vLLM Scheduler:为什么 Continuous Batching 是 LLM Serving 的核心?
摘要
在上一篇笔记里,我从一个请求的生命周期出发,梳理了 LLM 推理服务的大致流程:请求进入系统后,会经历 tokenizer、prefill、KV Cache 初始化、decode loop、scheduler 调度和 streaming output。
这篇继续沿着这条主线往下看:当系统里不止一个请求时,推理服务到底应该如何安排这些请求执行?
LLM 推理和普通模型推理最大的不同之一,是请求不会一次 forward 后立刻结束。一个请求在 prefill 之后,会进入多轮 decode,每一轮通常只生成一个 token。不同请求的 prompt 长度不同、生成长度不同、到达时间也不同。如果仍然使用传统 static batching,很容易出现短请求被长请求拖住、新请求无法加入、GPU 利用率下降等问题。
vLLM Scheduler 的核心价值,就是在每一轮推理 iteration 中动态决定哪些请求进入执行。Continuous Batching 则是在这种动态调度基础上,让完成的请求退出、新请求加入、运行中的请求继续生成,从而提高 GPU 利用率和整体吞吐。
这篇文章不直接深入某一行源码,而是先从调度问题本身出发,理解 Scheduler 为什么存在、Continuous Batching 解决了什么问题,以及 token budget、waiting / running 队列、prefill / decode 混合调度这些概念之间的关系。
1. 为什么 LLM 推理不能只用普通 batching
在很多传统推理任务里,batching 的逻辑比较直接。
比如图像分类服务,可以先收集一批图片,然后拼成一个 batch,送入模型 forward 一次,最后把结果分别返回给用户:
text
请求 A
请求 B → 拼成 batch → 模型 forward → 返回结果
请求 C这种场景里,请求通常是"一次性"的。模型执行一次,请求就结束了。
但 LLM 推理不一样。
一个请求进入 LLM 推理服务后,通常会经历:
text
prefill → decode → decode → decode → ... → finished也就是说,请求不是执行一次就结束,而是会在系统中停留很多轮。每一轮 decode 通常只生成一个 token,然后继续进入下一轮。
如果用户让模型生成 200 个 token,那么这个请求就会经历大约 200 次 decode step。
