技术限制导致了高噪声的多模态数据。尽管已经提出了计算方法来跨模态翻译单细胞数据,但是这些方法的泛化性仍然受到制约。scButterfly是一种基于双重对齐变分自编码器和数据增强方案的多功能单细胞跨模态翻译方法。通过对多个数据集进行全面的实验,证明了scButterfly在保留细胞异质性、同时翻译不同上下文的数据集以及揭示特定细胞类型的生物学见解方面优于基线方法。此外,scButterfly还可以推广到未配对数据训练、扰动-响应分析,连续翻译等。
来自:scButterfly: a versatile single-cell crossmodality translation method via dualaligned variational autoencoders
目录
方法概述
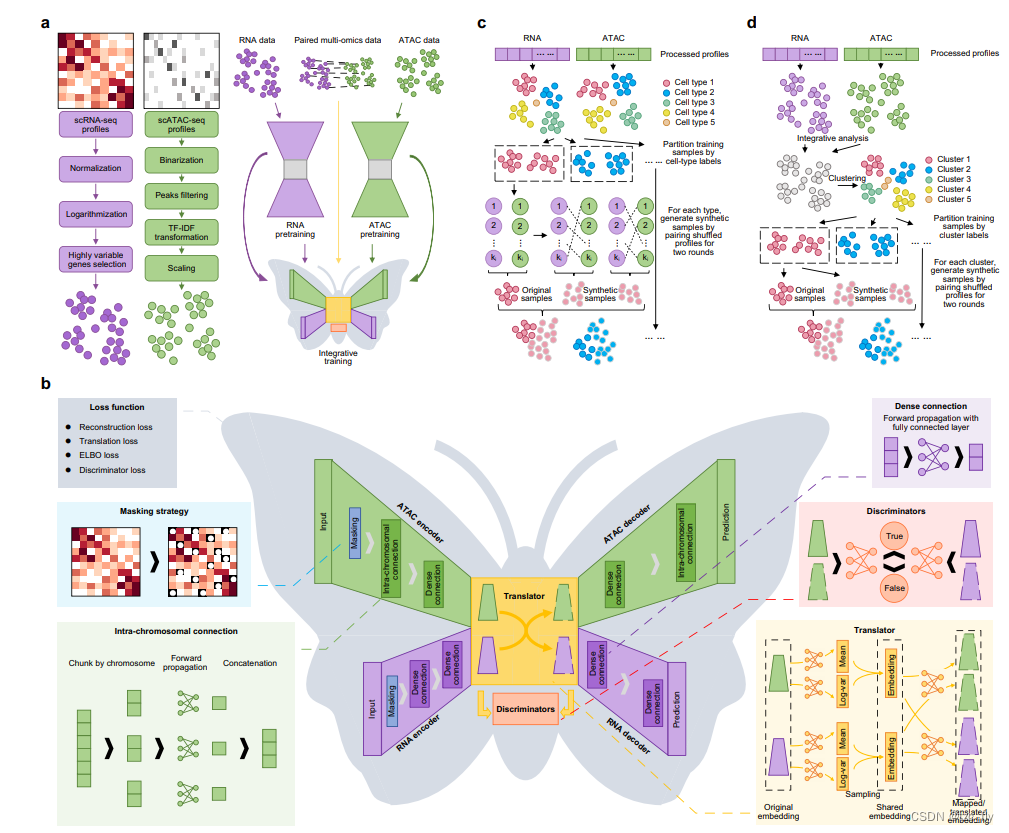
上图为模型概述,以转录组和染色质图谱之间的翻译为例说明。
a. scButterfly使用相应的常规策略预处理每种模态的数据,以模态特定的方式预训练编码器和解码器,并基于预训练参数对配对的多模态数据进行训练。
b. 基本的scButterfly模型(scButterfly-B)包括两个编码器,用于将预处理的数据投影到模态特定的潜在空间;一个翻译器,用于在不同模态之间进行翻译,并利用潜在空间中的多变量高斯分布在每个模态内进行映射;两个模态特定的判别器,用于区分翻译前后的潜在细胞嵌入,并实现对抗训练;以及两个解码器,用于使用翻译器翻译或映射的嵌入重建每个模态的原始高维细胞表示。作者为编码器引入了一种掩码策略,以减轻dropout事件的噪音影响,并修剪染色质图谱的编码器和解码器的染色体间连接,以减轻计算负担,并专注于染色体内的生物模式。
c. scButterfly的数据增强策略,适用于训练集有细胞类型标签的情景。作者通过随机配对同一类型细胞的转录组图谱和染色质图谱生成样本,得到的变体称为scButterfly-T(Type)。
d. scButterfly的数据增强策略,适用于训练集没有注释的更通用情景。作者进行综合分析以对训练集中的细胞进行聚类,并通过根据聚类标签随机配对生成样本,得到的变体称为scButterfly-C(Cluster)。
结果
