文章目录
- [K8s service 底层逻辑](#K8s service 底层逻辑)
-
- [Kube-proxy 代理模式](#Kube-proxy 代理模式)
- [Service 请求情况](#Service 请求情况)
-
- [Service-Iptables 模式](#Service-Iptables 模式)
-
- [iptables 规则介绍](#iptables 规则介绍)
- [ClusterIP 模式分析](#ClusterIP 模式分析)
- [NodePort 模式分析](#NodePort 模式分析)
- [Service- IPVS 模式](#Service- IPVS 模式)
- 服务发现
- [HeadLess Service](#HeadLess Service)
-
- Headless的作用
- [HeadLess 示例](#HeadLess 示例)
K8s service 底层逻辑
Kube-proxy 代理模式
Kube-proxy 代理模式有一下三种
userSpace(已废弃)
userspace 模式下,kube-proxy 为Service IP 创建一个监听端口,当用户向ServiceIP 发送请求
- 首先请求会被Iptables规则拦截,然后重定向到Kube-Proxy对应的端口
- 然后Kube-Proxy 根据调度算法选择一个Pod,将请求调度到该Pod 上
总结:Pod请求ServiceIP时,会被Iptables将请求拦截给用户空间的Kube-Proxy,然后再经过内核空间路由到对应的Pod;
问题:但是该模式流量经过内核空间后,会送往用户空问kube-Proxy进程,而后又送回内核空间,发往调度分配的目标后端Pod;
iptables
iptables 模式下,kube-proxy 为Service后端的所有Pod创建对应的iptables规则,当用户向ServiceIP发送请求时
- 首先Iptables 会拦截用户请求
- 然后直接将请求调度到后端的Pod
总结:Pod请求Service IP时,Iptables 将请求拦截并直接完成调度,然后转发到对应的Pod,效率比userspace 高
问题:一个Service 会创建出大量的iptables规则,且不支持更高级的调度算法,当Pod 不可用也无法重试
IPVS
Itvs 模式和iptables类似,kube-proxy为service 后端的所有pod 创建对应的IPVS规则,一个Service只会生成一条规则,所以规模较大的场景下,应该使用IPVS模式。其次IPVS支持更高级的调度算法
Service 请求情况
访问Service会出现如下四种情况;
- Pod-A ->Service-> 调度 -> Pod-B/Pod-C
- Pod-A -> Service -> 调度 -> Pod-A
- Docker -> Service调度 -> pod-B/pod-c
- NodePort -> Service -> 调度-> pod-B/pod-C
Service-Iptables 模式
