问题
需要再AWS的数据湖里面对数据进行CRUD,这里就需要使用Apache Iceberg来管理数据。
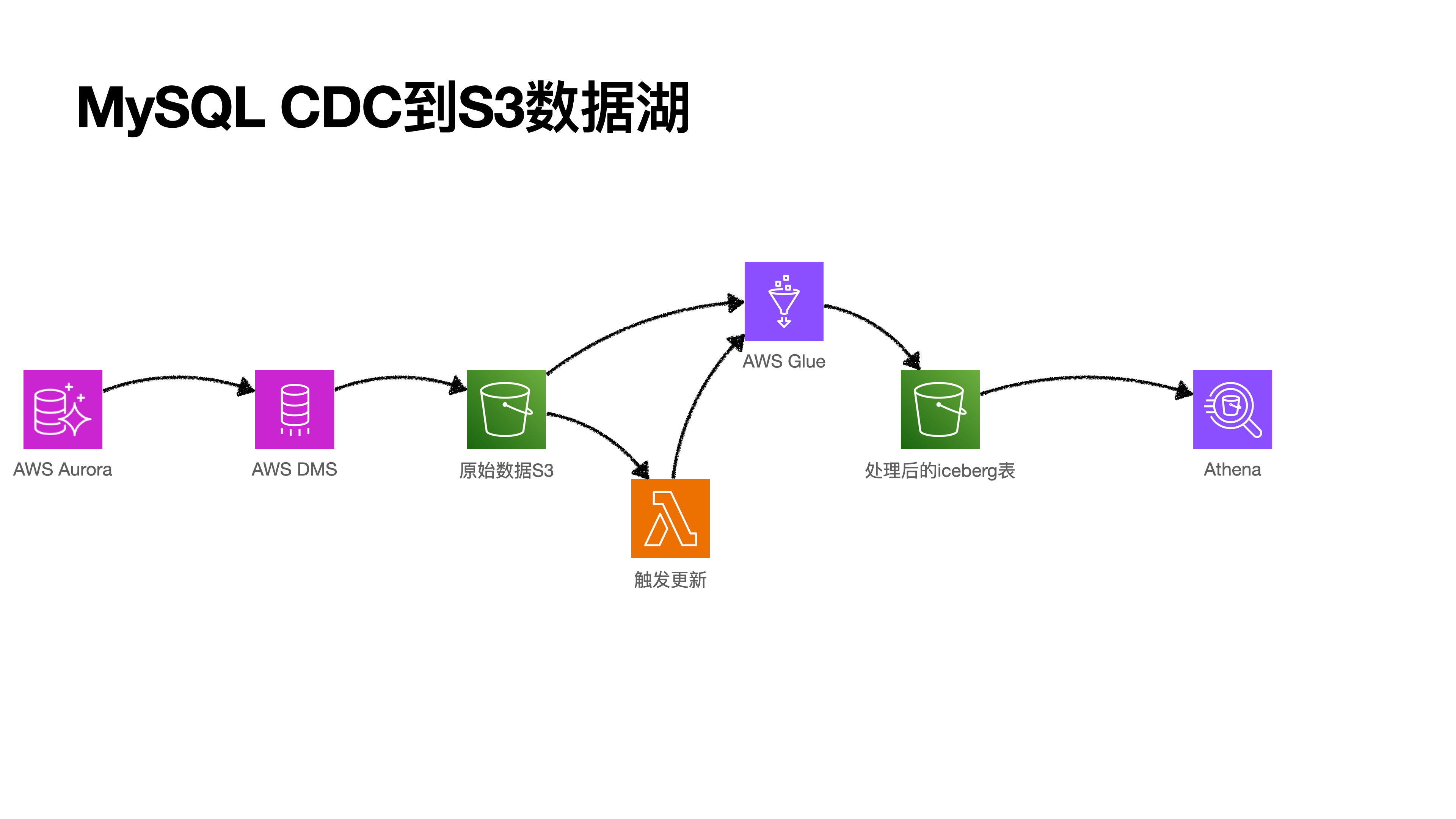
这了我们使用AWS DMS服务来构建CDC,将MySQL中的数据搬到s3,然后,使用Lambda来触发CDC更新数据到Athena(Apache Iceberg)中使用。
一图胜千言
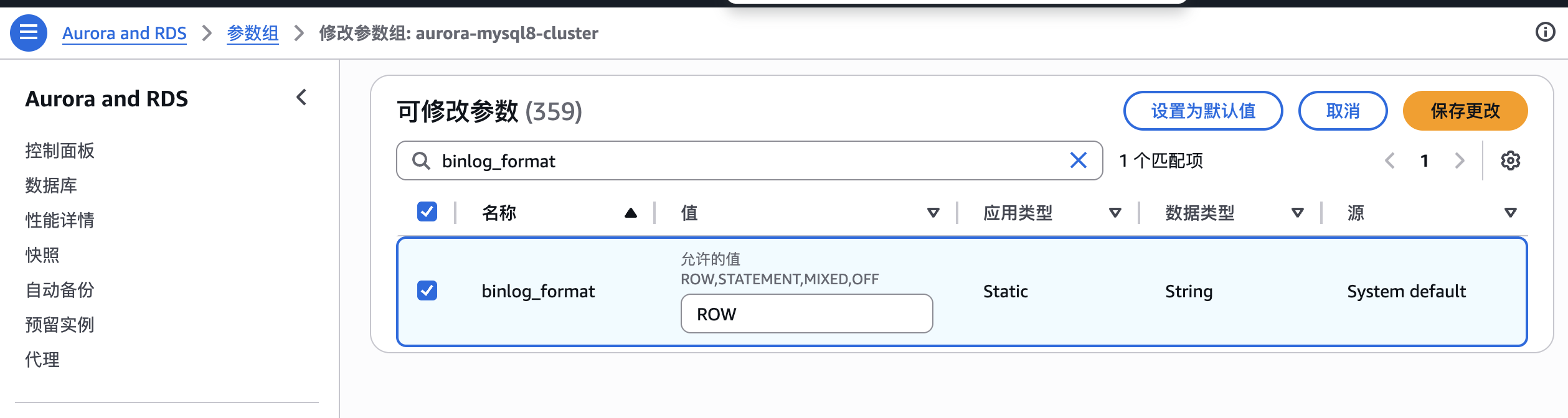
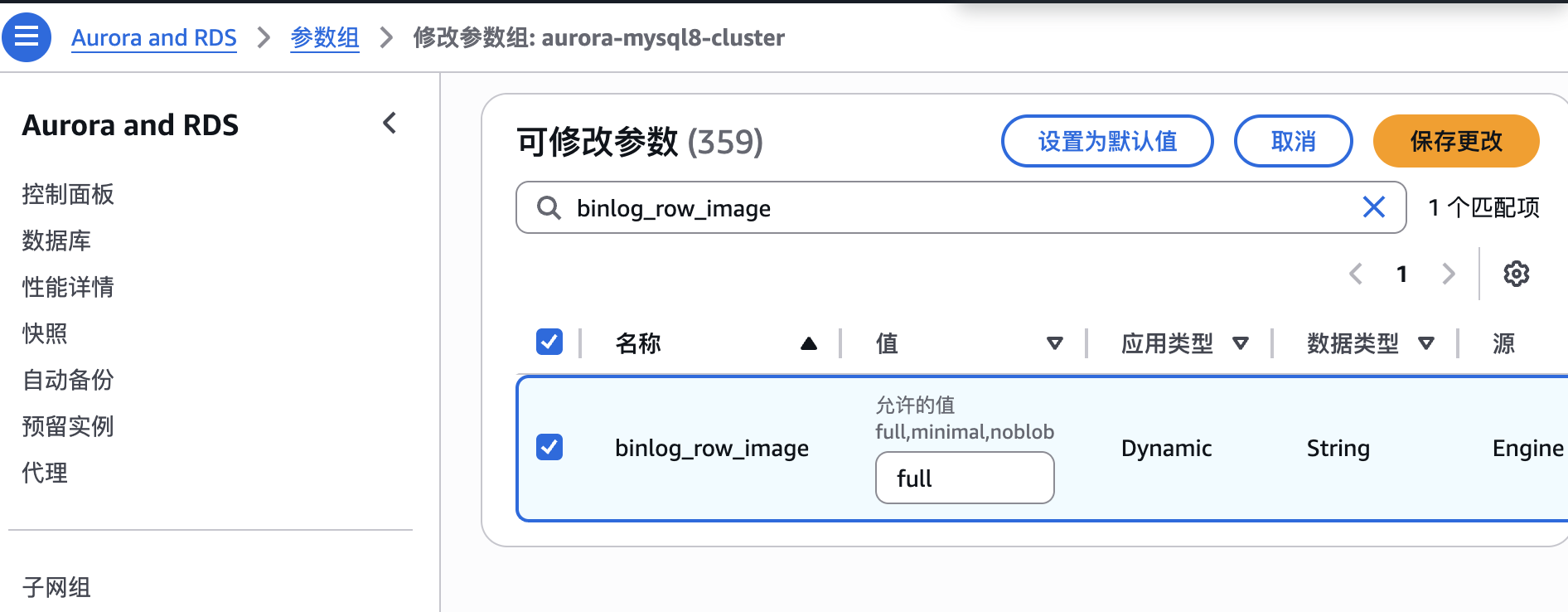
修改MySQL参数
binlog_format:ROWbinlog_row_image:Full
这是MySQL审计日志最全的方式。
创建mysql用户
sql
# CDC权限
CREATE USER 'dms_user'@'%' IDENTIFIED BY 'dms_User349';
GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'dms_user'@'%';
# 业务库和业务表
grant select on mydb.* to dms_user;
# 使用 MySQL 特定的迁移前评估
grant select on mysql.user to dms_user;
grant select on mysql.db to dms_user;
grant select on mysql.tables_priv to dms_user;
grant select on mysql.role_edges to dms_user; #only for MySQL version 8.0.11 and higher
grant select on performance_schema.replication_connection_status to dms_user; #Required for primary instance validation - MySQL version 5.7 and higher only
# RDS 运行 MySQL 特定的迁移前评估
grant select on mysql.rds_configuration to dms_user; #Required for binary log retention check
# 如果参数BatchEnable是必需的true,则需要授予权限
grant create temporary tables on *.* to dms_user;
FLUSH PRIVILEGES;Amazon Secrets Manager