保持细胞异质性的同时跨模态翻译
首先使用骨髓单核细胞的广泛配对RNA和ATAC-seq数据(称为BMMC数据集)作为概念验证,展示scButterfly的有效性。BMMC数据集作为一个综合的多模态基准数据集,包含来自4个site和10个不同供体的13个batch中的超过69,000个细胞。作者进行了五折交叉验证实验,通过将所有细胞随机分成五折,并迭代地使用训练模型将每折中的细胞染色质图谱翻译为转录组图谱,反之亦然。为了测试翻译后的图谱是否包含生物学上可解释的细胞异质性,作者通过各种下游分析任务(即降维、细胞聚类、差异表达和可及性分析等)评估了翻译性能。作者将scButterfly的性能与默认设置的BABEL、Polarbear和JAMIE进行了比较。以第一个测试fold为例,scButterfly从ATAC图谱翻译的RNA图谱可以有效地剖析细胞异质性,如t-SNE可视化所示(图2a)。具体来说,scButterfly的所有三种变体,包括基本模型(scButterfly-B),以及基于综合聚类(scButterfly-C)或训练集中的细胞类型标签(scButterfly-T)的数据增强模型,都能够区分红细胞生成的阶段,即前红细胞、正红细胞和红细胞(用红框标出),而BABEL和Polarbear这两种转录组和染色质图谱之间翻译的最新方法未能表征这三种重要的细胞类型。需要注意的是,JAMIE在BMMC数据集上由于超过了GPU内存限制(48GB,NVIDIA RTX A6000)而遇到了错误。
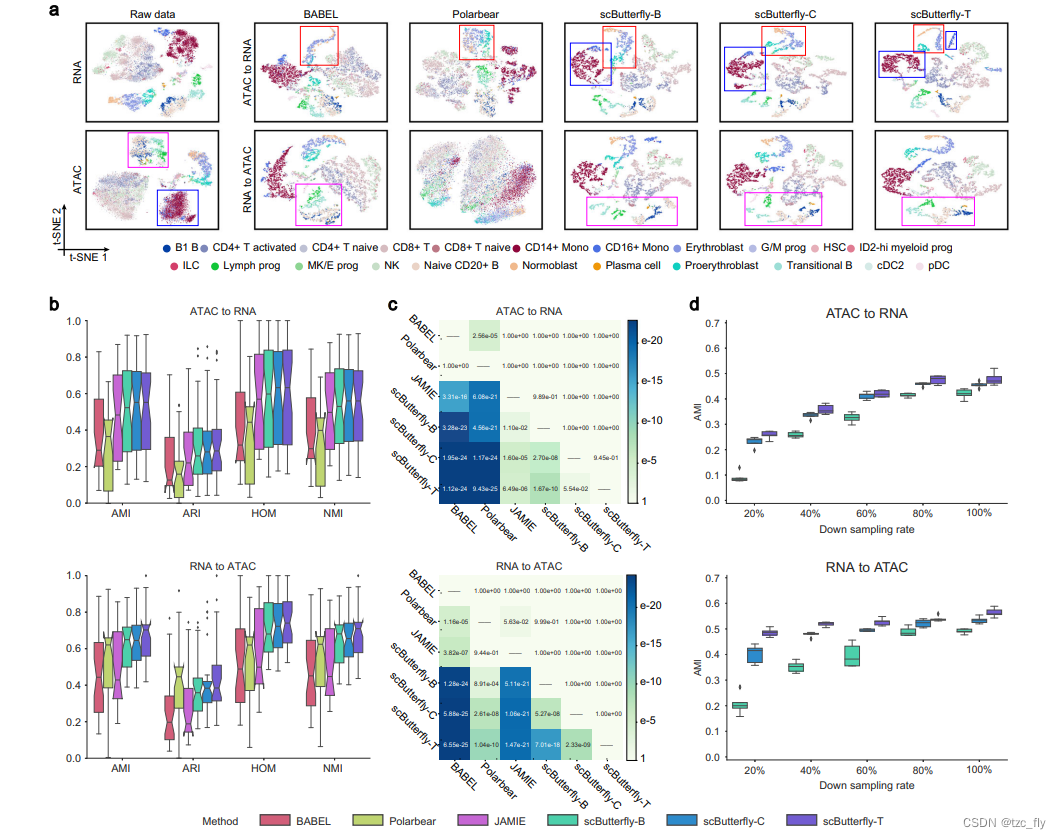
此外,注意到,scButterfly的所有三种变体都成功识别了CD14+单核细胞和CD16+单核细胞(用蓝框标出),这些在原始scATAC-seq数据中几乎难以剖析,表明scButterfly在将测试数据从一种模态翻译到另一种模态时,能够充分利用训练集中多模态的信息。
同样,scButterfly从RNA图谱翻译的ATAC图谱也很好地保留了细胞异质性(图2a)。例如,使用scButterfly预测的ATAC图谱,我们可以有效地捕捉到过渡性B细胞、淋巴前体、初始CD20+B细胞和B1 B细胞(用紫框标出),而BABEL预测的ATAC图谱甚至原始染色质图谱都几乎难以区分B1 B细胞和初始CD20+B细胞,Polarbear在这种情况下表现出不足的翻译能力。总体而言,scButterfly翻译的图谱能够熟练地表征细胞间的差异,并有潜力减少原始模态中的噪音,促进细胞类型的识别。