这意味着,LLM 服务面对的不是一批短生命周期请求,而是一组持续变化的生成任务。
Static Batching 的问题
假设系统里有三个请求:
text
请求 A:prompt 100 token,要生成 200 token
请求 B:prompt 20 token,要生成 30 token
请求 C:prompt 500 token,要生成 100 token如果使用传统 static batching,把 A、B、C 固定成一个 batch,一起开始、一起结束,就会遇到几个问题:
text
短请求 B 很快结束,但 batch 里还有 A 和 C
新请求 D 到达时,无法立刻加入当前 batch
不同请求生成长度不同,batch 内部会产生浪费
GPU 资源可能无法被持续填满这种模式对于自回归生成并不合适。
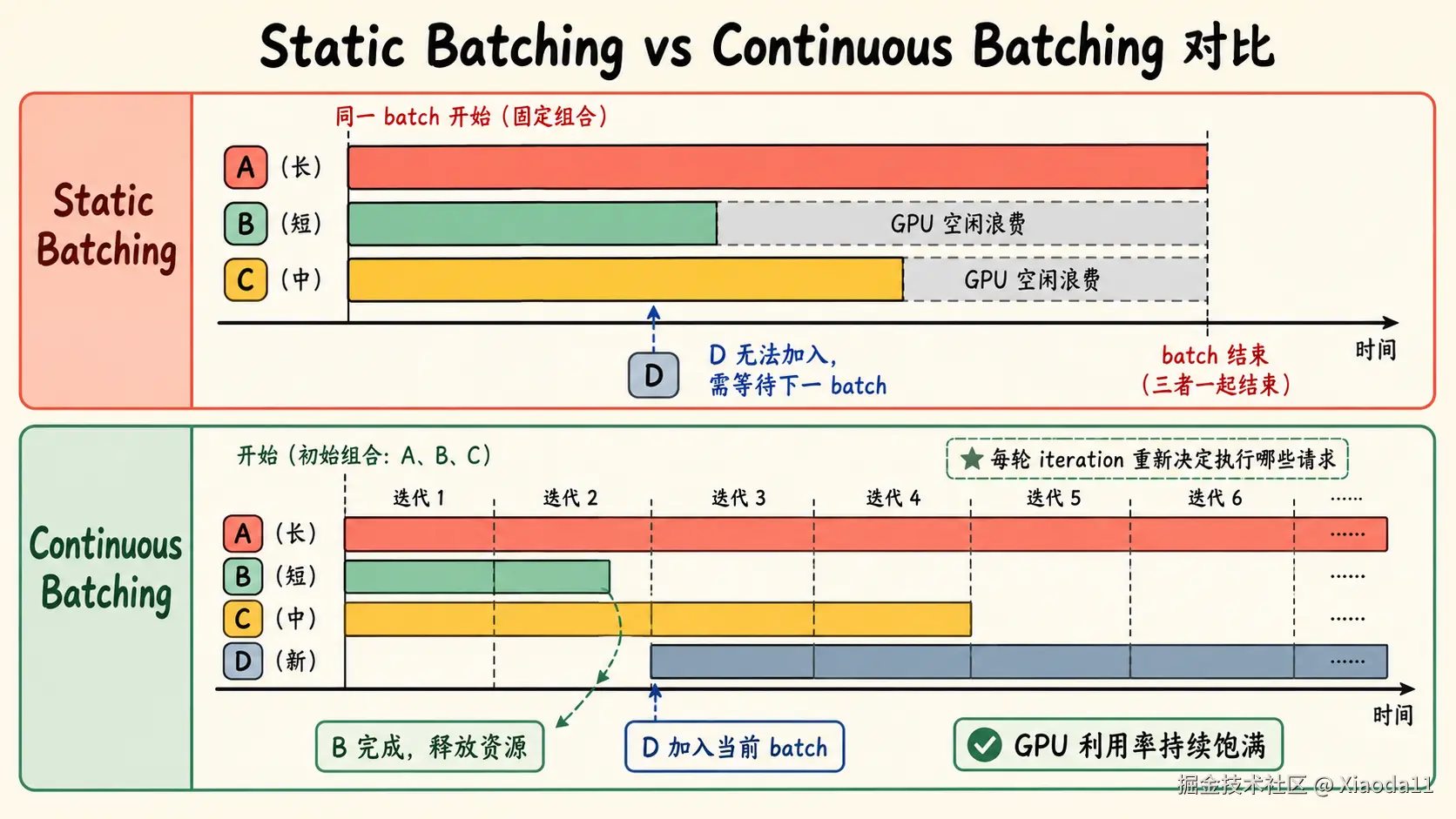
LLM 推理更需要的是:
每一轮生成时,都重新决定这一轮应该执行哪些请求。
这就是 iteration-level scheduling 的直觉,也是 Continuous Batching 的基础。
2. Prefill 和 Decode 的调度特征不同
要理解 Scheduler,必须先从调度角度重新看 Prefill 和 Decode。
这两个阶段不只是模型计算流程不同,它们对系统资源的需求也不同。
Prefill:大块计算,影响 TTFT
Prefill 处理的是用户输入的整段 prompt。
如果 prompt 很长,prefill 一次就可能处理几百甚至几千个 token。它的特点是:
text
输入 token 多
计算量大
通常并行度较高
会生成整段 prompt 的 KV Cache
主要影响 TTFTTTFT,也就是 Time To First Token,表示用户发出请求后,到系统返回第一个 token 的时间。
从用户体验看,prefill 越慢,用户看到第一个 token 的时间就越晚。
所以 prefill 更像一个"大任务"。
Decode:小步循环,影响 TPOT
Decode 阶段每一轮通常只为每个请求生成一个新 token。
它的特点是:
text
每轮 token 少
需要反复执行很多轮
每一轮都要读取历史 KV Cache
主要影响 TPOTTPOT,也就是 Time Per Output Token,表示后续每生成一个 token 的平均时间。
Decode 更像很多个"小任务"不断循环。
调度的矛盾
Scheduler 需要同时处理这两类任务。