我这里的mysql是使用了AWS Secrets Manager进行用户名和密码托管轮转的。这里就不重点介绍了,我们主要关注AWS DMS数据迁移任务怎么创建。
AWS DMS
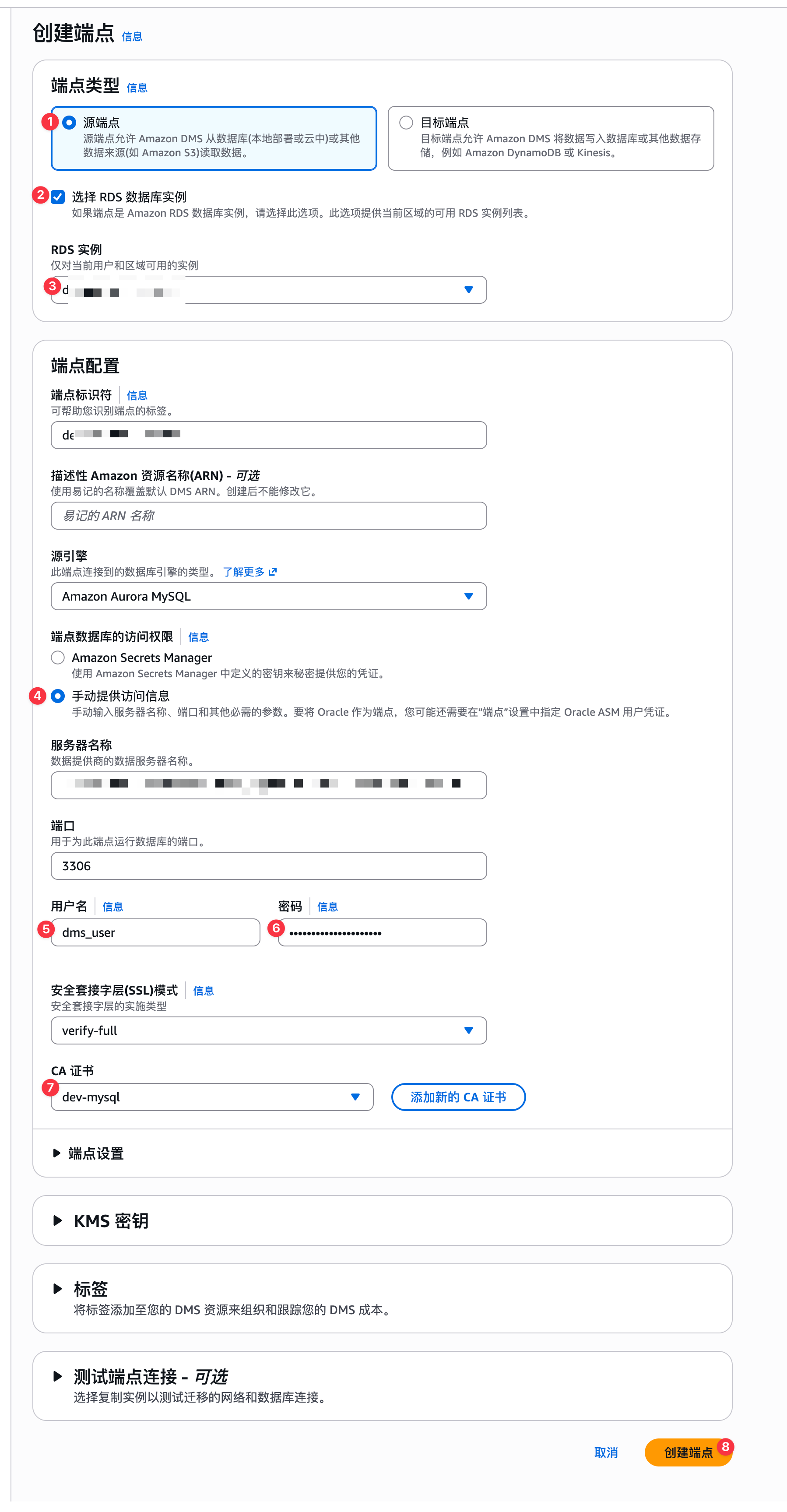
创建源端点
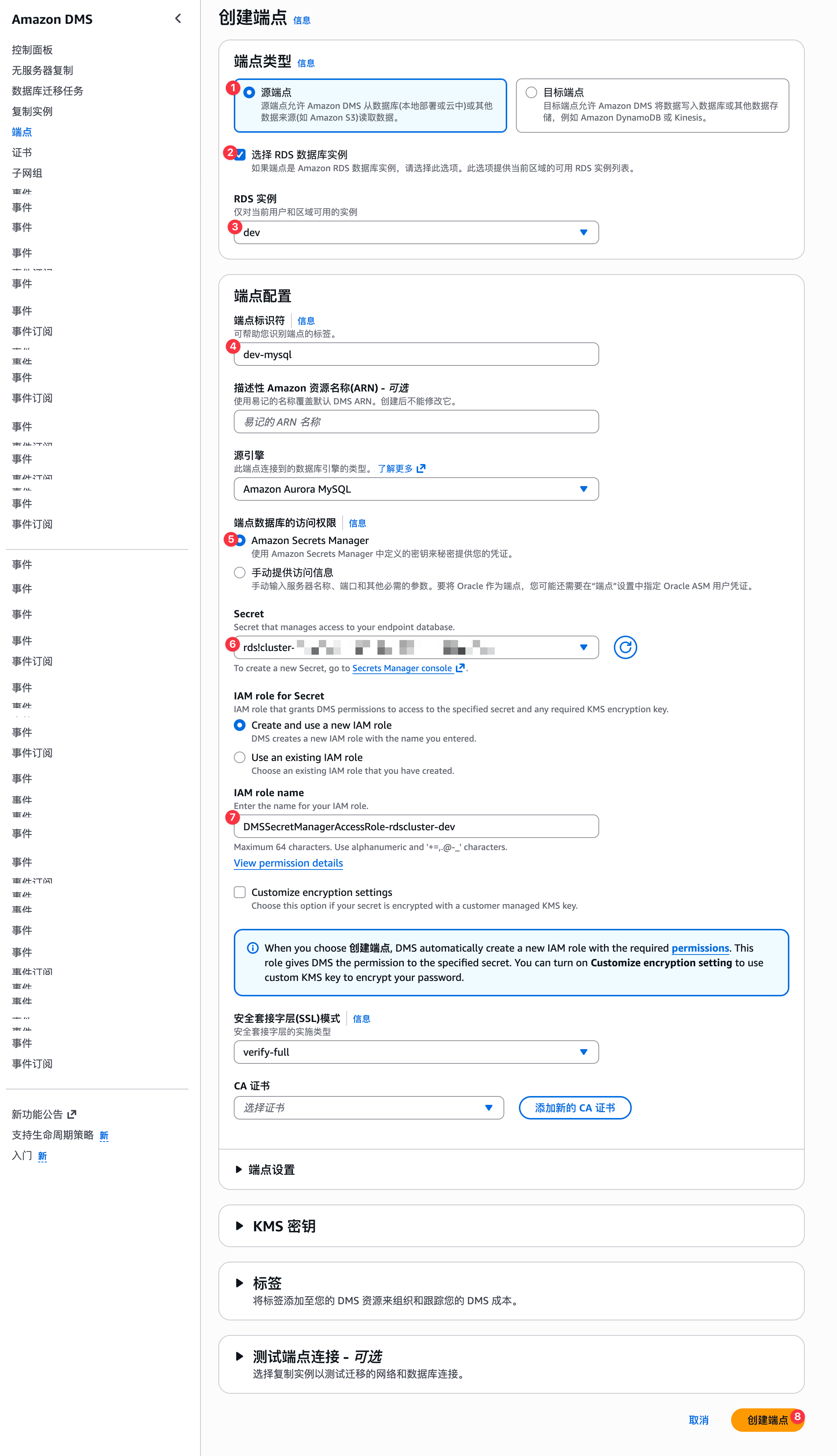
或者,如下方式创建:
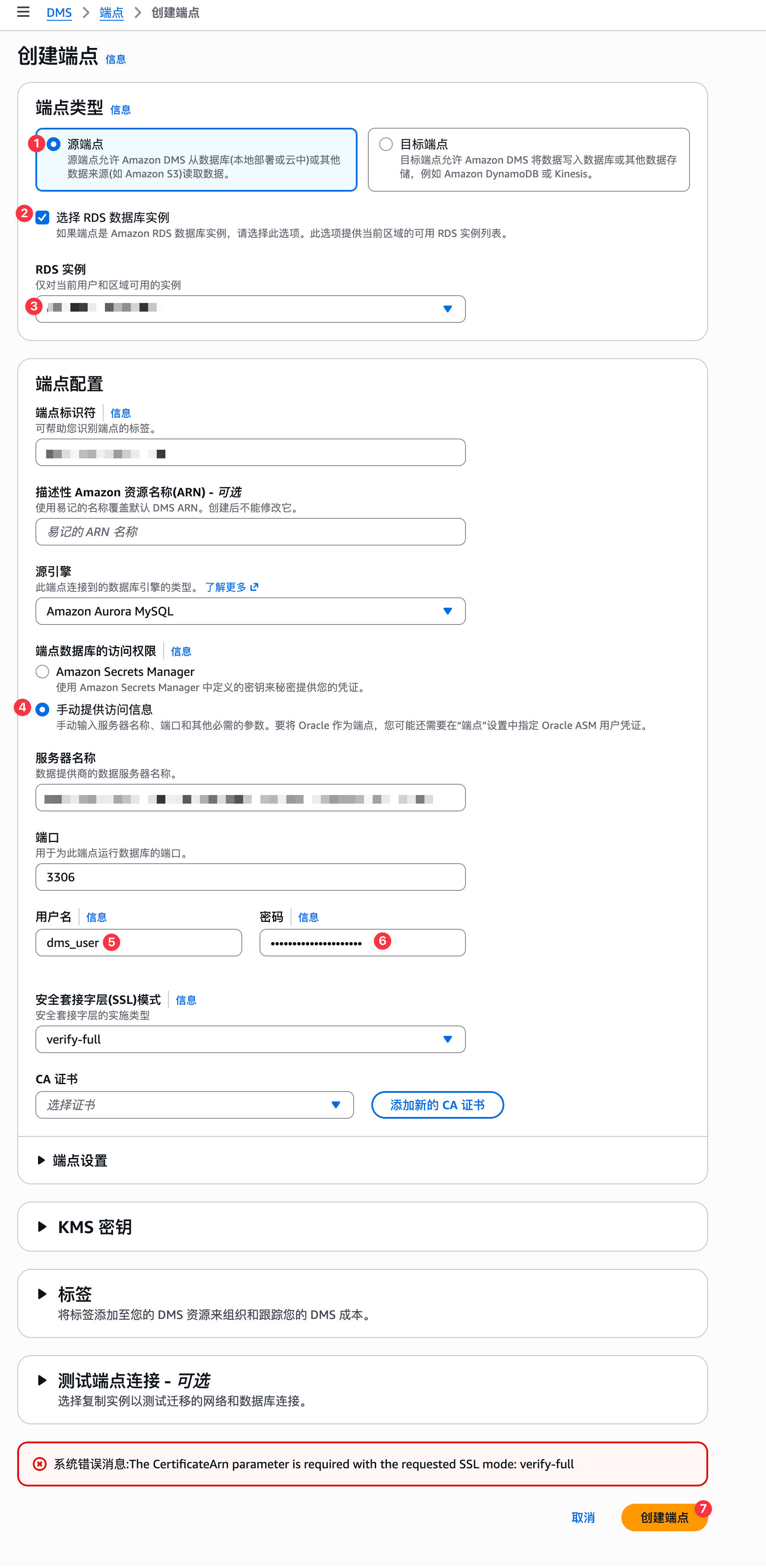
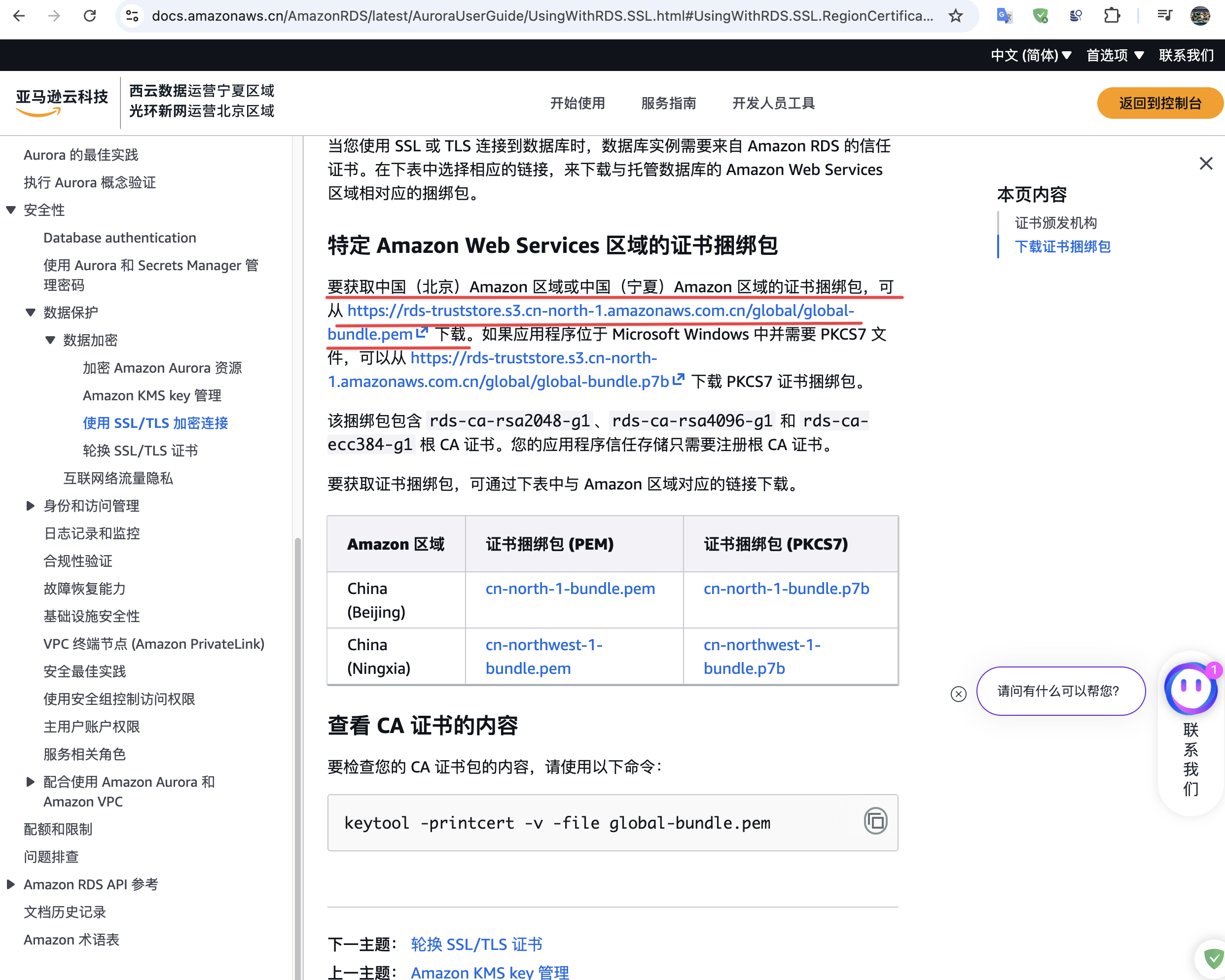
注意,这里连接mysql启用了必须使用SSL方式才能连接,需要手动将Aurora MySQL中的证书手动下载添加到DMS中。在如下页面中找到AWS Aurora MySQL中的证书,如下页面:
运行如下命令,验证一下下载的SSL证书:
bash
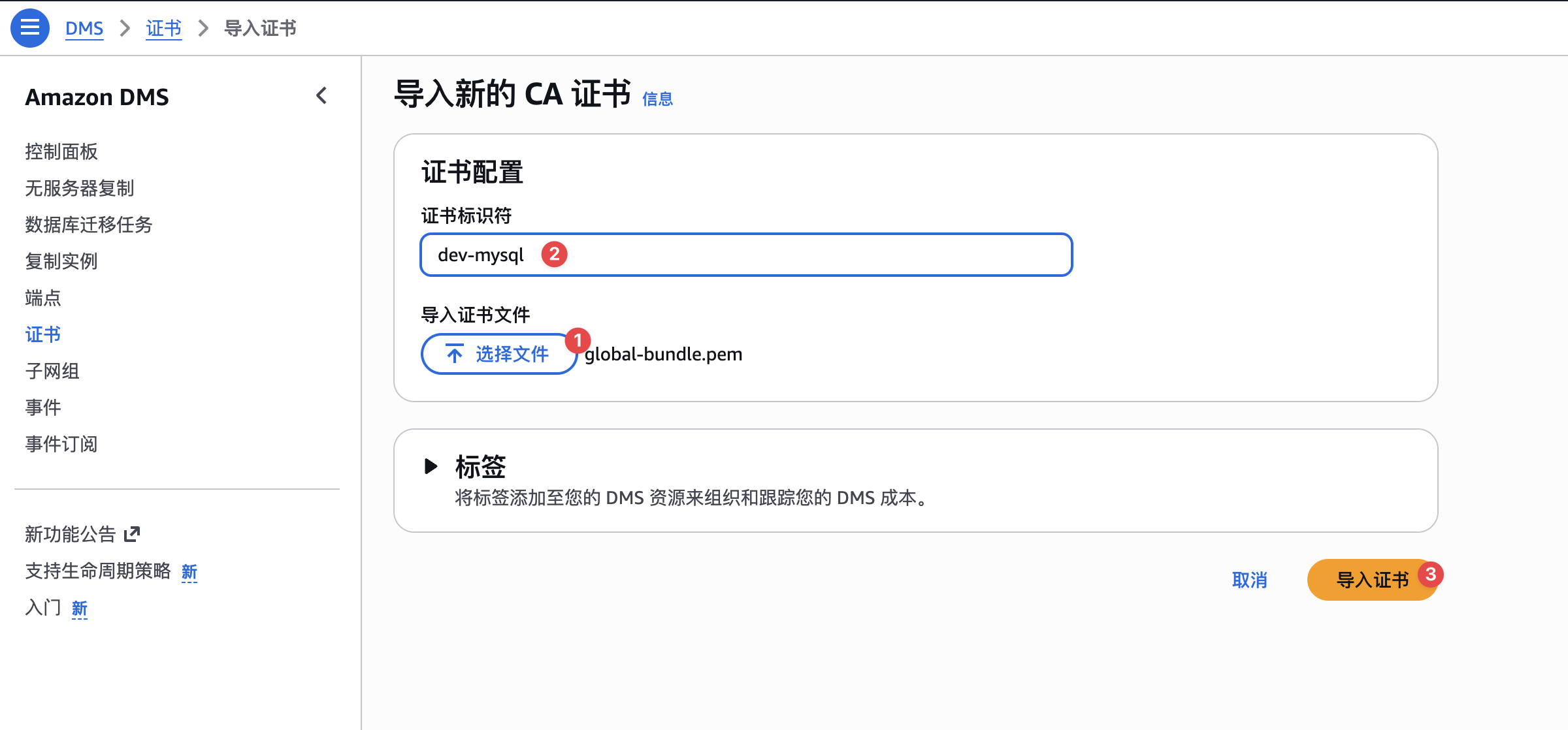
keytool -printcert -v -file global-bundle.pem我们在AWS DMS证书管理页面,导入上面MySQL的证书给DMS,如下图:
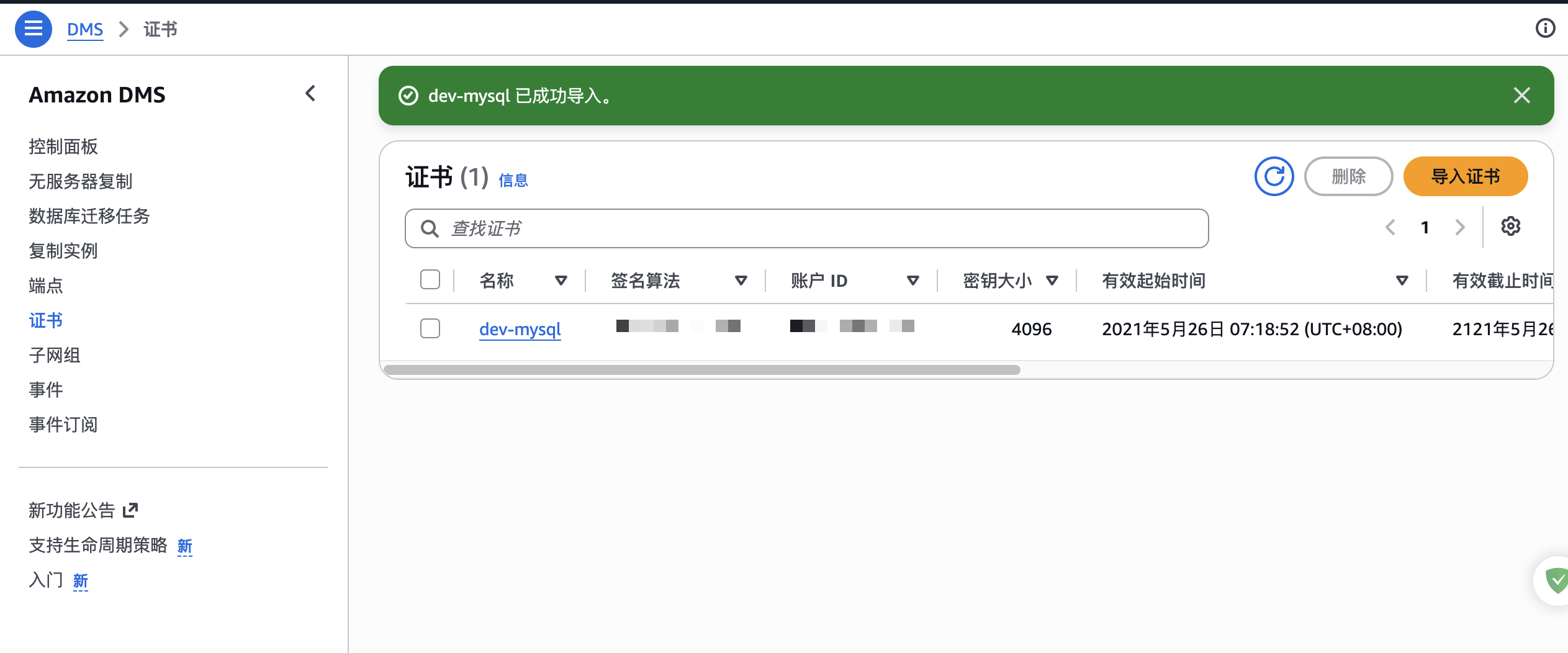
证书配置成功后,下面重新创建源端点:
创建目标端点
s3创建内网端点
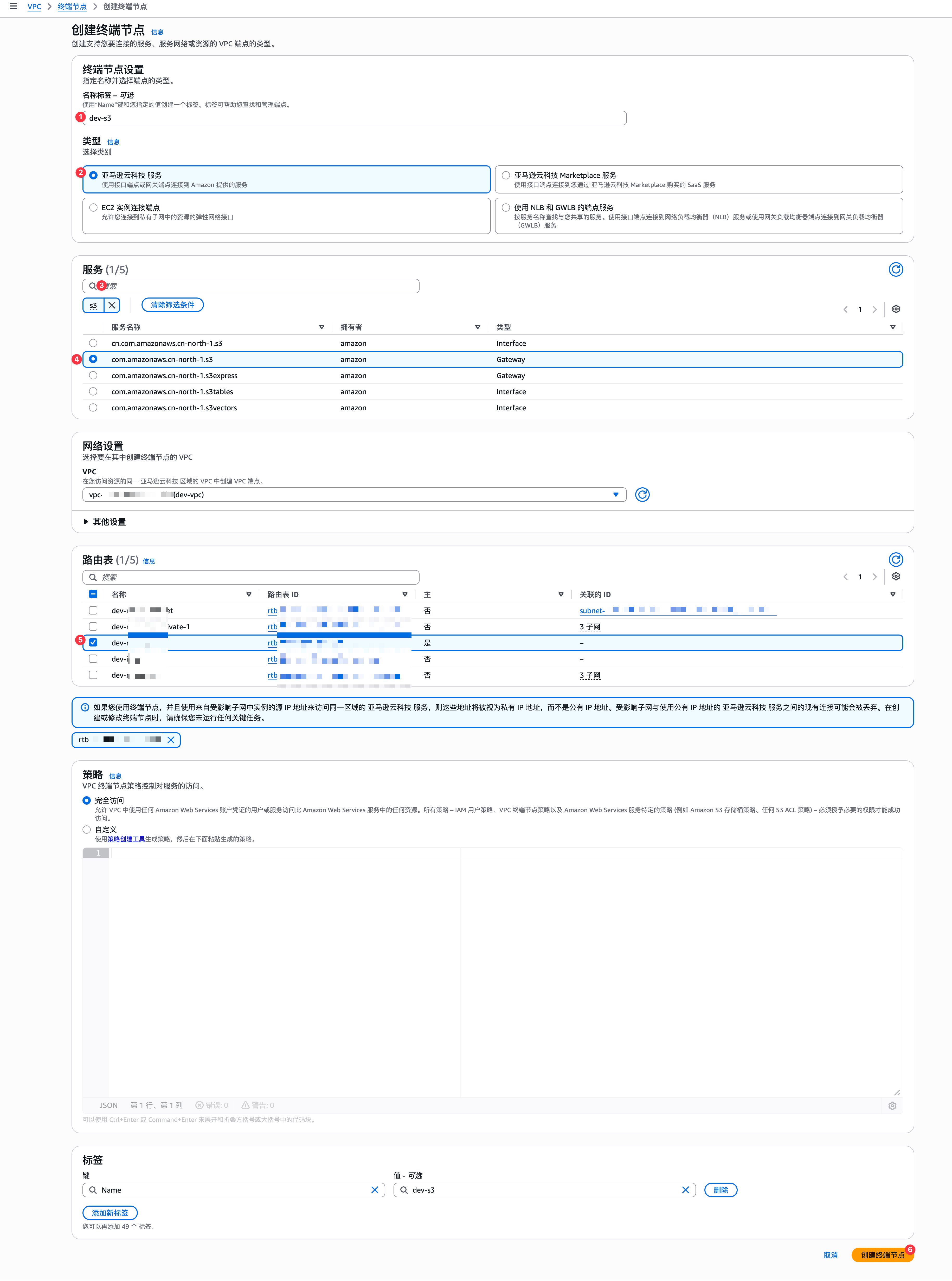
这里的路由表,你如果不知道怎么设置,或者后续无法写数据到s3的话,你可以一股脑全部把路由表都够选上也可以。
Athena的vpc 端点创建
Athena vpc端点安全组创建
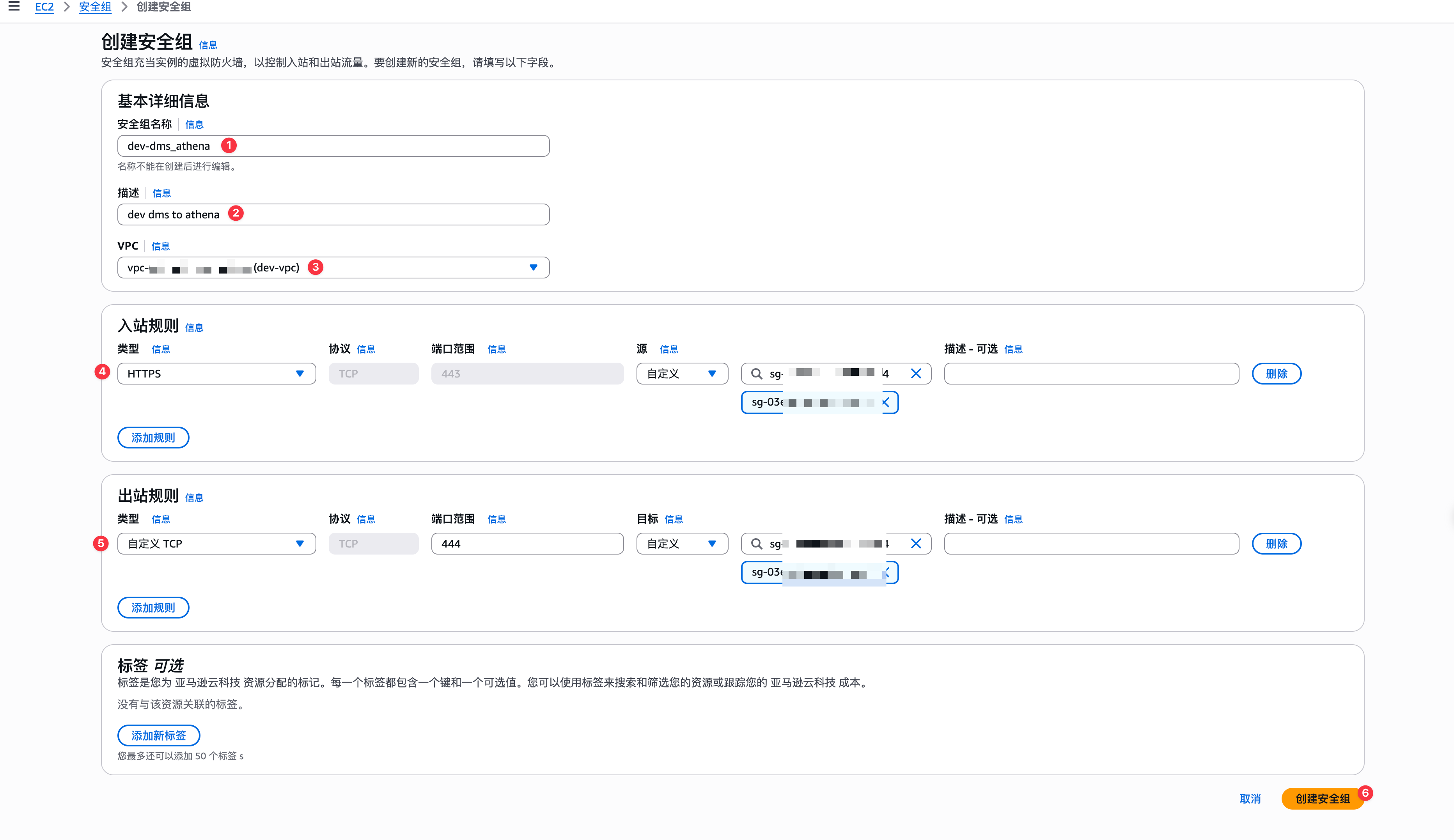
这里的athena vpc 端点的安全组中的出入站规则都是指定了dms的安全组。下面就可以开始创建athena的vpc内网端点了,如下图:
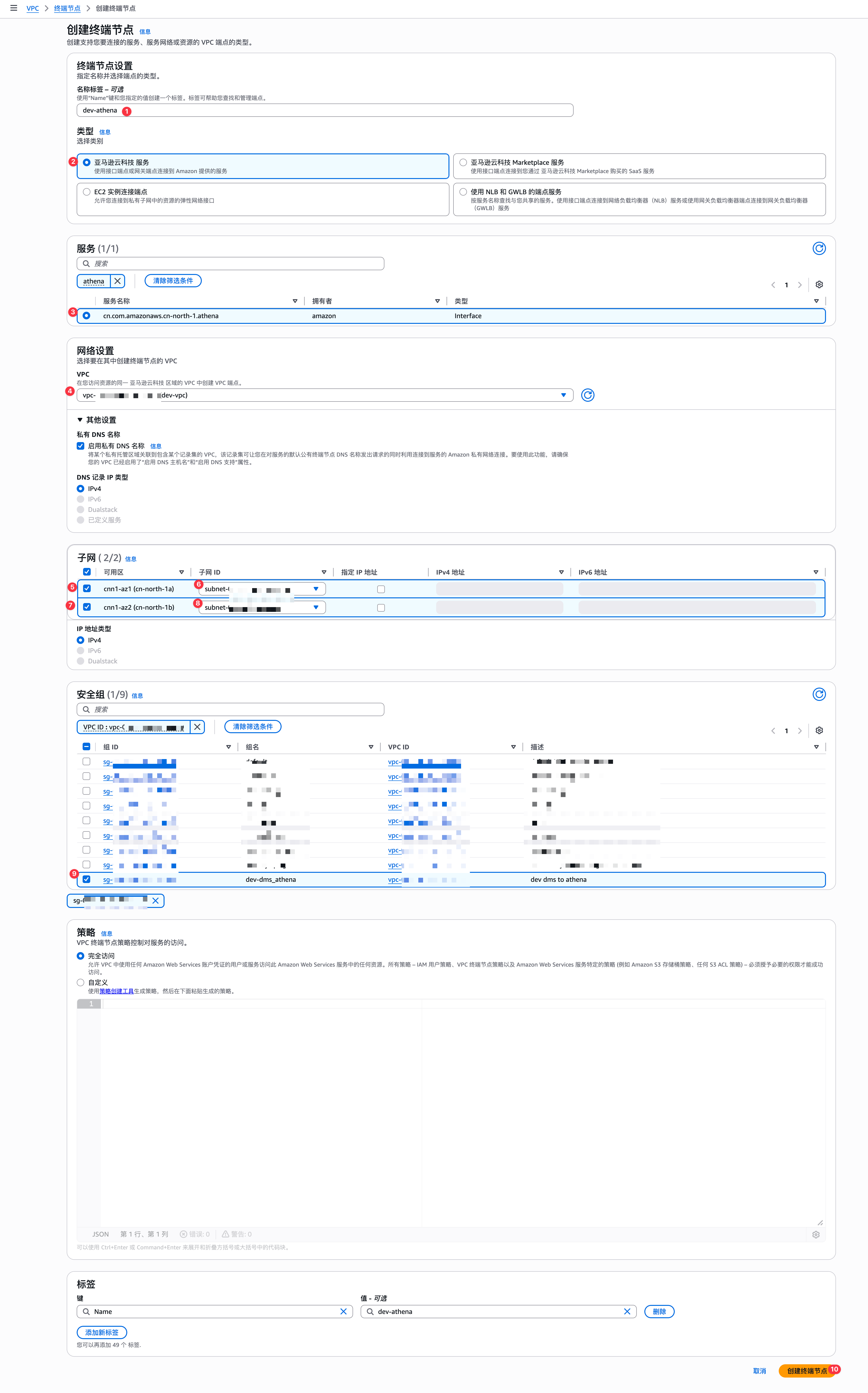
接下来创建s3目标端点,注意这里使用到的s3桶名,最好以aws-glue-开头,方便以后glue中任务读取。如下图:
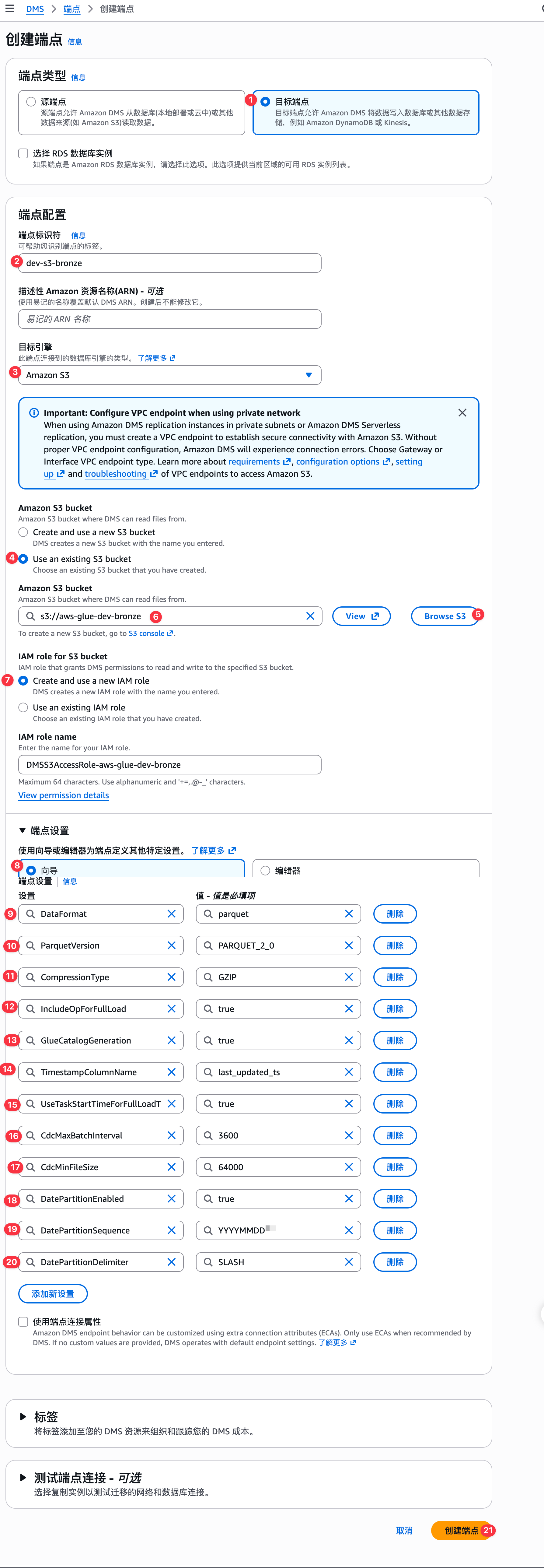
参数配置如下:
json
{
"DataFormat": "parquet",
"ParquetVersion": "PARQUET_2_0",
"CompressionType": "GZIP",
"IncludeOpForFullLoad": true,
"GlueCatalogGeneration": true,
"TimestampColumnName": "last_updated_ts",
