导航
- 引言
- tablestore简介
- 火线告警:500错误频发
- 真相大白:单表数据超2亿,tablestore连接超时
- 紧急发版:快速关闭查询功能
- 数据清理:仅保留半年内的数据
- 收紧入口:只同步一条到tablestore
- 双保险:增加功能开关
- 结语
本文首发《记一次群聊消息查询优化的实践》。
引言
我们在成长,代码也要成长。
一晃,做群聊业务两年多了。
随着业务的增长,群数量不断增长,聊天消息也在不断增长。
群聊的全局搜索的性能问题愈发凸显。
设计之初,考虑群消息的急剧增长,选择了使用阿里云的tablestore,这是一个类似ElasticSearch,拥有强大的搜索能力。
现在来看,还是过于乐观了。
当单表数据达到2亿+的时候,查询变得异常艰难,甚至频繁超时,被客户疯狂吐槽。
当然,遇到这些问题,或许是我们使用的方式不对,欢迎大家帮忙斧正。本篇仅用于问题记录和经验交流分享。
tablestore简介
表格存储(Tablestore)面向海量结构化数据提供Serverless表存储服务,同时针对物联网场景深度优化提供一站式的IoTstore解决方案。适用于海量账单、IM消息、物联网、车联网、风控、推荐等场景中的结构化数据存储,提供海量数据低成本存储、毫秒级的在线数据查询和检索以及灵活的数据分析能力。
基本概念
在使用表格存储前,您需要了解以下基本概念。
| 术语 | 说明 |
|---|
