1. 置信度(Confidence)的概念
置信度(Confidence)在机器学习和统计中通常指一个模型对其做出的预测是正确的确信程度。在分类任务中,置信度通常由模型赋予特定类别的概率值来表示。例如,在文本分类或实体识别任务中,模型可能预测一个单词是一个特定实体的类别(比如人名),并给出这个预测是正确的概率,这个概率就是置信度。
2. 置信度(Confidence)的重要性
决策制定:在自动化决策过程中,置信度可以帮助确定是否应该依赖模型的预测结果。
结果解释:提供一个可解释性指标,说明模型预测的不确定性。
性能评估:分析模型的可靠性,尤其是在处理真实世界数据时的鲁棒性。
错误分析:识别模型可能需要进一步改进的领域。
如果一个模型给出一个很高的置信度值,那么我们可以认为模型非常确信它的预测是正确的。但是,即使模型对预测很有信心,预测结果也可能是错误的,这就是为什么评估一个模型不仅要看置信度,还要看实际的性能指标,如准确度、召回率和F1分数等。
3. 置信度(Confidence)的例子
置信度通常是指模型对于其做出的预测或决策有多确信。在机器学习和特别是在分类问题中,置信度是一个概率值,通常介于0到1之间,表示预测的可靠程度。置信度高意味着模型相信它的预测结果是正确的概率大;相反,置信度低则意味着模型不太确定它的预测是正确的。
3.1 例子1
假设我们有一个邮件分类器,其任务是将邮件分为"垃圾邮件"或"非垃圾邮件"。当一封新邮件到达时,分类器会分析邮件内容,并基于学习到的规则给出一个预测,同时提供一个置信度分数。
如果分类器预测一封邮件是垃圾邮件,并给出了0.95的置信度,这意味着模型认为有95%的概率这封邮件是垃圾邮件。这是一个高置信度预测,模型非常确信它的判断。
