摘要
工业物联网的"最后一公里",不在云端,而在现场。一个被长期忽视的事实是:工业现场真正决定业务成败的那部分计算------轴承振动的频域诊断、产线异常的毫秒级捕获、地震波形的实时识别------一旦依赖云端往返,就注定赶不上事件发生的速度。带宽、断连、延迟、隐私,四道现实约束把"云端集中处理"的范式牢牢挡在了工业现场之外。本文聚焦 DolphinDB 的云边协同能力,深入解读其几十 MB 的边缘端轻量化部署、云端与边缘共用同一套技术栈、边缘库内信号处理与异常检测、脚本规则云端下发与异步复制、以及边缘库内 AI 推理等核心技术,展示 DolphinDB 如何让工业智能从"云端排队"真正下沉到"边缘上岗"。结合电力 SCADA 监测、大型水电枢纽、地震台网、车联网等真实落地场景,探讨工业物联网从"中心化集中计算"走向"边缘就地智能 + 云端全局协同"的演进路径。
一、引言:被"网络焦虑"支配的工业现场
在我走访过的多个工业项目中,有一个场景反复出现,却很少被认真讨论:厂区的网络又断了。
某钢铁企业的设备监控大屏上,关键参数突然变成一片灰色------厂区到云端数据中心的专线发生了抖动,数据上不去,分析结果下不来。运维工程师一边打电话催运营商,一边无奈地补一句:"这种情况一个月总要来几次,下雨天、施工挖断光纤、设备老化,哪一样都能让我们的'智能监控'变成'智能瞎子'。"
这不是个案,而是工业现场最真实、最普遍的日常。在能源电力、石油化工、车联网、智能制造等领域,"网络可靠"在很多场景下是一种奢望,而不是默认前提。
一组被反复引用的数据可以说明问题的普遍性:一个大型水电站部署了超过 200 万个传感器测点,每日产生数百亿行数据;一个新能源汽车品牌的车联网平台需要承受每秒 1.8 亿测点的实时数据写入;一台高端数控机床的振动传感器,采样频率可达 10kHz。这些数据如果全部上云,带宽成本和网络延迟将成为不可承受之重。
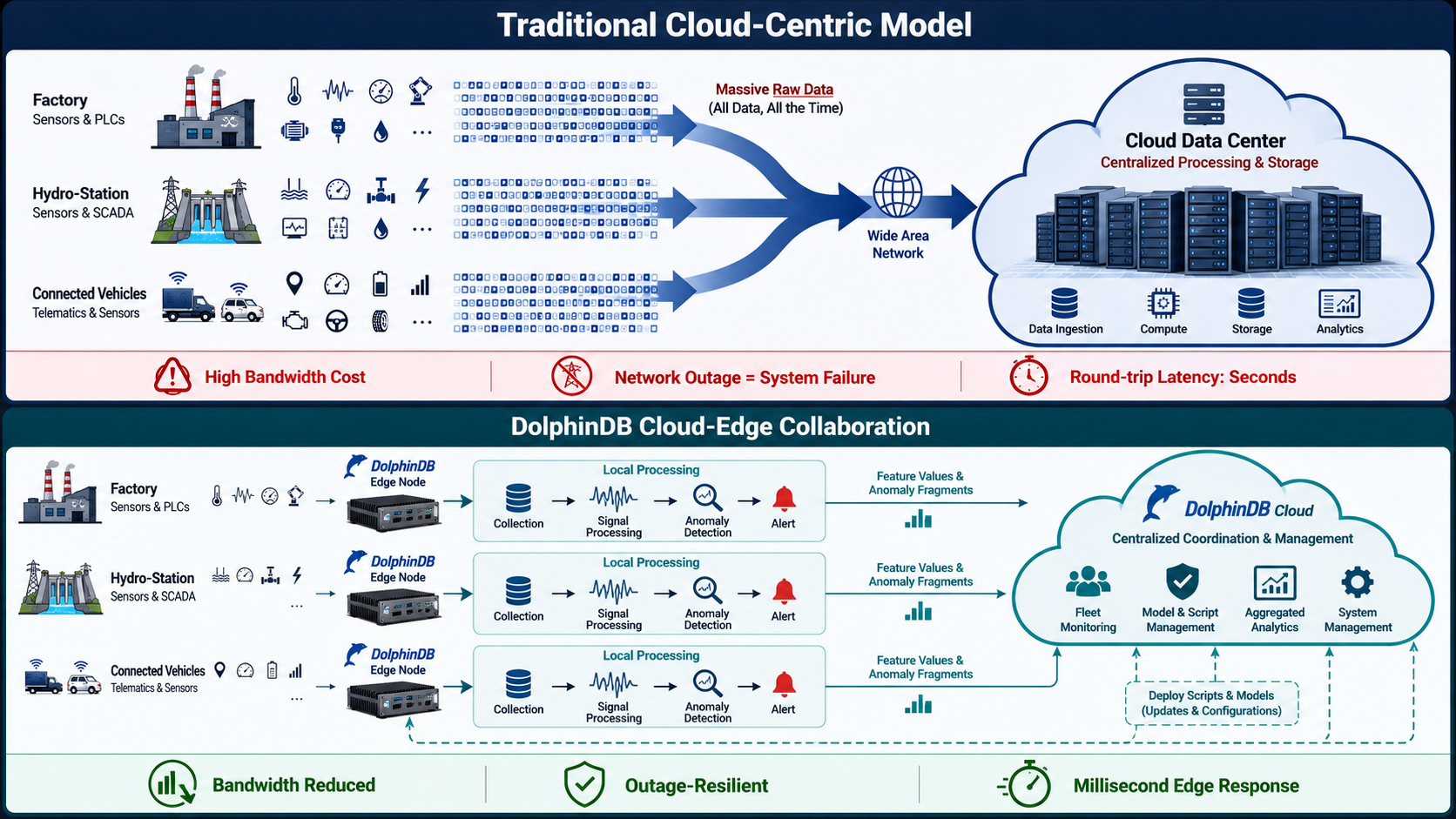
更关键的是时间。一个轴承从异常振动到彻底失效,留给系统的预警窗口可能只有几百毫秒;一次地震波从初动到破坏性震动到达,预警窗口往往只有几秒到十几秒。在这些场景中,"先把数据传到云端,再由云端算完把结果传回来"的往返模式,在物理上就不可能赶上事件本身的速度。
DolphinDB 对这一困境给出的答案,不是"把云做得更大更快",而是让计算下沉到离数据最近的地方------让智能在边缘上岗,让云端回归协同的本位。
二、边缘之困:为什么"云端集中处理"走不通?