"UseTaskStartTimeForFullLoadTimestamp": true,
"CdcMaxBatchInterval": 3600,
"CdcMinFileSize": 64000,
"DatePartitionEnabled": true,
"DatePartitionSequence": "YYYYMMDD",
"DatePartitionDelimiter": "SLASH",
"DatePartitionTimezone": "Asia/Shanghai"
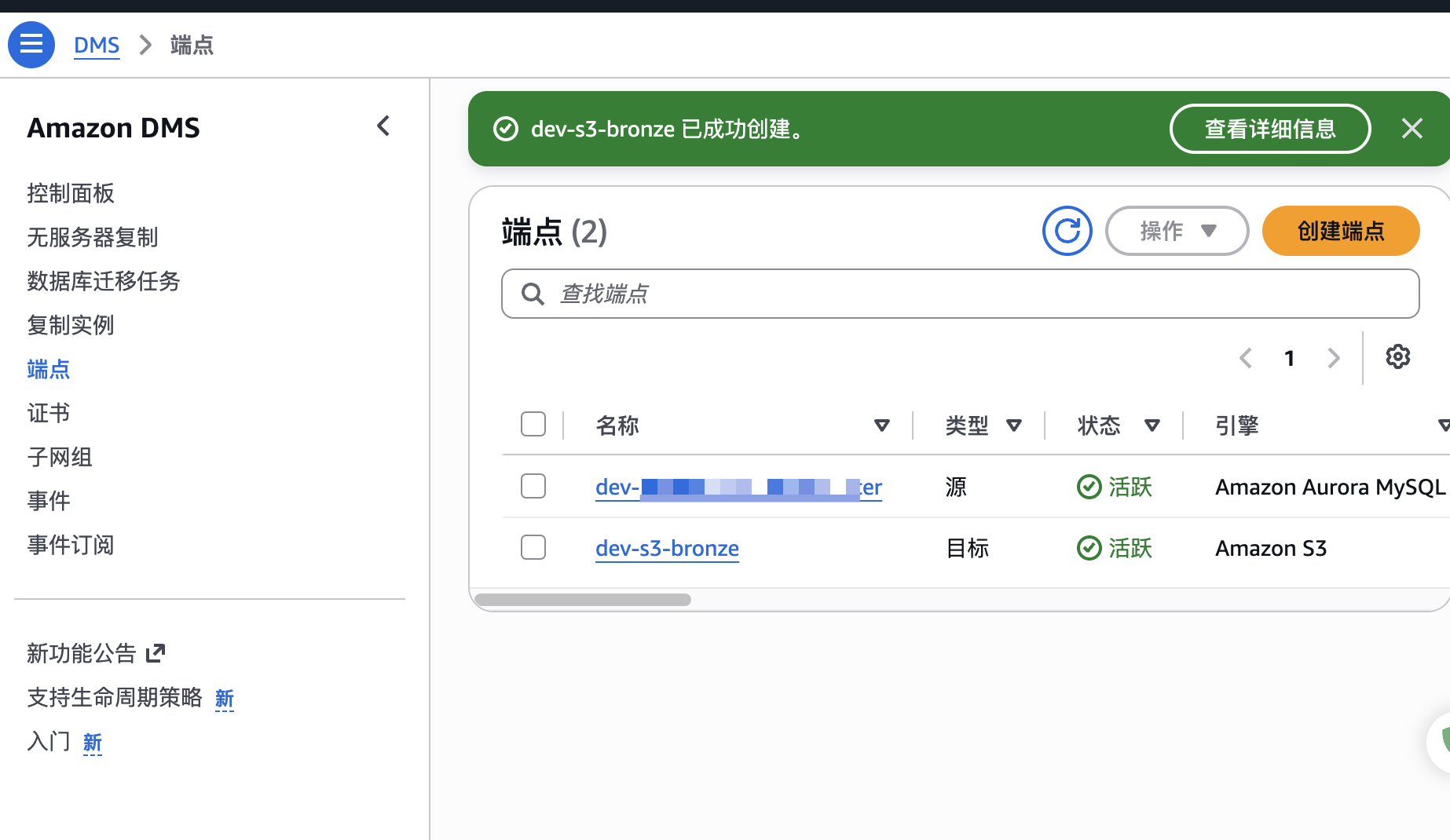
}源和目标端点都创建之后,如下图:
这个目标S3端点会创建一个角色,这个角色缺失"s3:DeleteObject",权限,需要我们自己手动加一下这个权限。还得添加s3解密,glue和athena相关权限配置:
json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:GetObjectVersion"
],
"Resource": [
"arn:aws-cn:s3:::aws-glue-dev-bronze/*"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "111112234434"
}
}
},
{
"Sid": "ListBucketActions",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "111112234434"
}
}
},
{
"Sid": "GetBucketActions",
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:GetBucketVersioning"
],
"Resource": [
"arn:aws-cn:s3:::aws-glue-dev-bronze"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "111112234434"
}
}
},
{
"Sid": "EnableBucketHTTPSOnly",
"Action": "s3:*",
"Effect": "Deny",
"Resource": [
"arn:aws-cn:s3:::aws-glue-dev-bronze/*",
"arn:aws-cn:s3:::aws-glue-dev-bronze"
],
"Condition": {
"Bool": {
"aws:SecureTransport": false
