💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
💡本章重点
- 命名实体识别
🍞一. 概述
实体识别任务(Named Entity Recognition,简称NER)是自然语言处理(NLP)中的一个基本任务,旨在从文本中识别和分类命名实体。命名实体通常包括专有名词,如人名、地名、组织名等。
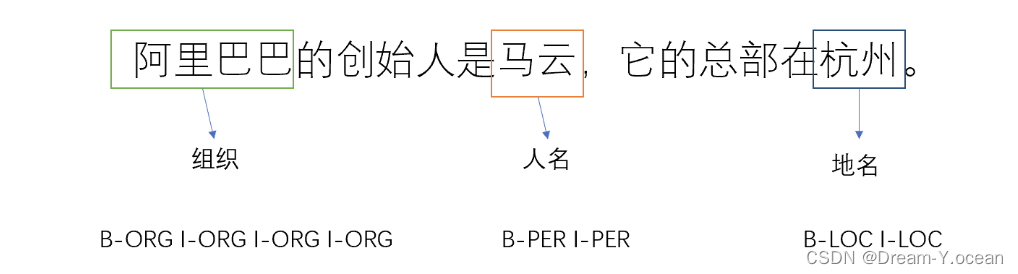
下图展示了一个简单的实体抽取任务,在句子中抽取出来阿里巴巴(组织名)、马云(人名)和杭州(地名)三个实体。

🍞二. 主要目标
NER 的主要目标是找到文本中有意义的实体,并将其归类到预定义的类别中。以下是一些常见的类别:
人名(Person):例如"乔布斯"、"马云"。
地名(Location):例如"纽约"、"长城"。
组织名(Organization):例如"微软"、"联合国"。
应用
命名实体识别是自然语言处理领域的一个重要的任务,它在很多具体任务上有着自己的应用:
- 信息抽取:从大量文档中自动提取有价值的信息。
- 问答系统:帮助系统更准确地理解问题并返回相关答案。
- 文本摘要:在生成文本摘要时识别出关键实体以保留重要信息。
- 推荐系统:通过识别用户偏好的实体来提供个性化推荐。
🍞三. 论文介绍
本文的工作启发于论文BERT-BiLSTM-CRF Chinese Resume Named Entity Recognition Combining Attention Mechanisms
技术方法
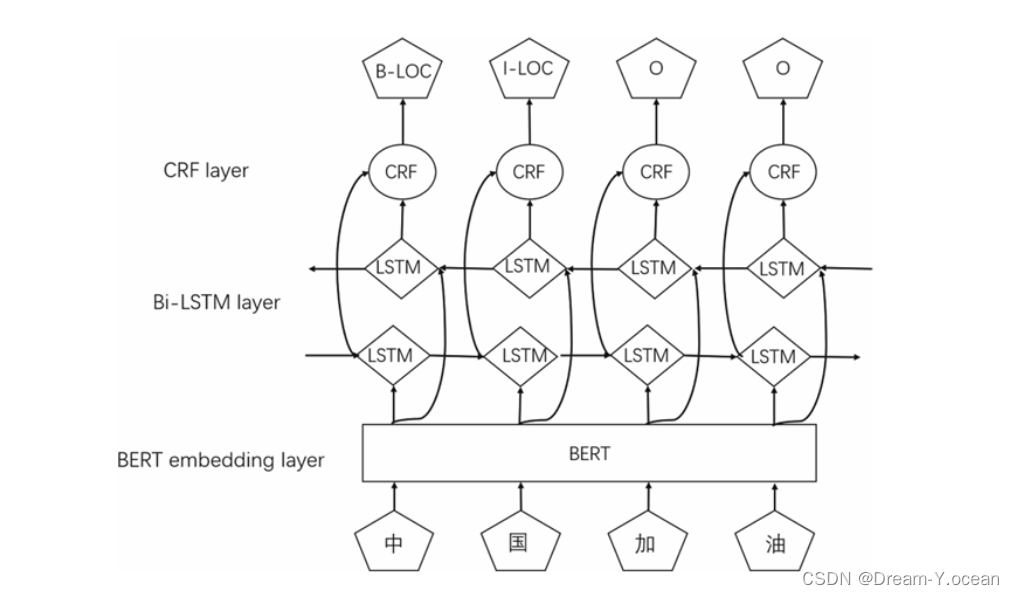
BERT编码
首先,将输入的中文文本通过预训练的 BERT 模型进行编码,生成每个字的上下文表示。BERT模型通过其双向Transformer架构,能够捕捉文本中每个字与其前后文之间的复杂关系,从而生成高质量的字级别表示,有助于后续的特征提取和实体识别。
BiLSTM特征提取
接下来,将 BERT 输出的特征向量输入到双向长短时记忆网络(BiLSTM)中,以捕捉序列中的前后依赖关系。BiLSTM网络能够从两个方向处理序列数据,即从前向后和从后向前。使得模型可以充分利用上下文信息,对每个字在整个序列中的位置和角色进行更准确的建模,从而提取出更丰富的特征表示。
