内容参考于:图灵AI大模型全栈
llamaIndex中有一个全局配置,当我们没有指定模型的时候它会使用全局配置中设置的模型
效果图:
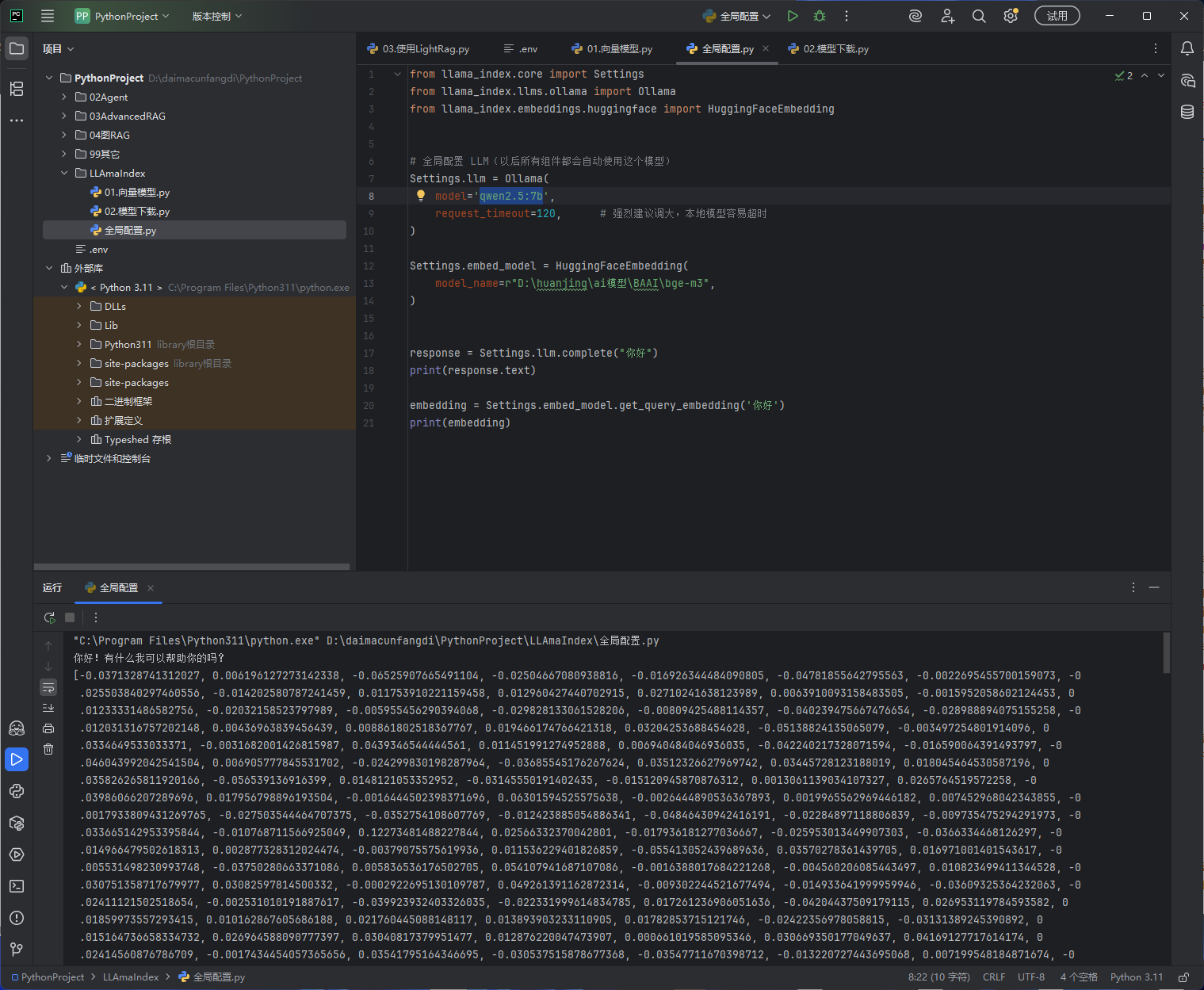
代码
python
# 导入 LlamaIndex 的全局配置对象 Settings
# 核心作用:LlamaIndex 的全局单例配置中心,统一管理大模型、嵌入模型、文本切分等全局参数
# 设计逻辑:一次配置后,后续所有组件(索引、查询引擎、文档加载器等)都会自动复用这里的配置
# 不用每个组件都单独初始化模型,避免重复加载、代码冗余,切换模型也只需要改一处
from llama_index.core import Settings
# 导入 Ollama 本地大模型适配类
from llama_index.llms.ollama import Ollama
# 导入 HuggingFace 本地嵌入模型适配类
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# ========== 全局配置大模型 ==========
# 把初始化好的 Ollama 模型赋值给 Settings.llm
# 效果:全局生效,之后所有需要调用大模型的地方(生成回答、总结、提取等)都会自动用这个模型
# 不用再给每个组件单独传 llm 参数,代码更简洁,配置统一
Settings.llm = Ollama(
model='qwen2.5:7b', # 指定本地运行的模型名称
request_timeout=120, # 请求超时时间,单位秒
# 强烈建议调大:本地模型生成速度慢,默认超时短很容易中途报错
)
# ========== 全局配置嵌入模型 ==========
# 把初始化好的本地嵌入模型赋值给 Settings.embed_model
# 效果:全局生效,之后文档入库生成向量、查询生成问题向量,都会自动用这个模型
# 保证入库和查询用的是同一个嵌入模型,向量维度一致,检索不会出问题
Settings.embed_model = HuggingFaceEmbedding(
# 本地模型文件路径,指向提前下载好的 bge-m3 模型文件夹
model_name=r"D:\huanjing\ai模型\BAAI\bge-m3",
)
# ========== 测试:调用全局大模型 ==========
# 直接通过 Settings.llm 调用大模型,验证全局配置是否生效
# complete 是单轮补全接口,输入文本直接返回回答
response = Settings.llm.complete("你好")
# 取回答的纯文本内容并打印
print(response.text)
# ========== 测试:调用全局嵌入模型 ==========
# 直接通过 Settings.embed_model 生成查询向量,验证嵌入模型配置是否生效
embedding = Settings.embed_model.get_query_embedding('你好')
# 打印生成的向量数组
print(embedding)