iptables 规则介绍
sh
iptables中的四表五链
1. 四个表
具备某种功能的集合叫做表。
filter: 负责做过滤功能呢
nat: 网络地址转换
mangle: 负责修改数据包内容
raw: 负责数据包跟踪
2. 五个链
在什么位置执行,能把表放在某个地方执行
PREROUTING、INPUT、OUTPUT、FORWARD、POSTROUTING
1) PREROUTING: 主机外报文进入位置,允许的表mangle, nat(目标地址转换,把本机地址转换为真正的目标机地址,通常指响应报文)
2) INPUT:报文进入本机用户空间位置,允许的表filter, mangle
3) OUTPUT:报文从本机用户空间出去的位置,允许filter, mangle, nat
4) FOWARD:报文经过路由并且发觉不是本机决定转发但还不知道从哪个网卡出去,允许filter, mangle
5) POSTROUTING:报文经过路由被转发出去,允许mangle,nat(源地址转换,把原始地址转换为转发主机出口网卡地址)
流入本机: PREROUTING --> INPUT --> PROCESS(进程)
从本机流出: PROCESS(进程) --> OUTPUT --> POSTROUTING
经过本机: A ---> OUTPUT ---> POSTROUTING | ---> PREROUTING ---> FORWARD ---> POSTROUTING ---> C ---> PREROUTING ---> INPUT ---> B更多iptables相关参考 Linux之Iptables. Linux之iptables使用 Linux之Iptables模块使用
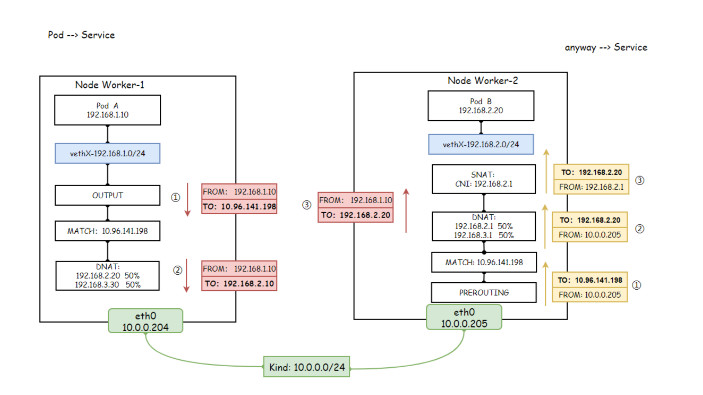
ClusterIP 模式分析
-
从Pod发出的请求会先经过 OUTPUT ,然后被转发到 KUBE-SERVICES 自定义规则链中
sh[root@k8s-master ~]# iptables -t nat -S OUTPUT -P OUTPUT ACCEPT # 默认通过 -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES # 转发到 KUBE-SERVICES -
KUBE-SERVICES 自定义规则链中,所有对nginx-svc发起的请求都会调度到KUBE-SVC- 链上
sh
[root@k8s-master ~]# iptables -t nat -S KUBE-SERVICES
-N KUBE-SERVICES # 创建自定义链
-A KUBE-SERVICES -d 10.107.78.95/32 -p tcp -m comment --comment "default/nginx-svc:http cluster IP" -m tcp --dport 80 -j KUBE-SVC-ELCM5PCEQWBTUJ2I #
...-
查看 KUBE-SVC- 自定义链
