4. alertmanager
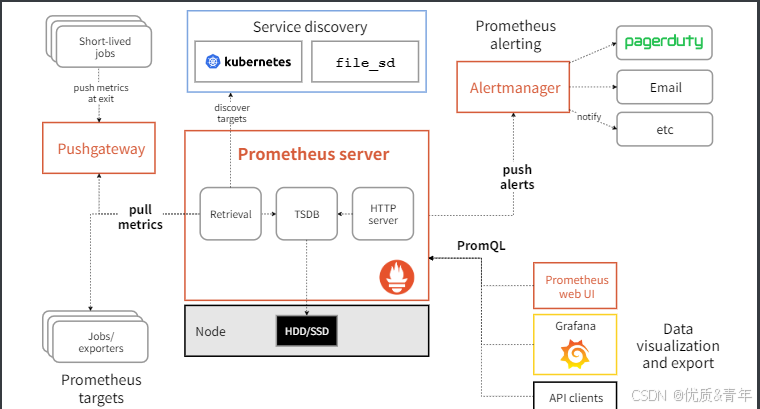
alertmanager架构图
警处理全链路
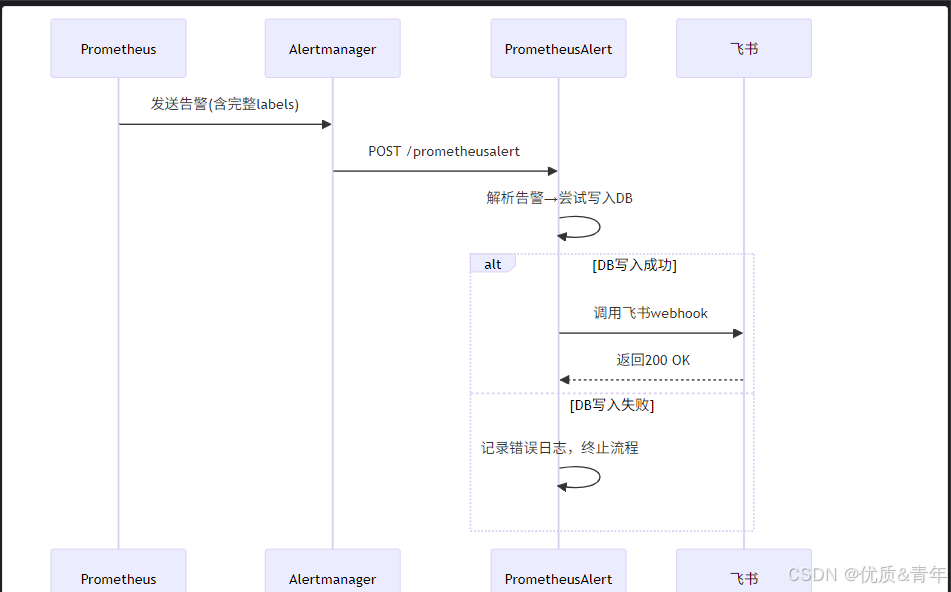
从官网的架构可以看出alertmanager的作用是接收Prometheus的告警通知然后再通过webhook发送到第三方媒介如飞书、钉钉。由于每个媒介的webhook接口是不一样的故可以通过Prometheusalert第三方开源的webhook集成器来完成消息的发送
参考链接:https://github.com/feiyu563/PrometheusAlert/blob/master/doc/readme/conf-feishu.md
4.1 部署PrometheusAlert服务
Prometheus服务默认没有做数据持久化,故需做持久化,持久化可选择的库参考官方文档说明,我这里采用mysql数据库
bash
#Kubernetes中运行可以直接执行以下命令行即可(注意默认的部署模版中未挂载模版数据库文件 db/PrometheusAlertDB.db,为防止模版数据丢失,请自行增加挂载配置 )
kubectl apply -n monitoring -f https://raw.githubusercontent.com/feiyu563/PrometheusAlert/master/example/kubernetes/PrometheusAlert-Deployment.yaml
#启动后可使用浏览器打开以下地址查看:http://[YOUR-PrometheusAlert-URL]:8080
#默认登录帐号和密码在app.conf中有配置4.2 部署mysql数据库
4.2.1 编写mysql deployment
bash
vim deploy-mysql.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mysql
name: mysql
namespace: prometheus-mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: harbor.cloudtrust.com.cn:30381/hangyan/mysql:9.4
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-user-pass
key: root.password
- name: MYSQL_USER
valueFrom:
secretKeyRef:
name: mysql-user-pass
key: user.name
- name: MYSQL_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-user-pass
key: user.password
- name: MYSQL_DATABASE
valueFrom:
secretKeyRef:
name: mysql-user-pass
key: database.name
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql/
volumes:
- name: mysql-data
persistentVolumeClaim:
claimName: mysql-data4.2.2 编写mysql pvc
bash
vim pvc-mysql.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-data
namespace: prometheus-mysql
spec:
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: nfs-prometheus4.2.3编写mysql secret
bash
vim service-mysql.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: mysql
name: mysql
namespace: prometheus-mysql
spec:
ports:
- name: mysql
port: 3306
protocol: TCP
targetPort: 3306
selector:
app: mysql
type: ClusterIP4.2.4编写mysql svc
bash
vim service-mysql.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: mysql
name: mysql
namespace: prometheus-mysql
spec:
ports:
- name: mysql
