
当 AI 从「聊天」走向「干活」,搜索这件事,也得换一套玩法了。
一、先讲一个真实痛点
你让 AI Agent 帮你做调研:
「查一下某公司的融资历史、用户口碑和真实产品短板,要有来源、有置信度。」
或者:
「找过去一个月发表强化学习论文、且和医学交叉的研究者。」
这类任务,已经不是传统「搜网页」能搞定的了。
但大多数 Agent 今天还是这么干的:调用通用搜索引擎 → 扫一堆 SEO 堆砌的网页 → 自己从噪声里抠信息 → 再推理、再执行。
问题出在哪?
- 搜索结果里广告和 SEO 噪声太多
- 很多高价值数据根本不在公网,而在金融终端、学术平台、代码仓库、行业数据库里
- 返回的是给人看的网页,不是给 Agent 直接拿来执行的结构化信息
- 信息来源、时效、可信度难以追溯
模型再聪明,信息层不可靠,决策就不可靠。
AnySearch 要解决的,正是这个问题:为 AI Agent 提供一套新的搜索基础设施。
二、AnySearch 到底是什么?
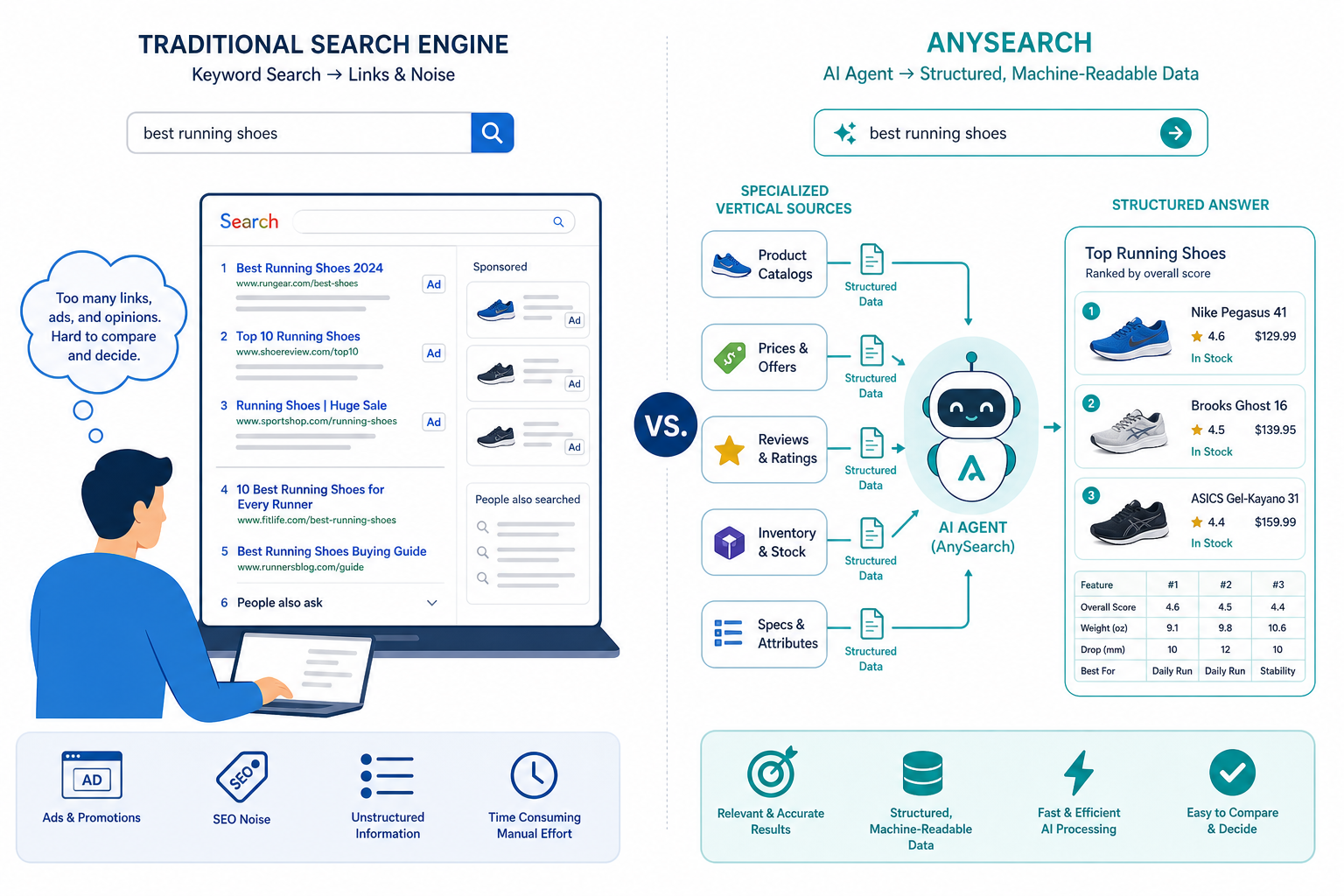
AnySearch 是一款面向 AI Agent 和企业 AI 系统的下一代搜索基础设施,2026 年 5 月正式发布。
它和传统搜索引擎、普通 AI 搜索产品的根本区别:
| 维度 | 传统搜索 | AnySearch |
|---|---|---|
| 服务对象 | 人类用户 | AI Agent |
| 核心目标 | 帮你找到网页 | 给 Agent 提供可执行的结构化信息 |
| 数据来源 | 主要是公网网页 | 公网 + 大量垂直领域专业数据源 |
| 接入方式 | 浏览器 / 网页 | API 优先,原生支持 Skill、MCP、API |
| 商业模式 | 广告驱动 | 无广告,API-first |
| 返回结果 | 链接列表 | 准确、简洁、可直接用于下一步执行 |
一句话概括:
AnySearch 不是「又一个 AI 搜索产品」,而是 AI 时代的信息基础设施。
三、为什么 Agent 需要「垂直搜索」而不只是「搜网页」?