sh[root@k8s-master ~]# iptables -t nat -S KUBE-SVC-ELCM5PCEQWBTUJ2I -N KUBE-SVC-ELCM5PCEQWBTUJ2I # 创建自定义链 -A KUBE-SVC-ELCM5PCEQWBTUJ2I ! -s 10.244.0.0/16 -d 10.107.78.95/32 -p tcp -m comment --comment "default/nginx-svc:http cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ 处理 # 来源地址不是 10.244.0.0/16(Pod ip网段) 访问 地址是 10.107.78.95/32 (nginx-svc Service ip) 的IP交给 KUBE-MARK-MASQ 处理 -A KUBE-SVC-ELCM5PCEQWBTUJ2I -m comment --comment "default/nginx-svc:http" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-HCUFVO5PTBGTHQ3U # 第一次 50% 几率(两个pod) -A KUBE-SVC-ELCM5PCEQWBTUJ2I -m comment --comment "default/nginx-svc:http" -j KUBE-SEP-7U4Y7ZRUZBRTYDGE # 第二次100% 几率 -
查看任意一条 KUBE-SEP- 自定义链
sh[root@k8s-master ~]# iptables -t nat -S KUBE-SEP-7U4Y7ZRUZBRTYDGE -N KUBE-SEP-7U4Y7ZRUZBRTYDGE # 创建自定义链 -A KUBE-SEP-7U4Y7ZRUZBRTYDGE -s 10.244.36.76/32 -m comment --comment "default/nginx-svc:http" -j KUBE-MARK-MASQ # 请求ip如果是Pod 的IP,则交给 KUBE-MARK-MASQ 处理 -A KUBE-SEP-7U4Y7ZRUZBRTYDGE -p tcp -m comment --comment "default/nginx-svc:http" -m tcp -j DNAT --to-destination 10.244.36.76:80 # 进行DNAT 地址替换, 将请求 ServiceIP 替换为后端的 PodIP,然后发出请求 -
查看 KUBE-MARK-MASQ
sh[root@k8s-master ~]# iptables -t nat -S KUBE-MARK-MASQ -N KUBE-MARK-MASQ # 创建自定义链 -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000 # 给数据包打上 makr -
OUTPUT 处理完后,数据包会流入 POSTROUTING 链,由 POSTROUTING 链决定怎么发送数据包