要理解 DolphinDB 云边协同的价值,需要先看清"云端集中处理"这一范式在工业现场遭遇的四道现实约束。
2.1 约束一:带宽成本------海量数据上云的"过路费"
工业现场的传感器数据,频率高、维度多、总量大。一台振动传感器以 10kHz 采样,单点每秒就产生上万条记录;一条产线上百台设备并发,峰值写入每秒可达数十万数据点。如果将这些原始数据全部上传云端,所需的专线带宽和企业支付的流量费用都是天文数字。
以某水电企业为例,200 余万测点、每日数百亿行数据,如果全部走云端集中存储和处理,所需的跨地域专线带宽足以让任何一家企业的 IT 预算捉襟见肘。更现实的问题是,这些海量数据中真正有价值的"信号"占比极低 ------绝大多数振动数据是正常的周期性波形,只有极少量的异常片段对故障诊断有意义。把全量原始数据搬运到云端,本质上是在为"数据中的噪音"支付过路费。
2.2 约束二:网络不稳------工业现场的"断连焦虑"
消费互联网的隐含假设是"网络永远在线",但工业现场从来不具备这种奢侈条件。
厂区专线可能因为施工挖断、设备老化、极端天气而中断;车联网车辆驶入隧道、偏远山区、地下停车场时,网络连接时有时无;部署在野外的水电站、油气管道、地震监测台站,更是长期处于弱网或断网环境。在"云端集中处理"的范式下,网络一旦中断,现场的实时监控、异常预警、设备保护就全部失效------这对工业场景而言往往是不可接受的。
某电力监测设备企业的工程师曾坦言,他们早期尝试过"振动数据全量上云"的方案,结果在一次厂区网络故障中,关键轴承的异常特征数据被困在本地缓冲区里没能及时上传,等到网络恢复时,设备已经出现了不可逆的损伤。"从那以后我们就明白了一件事:在工业现场,断网不能等于失能。"
2.3 约束三:实时性------往返云端的"延迟陷阱"
工业现场对实时性的要求,往往以毫秒为单位。设备温度骤升、液压异常、振动突变,这些事件从发生到被识别再到触发保护动作,留给系统的时间窗口可能只有数百毫秒甚至更短。
在"云端集中处理"模式下,数据要经历"采集→本地缓冲→网络传输→云端接收→云端计算→结果回传→现场执行"的漫长往返链路。每一个环节都引入延迟:网络传输延迟、云端队列等待延迟、计算调度延迟、结果回传延迟。这些延迟叠加在一起,端到端响应时间往往在秒级甚至十秒级------对于工业保护场景而言,这等于"事后追溯"。
某地震台网中心的需求最能说明问题的极端性:每 10 毫秒采集一条监测记录,从波形异常出现到预警输出,必须在毫秒级内完成。如果把这条链路搬到云端,光网络往返就足以让预警窗口被消耗殆尽。在这种场景下,计算必须发生在数据产生的地方,而不是数据被搬运到的地方。
2.4 约束四:数据合规------核心数据出厂的"红线"
随着《数据安全法》《个人信息保护法》的深入实施,以及关键行业对数据自主可控要求的不断提升,越来越多的企业对"核心数据出厂"划出了明确红线。
电网的运行负荷数据、核工业的仪控监测数据、海关政务的通关数据------这些数据不仅关乎企业商业利益,更关乎国家安全和公共利益。将这类数据全量上传至公有云或异地数据中心,往往无法通过合规审查。即便采用私有云,跨地域的数据传输也面临严格的审计和审批要求。
在这种背景下,"数据就地采集、就地处理、就地存储,仅将脱敏后的特征或告警结果上传云端"成为更符合合规要求的架构选择。边缘计算不是"锦上添花",而是合规框架下的必然路径。
