还在为笔记散乱、知识无法沉淀而烦恼吗?本文从资深架构师的视角出发,深度剖析以 Obsidian 为代表的本地知识库方案。我们不仅会揭示 Obsidian 胜出的核心原因,还会带你探索如何结合本地 AI 大模型(如 Gemma、Claude)打造真正的智能助手,并对比 Tiddlywiki 等其他方案的适用场景。读完后,你将获得一套清晰的选型决策框架,告别工具选择困难症。
笔记的坟场
干我们这行的,谁的收藏夹里没几个吃灰的链接,谁的硬盘里没一堆 `Untitled.md`?从 Evernote 到 Notion,再到散落在各个项目目录下的 `README` 和笔记,我们不停地记录,却发现信息越来越乱,找个东西比登天还难。很多时候,知识不是没有,而是被埋起来了,成了一座座数字坟场。这背后的代价是巨大的:重复踩坑、重复学习、关键时刻找不到资料,最终浪费的是我们最宝贵的时间。如果你也曾被淹没在信息的海洋里,这篇文章建议先收藏,后面我们聊的选型原则,能帮你从根上解决这个问题,搭建一个真正"活"的知识库。
先说答案
别急着往下划,我先把结论给你。目前来看,对绝大多数开发者和知识工作者而言,不存在唯一的"最好"工具,但存在一个最佳的"组合范式" 。这个范式就是:以本地、纯文本(Markdown)为基石,用 Obsidian 作为中枢管理,再通过插件集成 AI 大语言模型(LLM)作为智能外脑 。为什么是这个组合?三个关键词:数据主权 、连接性 和可扩展性。你的数据永远属于你,笔记之间能织成一张知识网络,并且系统的能力边界可以无限延伸。这套组合拳,既解决了眼前的混乱,也为未来的智能化浪潮留足了空间。
王者 Obsidian
为什么社区讨论里,Obsidian 的呼声最高?因为它抓住了知识管理的核心痛点。我把它总结为三板斧:
- 本地优先,数据为王 :你的所有笔记,本质上就是你硬盘里的一个个 `.md` 文件。这意味着什么?没有供应商锁定,不用担心哪天服务商关门大吉或者修改用户协议。你可以用任何你喜欢的编辑器打开它,用 Git 做版本管理,用 `rsync` 做备份。这种安全感和掌控感,是任何云端服务都给不了的。
- 双向链接,织网成图 :这是 Obsidian 的灵魂。传统的笔记是孤岛,但通过 `\[]` 语法,你可以在笔记之间建立连接。更关键的是,它会自动生成"反向链接",让你知道"谁链接了我"。这就像从单行道升级到了城市路网,你总能发现意想不到的知识关联,让思考从线性走向网状。这才是真正的"第二大脑"。
- 插件生态,无限可能 :Obsidian 本体很克制,但它的插件社区极其繁荣。你可以把它魔改成看板工具、任务管理器、电子书阅读器,甚至是绘图工具。这种感觉就像 VS Code,一个轻量级的核心加上一个强大的扩展市场,让每个人都能把它定制成最适合自己的利器。
回归 TXT
聊到这,肯定有老哥会说:"搞那么复杂干嘛?记事本 `txt` 不香吗?" 香,当然香。我们必须承认,对于临时的、一次性的信息记录,比如一个待办事项、一个临时的 IP 地址,任何复杂的工具都是一种认知负担。追求极简,本身没错。但问题的关键在于,我们是在做"临时记录",还是在建"知识体系"? 一个 `.txt` 文件能帮你快速记下东西,但一年后,当你想找到所有关于"微服务熔断"的笔记时,它就无能为力了。知识体系的核心价值在于"沉淀"和"复用",而这恰恰需要结构、链接和可检索性。所以,别再用"战术上的勤奋"去掩盖"战略上的懒惰",合适的工具是为了让你未来更轻松,而不是消耗你。