sh[root@k8s-master ~]# iptables -t nat -S POSTROUTING -P POSTROUTING ACCEPT # 默认通过 -A POSTROUTING -m comment --comment "cali:O3lYWMrLQYEMJtB5" -j cali-POSTROUTING # calico 网络插件,数据包跳转到 cali-POSTROUTING 自定义链处理 -A POSTROUTING -s 172.20.0.0/16 ! -o docker0 -j MASQUERADE # docker 默认规则不用管 -A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING # 数据包进入 KUBE-POSTROUTING 自定义链处理 -
查看 cali-POSTROUTING 数据链
sh[root@k8s-master ~]# iptables -t nat -S cali-POSTROUTING -N cali-POSTROUTING # 创建自定义链 -A cali-POSTROUTING -m comment --comment "cali:Z-c7XtVd2Bq7s_hA" -j cali-fip-snat # 转到 cali-fip-snat 链 -A cali-POSTROUTING -m comment --comment "cali:nYKhEzDlr11Jccal" -j cali-nat-outgoing # 转到 cali-nat-outgoing 链 -A cali-POSTROUTING -o tunl0 -m comment --comment "cali:JHlpT-eSqR1TvyYm" -m addrtype ! --src-type LOCAL --limit-iface-out -m addrtype --src-type LOCAL -j MASQUERADE # 匹配那些源地址不是从 tunl0 网卡输出出去的数据包,但是源地址是 tunl0 网段的数据包发送到目标ip [root@k8s-master ~]# iptables -t nat -S cali-fip-snat -N cali-fip-snat # 创建自定义链 [root@k8s-master ~]# iptables -t nat -S cali-nat-outgoing -N cali-nat-outgoing # 创建自定义链 -A cali-nat-outgoing -m comment --comment "cali:Dw4T8UWPnCLxRJiI" -m set --match-set cali40masq-ipam-pools src -m set ! --match-set cali40all-ipam-pools dst -j MASQUERADE # 源地址在 cali40masq-ipam-pools 集合中,且目标地址不在 cali40all-ipam-pools 