目录
- 前言
- 一、规则(Rules)与技能(Skills)
-
- [1.1 规则(Rules)](#1.1 规则(Rules))
- [1.2 技能(Skills)](#1.2 技能(Skills))
- 二、总结:如何选择与协同工作
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》《笔试算法》《AI赋能》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q ,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
这篇是对vibe coding中重要的规则和技能的详细解释
一、规则(Rules)与技能(Skills)
在第二个项目开始之前,我们先详细说一下Trae中的规则与技能,理解他们是使用Trae这个工具的重点,也是使用其他AI开发工具要必须理解的,依旧点击设置
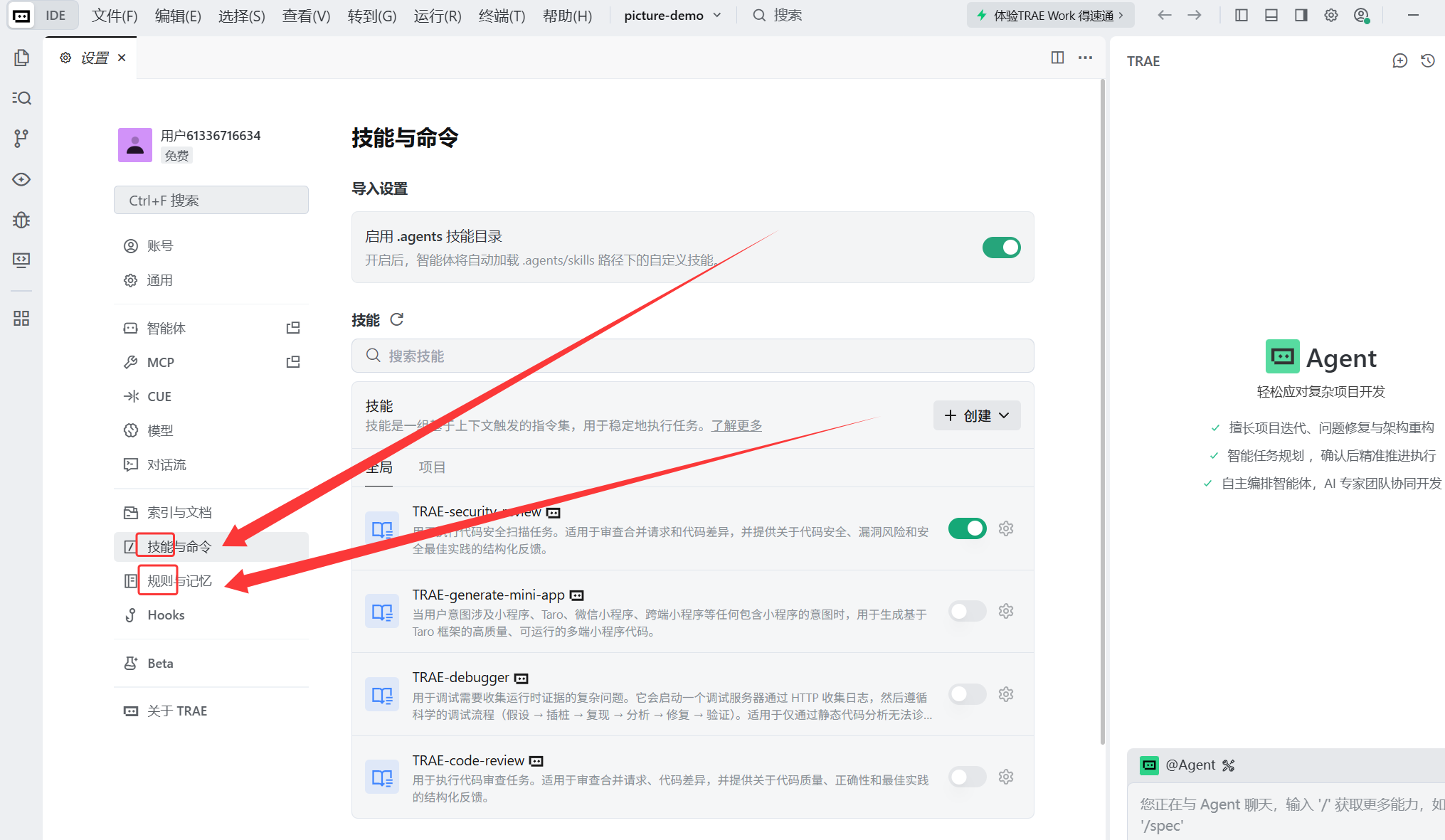
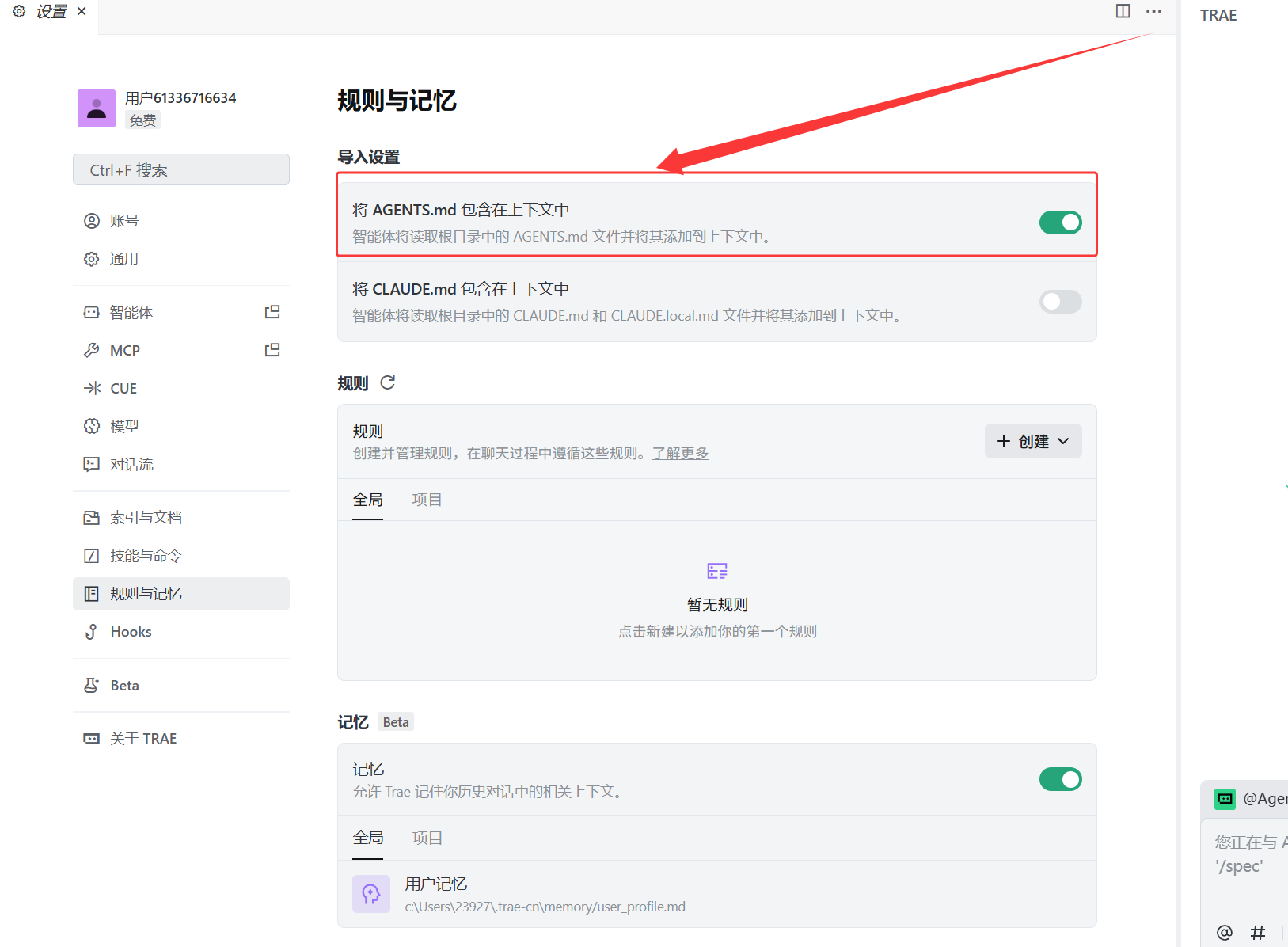
1.1 规则(Rules)
定义:规则 (Rules) 是 "契约"或 "基本法",负责强制AI"必须知道什么",定义行为边界和底层原则。
- 个人/全局规则(全局生效):作用于所有项目,用于定义个人偏好,例如"所有回复请使用中文"、"优先使用函数式编程"。
针对人:我从来不借钱给别人 - 项目规则(仅项目内生效):针对特定项目的要求,通常在团队协作中使用。例如"本项目使用Vue 3 + TypeScript"、"命名必须使用驼峰式"。