三、边缘之解:DolphinDB 云边协同的"轻量重装"之道
DolphinDB 对云边协同的理解,不是"在边缘端放一个阉割版的数据库",而是让边缘端和云端共享同一套技术基因------边缘端轻量到可以塞进一台工控机,强大到可以在本地完成信号处理、异常检测甚至 AI 推理;云端则承担全局汇聚、模型训练、规则下发和深度分析。两端之间,用同一套脚本、同一套函数、同一套数据模型无缝协同。
3.1 几十 MB 的边缘端:把高性能时序数据库"塞进"工控机
DolphinDB 支持在边缘端设备上一键部署,部署包大小仅几十 MB。这一数字在工业现场的意义,远不止"安装包小"那么简单。
工业现场的边缘设备,通常是资源受限的工控机、边缘网关、甚至是国产 ARM 板卡。这些设备的 CPU、内存、磁盘都极为有限,根本无法承载传统时序数据库或大数据平台动辄几个 GB 的部署包。许多企业早期尝试在边缘端部署开源时序数据库,结果要么装不上,要么装上了也跑不动------内存被吃满、磁盘被写爆、CPU 长期满载。
DolphinDB 的几十 MB 部署包,意味着它可以在一台普通的工控机上稳定运行,提供完整的存储、查询、流计算和库内分析能力。某电力监测设备企业的案例最能说明这一点------他们在为南方电网搭建边缘端 SCADA 系统时,在硬件资源极其有限的工控机上,DolphinDB 同时承担了海量振动数据的写入、降采样、异常波形录制和傅里叶/小波变换等复杂信号处理,运行稳定且延迟极低。
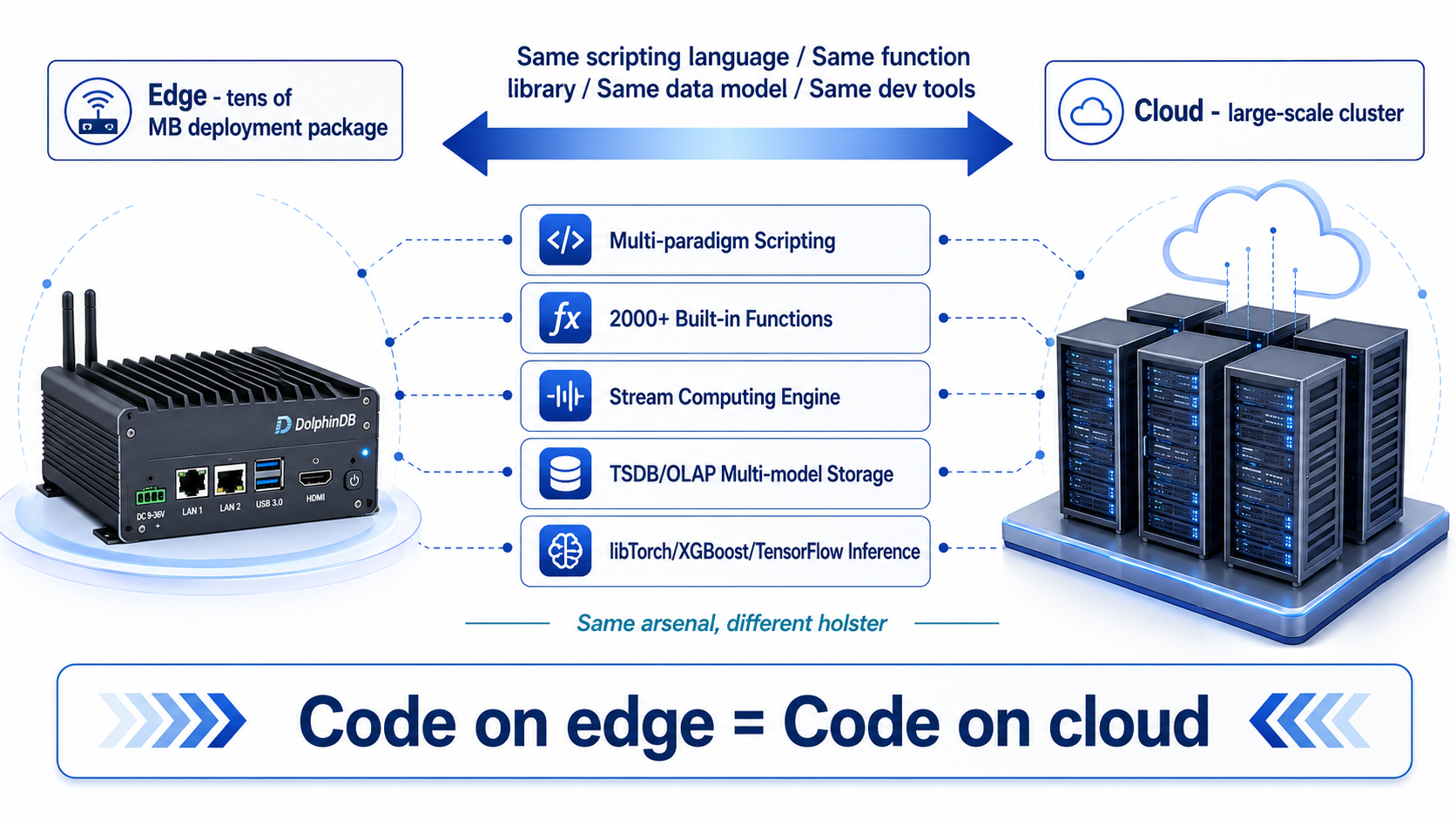
"轻量"不是"简配"------这是 DolphinDB 边缘端最值得关注的设计哲学。几十 MB 的体积背后,是一个完整的高性能时序数据库引擎,是 2000+ 内置函数,是流计算框架,是库内 AI 推理能力。边缘端拿到的是和云端同款的"武器库",只是装在了一个更小的"枪套"里。
3.2 同一套技术栈:边缘和云端共用同一份代码
云边协同最容易被忽视、却最致命的工程难题,是边缘端和云端的技术栈割裂。
在传统方案中,边缘端常用嵌入式数据库或轻量级时序库,云端用重型时序数据库或大数据平台------两端是两套完全不同的技术栈。这意味着同一个分析逻辑(比如计算设备的滑动窗口振动均值并检测异常)需要在边缘端用一种语言写一遍,在云端用另一种语言再写一遍,两套代码、两个团队、两套维护成本,结果一致性验证成为无解的难题。
DolphinDB 用"同一套技术栈"给出了根本性的解决方案:
- 同一门语言:边缘端和云端都使用 DolphinDB 的多范式脚本语言
- 同一套函数库:2000+ 内置函数在两端完全一致
- 同一套数据模型:分布式表、流数据表、多模存储引擎在两端语义统一
- 同一套开发工具:VS Code 插件、Jupyter 集成、Web 管理器在两端通用
这意味着,开发者在云端基于历史数据验证的一个分析算法,可以原封不动地下发到边缘端 ,在实时数据流上运行,且结果与云端批量计算完全一致。这正是 DolphinDB"流批一体"设计在云边协同场景下的延伸------不仅批处理和流处理共用一套代码,边缘端和云端也共用一套代码。
对于企业而言,这意味着维护成本减半:边缘端故障排查不需要专门的嵌入式工程师,云端算法迭代不需要"翻译"到边缘端。一个团队、一套技能栈,就能覆盖从边缘到云端的完整数据链路。