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 术语 | 说明 |
| 地域 | 地域(Region)物理的数据中心,表格存储服务会部署在多个阿里云地域中,您可以根据自身的业务需求选择不同地域的表格存储服务。更多信息,请参见表格存储已经开通的Region。 |
| 读写吞吐量 | 读吞吐量和写吞吐量的单位为读服务能力单元和写服务能力单元,服务能力单元(Capacity Unit,简称CU)是数据读写操作的最小计费单位。更多信息,请参见读写吞吐量。 |
| 实例 | 实例(Instance)是使用和管理表格存储服务的实体,每个实例相当于一个数据库。表格存储对应用程序的访问控制和资源计量都在实例级别完成。更多信息,请参见实例。 |
| 服务地址 | 每个实例对应一个服务地址(EndPoint),应用程序在进行表和数据操作时需要指定服务地址。更多信息,请参见服务地址。 |
| 数据生命周期 | 数据生命周期(Time To Live,简称TTL)是数据表的一个属性,即数据的存活时间,单位为秒。表格存储会在后台对超过存活时间的数据进行清理,以减少您的数据存储空间,降低存储成本。更多信息,请参见数据版本和生命周期。 |
应用场景
表格存储有互联网应用架构(包括数据库分层架构和分布式结构化数据存储架构)、数据湖架构和物联网架构三种典型应用架构。
- 互联网应用
- 历史订单数据场景