智能涌现
如果说 Obsidian 解决了知识的"存储"和"连接"问题,那 AI 大模型解决的就是"理解"和"生成"问题。这才是 2024 年知识库玩法升级的核心。一个静态的知识库,无论整理得多好,它依然是被动的。但注入 AI 之后,它就活了,变成了一个能与你对话的智能伙伴。实现路径主要有两条:
- 云端 API :通过 Obsidian 插件,连接到 OpenAI、Claude 等服务的 API。优点是能用上最顶尖的模型,效果拔群。缺点是数据要出门,涉及隐私和安全问题,而且长期使用有成本。
- 本地 LLM :在自己的电脑上运行像 Google 的 `Gemma`、Meta 的 `Llama 3` 这类开源模型。优点是数据绝对安全,完全离线,没有额外费用。缺点是对硬件有要求(最好有张不错的显卡),模型能力相比 `GPT-4` 顶级模型有差距,且需要一点折腾精神。看到这里,建议你对照一下自己的项目和数据敏感性。很多团队想用 AI 赋能,但卡在数据安全上,本地 LLM 就是目前最可行的解法。
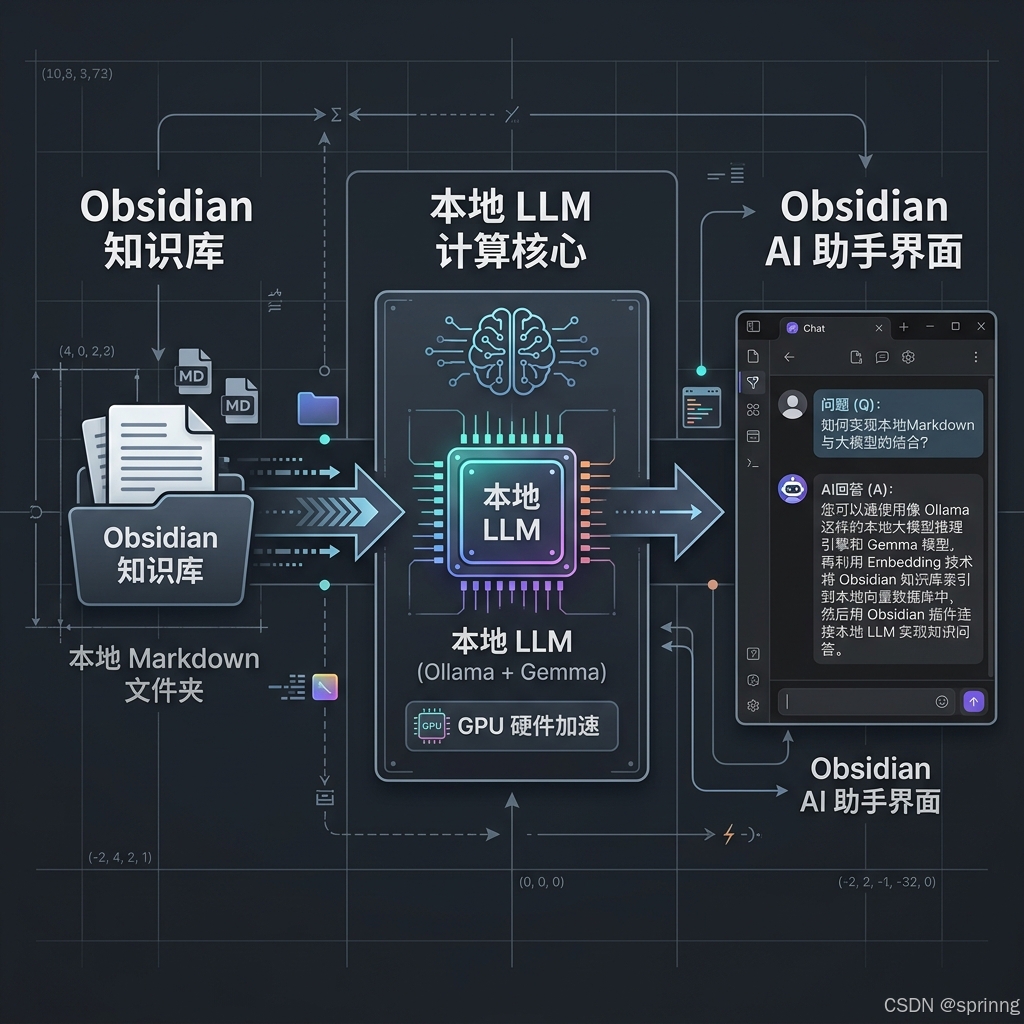
本地部署
想让你的知识库拥有"本地智慧"?其实没那么复杂。以现在非常流行的 `Ollama` 工具为例,整个流程可以简化为几步:
- 安装 `Ollama` :官网提供一键安装包,支持 macOS、Windows 和 Linux,基本是傻瓜式操作。
- 拉取模型 :打开终端,一行命令搞定。比如你想用 Google 的轻量级模型 `Gemma:2b`,就执行 `ollama run gemma:2b`。它会自动下载并运行模型,同时在本机 `11434` 端口开启一个 API 服务。
- 连接 Obsidian :在 Obsidian 社区插件市场里,搜索 `BMO Chatbot` 或类似支持自定义 Ollama 地址的插件。安装后,在设置里填入本地 API 地址(`http://127.0.0.1:11434`)并指定模型名称 `gemma:2b`。
- 开始对话 :现在,你可以直接在 Obsidian 里和一个"读过"你所有笔记的 AI 对话了。比如,选中一段代码问它"这段 Go 代码有什么优化空间?",或者直接提问"总结一下我关于 gRPC 负载均衡的所有笔记"。这种体验,是革命性的。
单文件维基
尽管 Obsidian 如日中天,但我们不能忽略一个骨灰级神器:TiddlyWiki。它的核心理念堪称惊艳------一个完整的、功能强大的个人维基,所有内容都存储在单一的 HTML 文件里。你可以把它想象成一个自带数据库、编辑器和渲染引擎的网页。它的优点是极致的便携性,你可以把这个 `tiddlywiki.html` 文件扔到任何地方------U盘、网盘、邮件附件------只要有浏览器就能打开并编辑你的整个知识库。它的定制性也极强,万物皆可为"Tiddler"(卡片)。但缺点也同样明显,学习曲线陡峭,生态相对小众,而且当知识库变得非常庞大(尤其是包含大量图片和附件时),单文件的性能和管理会成为瓶颈。它适合那些追求极致便携和高度自定义的极客用户。