AnySearch 团队有一个核心判断:
对 AI Agent 最有价值的信息,大量并不在公网上。
这些数据分散在:
- 实时金融终端
- 法律数据库
- 学术平台
- 代码仓库
- 网络安全情报
- 能源行业数据
- 企业情报系统
- 各类结构化 API 服务
如果每个 Agent 开发者自己去对接几十套数据源,成本极高、维护极难。
AnySearch 的做法是:把这些垂直数据源聚合起来,通过统一 API 对外提供服务。
目前已覆盖的垂直领域包括(持续扩展中):
- finance --- 金融
- legal --- 法律
- academic --- 学术
- security --- 网络安全
- code --- 代码
- social_media --- 社交媒体公开发现
- 以及 energy、corporate intelligence 等
Agent 不需要知道背后接了多少数据源,一次调用,智能路由到最相关的专业数据源,返回结构化、可执行的结果。
四、四大核心能力
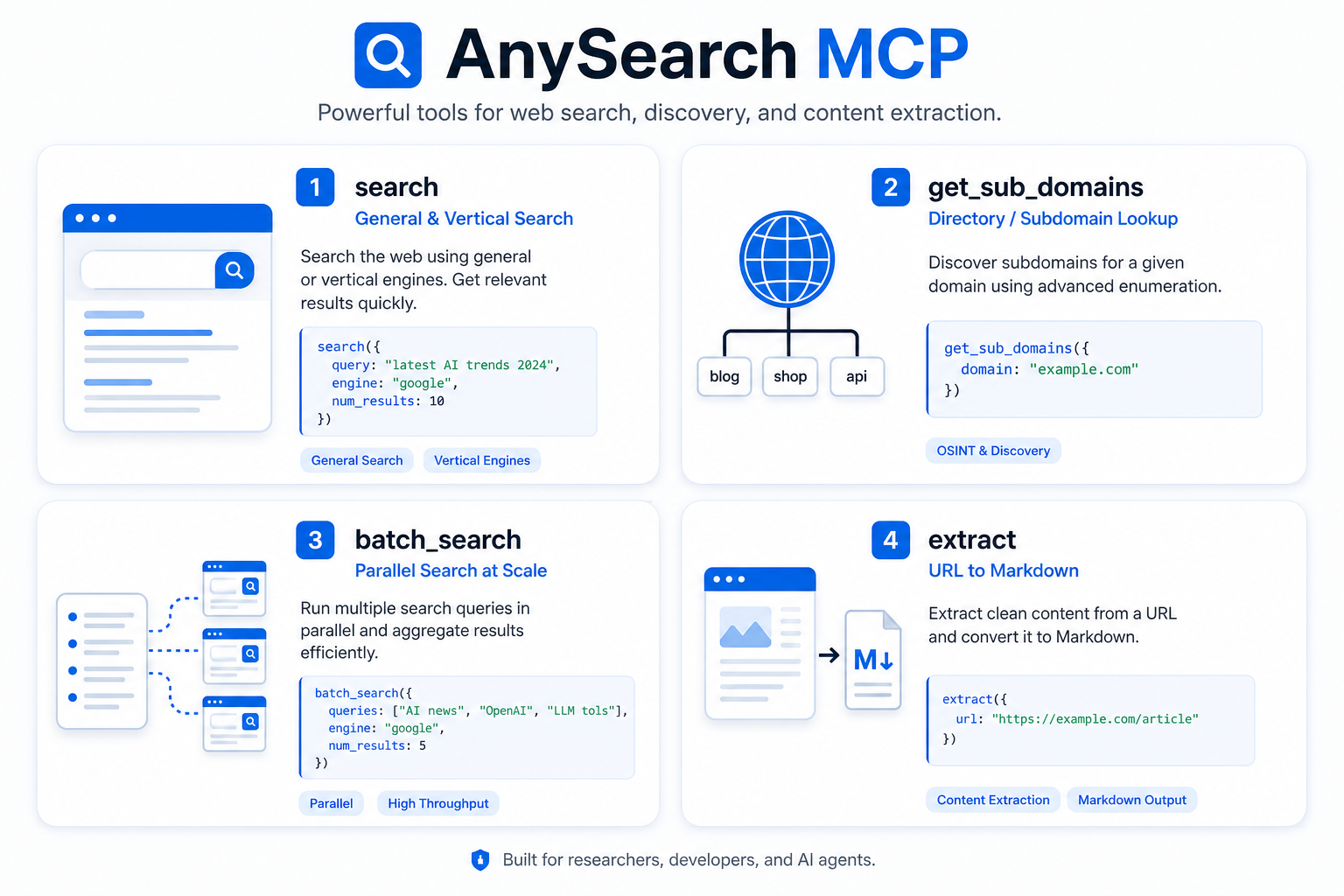
1. 通用网页搜索(General Web Search)
支持开放式自然语言查询,适合日常信息检索。
python
search(query="2026年大模型Agent发展趋势", max_results=10)2. 垂直领域搜索(Vertical Domain Search)
针对金融、学术、安全、法律、代码等专业场景,返回更精准的结构化结果。
重要规则 :使用垂直搜索前,必须先调用 get_sub_domains 查询可用的子领域和参数 schema,不能自己编造 domain 或参数。
python
# 第一步:查目录
get_sub_domains(domains=["finance", "academic"])
# 第二步:按返回的 sub_domain 和 params 搜索
search(
query="特斯拉最新财报分析",
