Python-爬虫
- [■ 爬虫分类](#■ 爬虫分类)
-
- [■ 1. 通用网络爬虫:(搜索引擎使用,遵守robots协议)](#■ 1. 通用网络爬虫:(搜索引擎使用,遵守robots协议))
-
- [■ robots协议(君子协议)](#■ robots协议(君子协议))
- [■ 2. 聚集网络爬虫:自己写的爬虫程序](#■ 2. 聚集网络爬虫:自己写的爬虫程序)
- [■ urllib.request(请求模块)](#■ urllib.request(请求模块))
-
- [■ 示例一:01_Request.py 向百度发送请求,并获取http响应码](#■ 示例一:01_Request.py 向百度发送请求,并获取http响应码)
- [■ 示例二:02_Request.py](#■ 示例二:02_Request.py)
- [■ 示例三:03_Request.py](#■ 示例三:03_Request.py)
- [■ 请求头(headers)User-Agent](#■ 请求头(headers)User-Agent)
-
- [■ 知识点一:向测试网站: http://httpbin.org/get 发送请求,**会返回我们的请求头User-Agent内容。**](#■ 知识点一:向测试网站: http://httpbin.org/get 发送请求,会返回我们的请求头User-Agent内容。)
- [■ 知识点二:写的py代码的User-Agent:是Python-urllib/3.7,这样子很容易被服务器知道你是爬虫访问的,所以在发送请求前指定一个User-Agent](#■ 知识点二:写的py代码的User-Agent:是Python-urllib/3.7,这样子很容易被服务器知道你是爬虫访问的,所以在发送请求前指定一个User-Agent)
- [■ urllib.parse(编码模块)](#■ urllib.parse(编码模块))
-
- [■ 知识点一:对中文进行编码后再发送请求。!在这里插入图片描述(https://img-blog.csdnimg.cn/direct/e567fb9e69004ac0ac04c2e28f941a5e.png)](#■ 知识点一:对中文进行编码后再发送请求。
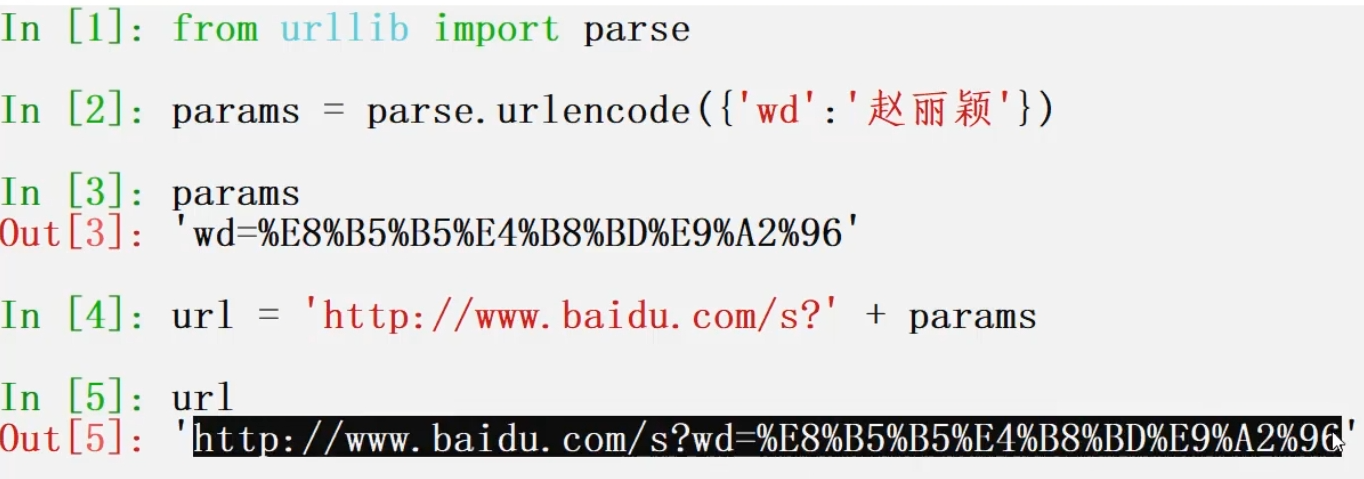 )
)
- [■ 知识点一:对中文进行编码后再发送请求。!在这里插入图片描述(https://img-blog.csdnimg.cn/direct/e567fb9e69004ac0ac04c2e28f941a5e.png)](#■ 知识点一:对中文进行编码后再发送请求。
- [■ 正则表达式re模块](#■ 正则表达式re模块)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ 数据持久化](#■ 数据持久化)
-
- [■ 1. 数据持久化-CSV](#■ 1. 数据持久化-CSV)
- [■ 2. 数据持久化-MySQL](#■ 2. 数据持久化-MySQL)
- [■ 3. 数据持久化-MongoDB](#■ 3. 数据持久化-MongoDB)
- [■ 多级页面抓取](#■ 多级页面抓取)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ requests模块](#■ requests模块)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ 互联网图片抓取](#■ 互联网图片抓取)
- [■ Chrome浏览器插件](#■ Chrome浏览器插件)
- [■ xpath语法解析](#■ xpath语法解析)
-
- [■ 1. lxml+xpath解析提取数据](#■ 1. lxml+xpath解析提取数据)
- [■ 2.](#■ 2.)
- [■ Json解析模块](#■ Json解析模块)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ Cookie](#■ Cookie)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ Selenium](#■ Selenium)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ 中间件](#■ 中间件)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ Scrapy](#■ Scrapy)
-
- [■ 1 Scrapy-框架原理](#■ 1 Scrapy-框架原理)
- [■ 2 Scrapy-](#■ 2 Scrapy-)
- [■ 3 Scrapy-](#■ 3 Scrapy-)
- [■ 分布式爬虫原理](#■ 分布式爬虫原理)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ 机器视觉](#■ 机器视觉)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ 极限滑块验证码破解](#■ 极限滑块验证码破解)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
- [■ 移动端数据抓取](#■ 移动端数据抓取)
-
- [■ 1.](#■ 1.)
- [■ 2.](#■ 2.)
- [■ 3.](#■ 3.)
■ 爬虫分类
■ 1. 通用网络爬虫:(搜索引擎使用,遵守robots协议)
■ robots协议(君子协议)
robots协议:通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
网页后面加 robots.txt 查看网站robots协议。

■ 2. 聚集网络爬虫:自己写的爬虫程序
■ urllib.request(请求模块)
作用: 向网站发送请求,即:我们平时在浏览器输入地址访问网站一样。
| 函数 | 作用 | 参数 |
|---|---|---|
| urllib.request.urlopen(URL,timeout) | 作用 | URL:需要爬取的URL地址 timeout:设置等待超时时间,指定时间内未响应抛出超时异常。 |
| urllib.request.Request() | 包装请求,重构User-Agent,使用程序更新正常人类请求 | URL:请求的URL地址 headers:添加请求头,类型为字典headers= {'User-Agent':} |
■ 示例一:01_Request.py 向百度发送请求,并获取http响应码
python
from ■ 示例二:02_Request.py
python
from ■ 示例三:03_Request.py
python
from 
■ 请求头(headers)User-Agent
作用: User-Agent 有游览器,操作系统信息。
■ 知识点一:向测试网站: http://httpbin.org/get 发送请求,会返回我们的请求头User-Agent内容。

python
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0■ 知识点二:写的py代码的User-Agent:是Python-urllib/3.7,这样子很容易被服务器知道你是爬虫访问的,所以在发送请求前指定一个User-Agent
■ urllib.parse(编码模块)
作用:给URL地址中查询参数进行编码