- IM场景
- Feed流场景
- 大数据
- 推荐系统
- 舆情&风控分析(数据爬虫)场景
- 物联网
基于我们的实际场景,选择了IM场景。

java sdk
更加详细的介绍请查看:《java sdk》
火线告警:500错误频发
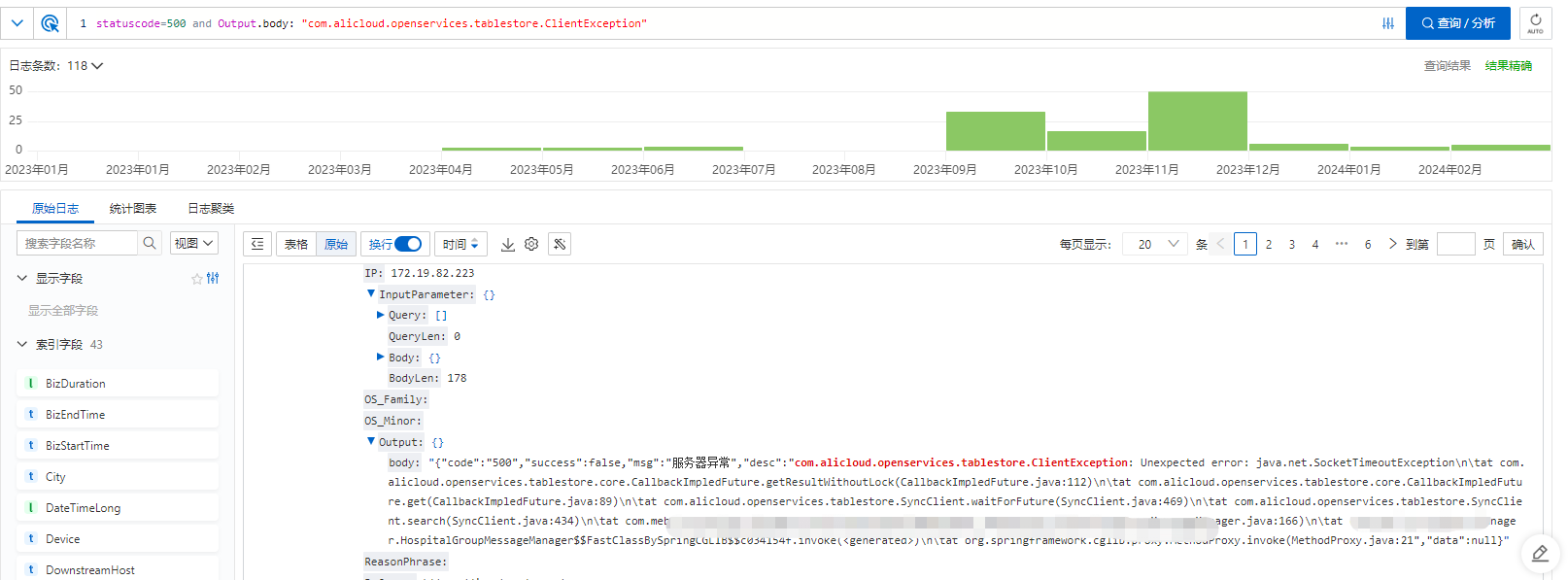
从日志记录可以看出,异常的主要集中在去年9月~12月之间,基本上超时请求。
除此以外,还有大量的慢查询。
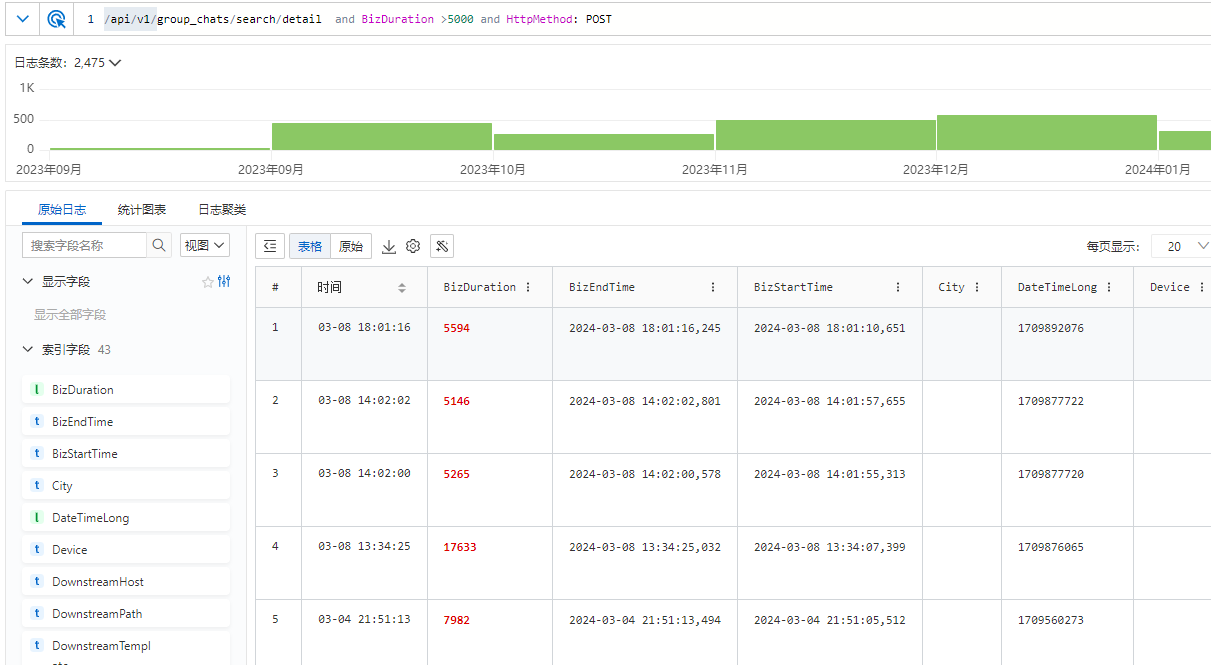
这是其中一个包含搜索群消息逻辑的接口,确实很慢。
特别是在去年年底,几乎每天技术群都会有几个报警。
真相大白:单表数据超2亿,tablestore连接超时
经过排查,存储群聊消息的宽表超过接近3亿条。
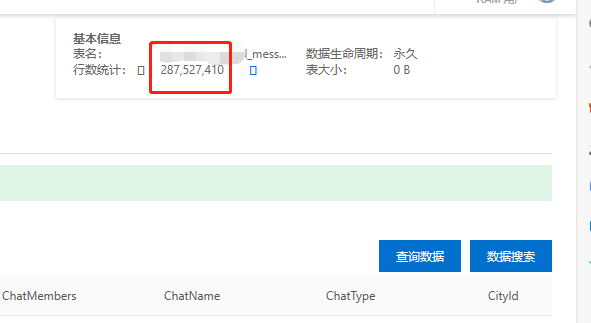
因为是群聊场景,每条消息发出都会投递给其他群成员,我们是按照接收人的方式存储的,所以消息数量会激增。
消息存储数量已经过亿,这个就导致ts查询性能急剧下降,不知道Elastic Search的在这种数量下的性能如何,请有这方面经验的朋友指点一下。
如何应对呢?
能想到的就是删除TS中历史数据,保留一定时段内的数据,控制数据量在一定范围内。
但是保留多久的数据,产品、运营都无法给出一个合理的时段。
于是陷入僵局。
紧急发版:快速关闭查询功能