为了定量展示scButterfly在跨模态翻译中的优势,作者进一步基于翻译图谱的降维结果进行细胞聚类,并按照现有参考文献建议的调整互信息(AMI)、调整兰德指数(ARI)、同质性得分(HOM)和归一化互信息(NMI)评估翻译性能。交叉验证实验中每折的聚类性能再次表明,scButterfly在跨模态翻译中显著优于基线方法,同时保留了细胞异质性(补充图1、2-细胞配对数据上训练)。
此外,作者收集了六个附加数据集,这些数据集中包含了配对的RNA和ATAC数据,包括使用SNARE-seq4技术从成年小鼠大脑皮层获取的MCC数据集、使用SHARE-seq2技术从成年小鼠大脑获取的MB数据集、使用10x-Multiome技术分析的外周血单个核细胞(PBMC)数据集、使用sci-CAR3技术从成年小鼠肾脏获取的MK数据集、使用scCAT-seq5技术从多个细胞系分析的CL数据集以及使用SHARE-seq2技术从成年小鼠背部皮肤获取的MDS数据集,以进一步全面评估scButterfly的性能(补充图3)。如图2b和补充图4所示,scButterfly-B在跨模态翻译的两个方向上都比基线方法表现更好,并且有效地表征了细胞异质性,特别是在从转录组到表观基因组的翻译中。
重点:本小节关注的应该是图2b,这是评估模态翻译的benchmark
scButterfly有效地翻译了新环境的数据并揭示了生物学的见解
考虑到待翻译的谱系可能来自于与训练集不同的生物背景,并包含新颖的细胞类型,作者进一步评估了各方法在跨模态翻译新颖细胞类型时的性能。具体做法是,通过细胞类型随机将细胞数据分成三折,进行交叉验证实验。也就是说,测试集中的细胞类型与训练集中的细胞类型之间没有交集。作者使用了四个单批次数据集(MB、MCC、MK和PBMC)进行评估。正如图3a所示,在这种具有挑战性的样本外翻译中,与常规交叉验证实验(图2b)相比,所有方法的整体性能均大幅下降,这符合预期,因为大多数机器学习方法的共同限制是:测试样本如果与训练集偏离过大,往往表现出较差的预测性能。即便如此,对于新颖细胞类型的跨模态翻译,scButterfly的三种变体在从ATAC谱系推断RNA表达或反方向翻译方面均优于其他方法(图3a),这表明scButterfly能够有效识别不同生物背景下细胞之间的复杂关系,而不仅仅是简单记忆训练中见过的类似细胞。