集合中 发送到目标ip tunl0 网卡,calico 创建的网卡 '''ClusterIP 类型走这条规则''' [root@k8s-master ~]# ipset list cali40masq-ipam-pools # 查看ip网段 Name: cali40masq-ipam-pools Type: hash:net Revision: 6 Header: family inet hashsize 1024 maxelem 1048576 Size in memory: 440 References: 1 Number of entries: 1 Members: 10.244.0.0/16 -
查看 KUBE-POSTROUTING 自定义链
sh[root@k8s-master ~]# iptables -t nat -S KUBE-POSTROUTING -N KUBE-POSTROUTING # 创建自定义链 -A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN # 如果没有匹配 0x4000/0x4000 就RETURN 回 POSTROUTING 继续处理 -A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0 # 如果匹配上一条就打上一个 标记 0x4000/0x0 -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE # 对 源地址进行 SNAT, SNAT 节点去往目标IP最近的接口IP地址
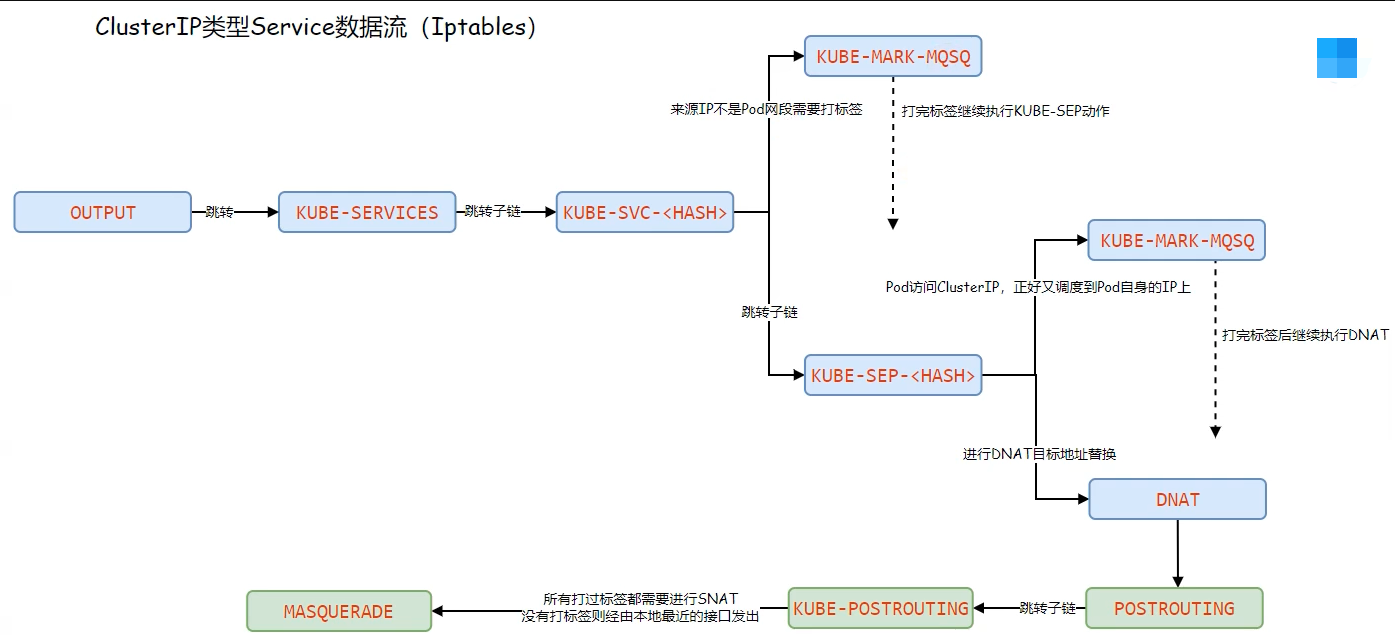
NodePort 模式分析
-
NodePort 先要经过PREROUTING 链,然后将所有请转入KUBE-SERVICES自定义链
sh[root@k8s-master ~]# iptables -t nat -S PREROUTING -P PREROUTING ACCEPT -A PREROUTING -m comment --comment "cali:6gwbT8clXdHdC1b1" -j cali-PREROUTING -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER-INGRESS -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER # cali-PREROUTING 自定义链默认啥都没干,如果用的 flannel 网络组建,就直接转入 KUBE-SERVICES自定义链 [root@k8s-master ~]# iptables -t nat -S cali-PREROUTING -N cali-PREROUTING -A cali-PREROUTING -m comment --comment "cali:r6XmIziWUJsdOK6Z" -j cali-fip-dnat [root@k8s-master ~]# iptables -t nat -S cali-fip-dnat -N cali-fip-dnat -