port: 3306
protocol: TCP
targetPort: 3306
selector:
app: mysql
type: ClusterIP
root@kcsmaster1:~/prometheus-mysql# cat service-mysql.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: mysql
name: mysql
namespace: prometheus-mysql
spec:
ports:
- name: mysql
port: 3306
protocol: TCP
targetPort: 3306
selector:
app: mysql
type: ClusterIP
#验证服务
root@kcsmaster1:~/prometheus-mysql# kubectl get pod -n prometheus-mysql
NAME READY STATUS RESTARTS AGE
mysql-7c48d67979-7dmxf 1/1 Running 0 17d4.3 配置PrometheusAlert使用mysql作为后端数据存储
4.3.1 修改PrometheusAlert服务的configmap文件
bash
#数据库驱动,支持sqlite3,mysql,如使用mysql,请开启db_host,db_user,db_password,db_name的注释
46 db_driver=mysql
47 db_host=mysql.prometheus-mysql.svc.cluster.local
48 db_port=3306
49 db_user=root
50 db_name=prometheusalert
51 db_password=Trantect132_
88 #是否开启飞书告警通道,可同时开始多个通道0为关闭,1为开启
89 open-feishu=1
90 #默认飞书机器人地址
91 fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/75cd688d-07e8-471e-9035-49d6a052f3454.3.2 配置mysql数据库
- 创建数据库
bash
CREATE DATABASE prometheusalert CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;- 修改alert_record字段类型
bash
-- 修改 labels 字段为 LONGTEXT(支持最大 4GB 数据)
ALTER TABLE alert_record MODIFY labels LONGTEXT NOT NULL;
-- 建议同时修改其他可能超长的字段
ALTER TABLE alert_record MODIFY description LONGTEXT NOT NULL;
ALTER TABLE alert_record MODIFY summary LONGTEXT NOT NULL;4.4 配置Alertmanager服务
4.4.1 熟悉Alertmanager CRD资源
bash
root@kcsmaster1:~/operator-prometheus# kubectl explain alertmanager.spec.alertmanagerConfigSelector
GROUP: monitoring.coreos.com
KIND: Alertmanager
VERSION: v1
FIELD: alertmanagerConfigSelector <Object>
DESCRIPTION:
AlertmanagerConfigs to be selected for to merge and configure Alertmanager
with.
FIELDS:
matchExpressions <[]Object>
matchExpressions is a list of label selector requirements. The requirements
are ANDed.
matchLabels <map[string]string>
matchLabels is a map of {key,value} pairs. A single {key,value} in the
matchLabels map is equivalent to an element of matchExpressions, whose key
field is "key", the operator is "In", and the values array contains only
"value". The requirements are ANDed.
