执行引擎
- 执行引擎是Java虚拟机核心的组成部分之一
- jvm的主要任务是负责装载字节码到其内部,但字节码并不能直接运行在操作系统上
- 执行引擎的任务就是将字节码指令解释/编译为对应平台上的本地机器指令才可以。简单来说,jvm中的执行引擎充当了将高级语言翻译成机器语言的译者
- 执行引擎在执行过程中需要依靠程序计数器来指定需要执行什么字节码。执行引擎也有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。

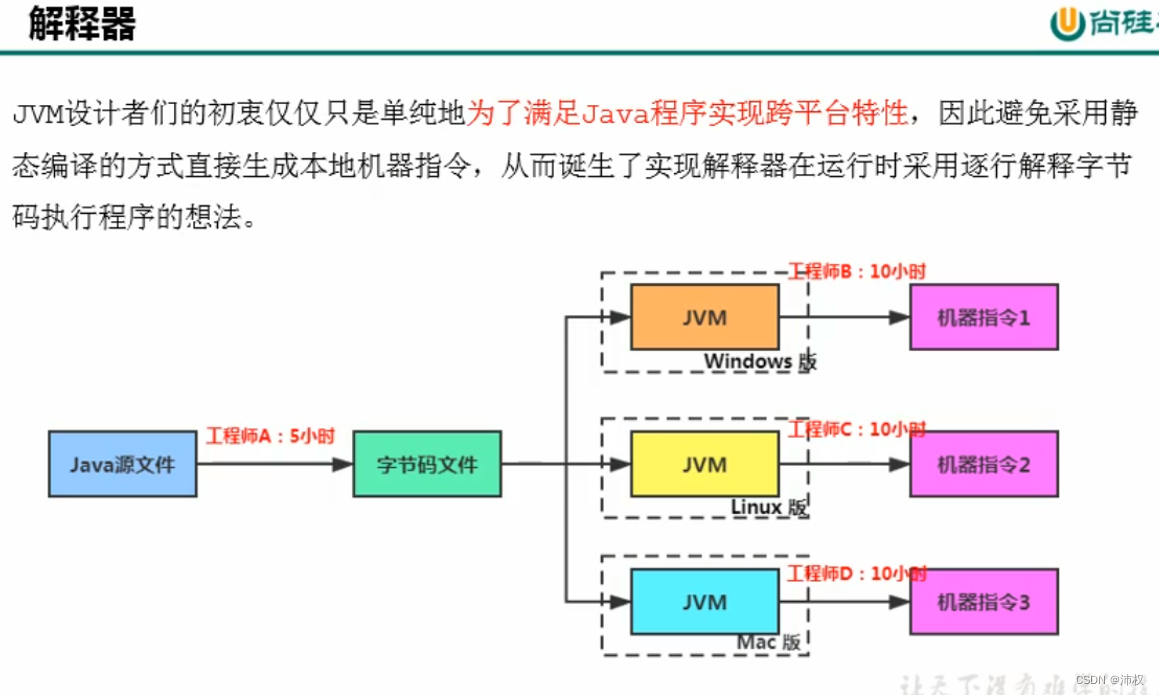
第一行是前端编译器 将Java源代码编译成字节码(和虚拟机关系不大,因为虚拟机是和字节码打交道的)
第二行是解释器,当Java虚拟机启动时,会根据预定义的规范对字节码采用逐行解释的方式执行,将每条字节码文件中的内容"翻译"为对应平台的本地机器指令执行
第三行是JIT编译器,就是虚拟机将源代码直接编译成和本地机器平台相关的机器语言【编译出来的机器语言可以缓存到方法区】
问题:为什么说Java是半编译半解释型语言?
在JDK1.0时代,将Java语言定位为"解释执行"还是比较准确的。再后来,Java也发展出可以直接生成本地代码的编译器。
现在JVM在执行Java代码的时候,通常都会将解释执行与编译执行二者结合起来进行。问题:字节码文件可以跨平台,Java源文件也可以跨平台。为什么不直接把Java源文件翻译成不同操作系统的机器指令?
视频说是因为直接把Java语言翻译成机器语言难度很高,也比较耗时。但是先把Java语言翻译成字节码,字节码再翻译成不同操作系统的机器指令就容易得多,也进行了人员的分工。
但是我个人理解是,其实Java的虚拟机可以看成是一个操作系统之上的操作系统。它跟实际的操作系统是很像的,只是不能直接执行程序而已。将Java语言翻译成字节码,把一整段的程序分成一个个的字节码指令,更有利用程序的执行解释器


hotspot采用解释器和编译器一起用的优点:
解释器虽然执行速度慢,但是在程序刚刚启动的时候,解释器可以快速做出响应,不用等待。而编译器需要一定的时间把代码编译成机器指令。这样可以节省很多不必要的编译时间。并且随着程序的执行,编译器注解发挥作用,检测热点代码,将有价值的字节码转换成机器指令,换取更高的执行速度。而且解释器还能在编译器进行激进优化不成立的时候,作为编译器的"逃生门"


热点代码及探测方式
- 热点代码:一个被多次调用的方法,或者是一个方法体内部循环次数教多的循环体都可以被称为"热点代码"
- 栈上替换(OSR编译 On Stack Replacement):因为JIT的编译发生在方法的执行过程中,所以称之为栈上替换
- hotspot虚拟机采用的热点探测方式是基于计数器的,它会为每个方法都建立两个不同类型的计数器
- 方法调用计数器
- 用于统计方法的调用次数
- 虚拟机在clinet模式下,方法要被调用1500次,才触发JIT编译。在server模式下,10000次
- 整个阈值可以用 -XX:CompileThreshould设定
- 当一个方法被调用时,会先判断它是否被JIT编译过,如果有,直接使用对应的机器码。如果没有,计数器+1,(如果方法调用计数器+回边计数器的值超过方法调用计数器的阈值,会向JIT提交编译请求,然后使用JIT编译出的机器码),否则解释执行
- 热度衰减
- 方法计数器统计的不是方法被调用的绝对次数,而是一定时间内的次数。当方法的调用数在一定时间内没有达到阈值,方法计数器值减半。这个过程称为方法计数器的衰减(Counter Decay) 。而这段时间就称为此方法统计的半衰周期(Counter Half Life Time)。
- 进行热度衰减的动作是垃圾回收时顺便执行的,可以用 -XX:-UseCounterDecay 来关闭热度衰减。这样,只要运行的时间足够长,绝大部分方法都会被编译成本地代码。
- -XX:CounterHalfLifeTime设置半衰周期的时间,单位为秒
- 回边计数器(在字节码中,遇到控制流向后跳转的指令称为"回边")(Back Edge)
- 用于统计循环体循环的次数
- 方法调用计数器
方法计数器

回边计数器

设置hotspot的运行方式
- -Xint:完全用解释器执行程序
- -Xcomp:完全用即时编译器执行程序
- -Xmixed:采用解释器+即时编译器混合模式共同执行程序


【如果机器是64位的话,默认还是C2编译器,还改不了】