}
}
},
{
"Sid": "AllowUseOfTheKey",
"Effect": "Allow",
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:CreateDatabase",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:CreateTable",
"glue:DeleteTable",
"glue:UpdateTable",
"glue:GetTable",
"glue:GetTables",
"glue:BatchCreatePartition",
"glue:CreatePartition",
"glue:UpdatePartition",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition"
],
"Resource": [
"arn:aws-cn:glue:*:111112234434:catalog",
"arn:aws-cn:glue:*:111112234434:database/*",
"arn:aws-cn:glue:*:111112234434:table/*"
]
},
{
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:CreateWorkGroup"
],
"Resource": "arn:aws-cn:athena:*:111112234434:workgroup/*"
}
]
}就可以开始CDC任务创建了。
开始CDC
创建安全组
创建一个安全组给CDC任务使用:
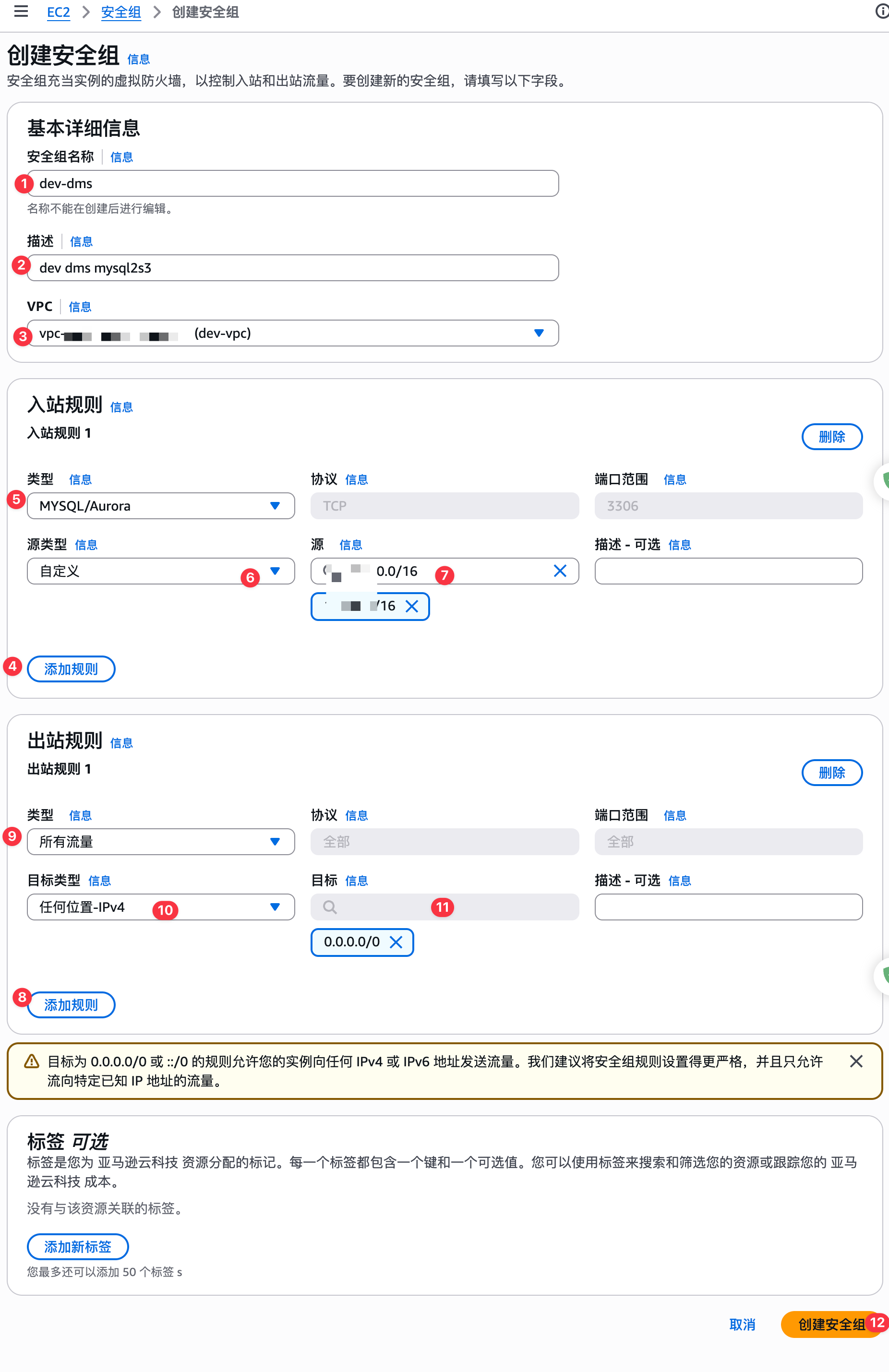
开始创建复制,如下图:
注意,这里的前缀,不要使用-字符,因为AWS DMS在Athena中创建数据库,使用连字符会失败,应该改成下划线_,需要注意一下。
创建完成,手动启动,如下图:
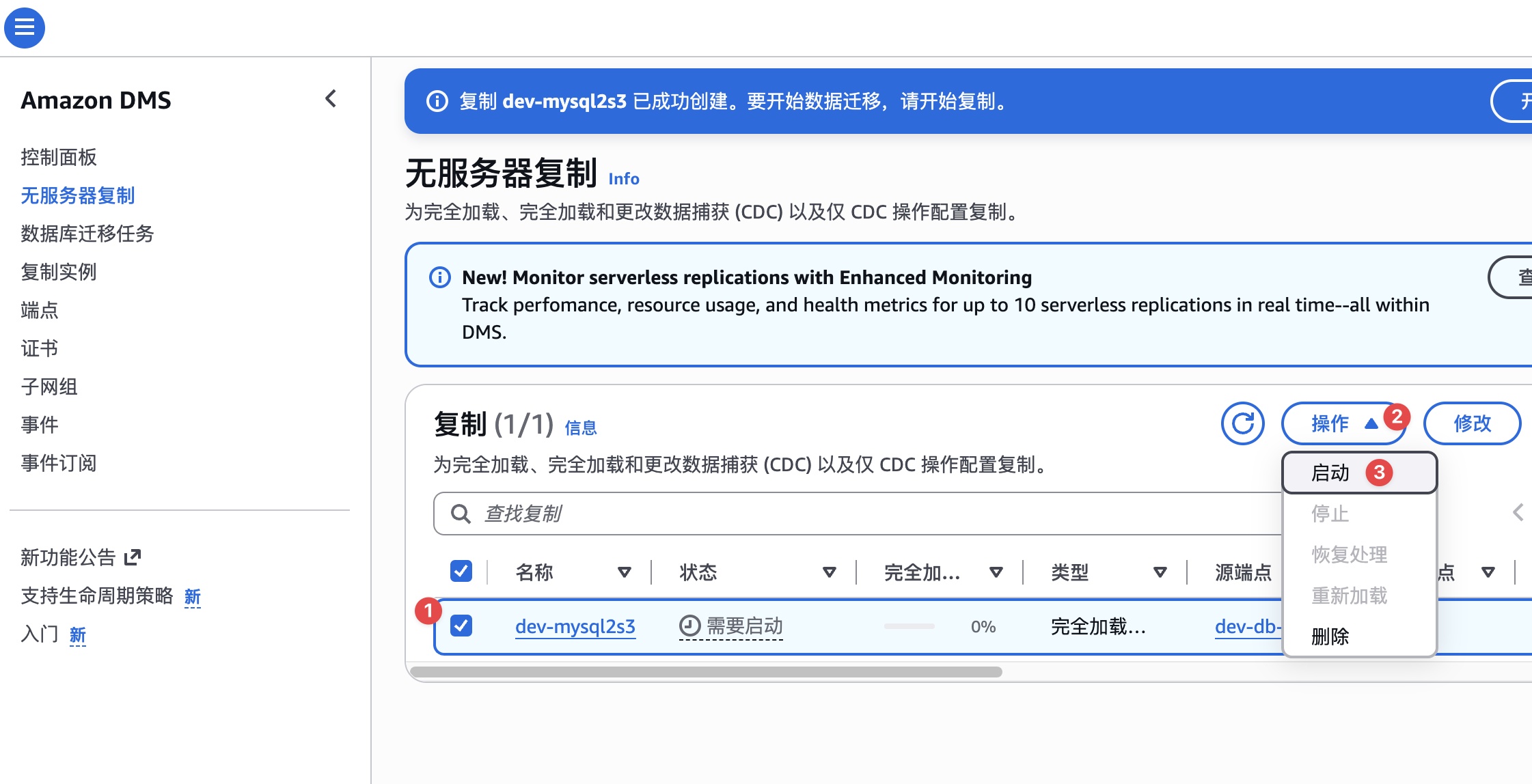
启动之前,先让AWS云先评估一下,如果没问题,再真正开始CDC任务,如下图:
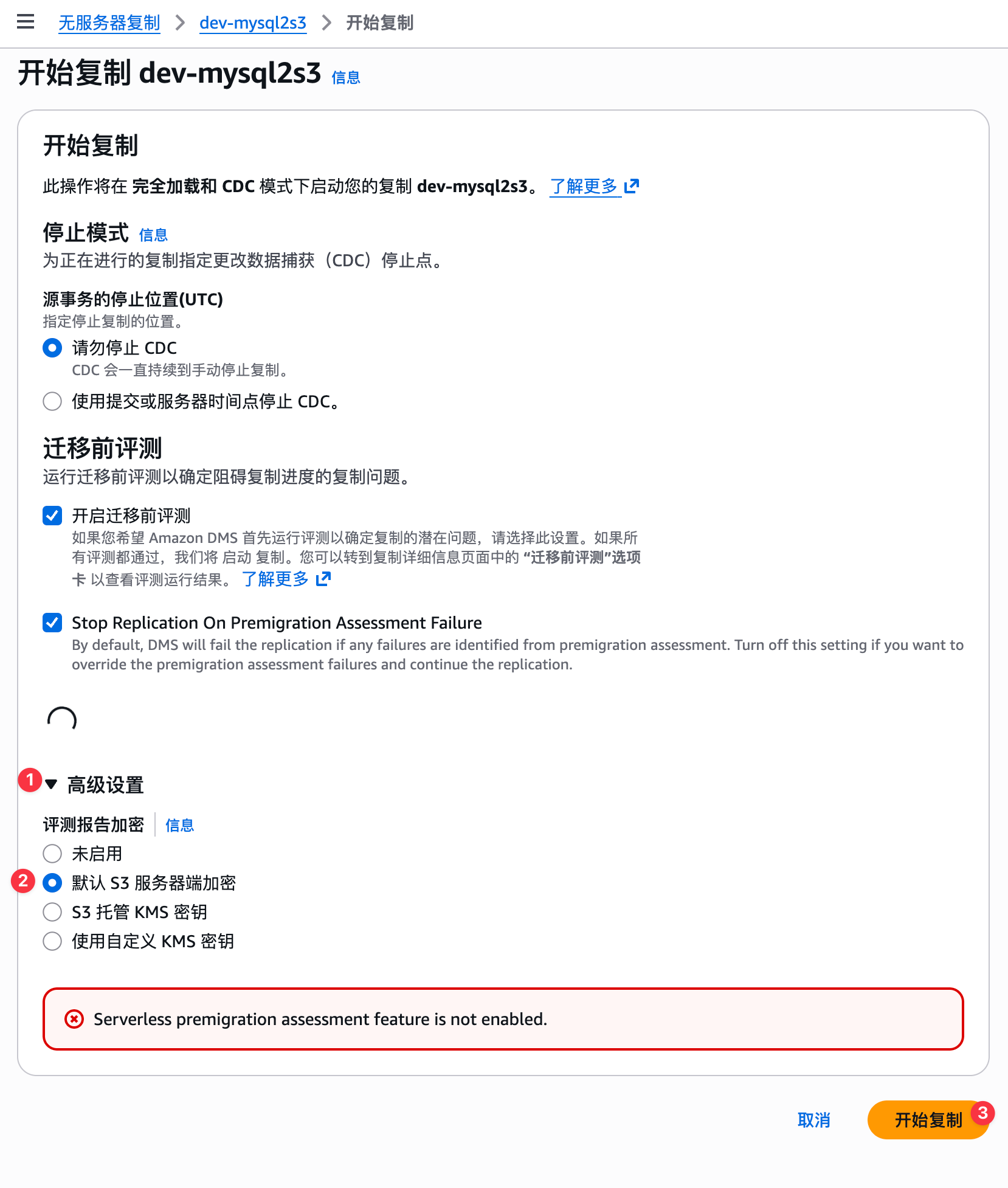
看到如下AWS DMS任务,表示我们的CDC任务运行成功了:
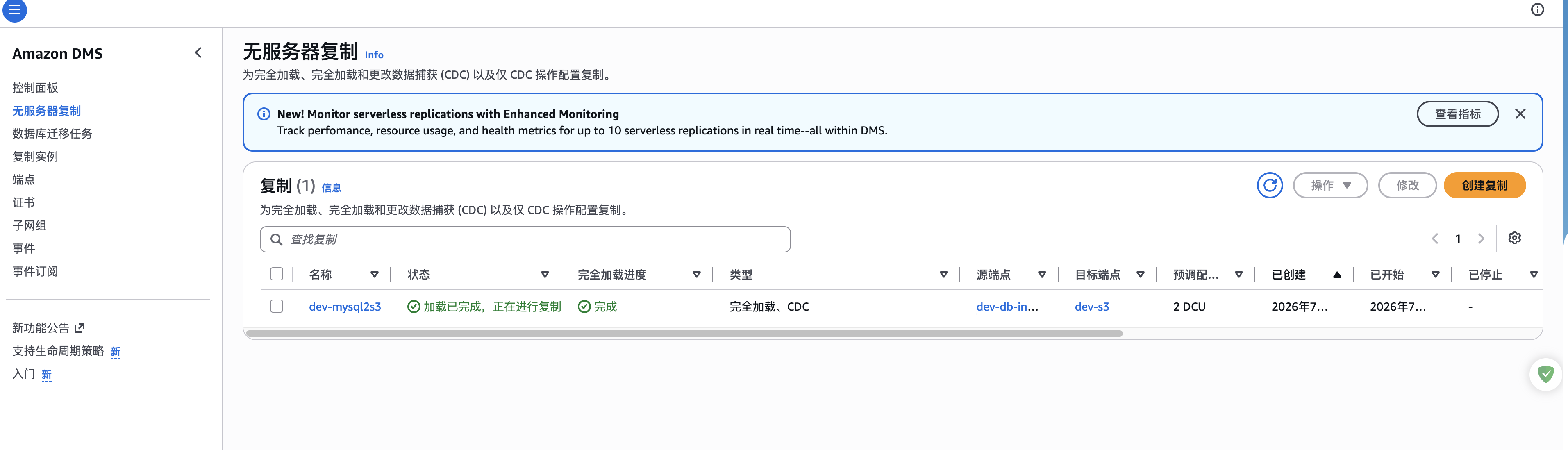
到此CDC任务运行成功。到这里只是将mysql里面的binlog数据全部搬到数据湖里面的铜牌层,还需要进一步清理数据到银牌层。
银牌层
创建Silver S3桶
