文章目录
为什么要用到事务
我们所有的程序都是按顺序来执行代码,但是就会存在中途出现异常,甚至代码挂掉无法执行后续的代码,这是很常见的。可是有的情况下我们容不得程序中途挂掉,就比如银行汇款,如果a账户给b账户汇款,a中余额1000元,b中余额1000元,当a给b汇款500元时,首先a要从余额中扣除500元,b要从余额中加上500元,在不出错的情况下,程序执行结束,a余额500元,b余额1500元。但是,当中途程序出错,数据库中途挂掉,a扣了500之后,b的500并没有加上去吗,这个时候就很尴尬了...我们宁愿程序出错a的余额没有扣除都是好的,最起码没有金钱的损失。为了解决以上问题,我们就会用到事务,就是为了解决SQL语句要么全部执行成功,要么全部执行失败。
事物的概念
事物指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
简单来说,就是把若干个SQL语句打包成一个"整体",要么都不执行,要么都执行完毕。但是这里的"都不执行"不是这些SQL真的没有执行,而是执行一半,发现出错的时候,数据库会自动进行"还原操作",相当于把之前执行过的SQL给撤销,最终看起来像是一个都没有执行的效果。这样的机制我们称为"回滚(rollback),同时也把事务支持的上述"特性"称为"原子性"。
日志体系
数据库是怎么进行回滚的?如何知道前面的SQL做出了啥样的修改呢?
数据库中存在一系列的"日志体系 ",当开启事务的时候,此时每一步执行的SQL都对数据进行了哪些修改,这些信息就会记录在案。后续如果需要回滚,就可以参考之前记录的内容,进行还原。并且以文件的方式记录和存储,这样即可以应对"程序崩溃"也能应对"主机掉电"的情况。
事务的使用
(1)开启事务
start transaction
(2)执行多条语句
(3)回滚或提交
rollback/commit
说明:rollback是全部失败,commit是全部成功
例如:
sql
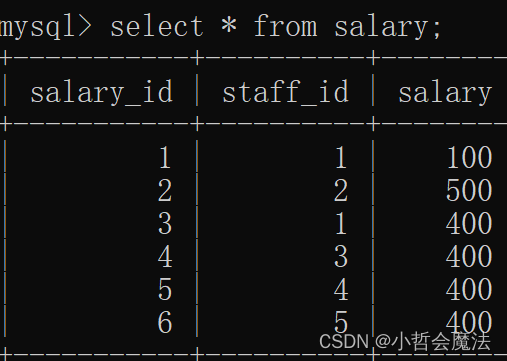
-- salary_id 为1的 给 salary_id 为2的转100
start transaction;
update salary set salary = salary - 100 where salary_id = 1;
update salary set salary = salary + 100 where salary_id = 2;
commit;程序运行之前
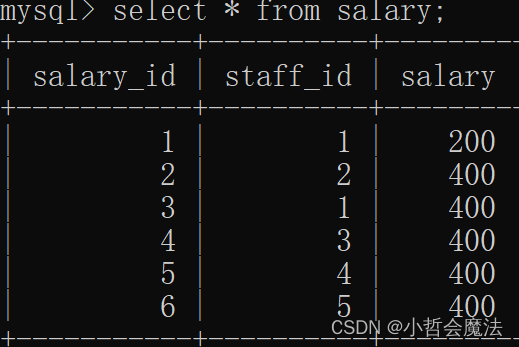
程序运行之后
事务的基本特性(重点掌握)
事务涉及到的四个核心特性:
1.原子性(最重要的特性):就是上文的回滚机制
2.一致性:描述的是,事务执行前和执行后,数据库中的数据,都是"合法状态",不会出现非法的零时结果的状态。
3.持久性:事务执行完毕之后,就会修改硬盘上的数据,事务都会持久生效。
4.隔离性(非常复杂的一个性质):描述了多个事务并发执行的时候,互相之间产生的影响是怎样的。
隔离性
1)脏读
2)不可重复读
3)幻读
- 脏读
两个事务A和B并发进行,其中事务A在针对某个表的数据进行修改,A执行过程中,B也去读取数据,当B读完之后,由于A的修改操作有误,回滚至修改之前,导致B读到的数据不是"正确"的数据,而是读到了零时的"脏数据"
| 时间顺序 | 转账事务 | 取款事务 |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 开始事务 | |
| 3 | 查询账户余额为2000元 | |
| 4 | 取款1000元,余额被更改为1000元 | |
| 5 | 查询余额为1000元(产生脏读数据) | |
| 6 | 取款操作发生错误,事务回滚,余额变为2000元 | |
| 7 | 转入2000元,余额更改为3000元(脏读的1000+2000) | |
| 8 | 提交事务 | |
| 备注 | 按照正确的逻辑,此时账户余额应为4000元 |
结论:读取了为提交的数据!
