文章目录
前言
本文介绍了3种常用的数据仓库(Hive, HBase, Kylin)解决方案的架构以及与ClickHouse的不同之处。这3种数据仓库解决方案都是基于分布式的前提进行的优化,而ClickHouse另辟蹊径,通过提高单机能力实现一定程度上的实时OLAP引擎,这种思路值得我们细细品味。
在正式开始分析前,我们需要明白一个道理:数据文件的组织会影响查询的性能 。按行存储的数据相比于按列存储的数据在分析时相对更慢。
ClickHouse与Hive的对比
Hive本质上是一个元数据管理平台,通过对存储于HDFS上的数据文件附加元数据,赋予HDFS上的文件以数据库表的语义,并对外提供统一的Hive SQL接口,将用户提交的SQL语句翻译为对应的MapReduce程序或Hive程序,交给相应的计算引擎执行。
在对比之前先简单介绍下 Hive, 目前 Hive 基本上已经退出了历史的舞台,关于 Hive 的更多详细资料网上也有很多,读者可以百度下看看
Hive 的数据文件
- Hive的数据文件存在多种类型, 包括 textfile, ORC, Parquet。
- 其中 ORC 与 Hive 结合紧密,基本上就是为 Hive 量身定做的,当数据量庞大,希望获得最强的查询性能,选择ORC。
- Parquet 在设计之初就与平台独立,因此很多开源项目都是使用 Parquet 作为列存格式,比如说现在比较流行的数据湖 Paimon,希望平台独立,具有更好的兼容性,选择Parquet。
Hive的存储系统
- Hive本身不提供存储功能,其数据都存储于HDFS 中。
计算引擎的差异
运行模式不同
- ClickHouse是MPP架构,强调充分发挥单机性能,没有真正的分布式表,ClickHouse的分布式表只是本地表的代理,对分布式表的查询都会被转换为对本地表的查询。这导致ClickHouse在执行部分大表Join操作时可能出现资源不足的情况。
- 由于Hive的数据存储于分布式文件系统,因此Spark在执行计算任务时,需要依据数据分布进行调度。在必要时,Spark可以通过CBO将数据重新排序后再分散到多台机器执行,以实现复杂的查询任务。
- ClickHouse适合简单的DW层之上的即席查询。而Spark由于其分布式特性,导致任务启动时间很长,因此不适合即席查询,但是对于大数据量的Join操作等复杂查询任务,Spark具备非常大的优势。
优化重点不同
- ClickHouse的优化重点在提高单机的处理能力,而Spark的优化重点在于提高分布式的协作效率。
ClickHouse比Hive查询速度快的原因
需要再次强调的是,ClickHouse只是在DW层即席查询场景下比Hive快,并没有在所有场景都比Spark快。
当ClickHouse和Hive都进行即席查询时,ClickHouse比Hive快的原因。
严格数据组织更适合做分析
- ClickHouse的数据组织相对于Hive更严格,需要用户在建表时指定排序键进行预排序。
- 在预排序的情况下,数据在写入物理存储时已经按照一定的规律进行了聚集,在理想条件下可以大幅降低I/O时间,避免数据遍历。
更简单的调度
- ClickHouse的目的是压榨单机性能,并没有实现分布式表,数据都在本地,这也使得ClickHouse不需要复杂的调度,直接在本机执行SQL语句即可。
- 而 Hive 任务需要依据数据分布确定更复杂的物理计划,然后将Spark程序调度到对应的Data Node上,调度的过程非常消耗时间。
ClickHouse与HBase的对比
HBase的存储系统与ClickHouse的异同
都使用LSM算法
- ClickHouse和HBase都使用了LSM算法实现预排序。
- ClickHouse使用LSM算法单纯是为了预排序,且ClickHouse需要将不同分区的数据分散到对应的分区。ClickHouse在实现LSM时,每个写入语句都会创建一个独立的子分区,由后台程序定期合并。
- HBase除了使用LSM算法实现预排序,由于HBase不存在分区的概念,因此HBase会将数据在内存中驻留,尽可能多地在一次磁盘写之前合并更多的随机写入操作,从而提高磁盘I/O的利用率。
HBase使用了HDFS
- HBase底层使用了HDFS,使其具备大数据海量存储能力,而ClickHouse则倾向于单纯存储。
HBase的适用场景及ClickHouse不适合的原因
HBase有着独特的适用场景,而这些场景正好是ClickHouse所不适合的。