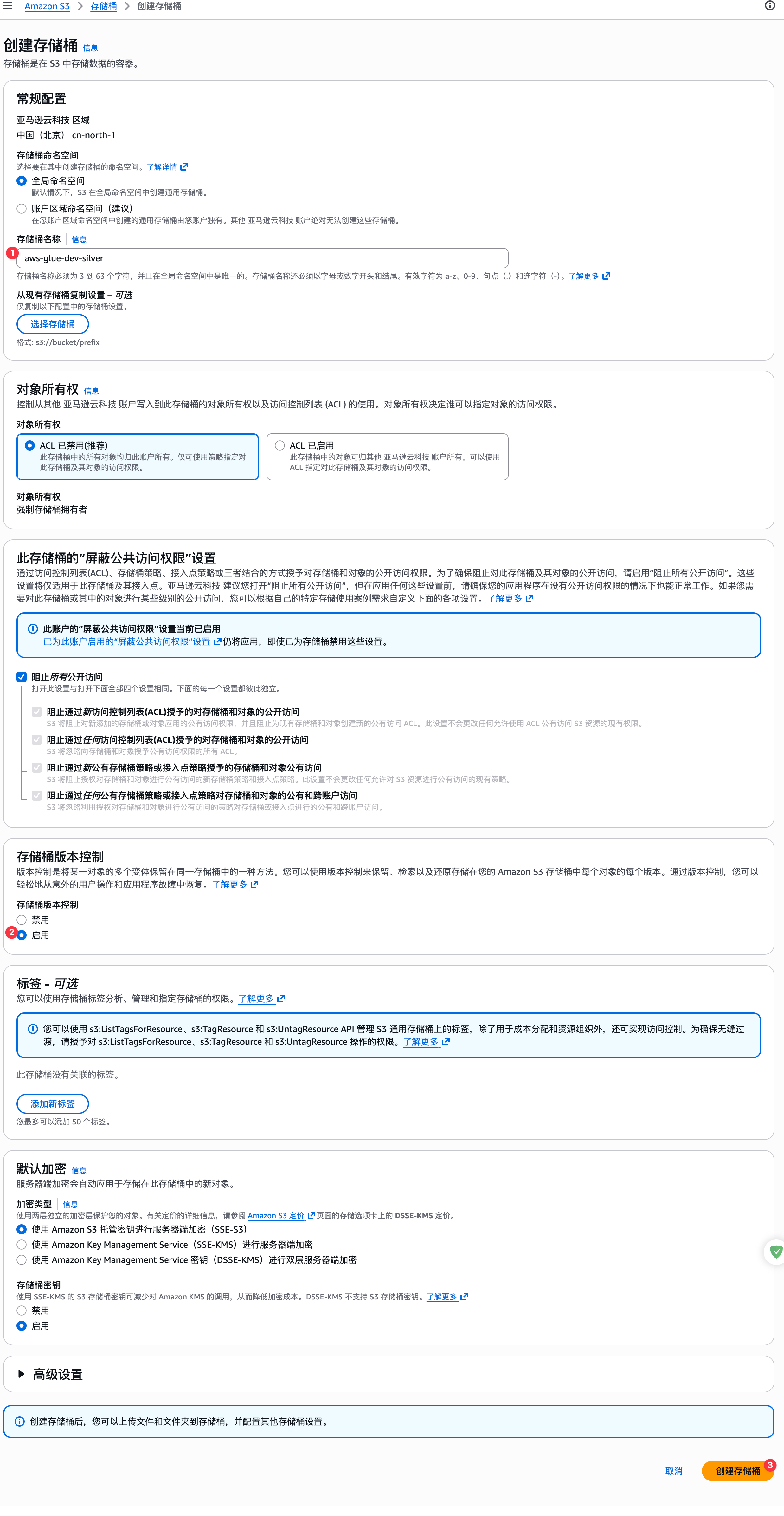
Iceberg数据库创建
sql
CREATE DATABASE dev_silver_db;直接在glue创建银牌层桶。
创建Iceberg表
根据需要处理的原始表结构,来写下面的DDL语句:
sql
CREATE TABLE my_iceberg (
last_updated_ts TIMESTAMP,
id BIGINT,
name STRING
)
LOCATION 's3://aws-glue-dev-silver/dbname/my_iceberg/'
TBLPROPERTIES ('table_type'='ICEBERG', 'format'='parquet')AWS Glue合并任务
AWSGlueServiceRoleDev角色创建
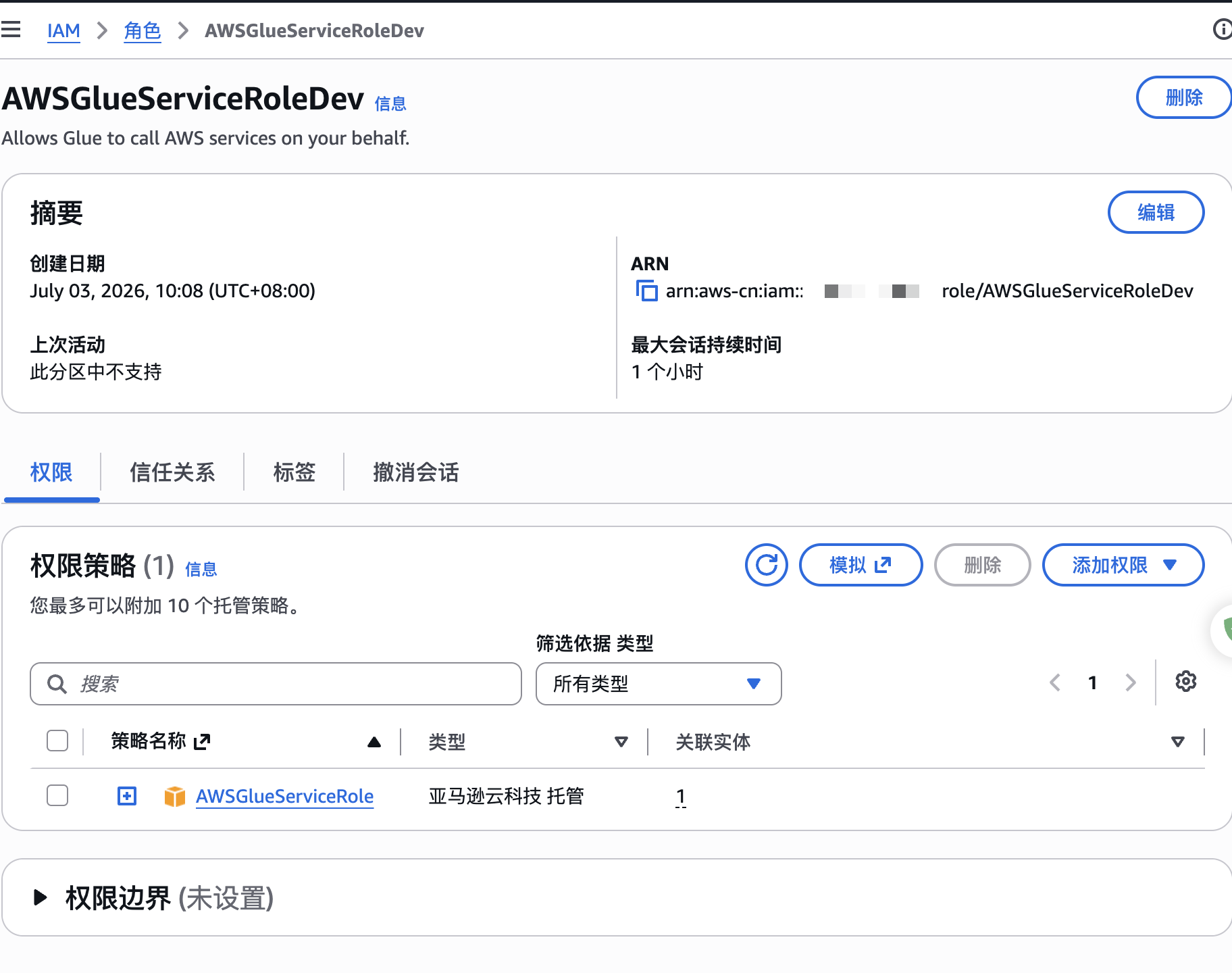
这个角色必须以AWSGlueServiceRole开头,不然AWS Glue任务无法选择这个角色。创建Glue任务如下:
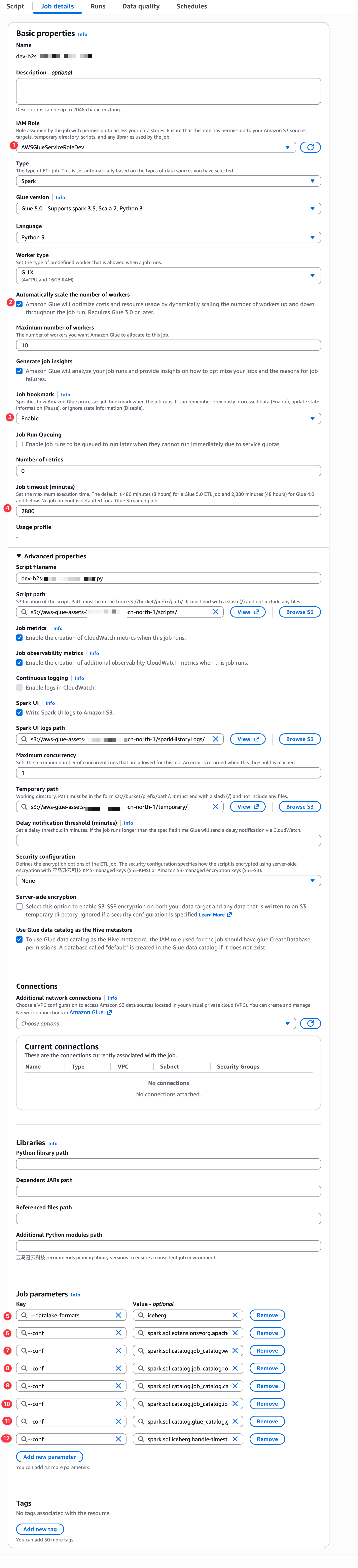
其中配置参数为:
bash
--datalake-formats iceberg
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
--conf spark.sql.catalog.glue_catalog.warehouse=s3://aws-glue-dev-silver/dbname/my_iceberg/
--conf spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog
--conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO
--conf spark.sql.catalog.glue_catalog.glue.lakeformation-enabled=true
--conf spark.sql.iceberg.handle-timestamp-without-timezone=true任务源代码如下:
python
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import TimestampType
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# ============================================