3.3 库内计算下放边缘:傅里叶、小波、异常检测就地完成
边缘端最核心的价值,是让复杂的计算就地完成,避免原始数据上云。但这要求边缘平台本身具备足够的计算能力------不仅仅是"存得下",更要"算得动"。
DolphinDB 的 2000+ 内置函数在边缘端完整可用,覆盖工业现场最常用的信号处理与异常检测需求:
- 信号处理函数:傅里叶变换、小波变换、滤波器、频谱分析------这些工业振动诊断的核心算法,直接在 DolphinDB 内置函数库中调用,配合 CPU 的 SIMD 指令集向量化加速,在工控机上也能实现低延时执行
- 滑动窗口与统计聚合 :
msum、mavg、mmax等时序函数,配合增量计算模式,将复杂度从 O(n) 降至 O(1),实现亚毫秒级计算延迟 - 异常检测引擎:基于规则表达式实时筛查异常数据,例如"振动幅值超过阈值且持续 3 秒以上",通过简单表达式即可定义复杂异常规则
- 降采样与插值:将高频原始数据降采样为低频特征数据,保留信号的总体特征,大幅降低数据存储和传输量
这些能力组合在一起,使 DolphinDB 边缘端可以完成"原始数据采集→信号处理→特征提取→异常检测→告警输出"的完整闭环,全程不需要将原始波形数据搬运到任何外部系统。
以某电力监测设备企业为例:振动数据在边缘端工控机内完成傅里叶和小波变换后,仅将特征值和异常波形片段上传云端,原始高频数据在本地降采样后落盘。数据上云的体积被压缩了几个数量级,而诊断的实时性反而大幅提升------因为计算不再依赖网络往返。
3.4 云边协同:逻辑下行、数据上行的双向通道
"边缘上岗"不等于"边缘独立"。工业物联网的完整价值链,仍然需要云端承担全局汇聚、历史分析、模型训练和跨站点协同的角色。问题的关键是:边缘端和云端之间,到底应该传什么?
DolphinDB 的答案是:逻辑下行,数据上行。
逻辑下行------脚本与规则云端统一下发。DolphinDB 云端脚本可以快速下发至边缘端执行。当业务逻辑发生变化时------比如异常检测阈值需要调整,或新增一个信号处理算子------管理员只需要在云端修改一次脚本,所有边缘节点自动同步最新逻辑,无需逐台设备现场维护。对于一个在多个地理位置分散部署的水电站网络而言,这种"规则统一下发"的能力,意味着运维效率的数量级提升。
数据上行------异步复制保障跨集群一致性 。DolphinDB 支持跨集群的异步复制,只需简单的参数配置即可建立多个集群之间的主从关系,以事务为单位进行数据同步,同时支持 DDL 和 DML 操作。这意味着边缘端处理后的特征数据、异常告警、降采样结果,可以事务级别的一致性保障同步到云端,进行长期存储和全局分析。
某世界 500 强企业正是利用 DolphinDB 的异步复制框架,搭建了覆盖上海、北京、深圳三地的异地多中心数据中台,集群间同步超 4000 张数据表,单表数据量最高达千亿级,百万级数据的同步延迟控制在毫秒级。这种异步复制能力同样适用于"边缘端 → 云端"的数据上行场景------边缘端是云端的数据生产者,云端是边缘端的全局汇聚者。
3.5 边缘库内推理:模型云端训练、边缘"上岗"
随着工业 AI 的深入,越来越多的预测性维护、故障诊断、工艺优化场景需要在边缘端实时运行机器学习模型。但传统架构下,模型部署到边缘端是一个工程噩梦------边缘推理服务的资源占用、版本管理、模型更新、与数据链路的对接,每一项都足以让工程团队疲于奔命。