如果系统过度偏向 prefill,长 prompt 请求可能一次性占用大量计算资源,导致已经在 decode 的请求等待时间变长,TPOT 抖动。
如果系统过度偏向 decode,新来的请求可能迟迟无法完成 prefill,TTFT 变差。
所以调度器要平衡的是:
text
新请求的 TTFT
已有请求的 TPOT
整体吞吐
KV Cache 显存资源
每一轮计算规模这就是为什么 vLLM 需要专门的 Scheduler,而不是简单地把所有请求塞进模型执行。
3. Continuous Batching:动态维护 batch
Continuous Batching 可以理解为:
不把一组请求固定绑定到一起,而是在每一轮推理 iteration 中动态维护 batch。
普通 static batching 是:
text
一批请求一起开始,一起结束。Continuous Batching 是:
text
完成的请求可以退出;
新来的请求可以加入;
还没结束的请求继续生成。一个简化例子:
text
Step 1: A, B, C 一起执行
Step 2: B 结束,A, C 继续
Step 3: 新请求 D 加入,A, C, D 一起执行
Step 4: C 结束,新请求 E 加入,A, D, E 一起执行这样做的好处是,系统不要求所有请求"同生共死"。
短请求结束后,可以及时释放位置;新请求到达后,也有机会进入后续 iteration。GPU 可以更持续地获得可执行任务,整体吞吐更高。
Continuous Batching 优化了什么
Continuous Batching 最直接优化的是 GPU 利用率和吞吐。
在低并发场景下,GPU 经常吃不满。尤其 decode 阶段每个请求每轮只生成一个 token,如果 batch 太小,很容易出现计算资源利用不足。
当并发请求增加,并且 scheduler 能够动态维护 batch 时,每一轮模型执行中可以包含更多请求,GPU 更容易被填满。
所以 Continuous Batching 的核心价值不是让单个请求的每一步都更快,而是提高系统整体处理请求的能力。
可以简单理解为:
text
单请求速度:不一定显著提升
系统吞吐:通常明显提升
GPU 利用率:更容易提高4. Scheduler 在每一轮到底决定什么
从高层看,Scheduler 每一轮要回答一个问题:
当前这一轮,哪些请求可以进入模型执行?
为了回答这个问题,它需要同时看请求状态、显存资源和本轮预算。
waiting / running / finished
一个请求进入系统后,通常可以粗略理解为几种状态:
text
waiting:已经到达,但还没有被真正执行
running:已经进入系统,正在 prefill 或 decode
finished:已经生成结束,或者被取消Scheduler 每一轮会从 waiting 和 running 请求中选择一部分进入执行。
waiting 请求可能需要先做 prefill。
running 请求可能已经完成 prefill,正在进行 decode。
finished 请求需要退出,并释放相关资源。
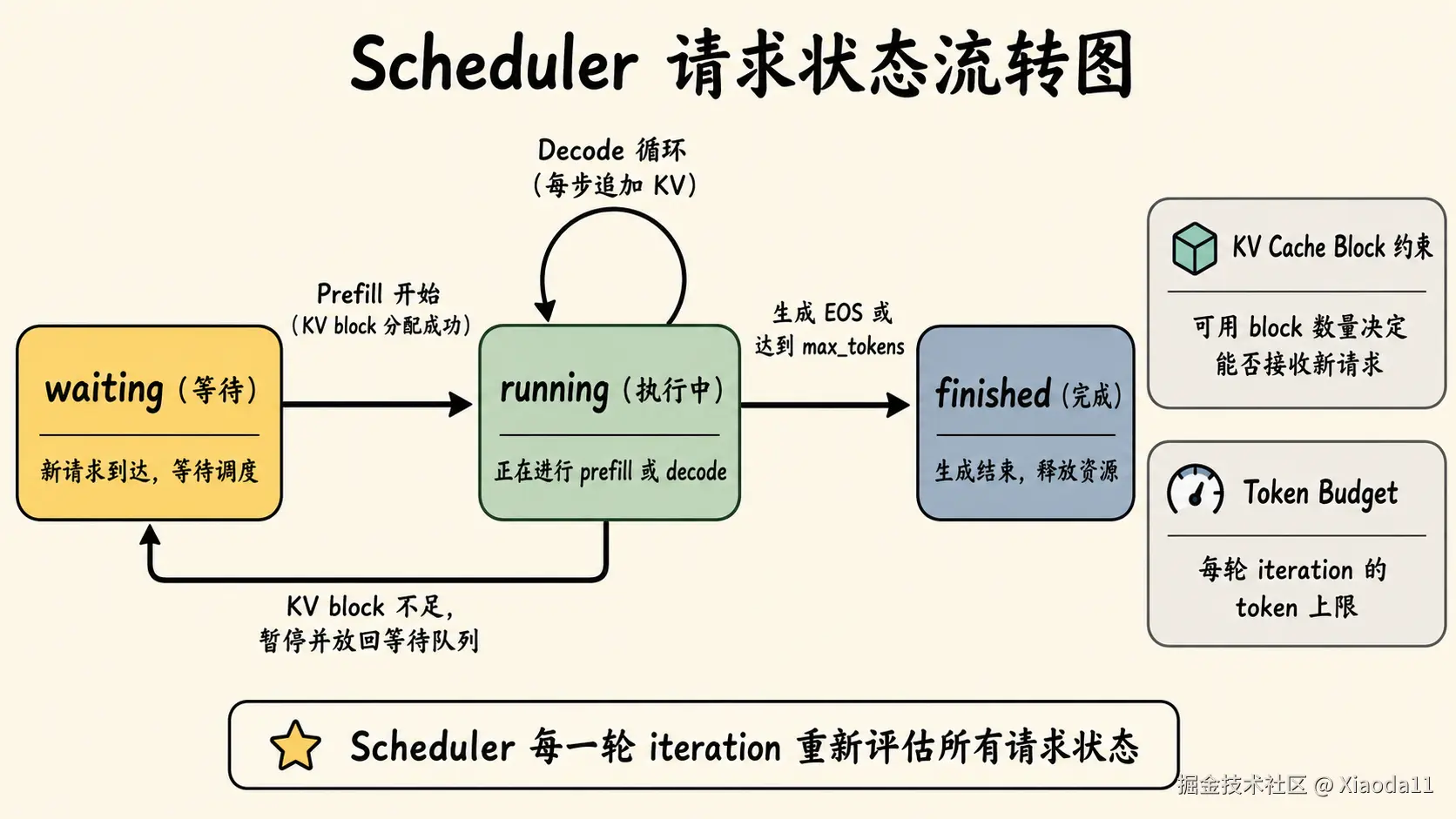
KV Cache 资源约束
调度器不能只看计算,还要看 KV Cache 显存是否够用。
因为请求一旦进入 prefill,就需要为 prompt token 分配 KV Cache。之后每生成一个新 token,也要继续追加新的 KV。
如果 KV Cache block 不够,系统就不能无限制接收新请求。
所以 Scheduler 的选择会受到 block manager / KV cache manager 的约束:
text
当前还有多少可用 KV block?
新请求 prefill 需要多少 block?
running 请求继续 decode 还需要多少 block?
如果资源不够,哪些请求需要等待?这也是 LLM 推理系统和普通后端服务不一样的地方:请求调度和显存管理是强绑定的。
Token Budget
Token budget 可以理解为:
每一轮调度最多允许处理多少 token。
它存在的原因,是 prefill 和 decode 的 token 数量差异很大。
比如一轮里可能有:
text
一个长 prefill 请求:1000 个 prompt token
十个 decode 请求:每个 1 个 token如果不做限制,长 prefill 可能一次性占用大量计算资源,导致 decode 请求等待时间变长。
token budget 的作用,就是控制单轮工作量,避免某一类请求把资源全部吃掉。
它可以帮助 Scheduler 在 TTFT、TPOT 和吞吐之间做平衡。
5. Prefill 和 Decode 如何混合调度
真实系统里,Scheduler 很少只面对单一类型请求。
它通常同时面对:
text
刚来的 waiting 请求,需要 prefill
已经 running 的请求,需要 decode
资源不足而等待的请求
即将 finished 的请求这就带来一个问题:
一轮里到底应该多放 prefill,还是多放 decode?