解决方法:修改时,不能读(给写操作加锁!)
- 不可重复读
不可重复读指在数据库访问时,一个事务在前后两次相同的访问中却读到了不同的数据内容。
比如说事务A的执行周期较长,事务A在第一次读取某个数据时,此数据的值为100,读取完成后,事务A又去执行其他的事情,在这个过程中,事务B将这个数据的值修改为200,然后事务A做完其他的事情后,又来读取这个数据的值,发现这个值和第一次所读取的值不相同,这种现象称为不可重复读。
| 时间顺序 | 事务A | 事务B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 第一次查询小明年龄为21岁 | |
| 3 | 开始事务 | |
| 4 | 其他操作 | |
| 5 | 更改小明年龄为22岁 | |
| 6 | 提交事务 | |
| 7 | 第二次查询小明年龄为22岁 | |
| 备注 | 按照正确的逻辑,事务A前后两次读的数据应该保持一致 |
结论:前后多次读取,数据内容不一致!
解决方法:读取时,其他事物不能修改(给读操作加锁!)
- 幻读
幻读指的是事务A在查询完记录总数之后,事务B执行了新增操作,事务A再次查询记录总数,发现两次查询的结果不一致,平白无故的多出了几行数据。
| 时间顺序 | 事务A | 事务B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 第一次查询,数据总量100条 | |
| 3 | 开始事务 | |
| 4 | 其他操作 | |
| 5 | 新增100条数据 | |
| 6 | 提交事务 | |
| 7 | 第二次查询,数据总量为200条 | |
| 备注 | 按照正确的逻辑,事务A前后两次读的数据总量应该保持一致 |
解决方法:进行"串行化",一次只执行一个事务。
那么脏读、不可重复读和幻读又和隔离性有什么关系呢?
在MySQL中提供了四个隔离级别,可以通过配置文件来设置当前的服务器隔离级别时哪个级别。
1)read uncommitted 读未提交
这种情况下,一个事务可以读取另一个事务未提交的数据,此时就可能会产生脏读、不可重复读和幻读三种问题,但是此时多个事务并发程度是最高的,执行速度也是最快的。
2)read committed 读已提交
这种情况下,一个事务只能读取另一个事务提交之后的数据(给写操作加了锁)此时,可能会产生不可重复读和幻读问题(脏读问题解决了)此时并发成都降低,执行速度会变慢,同时事务之间的隔离性提高了,事物之间的相互影响变小了,得到的数据更准确了。
3)repeatable read 可重复读
这是MySQL默认的隔离级别,这个情况下,相当于是给写操作和读操作都加了锁,此时可能产生幻读问题,解决了脏读和不可重复读问题,并发程度进一步降低,执行速度进一步变慢,事务直接按的隔离性进一步提高了。
4)serializable 串行化
此时,所有的事务都是在服务器上一个接着一个的执行的,此时解决了脏读、不可重复读和幻读问题,并发程度最低,执行速度最慢,隔离性最高,数据最准确。