海量明细数据的随机实时查询(点查)
- HBase底层使用Key-Value数据模型,具备非常强的点查能力,对于海量明细数据的随机查询有着天生的优势。但是HBase只有在依据Row Key进行精确点查时才能获得最大性能,如果依据列进行查找,性能会差好几个量级。
ClickHouse无法应对点查的原因
- ClickHouse由于底层存储是以块为最小单位进行的,即使只查询一行数据也需要读取整个块,会带来大量的磁盘I/O的浪费,因此ClickHouse并不适合进行点查。
ClickHouse与Kylin的对比
Kylin的架构
下图展示了传统Kylin的架构。Kylin用于解决Hive查询速度慢导致的无法支撑交互式查询的缺陷。Kylin在架构中引入一个存储立方体(Cube)的OLAP引擎作为缓冲层,避免查询直接落到底层的Hive上。当用户进行查询时,Kylin会自动判断用户查询的数据是否存在于充当缓存的OLAP引擎中,并自动将查询路由到缓存或Hive上,解决了Hive查询慢的问题。Kylin的本质是一套缓存系统,需要用户事先依据业务规则定义缓存的内容。
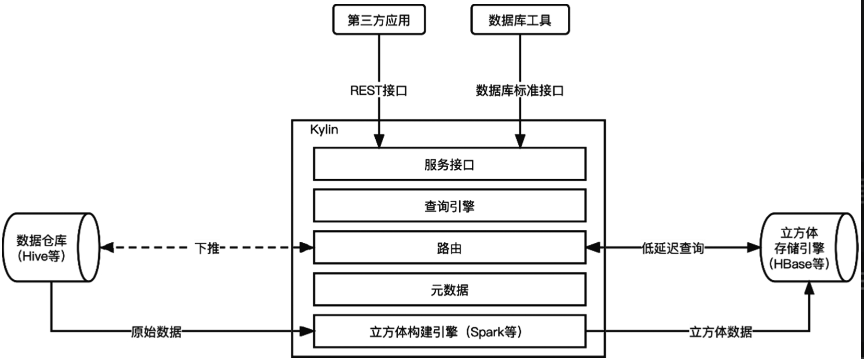
Kylin解决性能问题的思路
Kylin解决问题的核心是允许用户构建模型,在模型的基础上构建Cube,依据Cube将结果计算完成并保存到OLAP数仓引擎中。使用时,通过查询OLAP引擎即可实时获取结果。当所需的结果不在OLAP中时,触发计算下推规则。计算下推是指将计算交给Kylin的底层计算引擎Hive执行。
Cube是多维分析中的一个名词,Cube映射到维度建模中指应用服务层。Kylin使用的表、模型、立方体的概念,分别对应维度建模中的ODS层、DW层、ADS层。
Kylin方案的缺陷
触发计算下推时,查询速度降低
- 当所需的计算指标未命中Cube时,会触发Kylin的计算下推规则。由于计算下推的目的引擎是Hive,而Hive引入Kylin的根本原因就是Hive计算速度慢,因此当触发计算下推规则时,实际上Kylin的优化已经失效,即整个系统退化成原始Hive架构。
需要事前建模,无法响应临时的需求
- Kylin中Cube的构建过程需要通过计算速度慢的Hive实现,这导致无法实时构建Cube,这带来了Kylin的使用限制------无法响应临时的需求。
维度爆炸
- Kylin解决Hive高延迟问题的核心思路是预计算,但预计算无法事先确定哪些维度组合可能会用到,可能需要穷举,由此带来了维度爆炸的问题。
ClickHouse的方案
ClickHouse通过强大的存储引擎和计算引擎,在某些场景下实现了实时响应用户的能力,由于没有使用预计算的方案,因此避开了Kylin的一些问题。在使用ClickHouse代替Kylin时,只需要将Kylin中构建模型的结果导入ClickHouse,即可直接在ClickHouse上进行基于模型的多维分析。不再需要在Kylin中构建Cube,以此获得了非常大的灵活性。
使用ClickHouse替代Kylin可以解决Kylin灵活性的问题,可以适应数据探索等数据需求不确定的场景,但当数据探索完成,形成了固定的数据需求后,需要稳定地对外提供服务时,ClickHouse并发能力弱的缺陷就暴露出来了。
对外稳定提供数据服务的场景下,可能面临非常大的并发请求,ClickHouse在应对这类场景时,也需要将这些数据固化成Cube,并使用内存表存储Cube的数据,通过固化在内存表中的Cube数据对外提供服务,实现更高的并发能力。该方案只能略微缓解ClickHouse并发能力弱的缺陷,并不能完全解决。想要解决这个问题,需要引入缓存等分布式系统中常用的架构,或者继续使用Kylin提供服务。
综上,ClickHouse和Kylin的本质区别在于模型层次的深度不同。Kylin在解决问题时,将维度建模的层次建立到了Cube的程度,可以以极高的性能对外提供服务,但也带来了灵活性差的缺陷。而ClickHouse通过强大的实时多维分析能力,只需要将维度建模建立到模型程度,即可实现实时多维分析,带来了很强的灵活性,但这也意味着极大的计算量,制约了架构的并发能力。这更加印证了架构的核心原则------有得必有失。获得一个能力的同时,一定会付出相应的代价,需要依据业务的实际需求选择架构。
ClickHouse和Kylin对于原始数据层的建模都不太擅长,对于复杂的ODS层建模工作,还是要依赖更底层的计算引擎,例如Spark。