只做 Prefill 的问题
如果一轮里大量执行 prefill,尤其是长 prompt prefill,会让新请求更快获得首 token,但可能影响已经在 decode 的请求。
用户已经开始看到输出后,如果后续 token 间隔突然变长,体验会变差。
这会体现为 TPOT 抖动,甚至 p95 / p99 延迟变差。
只做 Decode 的问题
如果系统一直优先 decode,那么已经进入生成阶段的请求会比较稳定,但新请求可能一直排在 waiting 队列里。
这样 TTFT 会变差,用户迟迟看不到第一个 token。
混合调度的本质
所以 prefill / decode 混合调度的本质是:
在新请求响应速度和已有请求生成稳定性之间做权衡。
vLLM 这类系统会通过调度策略、token budget、chunked prefill 等机制,控制每一轮 prefill 和 decode 的比例。
后续理解 Chunked Prefill 时,也可以从这个角度出发:
长 prefill 太大,会影响 decode;所以把长 prefill 拆成更小的 chunk,让它更容易和 decode 交错执行。
6. Scheduler、Block Manager 和 Attention Kernel 的关系
Scheduler 不是孤立工作的。
在 LLM 推理系统里,它通常要和 KV Cache 管理、block table、attention kernel 配合。
可以把它们的关系粗略理解成:
text
Scheduler:决定这一轮哪些请求执行
Block Manager:为这些请求分配和释放 KV block
Block Table:记录每个请求的逻辑块到物理块的映射
Attention Kernel:根据 block table 读取对应 KV,完成 attention 计算这也是 vLLM 设计里很重要的一点:
调度不是单纯的请求队列问题,它会直接影响 KV Cache 的分配方式和 attention 的执行方式。
如果没有 PagedAttention 和 block table,动态调度会更难做。因为每个请求的 KV 长度不同、存储位置不同,batch 内部会非常不规则。
PagedAttention 让 KV Cache 可以以 block 为单位管理,Scheduler 才能更灵活地处理不同长度、不同状态的请求。
所以在后面看 vLLM 源码时,不能把 Scheduler、Block Manager、PagedAttention 分开理解。它们本质上是在共同解决一个问题:
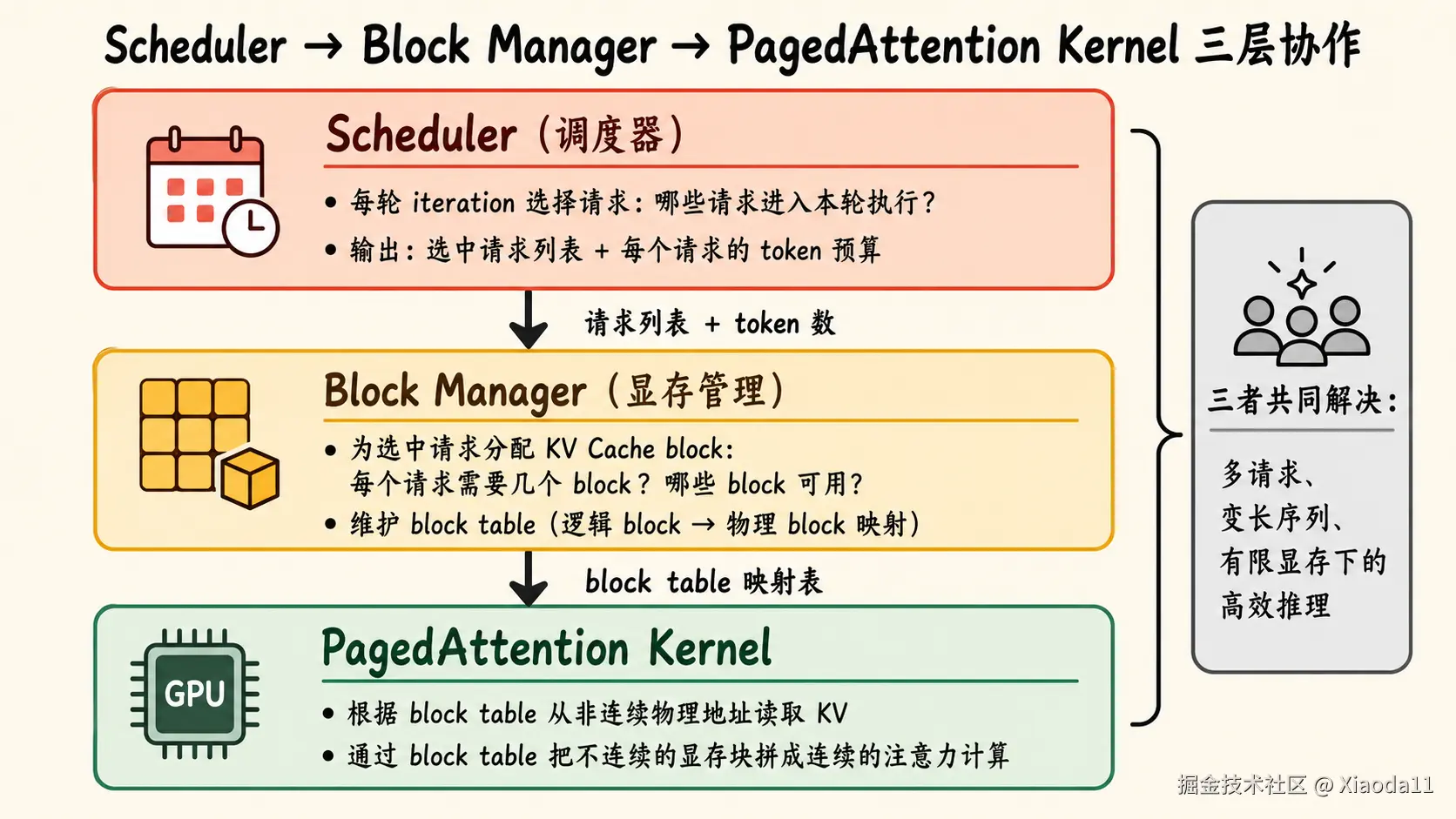
如何在多请求、变长序列、有限显存的情况下,让 LLM 推理持续高效地运行。
7. 总结:Scheduler 是推理系统的流量控制器