# 第一步:从 Bronze 表读取增量数据
# ============================================
# 注意:transformation_ctx 对 Glue 书签机制至关重要,请保持唯一且不变[reference:0]
myIcebergIncrementalInputDF = glueContext.create_dynamic_frame.from_catalog(
database="dev_bronze", # 修改为你的 Glue 数据库名
table_name="my_iceberg", # 修改为你的 Bronze 表名
transformation_ctx="myIcebergIncrementalInputDF"
).toDF()
# ============================================
# 第二步:去重 - 按 id 分组,保留 last_updated_ts 最新的记录[reference:1]
# ============================================
windowSpec = Window
.partitionBy(myIcebergIncrementalInputDF.id)
.orderBy(col("last_updated_ts").desc())
rankedDF = myIcebergIncrementalInputDF
.withColumn("row_num", row_number().over(windowSpec))
deduplicatedDF = rankedDF
.filter(col("row_num") == 1)
.drop("row_num")
# ============================================
# 第三步:清洗 - 数据类型转换、字段拆分等[reference:2]
# ============================================
deduplicatedDF = deduplicatedDF
.withColumn("last_updated_ts", col("last_updated_ts").cast(TimestampType()))
# 注册为临时视图,供 MERGE 语句使用[reference:3]
deduplicatedDF.createOrReplaceTempView("deduplicated_view")