针对某个事儿的规则 - AGENTS.md:提供项目概览、常见命令等通用背景信息,同样仅在当前项目中生效,为开发流程提供标准语境
比如:
- 个人规则举例
bash
# 我的个人规则
## 1. 回答风格
- 始终使用中文回答。
- 思考的过程也是中文的。
- 回答要简洁、直接,避免冗长的背景介绍。
- 如果代码有问题,先指出问题再给出修复方案。
## 2. 代码生成规范
- 变量、函数、类名使用英文,遵循"见名知意"原则。
- 复杂逻辑(超过5行或包含嵌套)必须写注释。
- 复杂函数必须在注释中说明参数类型、返回值和主要作用。
- 优先使用函数式编程,避免不必要的类。
- 代码缩进使用 4 个空格(或你偏好的风格)。
## 3. 安全与隐私
- 不要在代码注释或日志中输出真实的密码、Token、手机号等敏感信息,用占位符代替。
- 如果用户贴出了敏感信息,主动提醒用户注意安全。
## 4. 互动习惯
- 当用户问"为什么"时,给出原理性解释,而不仅仅是结论。
- 如果用户的问题可能产生歧义,先列出假设条件再回答。在此基础上你也可以新增一些更丰富的规则,或者让AI生成一些个人规则,你挑出来复制到下图中,这样这就属于你自己的个人规则了,这样不管做任何项目,你的个人规则都会发挥作用
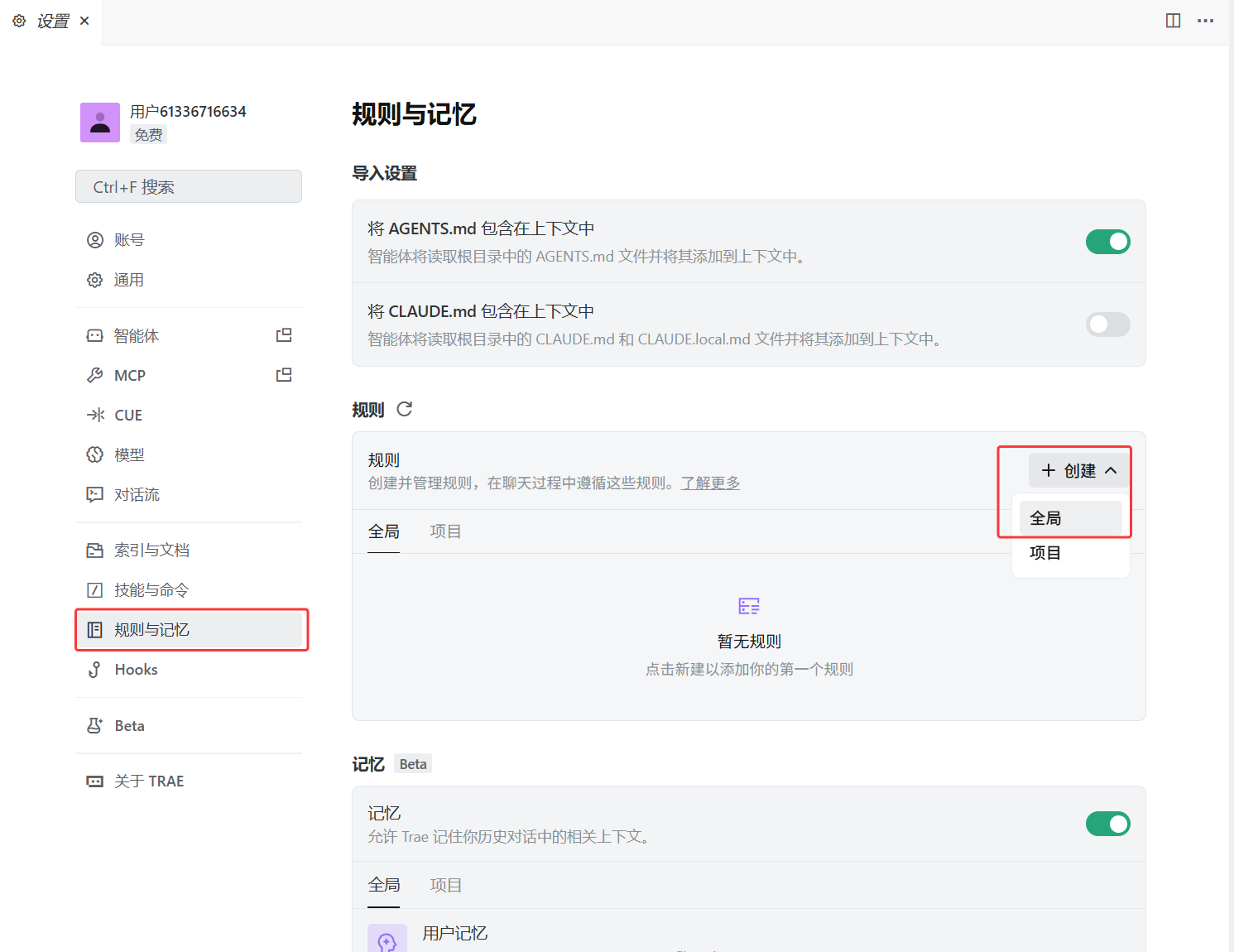
项目规则同样也是一样的,按照你的需求来给,无论给它markdown形式的还是大白话都是可以的,只是说markdown形式AI更好理解一些,也可以将大白话扔给AI让它改为markdown形式,思路要灵活,不能学死了
有时候AI也会根据自己的判断可能偶尔不会遵循你的规则,如果待会项目中发现有不遵循的地方,你就可以说检查一下代码中哪些地方没有遵循我的个人规则
