一、简介
KNN算法思想:如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。
这其中k值的选择较为关键,k值过小容易受异常点影响,容易过拟合,而k值过大则模型变得简单容易欠拟合,如k=N,无论输入实例是什么都是训练集里个数最多的。
可以使用交叉验证或者网格搜索对k值调优。
分为分类或回归两类。
二、API的使用
python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neighbors import KNeighborsRegressor
# KNN的分类API
def dm01_knnapi():
estimator = KNeighborsClassifier(n_neighbors=4)
X = [[0], [1], [2], [3]]
Y = [0, 0, 1, 1]
estimator.fit(X, Y)
mypre = estimator.predict([[4]])
print(mypre)
# KNN的回归API
def dm02_knnapi():
estimator = KNeighborsRegressor(n_neighbors=2)
X = [[0, 0, 1],
[1, 1, 0],
[3, 10, 10],
[4, 11, 12]
]
Y = [0.1, 0.2, 0.3, 0.4]
estimator.fit(X, Y)
mypre = estimator.predict([[3, 11, 10]])
print(mypre)
if __name__ == '__main__':
# dm01_knnapi()
dm02_knnapi()三、几种距离的衡量方式
1.欧氏距离
2.曼哈顿距离
3.切比雪夫距离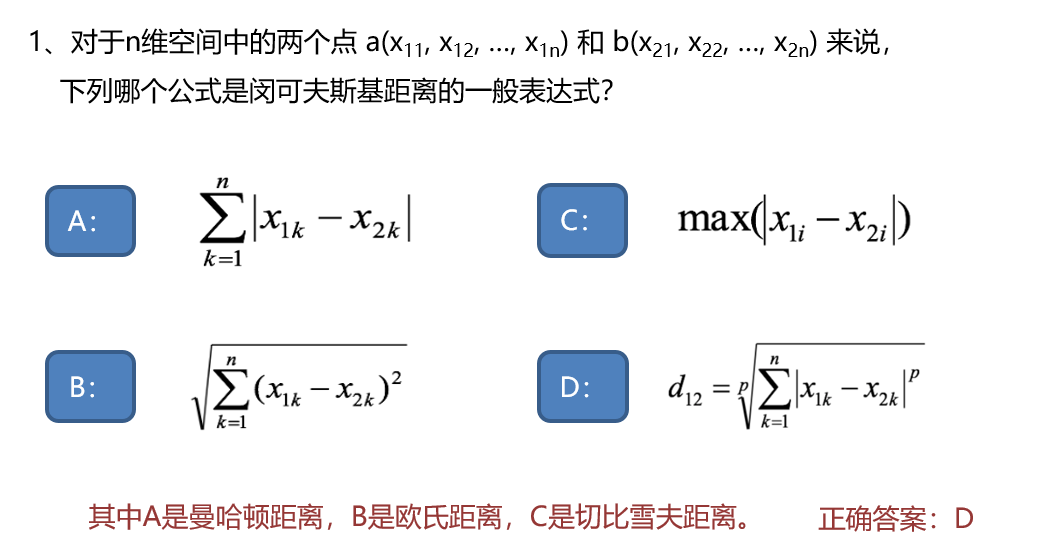
欧式距离就是日常生活中的距离,曼哈顿距离是方方正正的街道都到终点的距离,切比雪夫是国际象棋里国王可以横、竖、正45度斜角的距离,闵可夫斯距离是一类距离的统称。
四、特征预处理
1.归一化 将数据等比压缩至0-1区间,简单直观,缺点容易受最大值最小值的影响。不常用
2.标准化,转为正态分布。
五、鸢尾花数据集案例
鸢尾花Iris Dataset数据集是机器学习领域经典数据集,鸢尾花数据集包含了150条鸢尾花信息,每50条取自三个鸢尾花中之一:Versicolour、Setosa和Virginica
四个特征:花瓣长、花瓣宽、花萼长、花萼宽
python
"""
案例:通过KNN算法实现 鸢尾花的 分类操作
回顾:机器学习的研发流程
1. 加载数据
2. 数据的预处理
3. 特征工程
4. 模型训练
5. 模型评估
6. 模型预测
"""
# 导入工具包
from sklearn.datasets import load_iris # 加载鸢尾花数据集