每一个群报警,都像是敌人发起的冲锋号角,我不能坐视不管。
短时间内没有更好地解决方案,和运营沟通后,选择暂时关闭群聊查询功能。
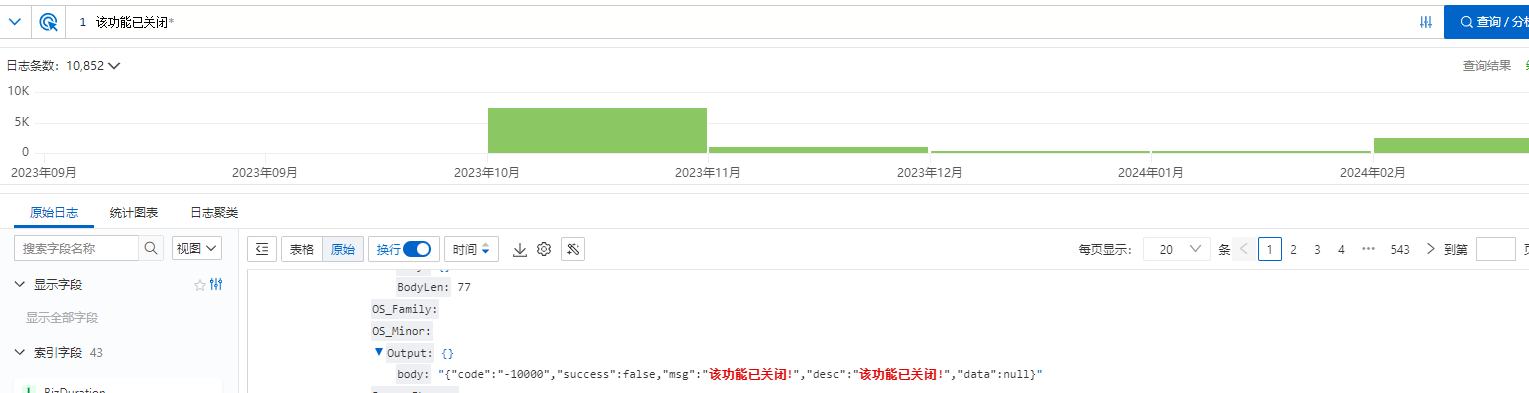
紧急给这个功能增加了开关,下班就发版了。报警群安静了,安稳过年。
数据清理:仅保留半年内的数据
选择妥协,别为难自己。
程序员朋友爱较真,有些人甚至到了丧心病狂的程度。
我有个写代码的同事,每次有人找他改问题都像是干架。
我呢,有时候也会钻进牛角尖。
经过一顿操作,我发现暂时没有很好的解决方案,于是我妥协了。
既然,没有很好的优化办法,那就把历史数据删除了,只保留半年的数据。
为此,转为写了一个定时任务,每天执行。
短时间内,我们将数据降低到2亿条以内。
收紧入口:只同步一条到tablestore
真正的猛士敢于直面困难,有些问题必须解决。
本以为定时删除数据的方案已经稳了,没想到增长的比删除的还快。
没到一个月,数据量又上来了。
我再次选择了关闭了群聊查询功能。
痛定思痛, 我决定优化方案------从源头控制写入TS的数量。
我们一起来看看之前的存储方案:
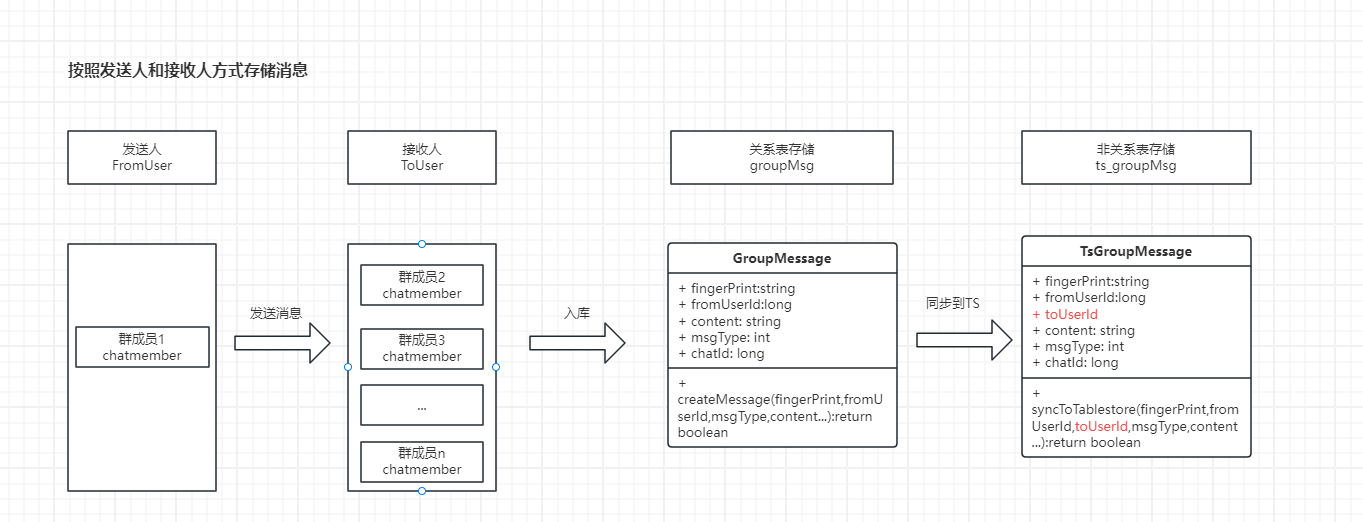
这样设计是考虑到可能会按照接收人来控制查看消息的权限。
比如尽管在一个聊天群,但是进群的人是有先后的,不同时间进群的人可能看到的消息不一样。
弊端就是同一份消息会存储多份。
为什么要这样做呢?