且一般情况下AI也不会忽略你的rules和skills,可以来到deepseek的官网看一下产品定价,其有1M的上下文,除非你的规则多到有一本书那么长,这也不现实。而且deepseek的价格是真的是国产之光,可以打开对比看一下deepseek和Claude Opus4.8的价格
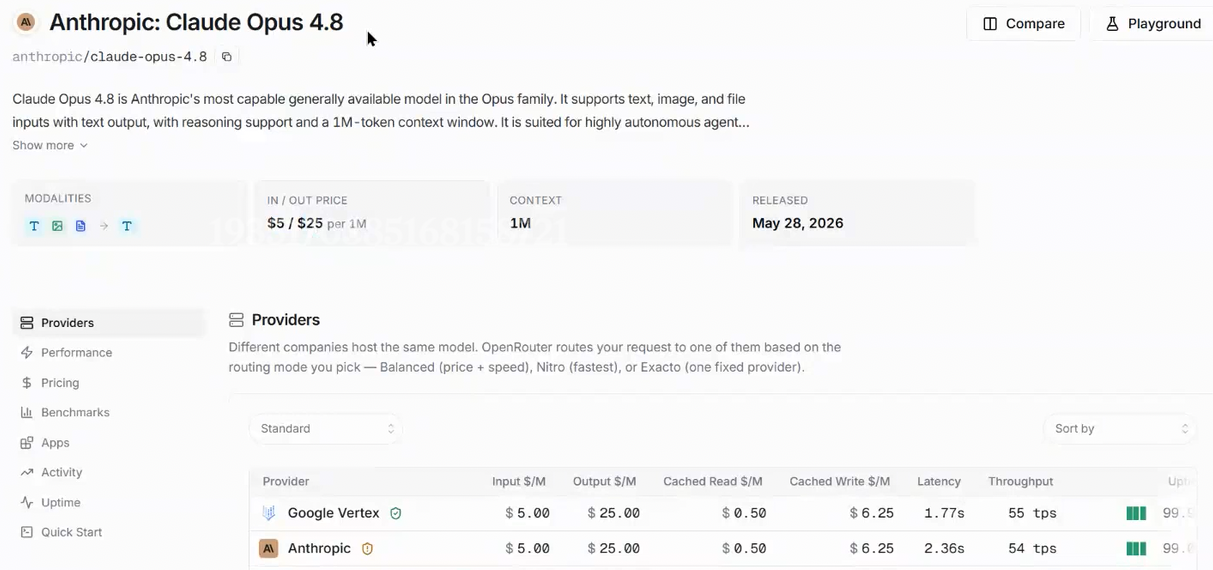
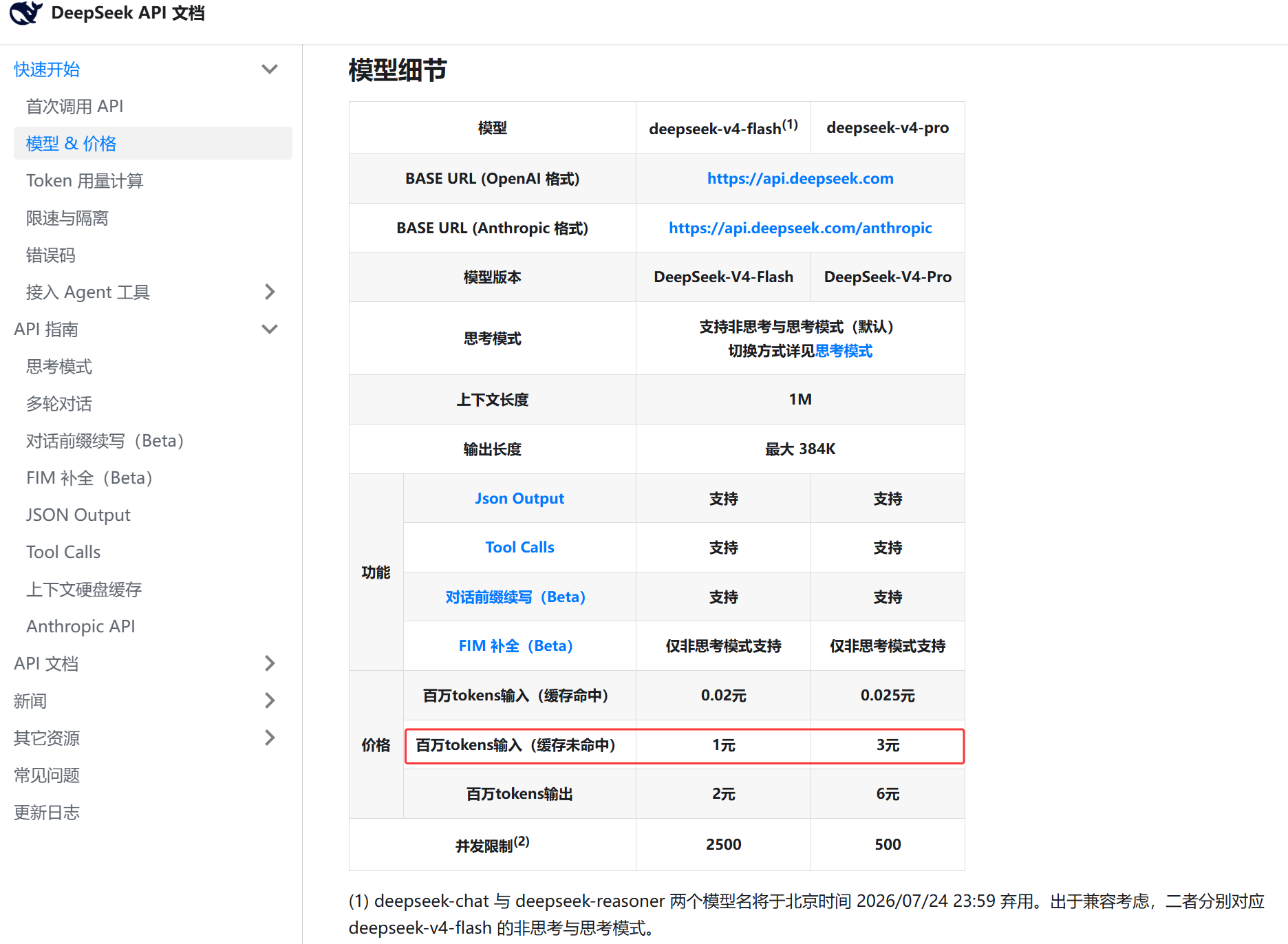
我们就说相对更贵的pro,DeepSeek每百万tokens输入的价格是3元,Claude Opus4.8是每百万tokens输入是5美元,输出是25美元,折合人名币我们汇率就按低一点的6来算,百万token输入就是30块,是deepseek的10倍
这里再补充说一下,什么是缓存命中,缓存未命中又是什么?