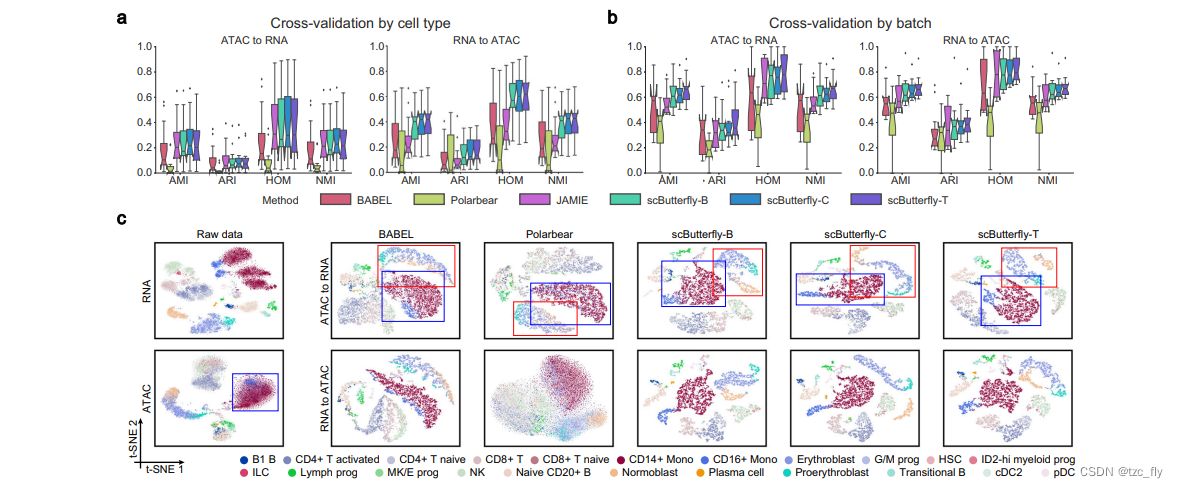
鉴于批次效应的技术变化可能构成跨模态翻译的障碍,作者接下来考虑了一个更普遍的挑战。作者使用了三个多批次数据集(BMMC、CL 和 MDS),通过随机将细胞按批次分组,进行了四倍交叉验证。具体而言,在来自一个批次(MDS 和 CL 数据集)或site(BMMC 数据集)的数据上进行翻译,同时在其余批次或site上训练模型,以确保训练和测试数据集包含完全不同的批次。如图 3b,scButterfly 的性能优于基线方法。
需要注意的是,JAMIE 在 BMMC 数据集上再次遇到了内存错误。此外,结果再次说明了利用数据增强来帮助预测跨模态概况的整体效用。以 BMMC 数据集中的第一个测试折为例,scButterfly 不仅可以保留数据中微妙的细胞类型进行转换,还可以利用不同模态之间学到的生物关系来减轻噪声的影响,并确定在翻译前通过原始数据很难区分的细胞类型(图 3c)。例如,利用从染色质翻译的转录组,scButterfly 的三个变体成功区分了红细胞生成的阶段(用红色方框标记),并确定了通过原始 scATAC-seq 数据很难分离的 CD14+ 单核细胞和 CD16+ 单核细胞(用蓝色方框标记),而 BABEL 和 Polarbear 仅适度地分离了这些细胞类型,再次表明了 scButterfly 在这种跨模态翻译场景中的优势。
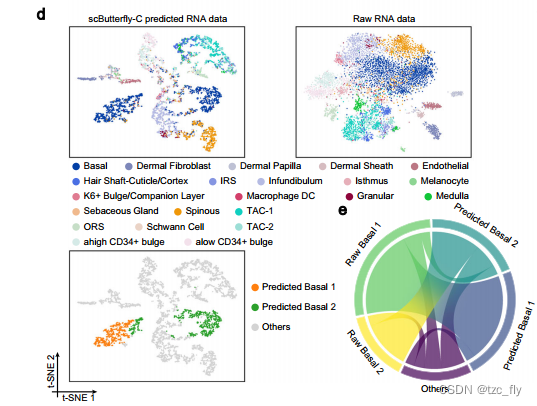
有趣的是,可以注意到 scButterfly-C 预测的 RNA 具有识别细胞亚型并提供对已识别的细胞亚群功能洞见的潜力。具体来说,在 MDS 数据集上,按批次进行了四倍交叉验证,并以第一个测试折中的细胞为例进行了说明,该折仅来自单个批次。预测的RNA将基底细胞分为两组,而使用原始RNA概况在 t-SNE 可视化中解剖basal细胞是困难的(见图3d)。然后,作者在预测的RNA概况上使用默认分辨率执行 Leiden 聚类,并根据聚类结果和表达模式确定了两个基底细胞亚组(预测的基底1和2),并且在这两个亚组之间及预测的RNA的两个亚组之间有56.850%的细胞一一对应(见图3e)。