# ============================================
# 第四步:执行 MERGE 到 Silver 层 Iceberg 表[reference:4]
# ============================================
merge_sql = """
MERGE INTO glue_catalog.dev_silver_db.my_iceberg AS target
USING deduplicated_view AS source
ON target.id = source.id
WHEN MATCHED AND source.op = 'U' THEN
UPDATE SET
target.last_updated_ts = source.last_updated_ts,
target.name = source.name
WHEN MATCHED AND source.op = 'D' THEN
DELETE
WHEN NOT MATCHED THEN
INSERT (
last_updated_ts, id, name
) VALUES (
source.last_updated_ts, source.id, source.name
)
"""
spark.sql(merge_sql)
job.commit()lambda触发函数
创建一个AWS Lambda函数,源代码如下:
python
import json
import boto3
def lambda_handler(event, context):
glue_client = boto3.client('glue')
glue_job_name = 'dev-b2s-xxxx'
try:
# Start the Glue job
response = glue_client.start_job_run(JobName=glue_job_name)
print(f"Glue job started: {response['JobRunId']}")
except Exception as e:
print(f"Error starting Glue job: {str(e)}")
raise e
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}注意,这里需要给aws lambda的角色添加启动glue任务的权限,类似如下:
json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:StartJobRun"
],
"Resource": "arn:aws-cn:glue:cn-north-1:111112234434:job/*"
}
]