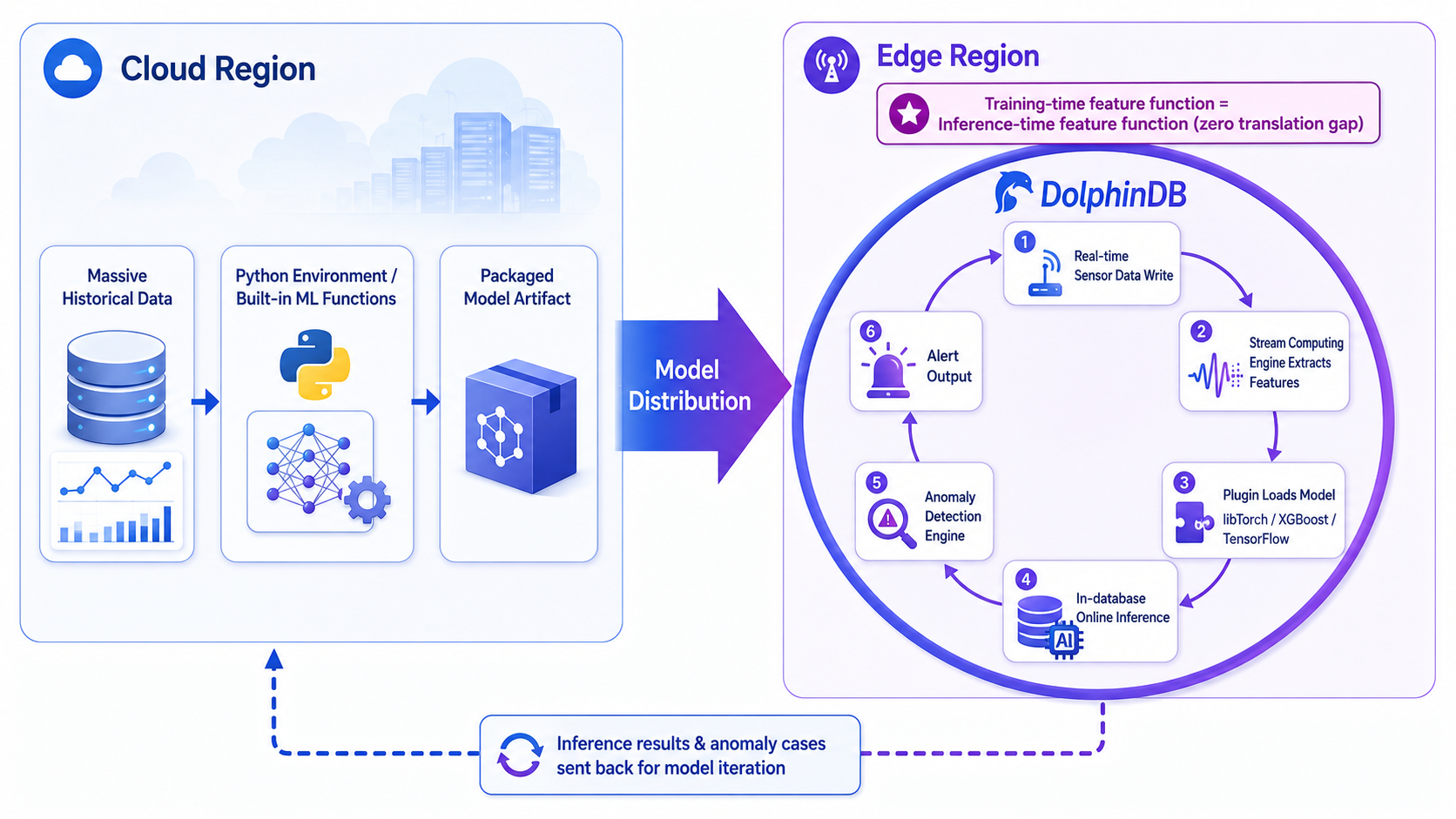
DolphinDB 给出了一个截然不同的方案:模型云端训练,边缘库内上岗。
DolphinDB 原生支持 Tensor(张量)数据格式,内置轻量化的机器学习推理模块,支持通过 libTorch(PyTorch C++ 库)、XGBoost、TensorFlow 等插件加载已训练好的模型。在云边协同架构下,整个 AI 工作流是这样的:
- 云端训练:基于云端汇聚的海量历史数据,算法工程师在云端使用熟悉的 Python 环境或 DolphinDB 内置的机器学习函数训练模型
- 模型下发:训练完成的模型作为制品(artifact),通过 DolphinDB 的云边通道下发到各边缘节点
- 边缘加载:边缘端 DolphinDB 通过插件加载模型,将模型"挂载"到流计算流水线上
- 边缘推理 :实时传感器数据写入边缘 DolphinDB 的同时,流计算引擎实时提取特征,推理模块对特征进行在线预测,预测结果触发预警规则------整条链路在边缘端进程内闭环完成
- 效果回传:边缘端的推理结果和异常案例异步同步到云端,用于模型迭代优化
这个闭环最核心的价值在于:特征计算函数在训练时和推理时是同一套 ------因为云端和边缘端共用同一套 DolphinDB 函数库,不存在"翻译差异"。这从根本上消除了工业 AI 落地中"实验室准确率高、产线效果差"的工程隐患。
3.6 国产芯片上的边缘部署:从 x86 到 ARM、LoongArch
工业现场的边缘硬件生态极为多样------既有传统的 x86 工控机,也有基于 ARM 架构的边缘网关,还有越来越多采用国产芯片的信创终端。一个边缘平台如果只能在某一种架构上运行,其适用范围将大打折扣。
DolphinDB 支持主流国产 CPU 和操作系统,包括龙芯(LoongArch)、鲲鹏、飞腾(ARM v8)、海光、兆芯等处理器架构,以及统信 UOS、银河麒麟等国产操作系统。这一点在边缘端尤为重要------许多国产化信创终端采用的是 ARM 架构或龙芯指令集,DolphinDB 的全架构适配意味着它可以在这些国产信创边缘设备上稳定运行,并保持良好性能。
更重要的是,DolphinDB 的内置函数针对不同指令集进行了向量化优化。配合 CPU 的 SIMD 指令集,在国产 ARM 架构芯片上同样能够实现高效的批量数据处理------这意味着在国产信创工控机上,傅里叶变换、小波变换这类计算密集型信号处理算法,依然可以在毫秒级内完成。
对于关键行业的国产化替代而言,这解决了一个核心痛点:国产化替代不再意味着"边缘端能力降级"。在自主可控的底座上,边缘端的实时智能能力依然可以得到完整保障。
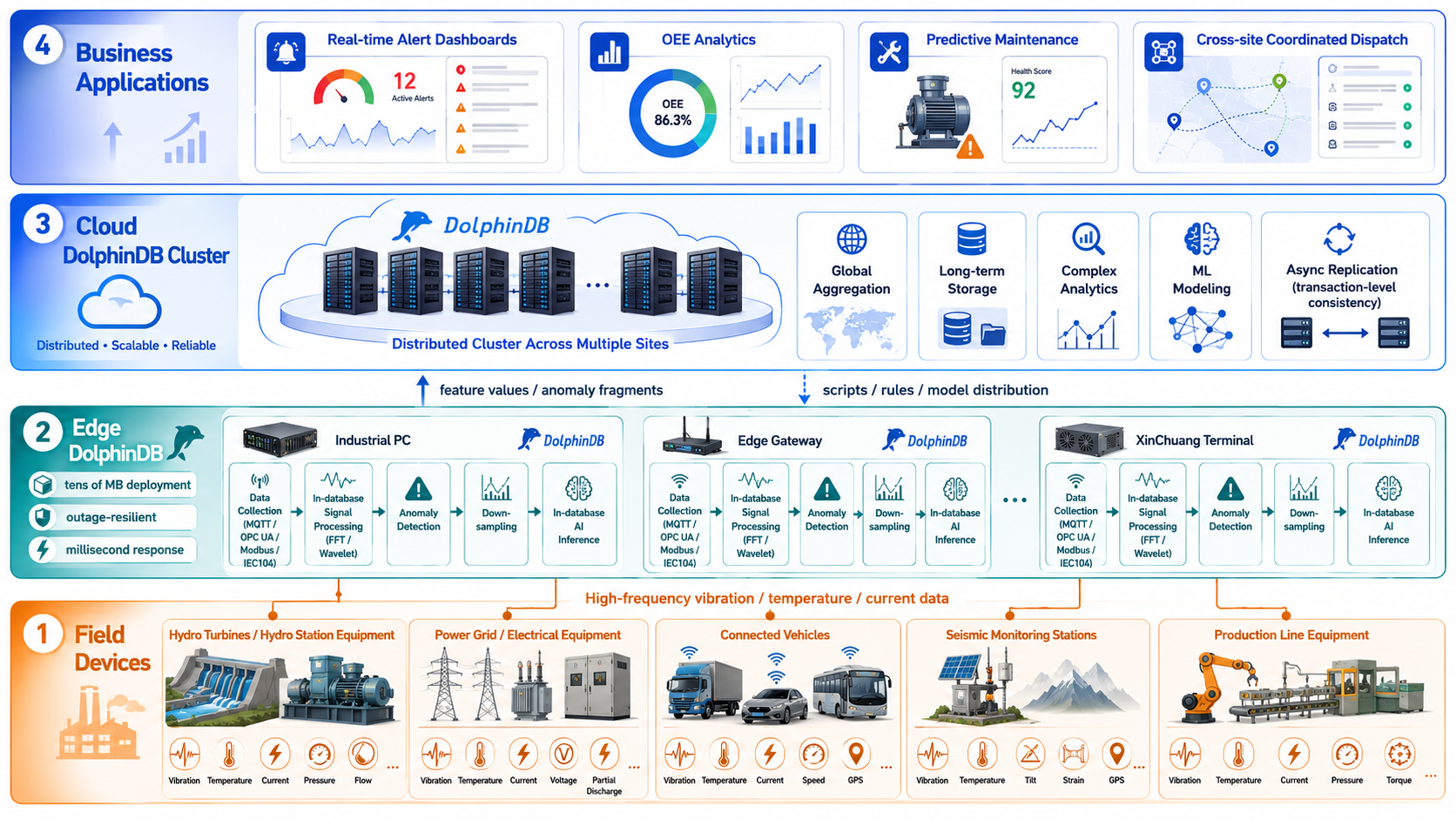
四、场景验证:真实工业现场的边缘智能实践
4.1 案例一:某电力监测设备企业------工控机上的 SCADA 边缘系统
背景:某上市企业作为电力监测设备生产商,为南方电网等电力企业提供工控机的振动监控与故障诊断服务,需要搭建边缘端 SCADA 系统。工业现场的工控机硬件资源极为有限,传统大数据方案根本无法适配。
传统方式的困境:传统方案要么将振动数据全量上传云端处理,受制于网络延迟和带宽成本;要么在工控机上部署轻量级采集程序,仅做简单的数据转发,复杂的信号处理和故障诊断全部依赖云端。无论哪种方式,都无法满足工业现场对低延时实时计算和断网容灾的双重需求。