scButterfly可以推广到非配对数据训练和扰动分析
大部分跨模态翻译方法都假设每种模态的训练样本是充分和完整的。然而,在普遍的应用中,这种假设并不总是成立,对于不在同一细胞中进行联合分析的不成对数据的对角线分析被认为比配对数据的分析更具挑战性。
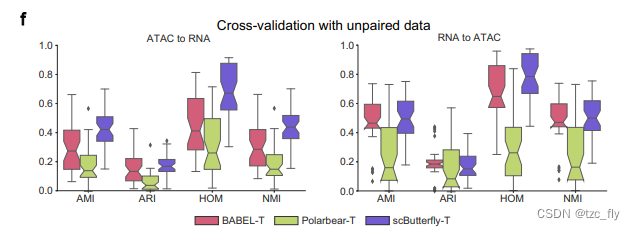
作者收集了八个不配对的转录组和染色质数据集,包括从成年人肾脏中提取的UP_HK数据集,从小鼠主要运动皮层中提取的UP_MPMC数据集,以及从不同人类胎儿器官中提取的六个数据集(UP_eye、UP_muscle、UP_pancreas、UP_spleen、UP_stomach、UP_thymus)。作者进行了五倍交叉验证,以测试scButterfly对不配对数据的普适性。具体来说,通过随机将一个细胞的RNA谱与训练集中同一细胞类型的另一个细胞的ATAC谱进行配对构建成对的训练样本。
对于多批次数据集,作者直接将来自不同批次的数据进行配对,而不进行批次校正,并通过用伪配对样本训练方法来获得BABEL-T、Polarbear-T、JAMIE-T和scButterfly-T的模型。注意,除了UP_HK数据集外,JAMIE在所有数据集上都遇到了GPU内存错误。如图4f所示,无论是预测的转录组谱还是预测的染色质谱,scButterfly都实现了显著更高的细胞簇聚类表现。
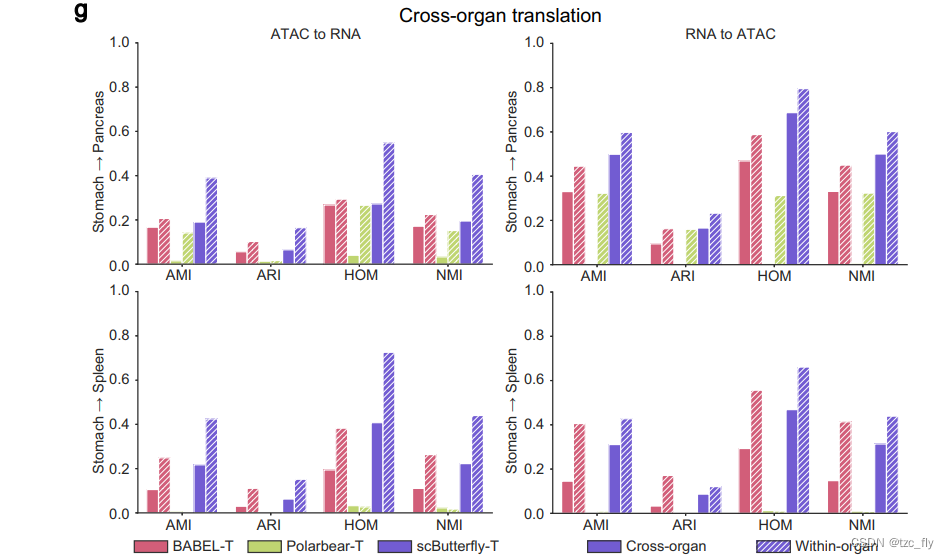
接下来,作者测试scButterfly是否可以推广到跨器官翻译。作者采用整个不配对的UP_stomach数据集作为训练集,使用与上述相同的训练策略,并分别在整个UP_pancreas和UP_spleen数据集上评估性能。如图4g所示,与上述器官内部的五倍交叉验证的性能相比,跨器官翻译的性能表现出明显的劣势,这可以归因于不同器官之间生物学背景的显著变化。尽管如此,可以注意到scButterfly再次在这个极具挑战性的任务中始终表现优异,进一步强调了scButterfly在跨器官翻译中的潜力和普适性。
