List<Object> yList = new ArrayList<>();
List<ReportResult> reportMaps = reportService.getAiReport(question);
for (ReportResult reportMap : reportMaps) {
Object groups = reportMap.getGroupTag();
Object count = reportMap.getCount();
xList.add(groups);
yList.add(count);
}
xyMap.put("xList", xList);
xyMap.put("yList", yList);
//转成json
HashMap<String, Object> map = new HashMap<>();
map.put("msg","操作成功");
map.put("code",200);
map.put("data",xyMap);
ObjectMapper objectMapper = new ObjectMapper();
String json;
try {
json = objectMapper.writeValueAsString(map);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
return json;
}
}
java
package com.donglin.report.service;
import com.donglin.report.domain.ReportResult;
import java.util.List;
import java.util.Map;
public interface ReportService {
List<ReportResult> getAiReport(String question);
}
java
package com.donglin.report.service.impl;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.donglin.report.aitool.AiQuest;
import com.donglin.report.aitool.PineconeSimilaryUtil;
import com.donglin.report.constants.PineconeConst;
import com.donglin.report.domain.ReportResult;
import com.donglin.report.domain.VOrderInfoJSONObject;
import com.donglin.report.mapper.VOrderInfoMapper;
import com.donglin.report.service.ReportService;
import org.checkerframework.checker.units.qual.A;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import java.util.List;
import java.util.Map;
import java.util.Set;
@Service
public class ReportServiceImpl implements ReportService {
private static final Set<String> GROUP_WHITE_LIST = Set.of(
"create_date", "province_name", "tm_name"
);
private static final Set<String> COUNT_WHITE_LIST = Set.of(
"order_id", "user_id", "order_amount"
);
@Autowired
private VOrderInfoMapper vOrderInfoMapper;
@Override
public List<ReportResult> getAiReport(String question) {
// ai过滤关键词
AiQuest aiQuest = new AiQuest();
String answerJson = aiQuest.processQuestion(question);
VOrderInfoJSONObject vOrderInfoJSONObject = JSON.parseObject(answerJson, VOrderInfoJSONObject.class);
// 向量数据库的业务内容匹配(将ai分解出的关键字换成系统统计报表相关字段)
//用向量数据库匹配相似工具,匹配ai过滤关键字,获取元数据(column和word),作为后期拼接报表sql的具体字段和条件数据
VOrderInfoJSONObject vectorData = getVectorData(vOrderInfoJSONObject);
// 3. (关键)字段白名单校验,防 SQL 注入
checkParam(vectorData);
// 4. 直接调用 XML SQL
List<ReportResult> reportList =
vOrderInfoMapper.selectMyReport(vectorData);
// 5. 如果前端必须要 Map(可选)
return reportList;
}
private QueryWrapper getMyReportWrapper(QueryWrapper queryWrapper, VOrderInfoJSONObject vectorData) {
return null;
}
private VOrderInfoJSONObject getVectorData(VOrderInfoJSONObject vOrderInfoJSONObject) {
// 1 分组和聚合关键字处理
// 此处通过向量数据库,关联用户的信息和本系统的数据字段
String countKeyword = vOrderInfoJSONObject.getCountKeyword();
String groupKeyword = vOrderInfoJSONObject.getGroupKeyword();
String countKeyWordSimilarityEmbeddings = PineconeSimilaryUtil.getPineconeSimilarityEmbeddings(countKeyword, PineconeConst.PCK_INDEX_COUNT_KEY_1).get("column");
String groupKeyWordSimilarityEmbeddings = PineconeSimilaryUtil.getPineconeSimilarityEmbeddings(groupKeyword, PineconeConst.PGK_INDEX_GROUP_KEY_1).get("column");
// 处理向量相似匹配结果
// 将向量比对后的结果更新到json对象中
// 如果用户没有提及与分组相关信息,则默认以最近一周的时间作为分组
if (StringUtils.isEmpty(countKeyWordSimilarityEmbeddings)){
countKeyWordSimilarityEmbeddings = "order_id";
}
if (StringUtils.isEmpty(groupKeyWordSimilarityEmbeddings)){
groupKeyWordSimilarityEmbeddings = "create_date";
}
vOrderInfoJSONObject.setCountKeyword(countKeyWordSimilarityEmbeddings.trim());
vOrderInfoJSONObject.setGroupKeyword(groupKeyWordSimilarityEmbeddings.trim());
// 2 条件过滤关键字处理,用户的分类关键字,因为系统分类有三级,所以这里需要确定使用哪一个分类,这里默认任何级别都可以,看具体需求
String provinceName = vOrderInfoJSONObject.getProvinceName();
String tmName = vOrderInfoJSONObject.getTmName();
String skuName = vOrderInfoJSONObject.getSkuName();
// 分类可能匹配多个,这部分代实际工作中,可以以后单独处理,现在为了实现功能,暂且不用加入(伪代码)
// if(StringUtils.hasText(categoryKeyword)){
// List<Map<String, String>> categoryListMap = PineconeSimilaryUtil.getCategoryPineconeSimilarityEmbeddings(categoryKeyword, PineconeConst.PSK_INDEX_SELECT_KEY_1);
// vOrderInfoJSONObject.setCategory3ListMap(categoryListMap);// 分类条件关键字
// }
if(StringUtils.hasText(provinceName)){
String provinceNameEmbeddings = PineconeSimilaryUtil.getPineconeSimilarityEmbeddings(provinceName, PineconeConst.PSK_INDEX_SELECT_KEY_1).get("word");
vOrderInfoJSONObject.setProvinceName(provinceNameEmbeddings.trim());// 地区条件关键字
}
if(StringUtils.hasText(tmName)){
String tmNameEmbeddings =PineconeSimilaryUtil.getPineconeSimilarityEmbeddings(tmName,PineconeConst.PSK_INDEX_SELECT_KEY_1).get("word");
vOrderInfoJSONObject.setTmName(tmNameEmbeddings.trim());// 商标条件关键字
}
if(StringUtils.hasText(skuName)){
String skuNameEmbeddings = PineconeSimilaryUtil.getPineconeSimilarityEmbeddings(skuName,PineconeConst.PSK_INDEX_SELECT_KEY_1).get("word");
vOrderInfoJSONObject.setSkuName(skuNameEmbeddings.trim());// 商品条件关键字
}
return vOrderInfoJSONObject;
}
private void checkParam(VOrderInfoJSONObject param) {
if (!GROUP_WHITE_LIST.contains(param.getGroupKeyword())) {
throw new IllegalArgumentException("非法分组字段");
}
if (!COUNT_WHITE_LIST.contains(param.getCountKeyword())) {
throw new IllegalArgumentException("非法统计字段");
}
}
}