domain="finance",
sub_domain="finance.us_stock",
sub_domain_params={...},
max_results=10
)3. 并行批量搜索(Batch Search)
一次调用执行 1~5 个独立查询,单个失败不阻塞其他。
python
batch_search(queries=[
{"query": "OpenAI 最新产品动态", "max_results": 5},
{"query": "Anthropic Claude 4 发布信息", "max_results": 5},
{"query": "Google Gemini Agent 能力", "max_results": 5}
])适合 Agent 需要同时从多个角度搜集信息的场景。
4. 网页内容提取(Extract)
给定 URL,抓取完整页面内容并返回 Markdown 格式(最长 50,000 字符)。
python
extract(url="https://example.com/article")Agent 搜到链接后,可以直接提取正文,无需自己写爬虫。
五、三种接入方式:Skill / MCP / API
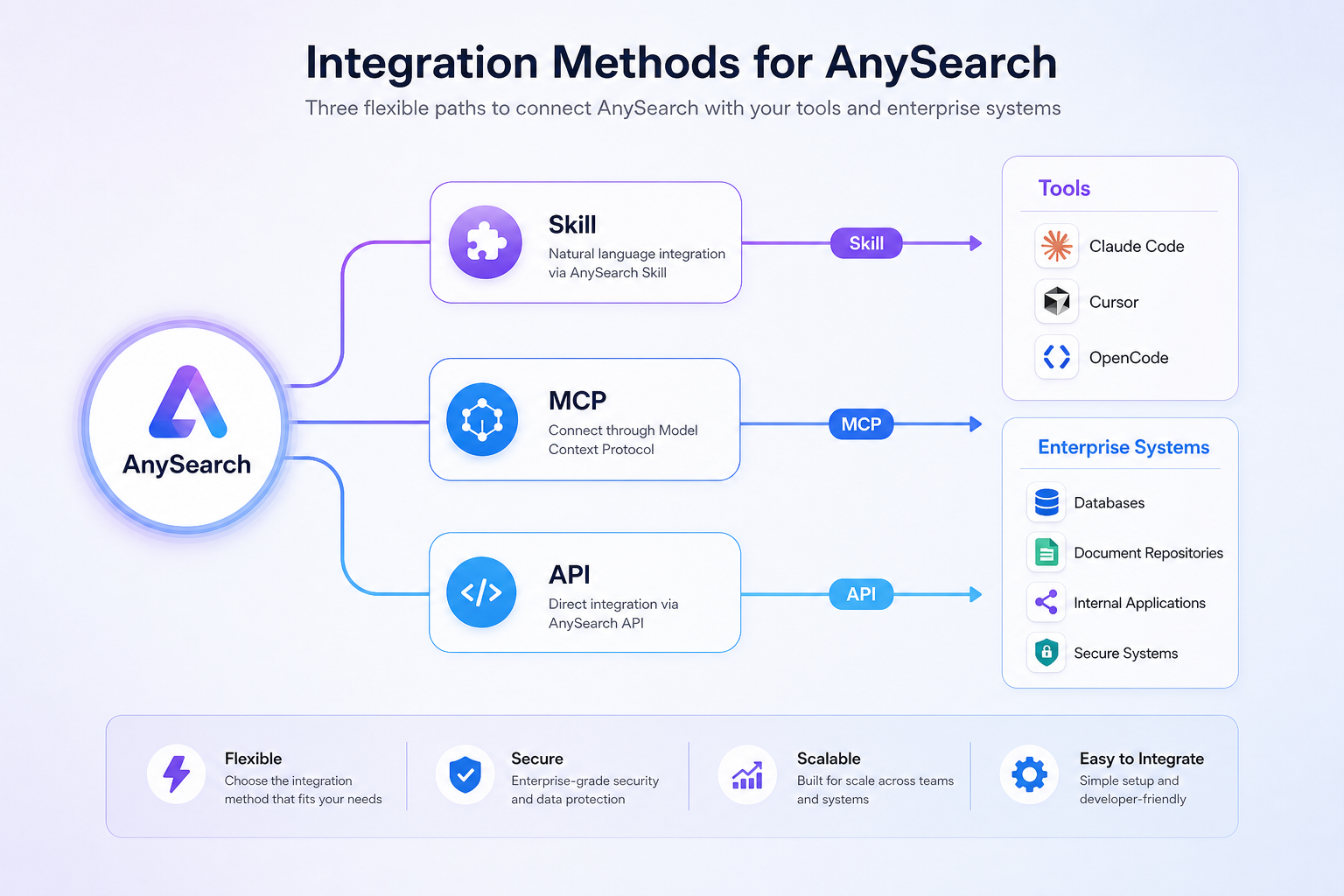
AnySearch 原生支持三种集成路径,覆盖主流 AI 开发工具链。
方式一:Skill(SKILL.md)
适合 Claude Code、Cursor、OpenCode、OpenClaw 等支持 Skill 目录的 Agent 平台。
GitHub 开源项目:anysearch-ai/anysearch-skill(3800+ Stars)
安装步骤:
bash
# 下载 release 包
curl -L -o anysearch-skill.zip \
https://github.com/anysearch-ai/anysearch-skill/archive/refs/tags/v2.1.0.zip