作者进一步研究了 scButterfly 在单细胞扰动-响应预测方面的潜力。扰动响应筛选能够探索对不同扰动的分子和表型响应,阐明控制生物过程的基本机制。尽管如此,获取受扰动的细胞在许多情况下往往是一个重大挑战。
因此,扰动响应的生成建模可以扩展计算机实验的能力。由于细胞通常在测量过程中被破坏,这会导致生成包含受扰动和不受扰动的细胞的非配对分布,因此单细胞扰动响应预测任务需要非配对数据训练。作者使用了 scGen 和 scPreGAN(两种最先进的方法)使用的 PT_PBMC 数据集作为概念证明,以证明 scButterfly 在扰动分析中的有效性。PT_PBMC数据集包括七种细胞类型的对照和干扰素β刺激的人外周血单核细胞。作者将对照和刺激细胞的转录组谱视为两种模态,并提出一种基于最优传输的策略来匹配两组细胞以生成配对训练样本,因为这两种模态通常表现出显著的生物学差异,而这些差异在前述非配对的单细胞多组学数据中是不存在的。具体而言,作者利用最优传输通过最小化每种细胞类型的对照和刺激细胞之间的距离来获得最优耦合矩阵,为每个对照细胞选择权重最大的刺激细胞,最终将这两个细胞匹配为配对训练样本。
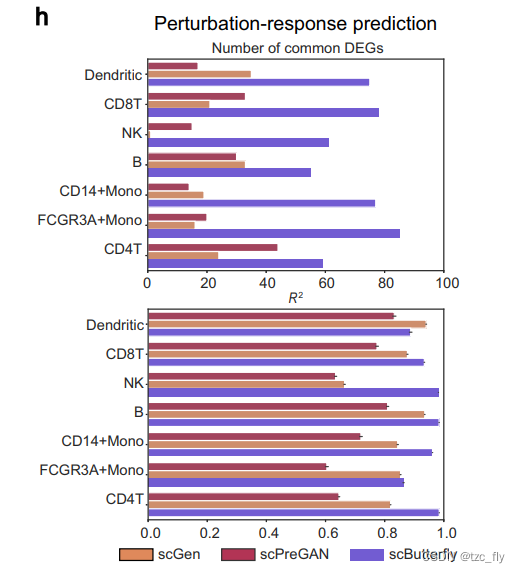
根据现有研究,作者评估了挑战性的样本外预测性能,该预测使用一个细胞类型的数据进行测试,并使用其余细胞类型的数据进行训练,类似于前述的对新细胞类型的跨模态翻译。作者采用了现有研究中普遍使用的两个指标来评估性能。如图4h所示,对照数据和真实刺激数据之间的前100个(真实)差异表达基因(DEGs)与控制数据和scButterfly预测的刺激数据之间的前100个(预测)DEGs之间的共同DEGs的数量明显超过了最先进方法的数量。此外,作者随机采样了80%的测试数据,并进行了100次替换,并计算了预测和真实刺激数据之间前100个(真实)DEGs的基因表达均值的平方皮尔逊相关系数(R2)。结果表明,由scButterfly-B预测的转录组谱与不同细胞类型的真实情况具有良好的相关性(每种细胞类型的平均R2一致超过0.85),scButterfly-B实现了整体最佳性能(图4h),阐明了scButterfly在单细胞干扰性研究中的潜在潜力。