#由此可以看出Alertmanager 服务的配置文件是根据alertmanagerConfigSelector 标签来捆绑的根据alertmanager-main pod的配置可以得出以下结论:Alertmanager服务的配置存放在/etc/alertmanager/config_out目录下的alertmanager.env.yaml文件里面
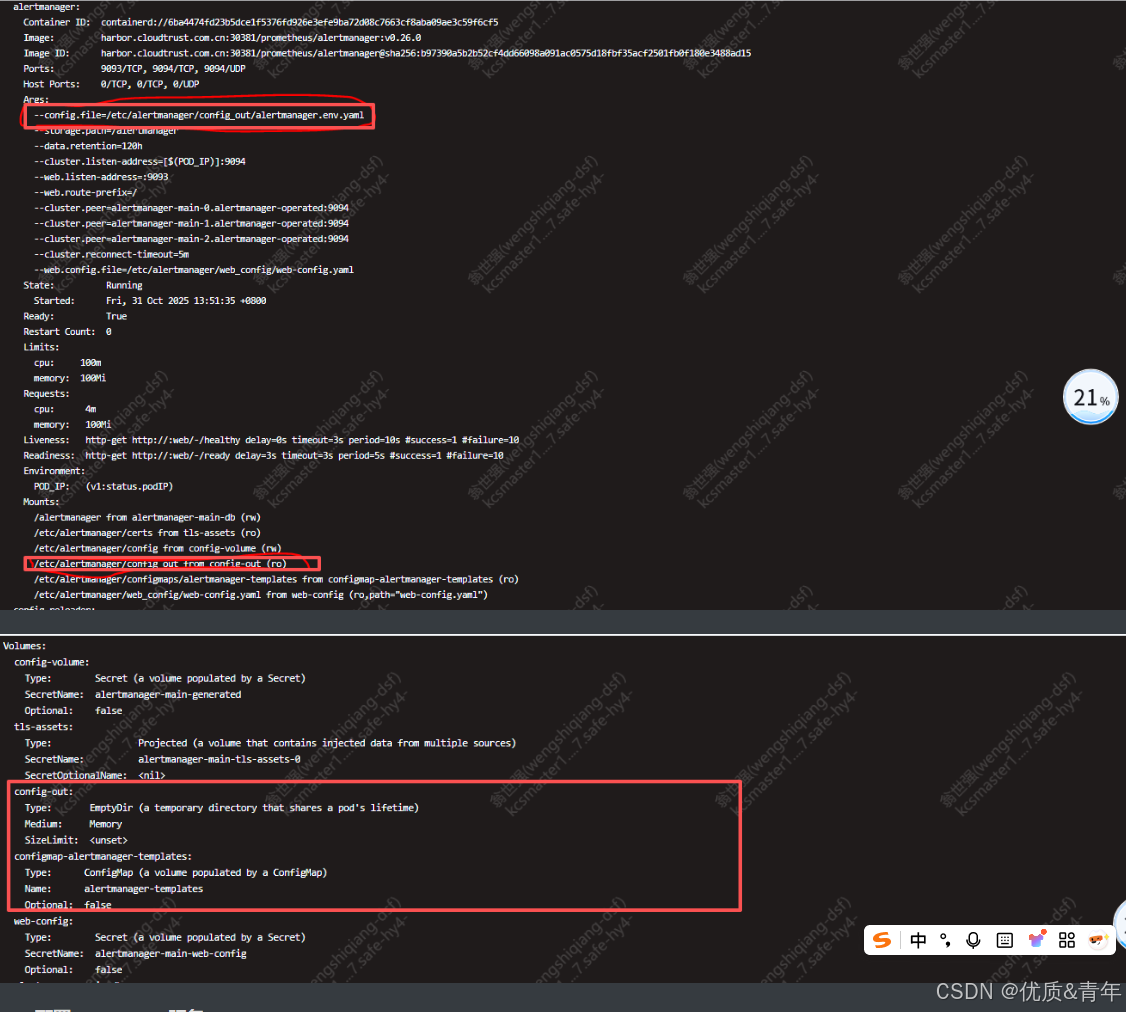
4.4.2 配置alertmanager服务
4.4.2.1修改alertmanager-alertmanager.yaml
bash
root@kcsmaster1:~/operator-prometheus# cat /apprun/kube-prometheus-release-0.13/manifests/alertmanager-alertmanager.yaml
#添加以下内容
alertmanagerConfigSelector:
matchLabels:
alertmanagerConfig: alertmanager-config #用来匹配alertmanager-config文件的4.4.2.2 创建alertmanager的配置文件
bash
root@kcsmaster1:~/operator-prometheus# cat alertmanager-config.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: feishu
namespace: monitoring
labels:
alertmanagerConfig: alertmanager-config #这个标签需要和alertmanager-alertmanager.yaml里面的alertmanagerConfigSelector标签保持一致
spec:
receivers: #接收器的配置
- name: feishu-receiver #定义告警接收器的名称
webhookConfigs:
- url: http://prometheus-alert-center.monitoring.svc.cluster.local:8080/prometheusalert?type=fs&tpl=行研应用中心&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/75cd688d-07e8-471e-9035-49d6a052f345 #webhook接收消息的媒介
sendResolved: true #是否在告警解决时发送通知
route: #路由配置
groupBy: ["namespace"] #根据namespace分组
groupWait: 30s #等待时间,在发送第一批告警前等待新告警加入分组的时间
groupInterval: 5m #分组间隔,发送同一组告警新消息前等待的时间
repeatInterval: 12h #重复间隔,发送已发送过的告警的频率
receiver: feishu-receiver #路由的接收器,需和上面定义的接收器名称保持一致
routes: #子路由配置
- receiver: feishu-receiver #子路由接收器
matchers: #用于匹配告警的标签
- name: severity
value: "warning|critical"
regex: true
inhibitRules: #抑制告警路由规则
# 基本抑制:Critical抑制同一资源的Warning
- sourceMatch:
- name: severity
value: "critical"
targetMatch:
- name: severity
value: "warning"
equal: ["namespace", "alertname"]
# 集群级别抑制:集群问题抑制节点级别告警
- sourceMatch:
- name: alertname
value: "KubeAPIDown|KubeControllerManagerDown|KubeSchedulerDown"
targetMatch:
- name: alertname
value: "NodeDown|PodCrashLooping|CPUThrottlingHigh"
equal: ["cluster"]
#部署
kubectl apply -f alertmanager-config.yaml4.4.2.3 检查配置是否生效
bash
1、热加载