}然后,我们回到bronze层的s3桶,创建一个当文件创建的事件来激活调用这个lambda函数,如下图:
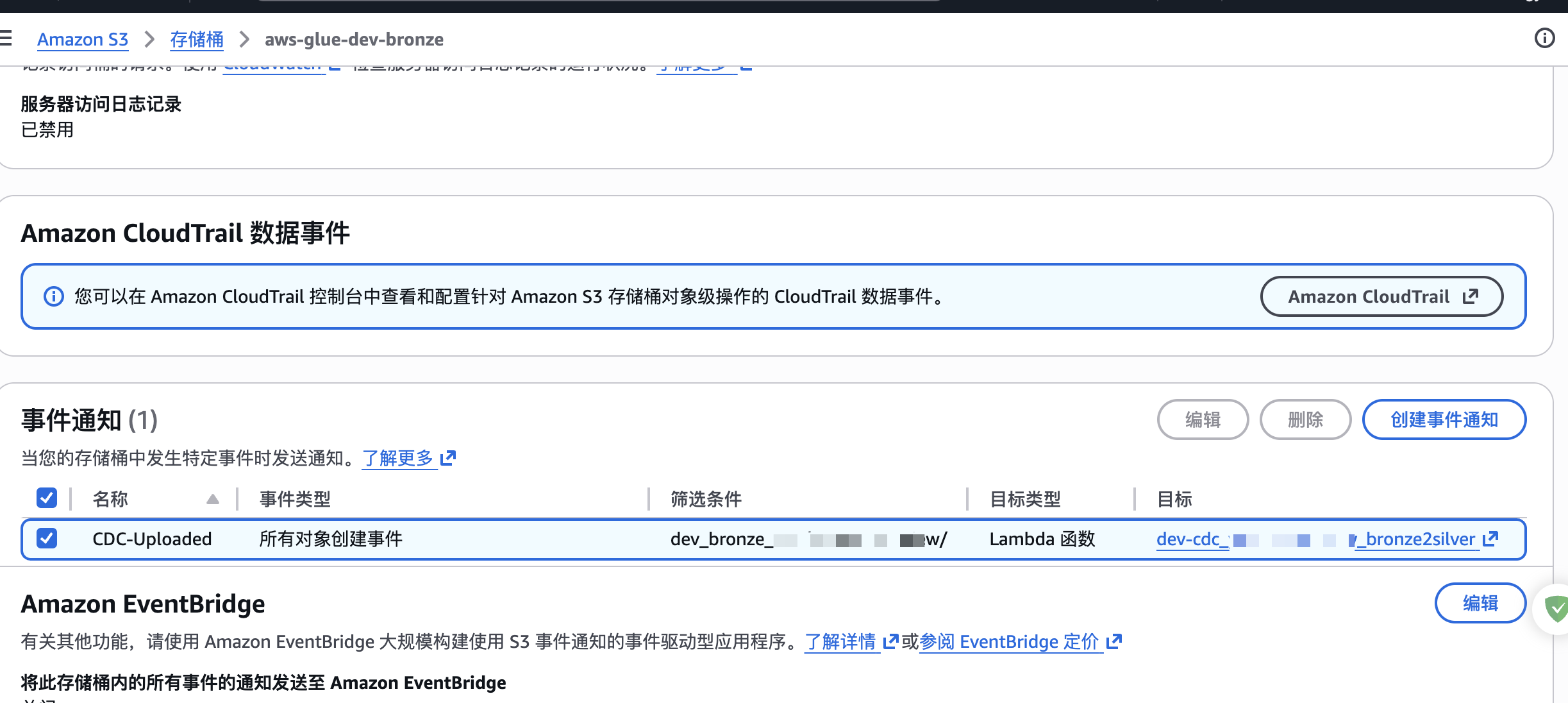
总结
没有搞过大数据的朋友,需要注意一下如下两个概念:
- Iceberg是表格式
- Parquet是文件格式
这就是AWS里面的将mysql里面数据搬到数据湖的方式。AWS DMS+AWS Lambda+AWS Glue。这里主要就是借助iceberg表来进行增量更新。
参考
- How to Merge your Relational Database into a Data Lake on AWS
- Real-Time CDC Pipeline: MySQL to Apache Iceberg Using AWS DMS Serverless, S3, and Lambda.
- Step 5: Configure an Amazon DMS Target Endpoint
- Using Amazon S3 as a target for AWS Database Migration Service
- How to MERGE your Database into a Data Lake on AWS | Change Data Capture | Apache Iceberg
- Apache Iceberg vs Parquet -- File Formats vs Table Formats
- Change data capture
- 使用与 MySQL 兼容的数据库作为源 Amazon DMS
- CREATE TABLE AS
- How to MERGE your Database into a Data Lake on AWS | Change Data Capture | Apache Iceberg
- AWS Aurora MySQL证书地址
- 为 MySQL-compatible、PostgreSQL 或 SQL Server 端点启用 SSL
- How can I use AWS DMS to migrate data to Amazon S3 in Parquet format?
- Athena JDBC 3.x 驱动程序
- Create an AWS Glue Data Catalog with AWS DMS
- Configuring VPC endpoints for AWS DMS
- Migrating MSSQL to AWS using Data Migration Service with CDC Migration
- 在 Amazon Glue 中使用 Iceberg 框架