# 解压并放到 Agent 的 skill 目录
unzip anysearch-skill.zip
mv anysearch-skill-2.1.0 ~/.agents/skills/anysearch各平台 skill 目录:
| 平台 | 路径 |
|---|---|
| Claude Code | ~/.claude/skills/anysearch |
| OpenCode | ~/.config/opencode/skills/anysearch |
| Cursor / Windsurf | <project>/.skills/anysearch |
| 通用共享目录 | ~/.agents/skills/anysearch |
方式二:MCP Server
适合 Cursor、Claude Desktop、VS Code Copilot、Windsurf 等支持 MCP 的工具。
GitHub 开源项目:anysearch-ai/anysearch-mcp-server(1400+ Stars)
Cursor 配置示例(通过 SSE 代理):
json
{
"mcpServers": {
"anysearch": {
"type": "sse",
"url": "http://localhost:8000/sse"
}
}
}OpenCode / Claude Desktop(2025.6+) 可直接用 Streamable HTTP,无需代理:
json
{
"mcp": {
"anysearch": {
"type": "remote",
"url": "https://api.anysearch.com/mcp",
"headers": {
"Authorization": "Bearer ${ANYSEARCH_API_KEY}"
}
}
}
}方式三:直接 API 调用
适合自建 Agent 系统或企业工作流,直接对接 REST API。
六、开发者最关心的:怎么开始用?