注意力机制
在 BiLSTM 层之后,引入注意力机制,以便模型能够聚焦于更相关的特征。注意力机制通过计算序列中各个字之间的相关性权重,使模型能够动态地调整对不同位置的字的关注程度。
CRF标注
最后,将经过注意力机制处理的特征向量输入CRF层,进行全局序列标注,输出最终的实体识别结果。CRF是一种用于序列标注的概率图模体型,它考虑了标注序列的全局依赖关系,从而在预测每个字的标签时,不仅依赖于当前字的特征,还综合考虑其邻近字的标注情况。
论文提出的BERT-BiLSTM-Att-CRF模型在中文数据集上取得了较好的识别效果。
结合论文提出的框架,本文新增了一个LoRA层,用来优化模型
LoRA
神经网络包含许多密集层执行矩阵乘法。这些层中的权重矩阵通常是满秩的。当适应特定下游任务时,研究表明:预训练语言模型拥有较低的内在维度,也就是说,存在一个极低维度的参数,对它进行微调,和在全参数空间中进行微调,训练效果是相近的。受此启发,在参数更新过程中,应当也存在一个相对较低的"本征秩"。对于预训练的权重矩阵,通过低秩分解来约束其更新。在涉及到矩阵相乘的模块,增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟本征秩。
🍞四. 数据处理
数据来源
本文所用的训练数据是MSRA-NER数据集。
MSRA-NER是由微软亚洲研究院标注的新闻领域的实体识别数据集。该数据集包含5万多条中文实体识别标注数据,实体类别分为人物、地点、机构三类。
数据集包含训练集46364个句子,验证集4365个句子。
格式举例如下:
bash
中 共 中 央 致 中 国 致 公 党 十 一 大 的 贺 词 各 位 代 表 、 各 位 同 志 : 在 中 国 致 公 党 第 十 一 次 全 国 代 表 大 会 隆 重 召 开 之 际 , 中 国 共 产 党 中 央 委 员 会 谨 向 大 会 表 示 热 烈 的 祝 贺 , 向 致 公 党 的 同 志 们 致 以 亲 切 的 问 候 !