import seaborn as sns
import pandas as pd
import matplotlib as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score # 模型评估的,用于计算模型预测的准确率
def dm01():
#加载数据集
iris_data=load_iris()
# print(f'数据集:{iris_data}')
print(f'数据集类型:{type(iris_data)}')
#查看数据集所有的键
print(f'数据集所有的键:{iris_data.keys()}')
print(f'数据集键对应的内容:{iris_data.data[:5]}')
print(f'数据集键对应的内容:{iris_data.target[:5]}')
print(f'数据集键对应的内容:{iris_data.frame}')
print(f'数据集键对应的内容:{iris_data.target_names}')
print(f'数据集键对应的内容:{iris_data.feature_names}')
print(f'数据集键对应的内容:{iris_data.filename}')
print(f'数据集键对应的内容:{iris_data.DESCR}')
if __name__ == '__main__':
dm01()
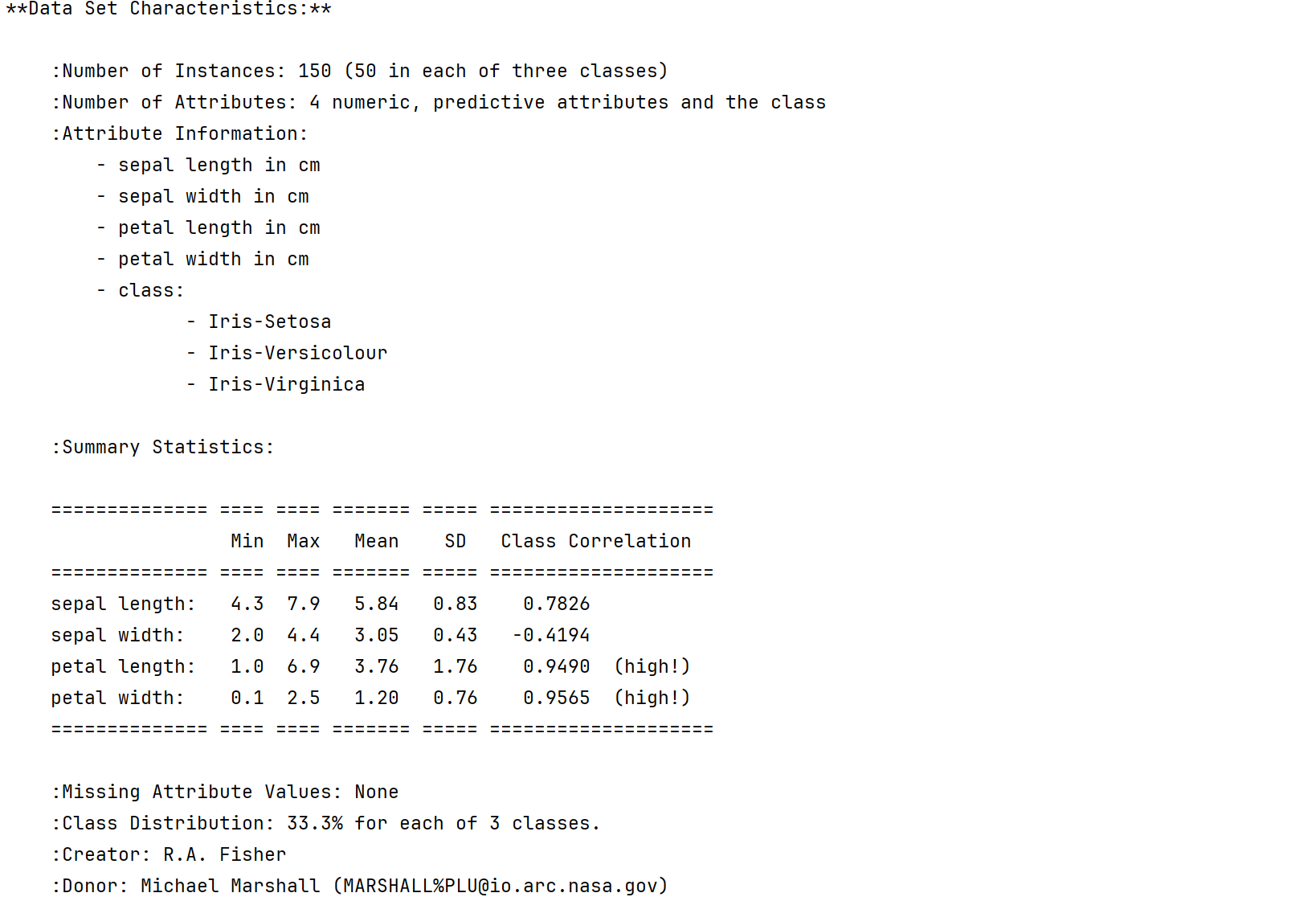
该数据集包含3个类别,每类50个实例,每个类别对应一种鸢尾花植物。其中一个类别与其他两个是线性可分的;而后者两个类别之间彼此不是线性可分的。
python
def dm04():
# 1.加载数据
iris_data = load_iris()
# 2 数据预处理
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2,
random_state=18)
# 3. 进行数据标准化处理
transfer = StandardScaler()
# fit_transform 兼具fit 和 transform 的功能,即训练和转换 该函数 适用于第一次进行标准化处理 一般用于训练集
x_train = transfer.fit_transform(x_train)
# transform 仅进行转换 该函数 适用于:重复进行标准化动作时使用,一般用于对测试集进行标准化
x_test = transfer.transform(x_test)
# 4.模型训练
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5 模型预测
y_pre = estimator.predict(x_test)
print(f'预测结果:{y_pre}')