LLM 推理服务和普通模型服务最大的区别之一,是请求会长期停留在系统中,并且不断参与后续 decode。
Scheduler 的核心作用,是在每一轮推理 iteration 中决定哪些请求进入执行。
它需要同时考虑:
text
请求状态:waiting / running / finished
计算特征:prefill 大块计算,decode 小步循环
性能目标:TTFT、TPOT、吞吐、p95 / p99
显存资源:KV Cache block 是否足够
调度预算:每轮 token budgetContinuous Batching 则是在这个调度框架下,让 batch 不再固定,而是动态变化。完成的请求退出,新请求加入,running 请求继续生成。
这样可以提高 GPU 利用率和整体吞吐,也让 LLM Serving 更适合真实在线服务场景。
后续继续阅读 vLLM 源码时,可以沿着这几个问题往下看:
text
请求如何进入 waiting 队列?
running 请求如何继续 decode?
Scheduler 如何计算本轮 token budget?
Block Manager 如何判断 KV block 是否足够?
Scheduler 输出如何传给模型执行层?
PagedAttention 如何根据 block table 读取 KV?理解了 Scheduler,再去看 KV Cache、PagedAttention、Prefix Cache 和 Chunked Prefill,会更容易建立整体感。
一句话串讲 vLLM Scheduler
如果要用一段话把 Scheduler 这条链路串起来:
LLM 推理请求不是一次 forward 就结束,而是在 prefill 之后进入多轮 decode,因此系统需要在每一轮 iteration 中重新决定哪些请求进入执行。vLLM Scheduler 的作用,就是根据请求状态、KV Cache 资源、token budget 以及 prefill / decode 的计算差异,从 waiting 和 running 请求中选择合适的一批请求执行。
Continuous Batching 的核心思想是动态维护 batch:完成的请求可以退出,新来的请求可以加入,正在生成的请求继续 decode。这样可以避免 static batching 中短请求被长请求拖住、新请求无法加入的问题,让 GPU 在多请求场景下更容易保持高利用率。
因此,Scheduler 不只是一个简单队列,而是 LLM 推理系统里的流量控制器。它一边影响 TTFT、TPOT、吞吐和 p95 / p99 延迟,一边又受到 KV Cache block、显存资源和每轮 token budget 的约束。理解 Scheduler,是继续理解 PagedAttention、Prefix Cache 和 Chunked Prefill 的前提。