打印KUBE-SERVICE 自定链,过滤和nodeport 相关规则,规则调度到 KUBE-NODEPORTS
sh[root@k8s-master ~]# iptables -t nat -S KUBE-SERVICES | grep nodeports -A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS -
打印 KUBE-NODEPORTS 自定义链, 后面就转入了 KUBE-SVC-
sh[root@k8s-master ~]# iptables -t nat -S KUBE-NODEPORTS -N KUBE-NODEPORTS -A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx-sc:web" -m tcp --dport 31996 -j KUBE-SVC-IIUXE3BBFAXNZ4WP
在后面和 ClusterIP 流程类似,但是需要注意的是,数据包匹配的规则不一样,所以不能说后面就是 ClusterIP 的链路。
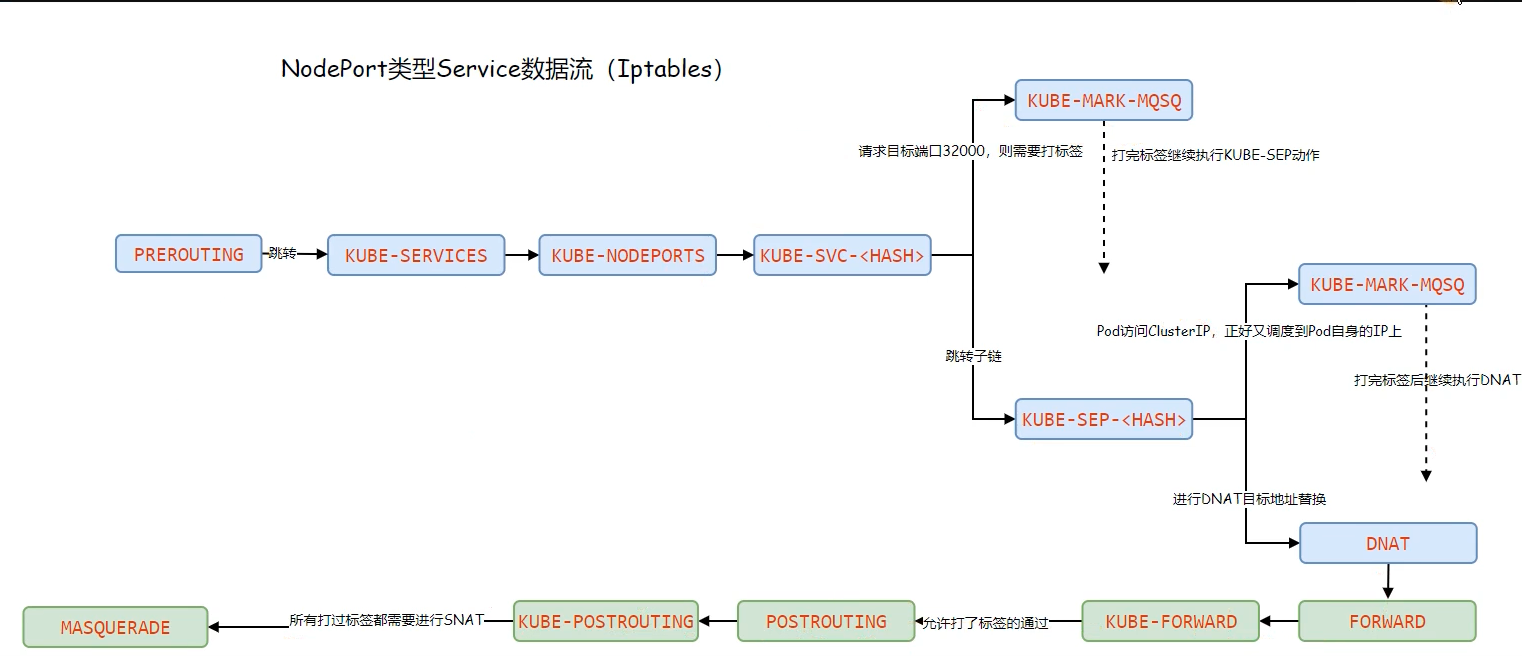
Service- IPVS 模式
- IPVS 会在每个节点上创建一个名为kube-ipvs0的虛拟接口,并将集群所有Service对象的ClusterIP都配置在该接口
- Kube-Proxy将每个Service生成一个虚拟服务器VirtualServer的定义(集群ip,集群对应后端的ip)
注意:ipvs仅需要借助极少量的iptables规则完成源地址转换、源端口转换等;
设置集群为IPVS模式:
yaml
[root@k8s-master ~]# kubectl edit cm kube-proxy -n kube-system # 修改 kube-proxy 配置文件
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" # 该为 ipvs 即可
nodePortAddresses: null
oomScoreAdj: null
# 删除原来的 kube-proxy pod ,重启更新配置
[root@k8s-master ~]# kubectl delete po -l k8s-app=kube-proxy -n kube-system
# 下载 ipvsadm
[root@k8s-master ~]# yum install -y ipvsadm
# 通过 ipvsadm 查看
[root@k8s-master ~]# ipvsadm -Ln
# 并且会加上一个 kube-ipvs0 网卡
[root@k8s-master ~]# ip addr | grep kube-ipvs0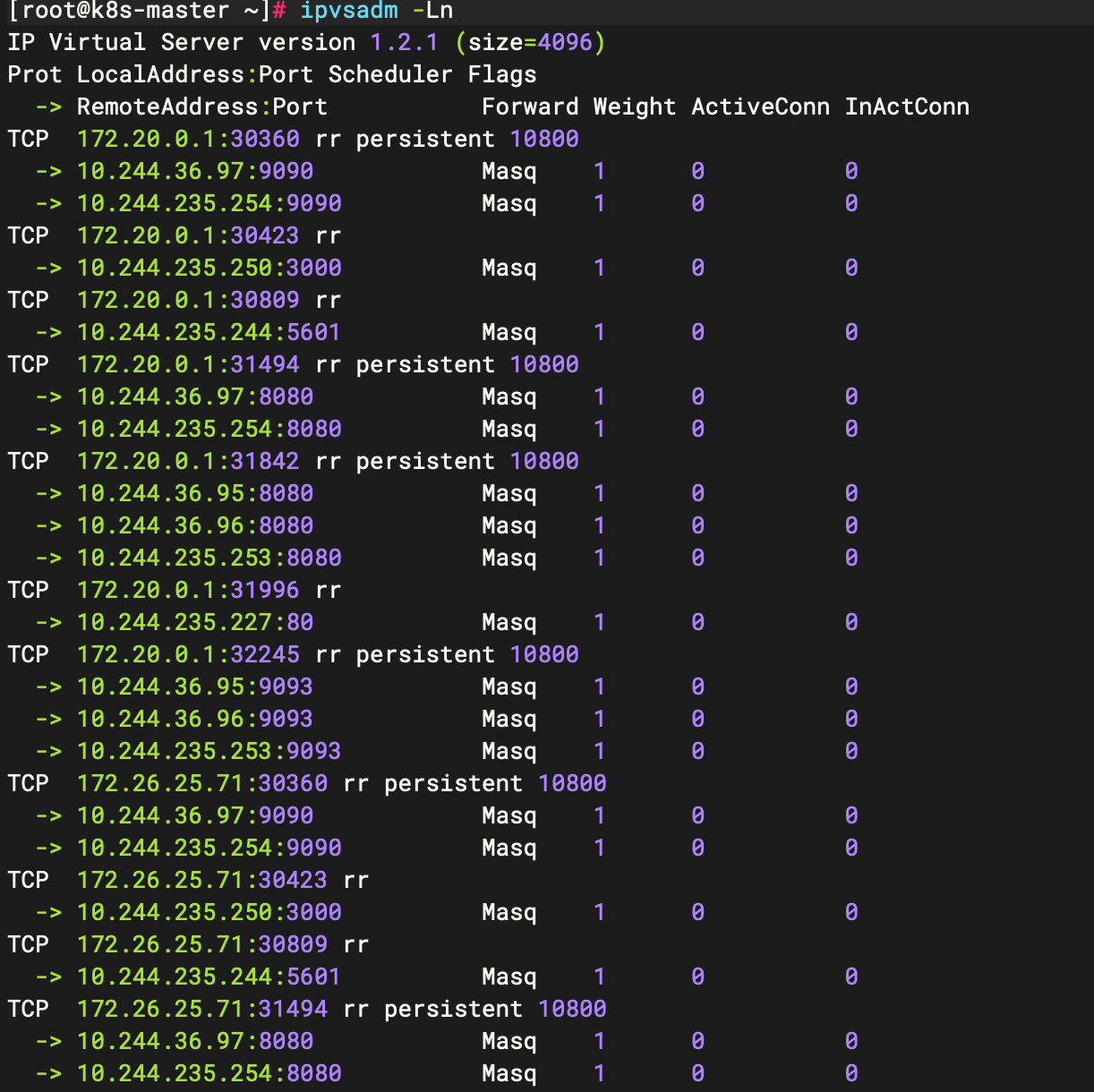
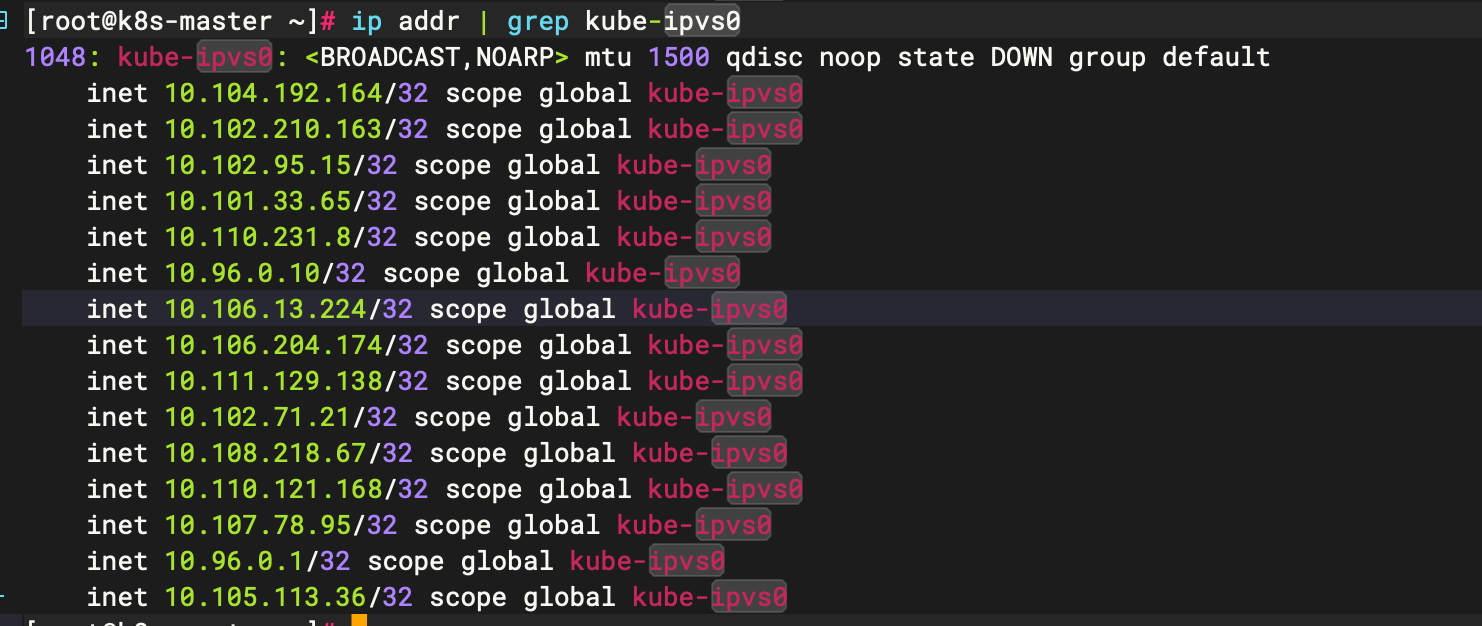