DolphinDB 边缘方案:在工控机上部署 DolphinDB 边缘端(几十 MB 部署包),振动、声音、温度、磁通量、电流、电压等多维传感器数据通过 MQTT、Socket 等接口实时接入。流计算引擎在边缘端就地完成降采样和异常波形录制------保留信号的总体特征,同时大幅降低存储压力。傅里叶变换、小波变换等复杂的信号处理算法,由 DolphinDB 内置的 signal 信号处理函数在边缘端就地完成,无需上传云端。处理后的特征值和异常片段通过云边协同架构定时上传云端,云端进行深度分析和模型迭代。
边缘成效:
- 在硬件资源有限的工控机上实现了低延时复杂实时计算
- 傅里叶/小波等信号处理在边缘端就地完成,诊断延迟从"云端往返秒级"降至"边缘毫秒级"
- 降采样与异常波形录制大幅降低了数据存储成本和上云带宽需求
- 云边协同架构支撑了"边缘就地诊断 + 云端模型迭代"的持续优化闭环
- 即使厂区网络中断,边缘端依然可以独立完成实时监控和异常预警
这个案例最能体现"边缘上岗"的价值:在资源最受限的工控机上,DolphinDB 边缘端承担了最计算密集型的信号处理任务。云端不再是"必需品",而是"增强项"------这恰恰是工业现场最期望的架构形态。
4.2 案例二:某大型水电企业------200 万测点的云边协同统一底座
背景:该企业是中国乃至全球最大的水电上市公司,拥有多个水电站,各电站地理位置分散,200 余万测点每日产生数百亿行数据。原有基于单机实时数据库的架构,导致各电站数据孤立、分散、封闭,无法有效同步与集中存储。
传统方式的困境:若采用"全量数据集中上云"的方案,跨地域专线带宽成本和数据同步延迟都不可接受;若各电站独立部署监控系统,又会陷入"数据孤岛"的旧困局------云端无法做全局分析,跨电站协同调度无从谈起。
DolphinDB 云边方案:采用云边协同架构,在各水电站边缘侧部署 DolphinDB 节点进行数据预处理------包括 ETL、降采样、特征计算、实时预警。云端节点进行全量数据汇聚、长期存储、复杂分析和机器学习建模。依托 DolphinDB 的分布式能力,不同设备数据得以集中存储。云端开发的脚本可快速下发至各边缘节点,实现"规则统一下发、数据按需上行"的协同架构。
边缘成效:
- 关键设备故障预警延迟从"分钟级"压缩至"毫秒级"------预警在边缘端就地完成,不依赖云端往返
- 多源数据关联查询响应从分钟级缩短至秒级
- 复杂分析任务处理效率提升 5-6 倍
- 各电站边缘节点独立运行,网络故障不影响本地实时监控
- 云端汇聚全局数据,支撑跨电站的协同调度和深度分析
- 为大型水电枢纽的安全运转和调度提供了坚实的数据保障
这个案例展示了云边协同在大型分布式工业场景中的核心价值:边缘端负责"快"------毫秒级预警、本地化处理;云端负责"全"------全局汇聚、深度分析、模型迭代。两者分工明确,又通过同一套技术栈无缝协同。
4.3 案例三:某地震台网中心------10 毫秒级波形的边缘预处理
背景:该中心每 10 毫秒采集一条地震监测记录,每个通道以 3 秒为单位将采集到的监测记录封装成 MiniSeed 文件发送到台网中心,需要构建包含地震预警、地震速报、地震烈度速报等多个模块的综合处理系统。