相反,如果分类器对另一封邮件的预测置信度只有0.55,这意味着虽然模型倾向于将其分类为某一类(比如垃圾邮件),但它对此并不太有把握,几乎是五五开的情况。
在实际应用中,根据任务的不同,我们可能会根据预测的置信度设定一个阈值,只有当预测的置信度超过这个阈值时,我们才采取相应的行动,或者当置信度较低时可能会转交给人工进行进一步的审核。
3.2 例子2
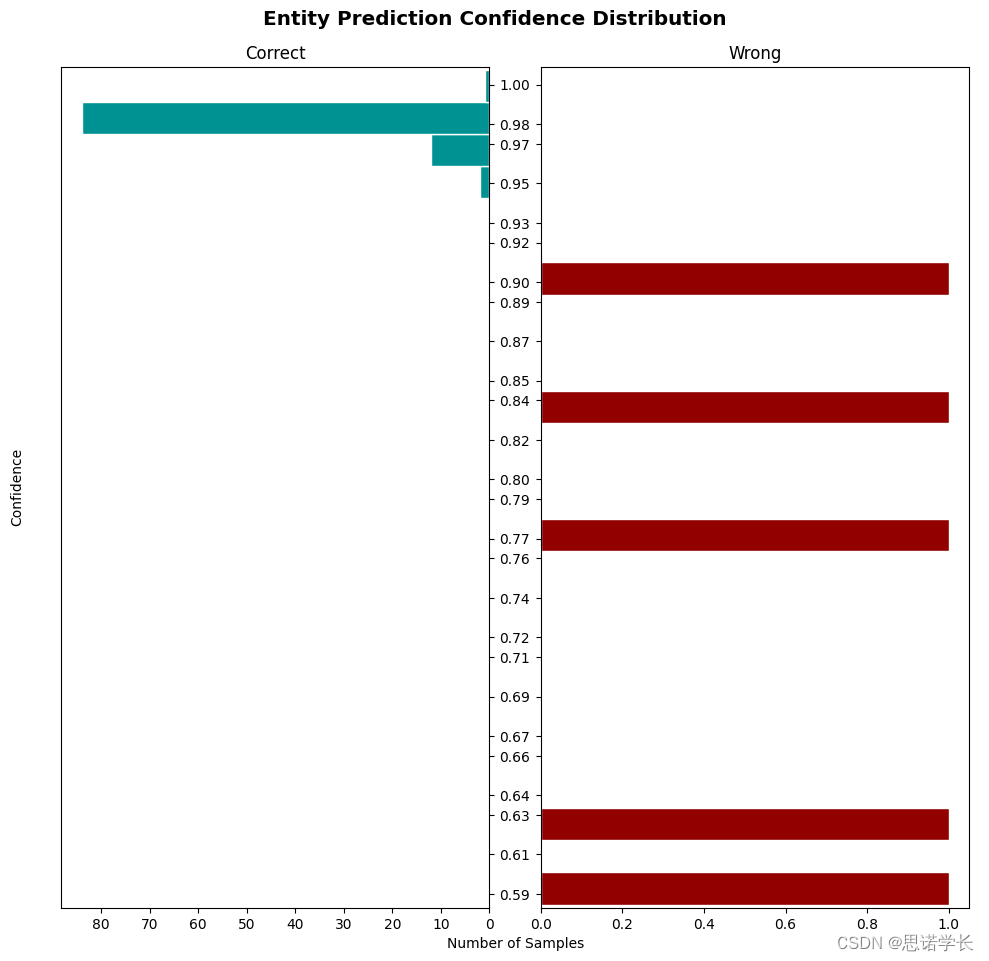
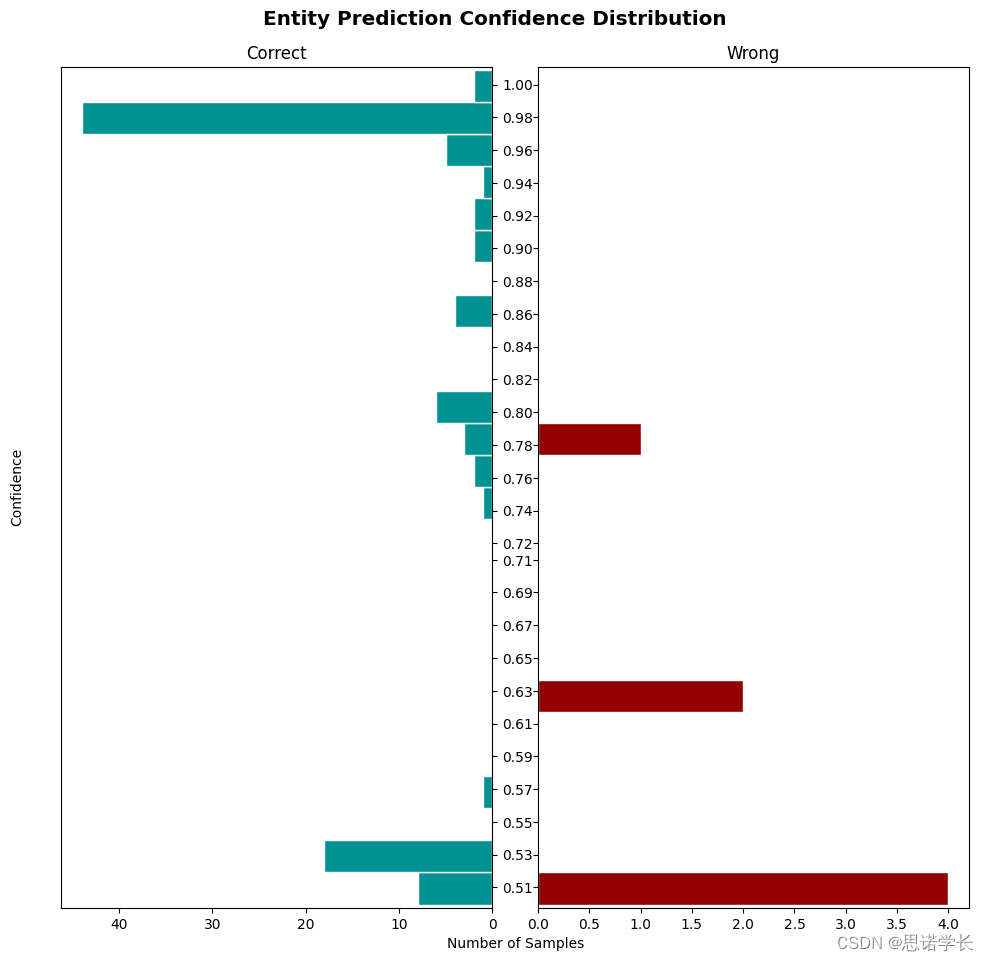
通过比较这两张图,我们可以观察到第二个模型(图2)相对于第一个模型(图1)有以下进步:
a. 减少了高置信错误预测:在第二个图中,高置信度(大于0.8)的错误预测数量减少了,这意味着模型在高置信度下犯错误的可能性降低了。
b. 错误预测的置信度分布更集中:第二个图中错误预测的置信度分布更加集中在0.6到0.7之间,表明模型可能在犯错误时更倾向于给出一个适度的置信度评分,而不是过于自信。
c. 增加了中置信正确预测:第二个图中,置信度在0.6到0.8区间内的正确预测数量有所增加,这可能表明模型对于它不是完全确定的预测变得更谨慎了。
总体上,第二个模型显示出在不牺牲太多高置信度正确预测的情况下,减少了高置信度的错误预测,这表明模型可能在某些方面变得更准确或者至少变得在做出预测时更加谨慎。然而,要得出更全面的结论,还需要更多的上下文信息,例如模型的整体准确率、召回率和F1分数,以及它们在不同置信度阈值下的表现。这些信息将有助于更全面地了解模型性能的改进情况。