更多选择
当然,世界不是非黑即白。在 Obsidian 和 TiddlyWiki 之间,还有很多优秀的选择:
- Trilium Notes :如果你更偏爱层级结构,喜欢构建像一本书或一部法典那样结构清晰的知识体系,Trilium 是个不错的选择。它更像一个自托管的个人版 Confluence,支持笔记的克隆和模板化,非常适合用来整理体系化的学习笔记或项目文档。它的后端是 Node.js,可以轻松部署在自己的服务器或 NAS 上。
- Tolaria :对于 macOS 用户,如果觉得 Obsidian 的界面有些"理工直男",想要一个更原生、更优雅的体验,可以看看 Tolaria。它是一个开源的 Markdown 知识库管理工具,专注于提供简洁流畅的写作和管理体验,虽然功能上不如 Obsidian 丰富,但胜在"小而美"。
- LLM-wiki :这是一个新兴的、将 LLM 作为一等公民的知识库方案。它不仅能帮你管理文档,还能自动为文档打标签、生成摘要、构建知识图谱。这类工具代表了未来的方向,但目前大多还处于早期阶段,成熟度有待考验。
如何选择
说了这么多,到底该怎么选?别慌,我给你准备了一份决策清单。在选择工具前,先问自己这五个问题,答案会自然浮现:
- 数据所有权有多重要? 必须 100% 掌握在自己手里,永不丢失?那就在 Obsidian、TiddlyWiki、Trilium 这些本地或自托管方案里选。
- 核心诉求是什么? 是为了激发创意、连接不同领域的知识点?那么 Obsidian 的双向链接和图谱视图是你的不二之选。还是为了系统化地组织和归档已有知识?那么 Trilium 的树状结构可能更适合你。
- 愿意花多少时间折腾? 想开箱即用,少操心?可以从简单的 Markdown 编辑器或 Tolaria 开始。享受定制的乐趣,不介意花时间配置插件和主题?那 Obsidian 的世界为你敞开大门。
- AI 是不是刚需? 如果你希望 AI 深度参与你的知识管理流程,比如自动摘要、智能问答,那么当前 Obsidian 凭借其成熟的插件生态,是集成 AI 最方便的平台。
- 对便携性的要求有多高? 是否需要在任何一台电脑上(即使是别人的), बिना任何安装就能访问和编辑你的整个知识库?如果是,TiddlyWiki 的单文件模式无可替代。
总结一下
技术圈没有银弹,知识管理也一样。我们一路走来,从简单的 `.txt`,到功能丰富的云笔记,再到掌控数据的本地知识库,如今又迎来了 AI 赋能的智能时代。工具在变,但核心原则不变:选择一个能让你真正拥有数据、并能适应你成长和变化的系统。 Markdown 纯文本是这个系统的基石,因为它足够简单、足够开放、足够持久。Obsidian 是现阶段这个基石上最好的"操作系统"之一。而本地 AI,则是你未来可以随时安装的"超级应用"。记住,工具是手段,不是目的。搭建知识库的最终目标,是更好地思考。如果这篇文章帮你理清了思路,欢迎点个赞。如果你觉得这套选型方法对同事或团队也有帮助,不妨直接转发给他们。当然,如果你有更牛的本地知识库方案,或者踩过什么奇特的坑,评论区就是你的舞台,聊聊你的实战经验。