免费额度
- 注册即可使用
- 当前提供 每天 1000 次免费 API 调用
- 支持匿名访问(无需 API Key,但速率限制更低)
API Key 配置
API Key 可选但强烈建议配置,优先级如下:
- CLI 参数
--api_key .env文件- 环境变量
ANYSEARCH_API_KEY - 匿名访问(最低配额)
获取 Key:https://anysearch.com/console/api-keys
bash
# Linux / macOS
export ANYSEARCH_API_KEY=your_key_here
# Windows PowerShell
$env:ANYSEARCH_API_KEY="your_key_here"安装验证
bash
# 检测 Python 环境
python3 --version
# 运行入口测试
python3 <skill_dir>/scripts/anysearch_cli.py doc
# 试一次真实搜索
python3 <skill_dir>/scripts/anysearch_cli.py search "hello world" --max_results 1返回 JSON 即表示连接成功。
七、AnySearch 在 Agent 工作流里扮演什么角色?
这里有一个容易混淆的点,必须说清楚:
AnySearch 不是 Coding Agent,它是 Agent 可以调用的「搜索能力层」。
它不写代码、不做任务规划、不审 diff。
它只做一件事:帮你找到可靠的信息。
在完整 Agent 工作流中的位置:
用户任务
│
▼
Agent(Claude Code / Cursor / 自研 Agent)
│
├── 推理 & 规划
├── 调用 AnySearch 检索信息 ← 信息层
├── 调用其他工具(代码、数据库、API)
└── 输出结果开发者的角色变化:
- 以前:自己搜 → 自己读 → 复制粘贴给 Agent
- 现在:配置好搜索层 → Agent 自动检索 → 开发者审核结果再行动
八、典型应用场景
1. 研究与情报分析
Agent 并行搜索多个信息源,汇总行业动态、竞品分析、学术进展。
2. 软件开发
在 Cursor / Claude Code 中,Agent 自动检索最新文档、GitHub Issue、API 变更,不再依赖开发者手动贴链接。
3. 安全审计
调用 security 垂直领域,检索漏洞情报、威胁分析、安全公告。
4. 金融与商业决策
通过 finance 领域获取实时市场数据、财报信息,支持 Agent 做结构化分析。
5. 内容工厂
batch_search 并行搜集素材,extract 提取长文正文,Agent 专注创作和审核。
6. 社交媒体监测
通过 social_media 领域做公开社交发现;如需账号级 X/Twitter 数据,可配合 TweetClaw 等专用工具。
九、AnySearch vs 传统 AI 搜索:关键差异
根据官方在 Frames、FreshQA、WebWalkerQA 等基准测试中的内部评估,AnySearch 在答案准确率和执行效率上优于以公网内容为主的 AI 搜索产品。
核心差异不在「谁更会聊天」,而在:
| 能力 | 说明 |
|---|---|
| 智能路由 | 自动把查询路由到最相关的专业数据源 |
| 结构化输出 | 返回 Agent 可直接消费的结果,而非原始网页 |
| 垂直深度 | 覆盖金融、法律、学术、安全等 Agent 高频场景 |
| 并行检索 | batch_search 一次多路并行,提升复杂任务效率 |
| 无广告干扰 | API-first,结果干净,适合自动化工作流 |
十、一张图看懂:你的 Agent 该不该接 AnySearch?
你的 Agent 需要搜索吗?
│
否 ──→ 暂时不需要
│
是
▼
只是偶尔查公网信息?
│
是 ──→ 匿名访问即可,零配置起步
│
否
▼
需要垂直领域数据(金融/学术/安全/代码)?
│
是 ──→ 注册 API Key + 接入 MCP 或 Skill
│
否
▼
需要并行多路检索或网页正文提取?
│
是 ──→ batch_search + extract,完整接入
│
否 ──→ 基础 search 能力足够十一、结语:AI 时代需要新的「信息层」
AI Agent 正在从聊天机器人,进化成能写代码、做调研、分析市场、执行工作流的生产力系统。
但再强的推理能力,也绕不开一个基础问题:
你能不能拿到可靠、结构化、可追溯的信息?
传统搜索是为「人找网页」设计的。
AnySearch 是为「Agent 拿信息去干活」设计的。
它不是要替代 Google,而是在 AI 时代补上一块关键基础设施------让 Agent 真正能在真实世界里可靠地运行。
快速上手清单
- 访问 https://anysearch.com 注册账号
- 在 Console 创建免费 API Key
- 选择接入方式:Skill / MCP / API
- 安装并运行
doc入口测试 - 试一次
search和batch_search - 如需垂直搜索,先调
get_sub_domains查目录
相关链接
- 官网:https://anysearch.com
- API Key 控制台:https://anysearch.com/console/api-keys
- Skill 仓库:https://github.com/anysearch-ai/anysearch-skill
- MCP Server 仓库:https://github.com/anysearch-ai/anysearch-mcp-server
- Skill 市场:skills.sh / ClawHub / SkillHub / Glama
如果这篇文章对你有帮助,欢迎转发给正在搭建 AI Agent 的朋友。