服务发现
当Pod需要访问Service时,通过Service提供的ClusterIP就可以实现了,但是有几个问题;
- Service的IP不稳定,删除重建会发生变化;
- ServiceIP难以记忆,如果能通过一个固定的名称访问就好了;
为了解决这样的问题,kubernetes引入了环境变量和DNS两种方案来解决这样的问题;
- 环境变量方式:通过特定的名称将环境变量注入到Pod内部;
- DNS方式:通过APIServer来监视Service变动,而后动态创建对应Service名称与ServiceIP的域名解析记录;
环境变量
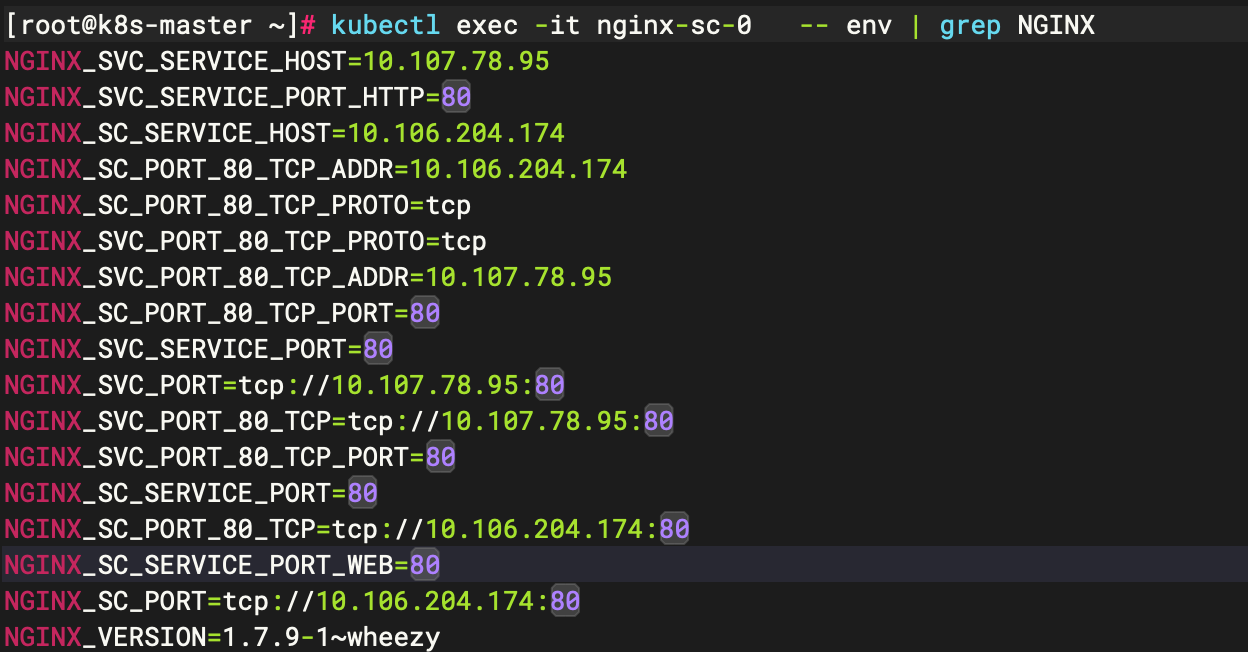
每个 Pod 启动的时候,会通过环境变量的方式将Service的IP以及Port信息注入进去,这样 Pod 中的应用可以通过读取环境变量来获取对应service服务的地址信息,这种方法使用起来相对简单但是也存在一定的问题。就是Pod所依赖的Service必须优Pod启动,否则无法注入到环境变量中。
CoreDNS
在安装Kubernetes集群时,CoreDNS作为附加组件,用来为Pod提供DNS域名解析。CoreDNs监视 Kubernetes API 中的新service, 并为每个service名称创建一组DNS 记录。这样我们就可以通过固定的Service名称来转换出不固定ServiceIP
sh
[root@k8s-master ~]# kubectl get cm coredns -n kube-system -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors # 错误记录
health { # 健康检查
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { # 用于解析kubernets 集群内域名
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153 # 监控端口
forward . /etc/resolv.conf { # 如果请求非kubernetes 域名,则用节点resolv.conf 中的dns解析
max_concurrent 1000
}
cache 30 # 缓存所有内容
loop
reload # 支持热更新
loadbalance # 负载均衡,默认轮询
}
kind: ConfigMapCoreDNS 之所以是固定IP 以及固定的搜索域。是因为kubelet 将 --cluster-dns=、 --cluster-domain= 对应的配置传递给了每个容
sh
[root@k8s-master ~]# cat /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
...
clusterDNS:
- 10.96.0.10 # DNS 固定的ServiceIP
clusterDomain: cluster.local # 域名
...