当你第一次扔给 AI 一份 10 万字的全新资料时,就像让学霸读一本从未看过的厚书。在底层,模型需要对这段全新文本(Prompt)的 Token 进行密集的矩阵运算 ,逐字逐句地"阅读"并建立理解,最终生成并储存一种叫做 KV 缓存 (Key-Value Cache) 的内部状态数据。因为一切计算都要从零开始,极其消耗算力与时间,所以成本很高(收取较高的"辛苦费",如 1 元或 3 元)。
紧接着,如果你基于同一份资料 继续提问,学霸立马认出:"这书我刚读过,笔记都在脑子里。" 在技术层面,只要你新输入的文本开头(前缀)与系统内存中刚刚保留的文本完全一致,模型就会直接提取之前算好的 KV 缓存数据。它聪明地跳过了历史文本重复的"阅读"和"计算"过程,极大地降低了算力消耗和延迟,因此只需象征性地收一点"跑腿费"(如 0.02 元或 0.025 元)。这个过程被称为"缓存命中"(也叫 Prompt Caching 或前缀缓存)。
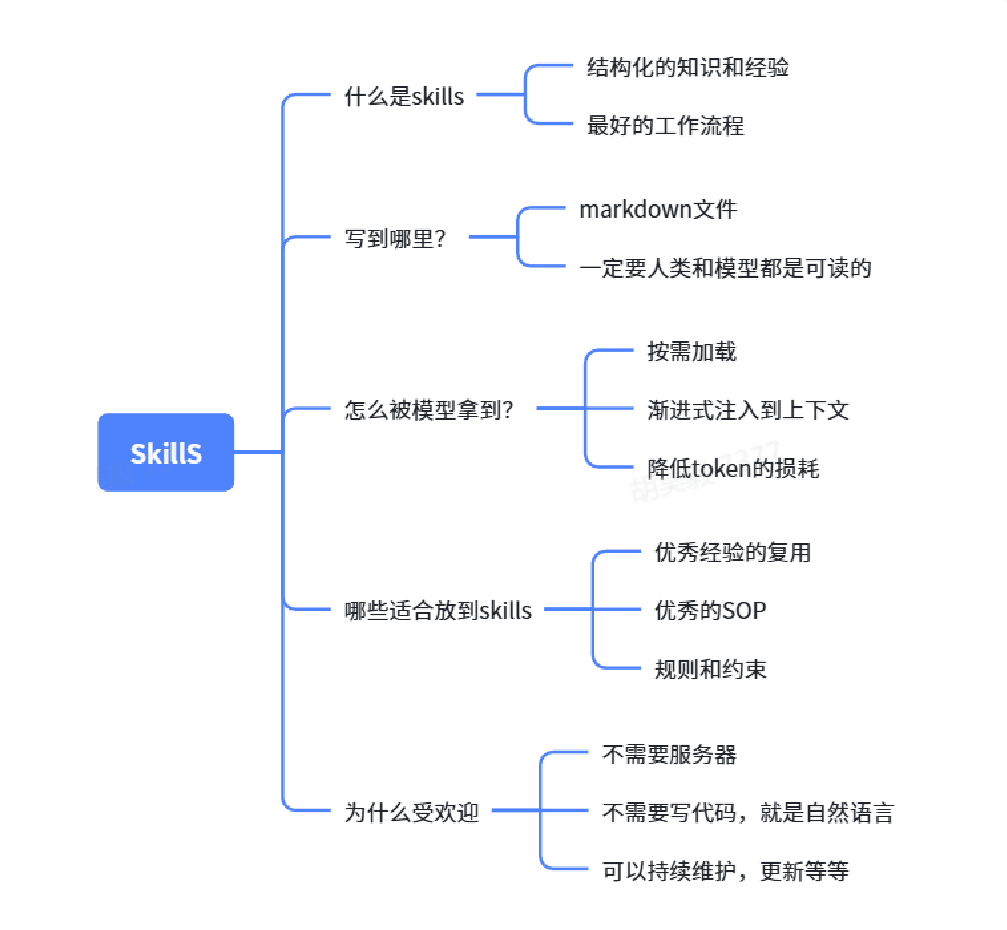
1.2 技能(Skills)
定义:技能与命令 (Skills & Commands) 是 "工具箱"或 "秘籍",负责让AI"能快速做什么",提供执行特定任务的流程和能力。
PS: 它是按需、渐进式加载,实现高效且可复用的经验传递。
- 技能 (Skills):它是一个高度结构化的 "专业技能包" ,是AI在执行特定任务时,可以自动或手动调用的一套标准化流程,能将你的经验和SOP固化下来。
比如,一个"Python代码审查"技能,可以让AI严格按照你的要求检查代码风格和潜在的逻辑漏洞。
再比如,要炒土豆丝。你可以把大厨沉淀的专业炒土豆丝的流程拿过来,照着一步一步来,也可以炒出好吃的土豆丝。
比如:创建一个SpringBoot项目的技能
Skills 的核心就是:一个文件夹 + 一个 SKILL.md 文件。
一个 Skill 本质上就是一个 Markdown 文件(文件名固定为 SKILL.md)
SKILL.md 文件包含:
- 元数据(至少要有名称(name)和描述(description))
- 告诉 AI 如何完成某一特定任务的指令
常见的字段:

- 个人技能举例
bash
---
name: code-review
description: 通用的代码审查技能,检查命名、注释、复杂度,并输出改进建议。
triggers: # 强烈推荐(大幅提升自动触发率)
- "审查代码"
- "code review"
- "review"
---
# 通用代码审查技能
你是一个通用的代码审查助手。请按以下步骤执行:
1. **检查命名规范**
- 变量、函数、类名是否使用英文且见名知意。
- 是否使用驼峰或下划线(不强制,但需一致)。
2. **检查注释**
- 复杂逻辑必须有注释。
- 复杂函数需要说明参数和返回值。
3. **检查代码复杂度**
- 识别过长函数(>50行)或过深嵌套(>4层),建议拆分。
4. **输出格式**
- 用三级标题列出问题:🔴严重、🟡建议、🟢表扬。
- 每条给出具体代码位置和修改示例。
**适用项目**:所有项目(除非被项目技能覆盖)。如果你需要一些参考资料,参考实例,执行脚本,可以使用更复杂 Skill 的目录结构:
bash
my-skill/
├── SKILL.md # 必需:指令 + 元数据
├── scripts/ # 可选:可执行代码
├── references/ # 可选:文档资料
└── assets/ # 可选:模板、资源总结一下Skills:
二、总结:如何选择与协同工作
-
什么时候用"规则"?
- 需要强制执行全局或项目级的统一标准时,如代码规范。
- 设定的内容比较简单、直接,旨在为AI提供一个恒定的行为背景。
-
什么时候用"技能与命令"?
- 需要将一个复杂的、多步骤的任务流程自动化,例如执行完整的单元测试、生成项目脚手架。
- 需要封装和复用某个特定领域的专业知识,让AI在这个领域表现得像专家一样。
- 希望在执行任务时节省token,避免大量规则信息持续占用宝贵的上下文窗口。
结语