传统方式的困境:地震预警是对实时性要求最极端的场景之一------早 1 秒预警,就可能挽救生命。如果 MiniSeed 文件全量上传到远端中心集中处理,网络传输和排队延迟足以让预警窗口被消耗殆尽。同时,全国数十上百个台站的原始波形数据全量汇聚,对中心节点的存储和算力都是巨大压力。
DolphinDB 边缘方案 :在台网中心构建基于 DolphinDB 的地震波形分析预警架构。MiniSeed 文件通过内置插件直接解析为结构化数据;数据采用时间 + ID 组合分区列式存储,多线程并行操作。流计算引擎以毫秒级延迟实时处理波形数据,内置的 FilterPicker 插件完成异常检测、RTSeis 插件完成实时分析、TensorFlow 插件加载深度学习模型进行预测。整套架构可以下沉到台站边缘侧------在台站本地完成波形解析、特征提取、异常筛查,仅将候选异常事件上传中心做最终判定和联合定位。
边缘成效:
- 毫秒级计算响应延时------从波形数据输入到异常检测到预测预警,全流程在库内闭环
- 数据分区列式存储配合 lz4、delta 压缩算法,大幅节约硬件资源
- AI 模型推理通过 TensorFlow 插件在库内直接运行,无需数据导出
- 边缘预处理后仅上传候选事件,中心节点算力和存储压力大幅降低
- 全流程效率显著提升
这个案例最能说明"边缘预处理 + 中心协同"在极端实时场景下的不可替代性:地震预警这种生死攸关的场景,计算必须发生在离波形数据最近的地方。 DolphinDB 的库内信号处理 + 库内 AI 推理能力,让边缘台站具备了过去只有大型中心才具备的智能分析能力。
4.4 案例四:某新能源车企------1.8 亿点/秒下的车端与云端协同
背景:该车企单车测点达 7000,每秒 1.8 亿测点的不间断写入,需要搭建高性能的车辆信息监控与分析系统,支撑车辆安全监控和产品优化。
传统方式的困境:车联网数据天然具有"边缘分散"的特征------每辆车都是一个独立的移动边缘节点。如果所有原始数据全量上传云端,不仅流量成本惊人,而且在车辆驶入弱网区域时数据会大量丢失或延迟。云端集中处理还面临巨大的写入压力和实时计算瓶颈。
DolphinDB 方案:基于 DolphinDB 构建一站式数据分析平台。在云端,DolphinDB 集群以每秒 1.8 亿点的写入速率稳定承接海量车辆数据,资源利用率保持在 40% 左右。写入过程中单点查询平均耗时控制在 100ms 以内。异常检测引擎进行毫秒级数据异常检测和告警,包含实时状态指标生成、车速偏离预警等核心模块。在车端/路侧边缘侧,DolphinDB 边缘端可以对原始车辆数据进行降采样和异常筛查,仅将关键事件和特征数据上传云端,大幅降低上云流量。
边缘成效:
- 满足每秒 1.8 亿点写入速率,写入过程中单点查询平均耗时 100ms 以内
- 毫秒级异常检测与实时告警
- 边缘端降采样与异常筛查,大幅降低弱网场景下的数据丢失风险
- 搭建了高效且轻量化的车联网大数据处理架构
- 车端与云端共用同一套 DolphinDB 技术栈,协同开发与维护成本低
这个案例展示了车联网场景下"边缘 + 云端"协同的典型形态:车辆作为移动边缘节点,在弱网或断网时依然可以本地缓冲和初步处理;云端则作为全局汇聚和分析中心。两端通过 DolphinDB 的统一技术栈无缝衔接。
五、选型思考:如何评估时序数据库的云边协同能力?