curl -X POST http://10.10.115.146:9093/-/reload
2、进入alertmanager-main pod里面的alertmanager.env.yaml文件是否读取到你的配置4.5 配置模版
4.5.1 使用PrometheusAlert自定义模版
模版内容
{{- $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved" -}}
[{{$v.labels.alertname}}]({{$var}})
告警环境:{{$v.labels.env}}
告警对象:{{$v.labels.object}}
告警级别:{{$v.labels.severity}}
告警状态:{{$v.status}} (✅ ( ̄▽ ̄)ノ 当前告警已恢复!!!)
开始时间:{{GetCSTtime $v.startsAt}}
结束时间:{{GetCSTtime $v.endsAt }}
{{$v.annotations.description}}
{{- else -}}
[{{$v.labels.alertname}}]({{$var}})
告警环境:{{$v.labels.env}}
告警对象:{{$v.labels.object_name}}
告警级别:{{$v.labels.severity}}
故障主机IP:{{$v.labels.instance}}
{{if eq $v.labels.severity "critical" -}}
告警级别:🔥 (╯°□°)╯︵ ┻━┻ {{$v.labels.severity}} (P0级告警,请立即处理!!!)
{{ else if eq $v.labels.severity "warning" -}}
告警级别:⚠️ ( ̄ω ̄;) {{$v.labels.severity}} (P1级告警,请24h之内处理!!)
{{ else -}}
告警级别:ℹ️ (・_・ヾ {{$v.labels.severity}}
{{end -}}
开始时间:{{GetCSTtime $v.startsAt}}
结束时间:{{GetCSTtime $v.endsAt }}
{{$v.annotations.description}}
{{end -}}
{{ end -}}4.5.2 编写template挂载到alertmanager服务里
4.5.2.1 创建template的configmap文件
bash
root@kcsmaster1:~/operator-prometheus# cat alertmanager-template.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-templates
namespace: monitoring
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
data:
feishu.tmpl: |
{{- $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved" -}}
[{{$v.labels.alertname}}]({{$var}})
告警环境:{{$v.labels.env}}
告警集群:{{$v.labels.cluster}}
告警平台: {{$v.labels.region}}
故障主机IP:{{$v.labels.instance}}
告警级别:{{$v.labels.severity}}
告警状态:{{$v.status}} (✅ ( ̄▽ ̄)ノ 当前告警已恢复!!!)
开始时间: {{ $v.startsAt.Format "2006-01-02 15:04:05 MST" }}
结束时间:{{ $v.endsAt.Format "2006-01-02 15:04:05 MST" }}
{{$v.annotations.description}}
{{- else -}}
[{{$v.labels.alertname}}]({{$var}})
告警环境:{{$v.labels.env}}
告警集群:{{$v.labels.cluster}}
告警平台: {{$v.labels.region}}
故障主机IP:{{$v.labels.instance}}
{{if eq $v.labels.severity "critical" -}}
告警级别:🔥 (╯°□°)╯︵ ┻━┻ {{$v.labels.severity}} (P0级告警,请立即处理!!!)