因为我们的IM并没有使用本地数据库的方式,所有消息都是从服务端拉取的。
上面的分析我们知道,数据量太大是导致tablestore查询性能差的根本原因。
那我们考虑对现有方案进行改进:
- 放开消息查询的限制,不在限制接收人
- 消息按照发送人存储,仅存储一条
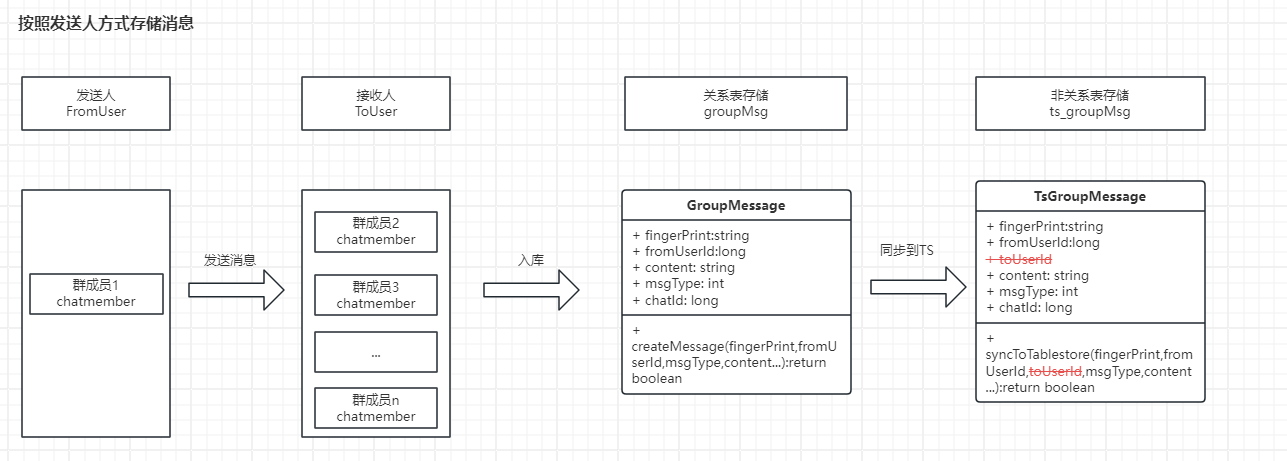
这样存储,我们的数据将会大幅度下降。
双保险:增加功能开关
防患未然,功能可开关。
我们总是喋喋不休的强调程序的稳定性、健壮性、可扩展性...
但是,我们总是无法一次性写出完美的程序。
业务需求的变化、数据量的变化、三方接口的升级等都不得不让我们经常考虑到对程序的重构,总之有各种不确定性的因素出现。
在《记一次加锁导致ECS服务器CPU飙高分析》一文中,我们提到为了防患未然,对一些复杂功能增加开关是一个比较好的处理办法。
通过两个主要措施:
- 数据清理:仅保留半年内的数据
- 收紧入口:只同步一条到tablestore
几天之后,我们再次查看tablestore中单表的数据量已经大幅降低。
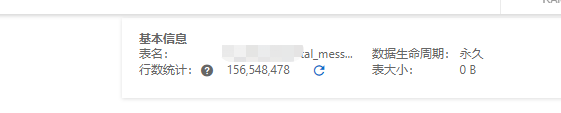
随着时间的推移,我们的策略会持续执行,那么数据量将会降低到千万级别。
当然,这个数据量,我们可以比较放心的打开这个群消息查询功能。
结语
善战者无赫赫之功。
哪有什么岁月静好,我们总是在打怪升级中成长。
或许对于大众而言所谓的"技术好",不是单纯的卖弄技术,而是能够针对灵活多变的场景,恰到好处的运用技术。
活到老,学到老。
这里笔者只根据个人的工作经验,一点点思考和分享,抛砖引玉,欢迎大家怕批评和斧正。
2024.03.11
成都