B-ORG I-ORG I-ORG I-ORG O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O O B-ORG I-ORG I-ORG O O O O O O O O O O O O数据标注
采用BIO标注方式对获得的文本句子进行标注
BIO数据标注方式是命名实体识别(NER)任务中常用的一种标注方法。BIO代表三种标签:B(Begin),I(Inside)和O(Outside),用于标记文本中每个词属于某个命名实体的开头、内部或外部。以下是对BIO标注方式的详细介绍:
BIO标签定义
B(Begin):表示命名实体的开始。一个实体的第一个词标注为B-<实体类型>。
I(Inside):表示命名实体的内部。属于同一个实体的后续词标注为I-<实体类型>。
O(Outside):表示不属于任何命名实体的词。
例如,B-ORG表示组织实体的开头,I-ORG表示组织实体的内部。下图展示了一个标注好的例子,其中未标注的字段都是无实体(O)。
🍞五.核心逻辑
BaLC模型
自定义attention层,bert模型、LSTM模型、CRF模型调用pytorch库中的相关模型,使用BERT预训练的语言模型对输入文本进行字符级编码,获得动态词向量,然后使用双向长短期记忆(BiLSTM)网络提取全局语义特征,然后使用注意力机制分配权重,更好地捕捉关键特征,最后使用条件随机场(CRFs)输出全局最优标记序列。具体定义如下:
python
import torch.nn as nn
from transformers import BertPreTrainedModel, BertModel, BertConfig
from torchcrf import CRF
import math
import torch
class Self_Attention(nn.Module):
def __init__(self, input_dim, dim_k, dim_v):
super(Self_Attention, self).__init__()
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self._norm_fact = 1 / math.sqrt(dim_k)
def forward(self, x):
Q = self.q(x)
K = self.k(x)
V = self.v(x)
atten = torch.bmm(Q, K.permute(0, 2, 1)) * self._norm_fact # Q * K.T()
atten = nn.Softmax(dim=-1)(atten)
output = torch.bmm(atten, V)
return output
class BERT_BiLSTM_ATT_CRF(nn.Module):
def __init__(self, bert_model, hidden_dropout_prob, num_labels, hidden_dim=128):
super(BERT_BiLSTM_ATT_CRF, self).__init__()
self.bert = BertModel.from_pretrained(bert_model)
bert_config = BertConfig.from_pretrained(bert_model)
self.dropout = nn.Dropout(hidden_dropout_prob)
self.bilstm = nn.LSTM(input_size=bert_config.hidden_size, hidden_size=hidden_dim, num_layers=1, bidirectional=True, batch_first=True)
out_dim = hidden_dim* 2
self.hidden2tag = nn.Linear(in_features=out_dim, out_features=num_labels)
self.attention = Self_Attention(128, 128, 128)
self.crf = CRF(num_tags=num_labels, batch_first=True)
def forward(self, input_ids, tags, token_type_ids=None, attention_mask=None):
outputs = self.bert(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
sequence_output = outputs[0]
sequence_output, _ = self.bilstm(sequence_output)
sequence_output = self.dropout(sequence_output)
sequence_output = self.attention(sequence_output)
sequence_output = self.hidden2tag(sequence_output)
outputs = self.crf(sequence_output , tags, mask=attention_mask.byte())
return outputsLoRA结构

python
for layer in model.bert.encoder.bert_layer_groups:
layer.bert_layers[0].attention.query = LinearLora(layer.bert_layers[0].attention.query,rank=8,alpha=16)
layer.bert_layers[0].attention.key = LinearLora(layer.bert_layers[0].attention.key,rank=8,alpha=16)
model.to(device)实现方式
首先下载Bert预训练模型,然后收集自己要训练的数据集,放入文件中,修改源码中的路径名称。
运行train.py函数,开始训练,可以自行调整训练中的epoch等参数,其中训练的时候会调用测试函数进行输出。
演示效果
运行train.py函数,可以看到模型开始训练,在模型训练结束后,会根据测试集的结果生成测试的结果
python
precision recall f1-score support
B-LOC 0.9257 0.8245 0.8721 2871
I-LOC 0.8894 0.8796 0.8845 4370
B-ORG 0.8625 0.7800 0.8192 1327
B-PER 0.9513 0.9021 0.9261 1972
I-PER 0.9254 0.9521 0.9386 3845
O 0.9913 0.9917 0.9915 150935
I-ORG 0.8631 0.9255 0.8932 5640
avg/total 0.9804 0.9803 0.9802 170960运行demo.py可以根据输入的句子,进行实体识别,例如:
python
sentence = "在 唐 胜 利 康 复 回 乡 前 一 天 , 北 京 博 爱 医 院 院 长 吴 弦 光 代 表 医 院 向 唐 胜 利 及 其 父 亲 赠 送 编 织 机 。"
output =[['<START>', 'O', 'B-PER', 'I-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'B-ORG', 'B-ORG', 'B-ORG', 'B-ORG', 'B-ORG', 'O', 'O', 'B-PER', 'I-ORG', 'I-ORG', 'O', 'O', 'B-LOC', 'B-ORG', 'O', 'B-PER', 'I-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', '<END>']]可以看出,模型能识别句子中的实体,并按照BIO标注返回结果
🫓总结
综上,我们基本了解了**"一项全新的技术啦"** 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 -- 了解更多新知识】