{{ else if eq $v.labels.severity "warning" -}}
告警级别:⚠️ ( ̄ω ̄;) {{$v.labels.severity}} (P1级告警,请24h之内处理!!)
{{ else -}}
告警级别:ℹ️ (・_・ヾ {{$v.labels.severity}}
{{end -}}
开始时间:{{ $v.startsAt.Format "2006-01-02 15:04:05 MST" }}
结束时间:{{ $v.endsAt.Format "2006-01-02 15:04:05 MST" }}
{{$v.annotations.description}}
{{end -}}
{{ end -}}
kubectl apply -f alertmanager-template.yaml4.5.2.2 将template的卷挂载到alertmanager服务上
bash
由于alertmanager.yml默认挂载的是alertmanager-main-generated secret卷,无法在线edit修改,故需要修改alertmanager.yml挂载卷
root@kcsmaster1:~/operator-prometheus# kubectl get secret -n monitoring
NAME TYPE DATA AGE
additional-configs Opaque 1 62d
alertmanager-main Opaque 1 4d23h #让alertmanager挂载这个secret卷
alertmanager-main-generated Opaque 1 4d23h
alertmanager-main-tls-assets-0 Opaque 0 68d
alertmanager-main-web-config Opaque 1 68d
etcd-client-certs Opaque 3 67d
grafana-config Opaque 1 68d
grafana-datasources Opaque 1 68d
prometheus-k8s Opaque 1 63d
prometheus-k8s-tls-assets-0 Opaque 0 63d
prometheus-k8s-web-config Opaque 1 63d
(1) 修改alertmanager-alertmanager.yaml配置
root@kcsmaster1:~/operator-prometheus# cat /apprun/kube-prometheus-release-0.13/manifests/alertmanager-alertmanager.yaml
configSecret: alertmanager-main #修改这个参数,默认是{}走的是alertmanager-main-generated卷
(2) 创建alertmanager.yml文件
root@kcsmaster1:~/operator-prometheus# cat alertmanager.yaml
global:
resolve_timeout: 5m
route:
receiver: Default
group_by:
- namespace
routes:
- receiver: monitoring/feishu/Critical
group_by:
- namespace
matchers:
- namespace="monitoring"
continue: true
routes:
- receiver: monitoring/feishu/Critical
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
- receiver: Watchdog
matchers:
- alertname = Watchdog
- receiver: "null"
matchers:
- alertname = InfoInhibitor
- receiver: Critical
matchers:
- severity = critical
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
inhibit_rules:
- target_matchers:
- severity =~ warning|info
source_matchers:
- severity = critical
equal:
- namespace
- alertname
- target_matchers:
- severity = info
source_matchers:
- severity = warning
equal:
- namespace
- alertname
- target_matchers:
- severity = info
source_matchers:
- alertname = InfoInhibitor
equal:
- namespace
receivers:
- name: Default
- name: Watchdog
- name: Critical
- name: "null"
- name: monitoring/feishu/Critical
webhook_configs:
- send_resolved: true
url: http://111.1.51.58:30382/prometheusalert?type=fs&tpl=行研应用中心&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/75cd688d-07e8-471e-9035-49d6a052f345
templates:
- '/etc/alertmanager/config/*.tmpl'
(3) 更新alertmanager-main secret卷
root@kcsmaster1:~/operator-prometheus# kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --dry-run=client -o yaml | kubectl apply -f - -n monitoring
(4) 验证配置是否生效
root@kcsmaster1:~/operator-prometheus# kubectl get secret alertmanager-main -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' | base64 -d
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = critical"
"target_matchers":
- "severity =~ warning|info"
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = warning"
"target_matchers":
- "severity = info"
- "equal":
- "namespace"
"source_matchers":
- "alertname = InfoInhibitor"
"target_matchers":
- "severity = info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "Critical"
- "name": "null"
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "Watchdog"
- "matchers":
- "alertname = InfoInhibitor"
"receiver": "null"
- "matchers":
- "severity = critical"
"receiver": "Critical"
"templates":
- "/etc/alertmanager/configmaps/alertmanager-templates/*.tmpl"
#进入alertmanager-main-0查看是否有feishu.tmpl模版文件
root@kcsmaster1:~/operator-prometheus# kubectl exec -it alertmanager-main-1 -n monitoring sh
/etc/alertmanager/configmaps/alertmanager-templates $ pwd
/etc/alertmanager/configmaps/alertmanager-templates
/etc/alertmanager/configmaps/alertmanager-templates $ ls
feishu.tmpl
/etc/alertmanager/configmaps/alertmanager-templates $ cat custom.tmpl
{{- $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved" -}}
[{{$v.labels.alertname}}]({{$var}})
告警环境:{{$v.labels.env}}
告警集群:{{$v.labels.cluster}}
告警平台: {{$v.labels.region}}
故障主机IP:{{$v.labels.instance}}
告警级别:{{$v.labels.severity}}
告警状态:{{$v.status}} (✅ ( ̄▽ ̄)ノ 当前告警已恢复!!!)