# 6 模型评估
# 6. 模型预估, 有两种方式, 均可.
# 6.1 模型预估, 方式1: 直接计算准确率, 100个样本中模型预测正确的个数.
my_score = estimator.score(x_test, y_test)
print(my_score) # 0.9666666666666667
# 6.2 模型预估, 方式2: 采用预测值和真实值进行对比, 得到准确率.
print(accuracy_score(y_test, y_pre))
if __name__ == '__main__':
# dm01()
# dm02_scatter()
# dm03_split_train_test()
dm04()想象你在备考:
-
x_train:复习题(老师给你看的练习题) -
y_train:复习题答案(老师给的参考答案) -
x_test:期末考试题(你没见过的考题) -
y_test:期末考试答案(老师有的标准答案,但不告诉你)
学习过程:
-
你用
(x_train + y_train)学习 -
用
x_test考试,结果是y_pre -
用
y_test批改试卷(对比y_pre与y_test)
六、交叉验证与网格搜索
交叉验证法,是划分数据集的一种方法,目的就是为了得到更加准确可信的模型评分。

这个k不是KNN的几个邻居的k,就是指第几轮,上图就是4轮。
交叉验证一般结合网格搜索使用,
python
"""
案例:演示网格搜索和交叉验证
交叉验证解释:
原理:
第1次:把第1份数据作为验证集,其他作为训练集,训练模型,模型预测,获取:准确率->准确率1
第2次:把第2份数据作为验证集,其他作为训练集,训练模型,模型预测,获取:准确率->准确率2
第3次:把第3份数据作为验证集,其他作为训练集,训练模型,模型预测,获取:准确率->准确率3
第4次:把第4份数据作为验证集,其他作为训练集,训练模型,模型预测,获取:准确率->准确率4
假设第4次最好(准确率最高),则:用训练集的全部数据训练模型,再次用(第4次)测试集对模型测试
目的:
为了让模型最终真结果更准确
网格搜索:
目的/作用
寻找最优参数
原理:
接收超参可能出现的值,然后针对于超参的每个值进行 交叉验证,获取到 最优超参组合
超参数:
需要用户手动录入的参数,不同的参数
大白话解释:
网格搜索 + 交叉验证 本质指的是GridSearchCV这个API,他会帮我们寻找最优超参
"""
# 导入工具包
from sklearn.datasets import load_iris # 加载鸢尾花测试集的.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV # 分割训练集和测试集的
from sklearn.preprocessing import StandardScaler # 数据标准化的
from sklearn.neighbors import KNeighborsClassifier # KNN算法 分类对象
from sklearn.metrics import accuracy_score # 模型评估的, 计算模型预测的准确率
# 1 加载鸢尾花数据集
iris_data = load_iris()
# 2 数据预处理
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)
# 3 特征工程
transfer = StandardScaler()
x_train = transfer.fit_transform(X_train)
x_test = transfer.transform(X_test)
# 4 模型训练
# 4.1 创建KNN分类对象
estimator = KNeighborsClassifier()
# 4.2定义字典
param_dict = {"n_neighbors": [i for i in range(1, 11)]}
# 4.3 创建GridSearchCV->寻找最优超参 使用网格搜索+交叉验证
# 参1 要计算最优超参的模型对象
# 参2 超参可能出现的值
# 参3 交叉验证的次数
estimator = GridSearchCV(estimator, param_dict, cv=4)
# 4.4 模型训练
estimator.fit(x_train, y_train)
# 4.5 打印最优超参组合
print(f'最优评分:{estimator.best_score_:.4f}')
print(f'最优超参组合:{estimator.best_params_}')
print("最优估计器对象:", estimator.best_estimator_)
print("交叉验证结果:", estimator.cv_results_)
# 5 模型评估
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
y_pre = estimator.predict(x_test)
print(f'准确率:{accuracy_score(y_test, y_pre):.4f}')