基于以上分析与案例,对于正在评估工业物联网云边协同平台的企业,我提炼出评估"云边协同能力"的六个维度。
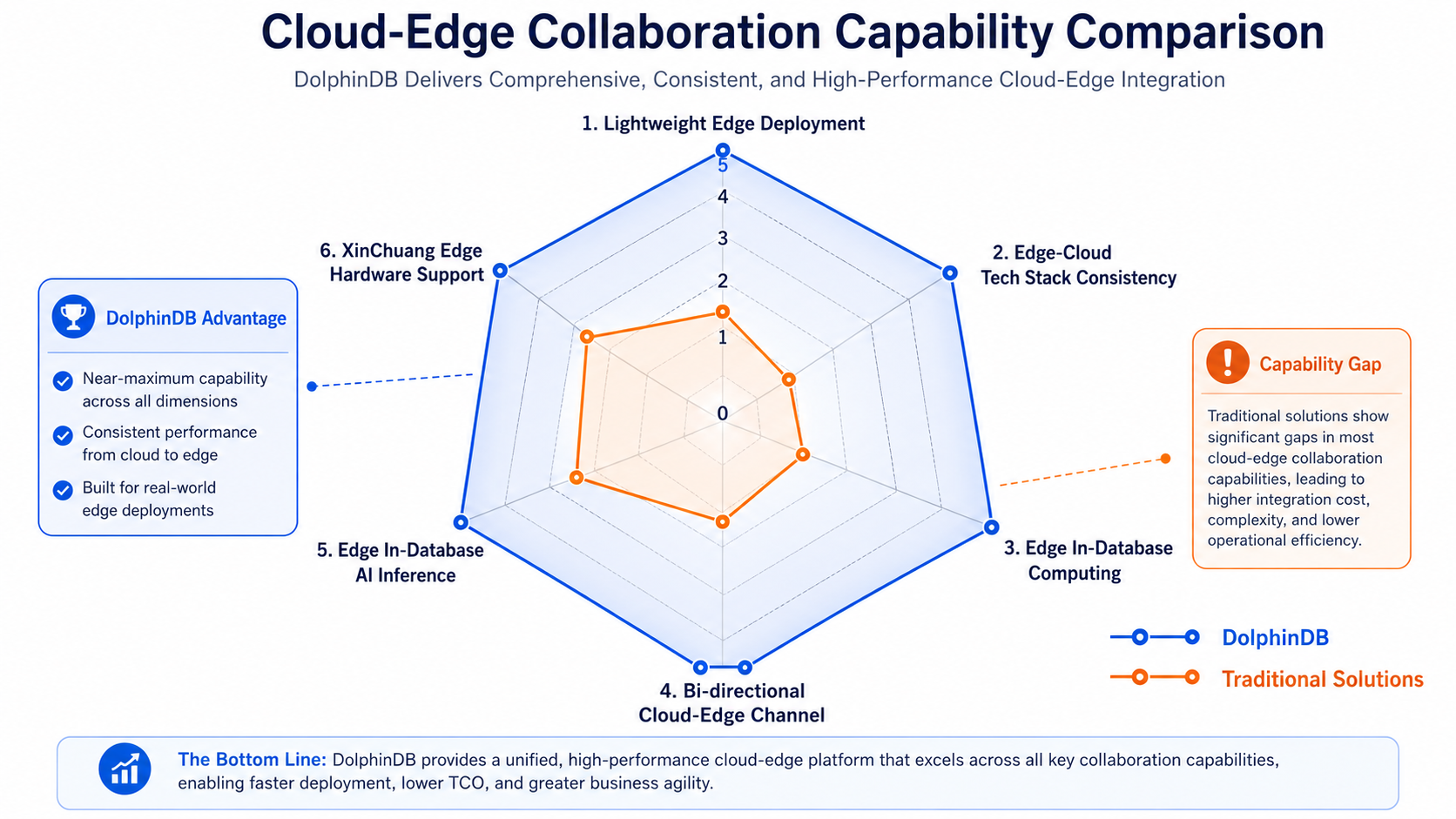
维度一:边缘端是否足够轻量? 工业现场的边缘设备往往是资源受限的工控机、网关或信创终端。如果边缘端部署包动辄数 GB,根本无法在这些设备上稳定运行。几十 MB 量级的轻量化部署,是边缘端落地的第一道门槛。
维度二:边缘与云端是否共用同一套技术栈? 如果边缘端和云端是两套完全不同的技术栈,那么同一个分析逻辑需要写两遍、维护两套、验证一致性两遍------协同成本极高。真正的云边协同,要求两端共用同一门语言、同一套函数库、同一套数据模型。
维度三:边缘端是否具备足够的库内计算能力? 边缘端不能只是"数据转发器"。如果信号处理、异常检测等复杂计算必须依赖云端,那么网络一旦中断边缘端就失去智能。丰富的内置函数和流计算引擎,是边缘端"算得动"的根本保障。
维度四:云边之间的协同通道是否双向? 单向上行的"数据汇报"不是真正的协同。真正的云边协同要求逻辑下行(脚本和规则统一下发)和数据上行(异步复制保障一致性)双向畅通。事务级别的异步复制,是大规模分布式场景下数据一致性的安全保障。
维度五:是否支持边缘库内 AI 推理? 工业 AI 的未来在边缘------模型云端训练,边缘实时推理。如果推理必须依赖云端服务,断网即失能。边缘端库内推理能力,是工业 AI 规模化落地的关键基础设施。
维度六:是否支持国产信创边缘硬件? 关键行业的边缘设备越来越多采用 ARM 架构或龙芯等国产芯片。如果边缘平台无法在这些硬件上运行,或运行后性能大幅下降,国产化替代就会卡在"边缘这一环"。全架构适配 + 深度向量化优化,是信创边缘部署的必要条件。
DolphinDB 在这六个维度上都给出了完整的答案。它不是用"边缘阉割版 + 云端完整版"的拼凑方式来满足云边协同需求,而是从架构底层就让边缘端和云端共享同一套技术基因------同一套函数库、同一套脚本语言、同一套数据模型、同一套 AI 推理能力,只是部署形态根据硬件资源做了适配。
六、结语
工业物联网的"最后一公里",从来不在云端,而在现场。
过去十年,行业把太多精力花在了"把数据搬到云端"这件事上------更大的带宽、更快的专线、更强的云中心。但当真正深入到工业现场,会发现一个被长期忽视的事实:决定工业智能成败的那部分计算,往往必须在数据产生的地方完成。 轴承振动的频域诊断、产线异常的毫秒级捕获、地震波形的实时识别------这些场景留给系统的时间窗口,根本不够一个云端往返。
DolphinDB 的云边协同路线,代表了一种值得关注的范式转变:让智能下沉到边缘,让云端回归协同的本位。 几十 MB 的边缘部署包,让时序数据库可以"塞进"工控机;同一套技术栈,让边缘端和云端共用同一份代码;库内信号处理与异常检测,让边缘端具备独立智能;脚本下发与异步复制,让两端形成逻辑下行、数据上行的双向闭环;库内 AI 推理,让模型云端训练、边缘上岗成为现实;全架构信创适配,让国产化边缘部署不再意味着能力降级。
从工控机上的 SCADA 边缘系统,到 200 万测点水电网络的云边协同,再到 10 毫秒级地震波形的边缘预处理------这些案例印证了一个事实:当计算发生在离数据最近的地方,当智能不再依赖云端往返,工业现场的实时性、可靠性和自主性才能得到真正的保障。
工业物联网的下一站,不是更大的云,而是更聪明的边缘。让数据少走路、让计算多下沉、让现场能自主------这或许就是 DolphinDB 云边协同给工业物联网最重要的启示。