[root@k8s-master ~]# kubectl exec -it nginx-sc-0 -- bash
root@nginx-sc-0:/# cat /etc/resolv.conf
nameserver 10.96.0.10 # pod 里面默认配置的 dns 把这个配置到节点中,就能在节点上通过域名访问pod了
search default.svc.cluster.local svc.cluster.local cluster.local # dns 解析器会依次尝试在这个列表中的每个域名后缀前加上这个短域名,并查询新构造的完整域名
options ndots:5CoreDNS 策略
DNS策略可以单独对Pod进行设定,在创建Pod时可以为其指定DNS策略,最终配置会落在Pod的/etc/resolv.conf 文件中,可以通过 pod.spec.dnsPolicy 字段设置DNS的策略
ClusterFirst(默认DNS策略)
Pod 内的DNS使用集群中配置的DNS服务,简单来说就是使用Kubernets 中的 coredns 服务进行域名解析。如果不成功, 会使用当前Pod 所在的宿主机DNS 进行解析
yaml
apiVersion: v1
kind: Pod
metadata:
name: dns-example-1
spec:
dnsPolicy: ClusterFirst
containers:
- name: tools
image: nginx:1.7.9
ports:
- containerPort: 8899CluterFirstWithHostNet
在某些场景下,我们的 Pod是用HostNetwork 模式启动的,一旦使用HostNetwork 模式,那该Pod则会使用当前宿主机的/etc/resolv.conf、来进行 DNS 查询,但如果任然想继续使用Kubernetes 的DNS服务,那就将dnsPolicy 设置为ClusterFirstWithHostNet
yaml
apiVersion: v1
kind: Pod
metadata:
name: dns-example-2
spec:
hostNetwork: true # 与宿主机共享网络名称空间 如果只设置这个,就不会使用coredns服务,无法通过域名解析找到对应的pod
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: tools
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8899Default
默认使用宿主机的 /etc/resolv.conf 但可以使用kubelet 的 --resolv-conf=/etc/resolv.conf 来指定DNS 解析文件地址
None
空的DNS设置,这种方式一般用于自定义 DNS 配置的场景, 往往需要和dnsConfig 一起使用才能达到自定义DNS的目录
yaml
apiVersion: v1
kind: Pod
metadata:
name: dns-example-4
spec:
containers:
- name: tools
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8899
dnsPolicy: None
dnsConfig:
nameservers:
- 10.96.0.10
- 114.114.114.114
searches:
- cluster.local
- svc.cluster.local
- default.svc.cluster.local
options:
- name: ndots
value: "5"HeadLess Service
HeadlessService也叫无头服务,就是创建的Service没有ClusterIP,而是为Service所匹配的每个Pod都创建一条DNS的解析记录,这样每个Pod都有一个唯一的DNS名称标识身份,访问的格式如下
( s e r v i c e n a m e ) . (service_name). (servicename).(namespace).svc.clustter.local

Headless的作用
像elasticsearch,mongodb, kafka 等分布式服务,在做集群初始化时,配置文件中要写上集群中所有节点的工P(或是域名)但Pod是没有固定IP的,所以配置文件里写DNS名称是最合适的。
那为什么不用Service, 因为 Service 作为 Pod 前置的负载均衡,一般是为一组相同的后端 Pod 提供访问入口,而且 Service的selector也没有办法区分同一组Pod的不同身份。
但是我们可以使用 Statefulset控制器,它在创建每个Pod的时候,能为每个 Pod 做一个编号,就是为了能区分这一组Pod的不同角色,各个节点的角色不会变得混乱,然后再创建 headless service 资源,集群内的节点通过Pod名称+序号.Service名称,来进行彼此问通信的,只要序号不变,访问就不会出错。
当 statefulset.spec.serviceName 配置与headless service相同时,可以通过 thostName}.theadless service} .{namespace}.svc.cluster.local 解析出节点IP。hostName 由{statefulset name}-{编号} 组成。
HeadLess 示例
yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
spec:
clusterIP: "None" # 设置为None 表示无头服务
selector:
app: nginx-head
ports:
- port: 80
targetPort: 80
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web-head
spec:
serviceName: "myapp"
replicas: 3
selector:
matchLabels:
app: nginx-head
template:
metadata:
labels:
app: nginx-head
spec:
containers:
- name: nginx-sts-head
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80查看创建的pod
sh
[root@k8s-master demo]# kubectl get po
NAME READY STATUS RESTARTS AGE
web-head-0 1/1 Running 0 2m23s
web-head-1 1/1 Running 0 2m20s
web-head-2 1/1 Running 0 2m19s测试
sh
[root@k8s-master demo]# kubectl exec -it nginx-sc-0 -- bash # 随便找一个pod 进去
root@nginx-sc-0:/# ping web-head-0.myapp.default.svc.cluster.local
PING web-head-0.myapp.default.svc.cluster.local (10.244.235.199): 48 data bytes
56 bytes from 10.244.235.199: icmp_seq=0 ttl=63 time=0.193 ms
56 bytes from 10.244.235.199: icmp_seq=1 ttl=63 time=0.198 ms
56 bytes from 10.244.235.199: icmp_seq=2 ttl=63 time=0.191 ms
root@nginx-sc-0:/# ping web-head-1.myapp.default
PING web-head-1.myapp.default.svc.cluster.local (10.244.36.100): 48 data bytes
56 bytes from 10.244.36.100: icmp_seq=0 ttl=62 time=1.367 ms
root@nginx-sc-0:/# ping web-head-2.myapp
PING web-head-2.myapp.default.svc.cluster.local (10.244.235.203): 48 data bytes
56 bytes from 10.244.235.203: icmp_seq=0 ttl=63 time=0.138 ms
56 bytes from 10.244.235.203: icmp_seq=1 ttl=63 time=0.234 ms