开始时间: {{ $v.startsAt.Format "2006-01-02 15:04:05 MST" }}
结束时间:{{ $v.endsAt.Format "2006-01-02 15:04:05 MST" }}
{{$v.annotations.description}}
{{- else -}}
[{{$v.labels.alertname}}]({{$var}})
告警环境:{{$v.labels.env}}
告警集群:{{$v.labels.cluster}}
告警平台: {{$v.labels.region}}
故障主机IP:{{$v.labels.instance}}
{{if eq $v.labels.severity "critical" -}}
告警级别:🔥 (╯°□°)╯︵ ┻━┻ {{$v.labels.severity}} (P0级告警,请立即处理!!!)
{{ else if eq $v.labels.severity "warning" -}}
告警级别:⚠️ ( ̄ω ̄;) {{$v.labels.severity}} (P1级告警,请24h之内处理!!)
{{ else -}}
告警级别:ℹ️ (・_・ヾ {{$v.labels.severity}}
{{end -}}
开始时间:{{ $v.startsAt.Format "2006-01-02 15:04:05 MST" }}
结束时间:{{ $v.endsAt.Format "2006-01-02 15:04:05 MST" }}
{{$v.annotations.description}}
{{end -}}
{{ end -}}4.6 配置分级告警路由
在实际生产环境中pod是有namespace命令空间的区分,故需要结合多级告警路由来分发告警规则
bash
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: feishu-global
namespace: monitoring
spec:
receivers:
- name: feishu-receiver
webhookConfigs:
- url: http://your-webhook-url #webhook的url地址
route:
groupBy: [namespace, alertname]
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: feishu-receiver
routes:
# 特定命名空间的路由(优先匹配)
- receiver: critical-team-receiver
matchers:
- name: namespace
value: "production"
- name: severity
value: "critical"
- receiver: database-team-receiver
matchers:
- name: namespace
value: "database"
# 默认路由(处理所有其他命名空间)
- receiver: feishu-receiver
matchers:
- name: severity
value: "warning|critical"
regex: true5.告警Rules
5.1 prometheus server识别到rules文件
注意:由于我alertmanager配置的是以namespace分组,故rule规则里面需包含namespace这个label标签,否则alertmanager收不到prometheus发的告警信息
bash
root@kcsmaster1:/apprun/kube-prometheus-release-0.13/manifests# cat prometheus-prometheus.yaml
ruleSelector:
matchLabels: #标签必须配置一下两个,Operator Prometheus自带的rule的CRD资源的标签是这两个
prometheus: k8s
role: alert-rules
#配置标签
root@kcsmaster1:/apprun/kube-prometheus-release-0.13/manifests# cat etcd-Ruleprometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels: #标签需要和prometheus-prometheus.yaml文件里面的ruleSelector标签选择器里面的标签保持一致
prometheus: k8s
role: alert-rules
name: etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd.rules
rules:
- alert: EtcdClusterUnavailable
annotations:
description: Configuration has failed to load for {{ $labels.namespace }}/{{ $labels.pod}}.
summary: Reloading an Alertmanager configuration has failed.
expr: |
count(up{job="etcd"} == 0 ) > (count(up{job="etcd"}) / 2 -1)
for: 10m
labels:
severity: critical
bash
prometheus还缺业务根据prometheus的相关指标实现自动化伸缩副本数以及prometheus分布式部署以及数据远端存储,后面有时间在补充!