MySQL使用连接查询(JOIN)是为了从多个相关表中获取数据。连接查询是一种强大且常用的操作,可以根据某些条件将两张或多张表中的数据组合在一起,返回一个联合结果集。
1.为什么使用连接查询
-
数据规范化:
- 数据库设计时通常会将数据拆分到不同的表中,以减少数据冗余和提高数据一致性。这种方法称为规范化。
- 例如,将用户信息存储在一个表中,将订单信息存储在另一个表中。这时,如果你需要获取某用户的订单信息,就需要使用连接查询将这两个表的数据组合在一起。
-
提高查询效率:
- 通过使用连接查询,可以减少重复的数据存储,优化数据的管理和查询效率。
- 比如,一个表中存储用户ID,另一个表中存储用户详细信息,查询时只需要连接用户ID和详细信息表即可获取完整信息,而不需要在单个表中存储冗余数据。
-
复杂查询需求:
- 在实际应用中,很多查询需求都涉及多个表的数据。例如,报表生成、数据分析、统计等都需要从多个表中提取相关数据。
- 连接查询可以实现这些复杂的查询需求,通过合并相关表的数据来满足业务逻辑。
2.主要类型的连接查询
INNER JOIN:
- 仅返回两个表中满足连接条件的记录。
sql
SELECT users.username, orders.order_id
FROM users
INNER JOIN orders ON users.user_id = orders.user_id;- 说明:这将返回所有用户和他们的订单,前提是用户和订单在两个表中都有匹配。
LEFT JOIN (或 LEFT OUTER JOIN):
- 返回左表中的所有记录,即使右表中没有匹配的记录。如果右表没有匹配,则结果为NULL。
sql
SELECT users.username, orders.order_id
FROM users
LEFT JOIN orders ON users.user_id = orders.user_id;- 说明:这将返回所有用户以及他们的订单。如果某个用户没有订单,则相应的订单ID将为NULL。
RIGHT JOIN (或 RIGHT OUTER JOIN):
- 返回右表中的所有记录,即使左表中没有匹配的记录。如果左表没有匹配,则结果为NULL。
sql
SELECT users.username, orders.order_id
FROM users
RIGHT JOIN orders ON users.user_id = orders.user_id;
users. Username- 说明:这将返回所有订单以及对应的用户。如果某个订单没有匹配的用户,则相应的用户名将为NULL。
FULL JOIN (或 FULL OUTER JOIN):
- 返回左表和右表中的所有记录,如果没有匹配则返回NULL。MySQL不直接支持FULL JOIN,可以通过UNION实现。
sql
SELECT users.username, orders.order_id
FROM users
LEFT JOIN orders ON users.user_id = orders.user_id
UNION
SELECT users.username, orders.order_id
FROM users
RIGHT JOIN orders ON users.user_id = orders.user_id;
users. Username3.测试连接查询
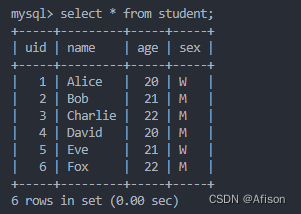
- student 表:
- 存储学生的基本信息。
uid:学生的唯一标识(主键),自动递增。name:学生姓名。age:学生年龄。sex:学生性别,使用枚举类型,值可以是'M'或'W'。
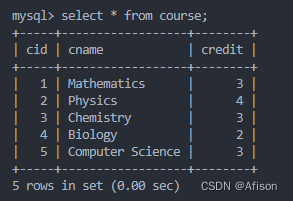
- course 表:
- 存储课程的基本信息。
cid:课程的唯一标识(主键),自动递增。cname:课程名称。credit:课程学分。
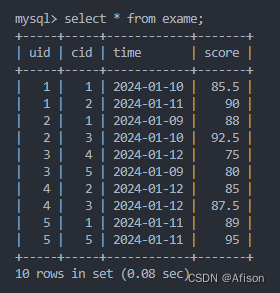
- exame 表:
- 存储考试信息,包括学生、课程和考试成绩。
uid:学生ID,对应student表中的uid。cid:课程ID,对应course表中的cid。time:考试时间。score:考试成绩。PRIMARY KEY(uid,cid):联合主键,确保每个学生在每门课程中只有一个成绩记录。
sql
CREATE TABLE student(
uid INT UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age TINYINT UNSIGNED NOT NULL,
sex ENUM('M','W') NOT NULL);
CREATE TABLE course(
cid INT UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
cname VARCHAR(50) NOT NULL,
credit TINYINT UNSIGNED NOT NULL);
CREATE TABLE exame(
uid INT UNSIGNED NOT NULL,
cid INT UNSIGNED NOT NULL,
time DATE NOT NULL,
score FLOAT NOT NULL,
PRIMARY KEY(uid,cid));插入一些数据
sql
-- 插入数据到 student 表
INSERT INTO student (name, age, sex) VALUES
('Alice', 20, 'W'),
('Bob', 21, 'M'),
('Charlie', 22, 'M'),
('David', 20, 'M'),
('Eve', 21, 'W');
-- 插入数据到 course 表
INSERT INTO course (cname, credit) VALUES
('Mathematics', 3),
('Physics', 4),
('Chemistry', 3),
('Biology', 2),
('Computer Science', 3);
-- 插入数据到 exame 表
INSERT INTO exame (uid, cid, time, score) VALUES
(1, 1, '2024-01-10', 85.5),
(1, 2, '2024-01-11', 90.0),
(2, 1, '2024-01-9', 88.0),
(2, 3, '2024-01-10', 92.5),
(3, 4, '2024-01-12', 75.0),
(3, 5, '2024-01-9', 80.0),
(4, 2, '2024-01-12', 85.0),
(4, 3, '2024-01-12', 87.5),
(5, 1, '2024-01-11', 89.0),
(5, 5, '2024-01-11', 95.0);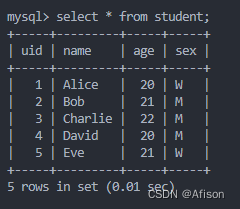
内连接
SELECT a.属性名1,a.属性名2,...,b,属性名1,b.属性名2... FROM table_name1 a inner join table_name2 b on a.id = b.id where a.属性名 满足某些条件;
sql
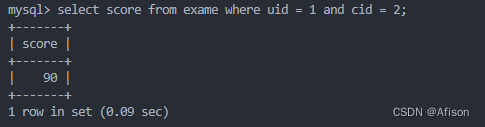
预置条件:uid:1 cid:2
select score from exame where uid=1 and cid=2;
select a.uid,a.name,a.age,a.sex from student a where a.uid=1;
select c.score from exame c where c.uid=1 and c.cid=2;连接两张表查询
// on a.uid=c.uid 区分大表 和 小表,按照数据量来区分,小表永远是整表扫描,然后去大表搜索 // 从student小表中取出所有的a.uid,然后拿着这些uid去exame大表中搜索 // 对于inner join内连接,过滤条件写在where的后面和on连接条件里面,效果是一样的
sql
select a.uid,a.name,a.age,a.sex,c.score from student a
inner join exame c on a.uid=c.uid where c.uid=1 and c.cid=2;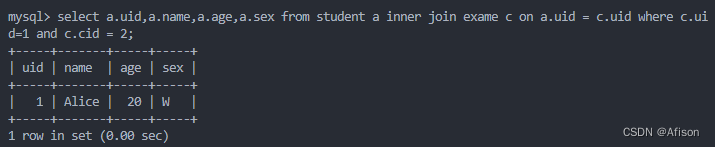
sql
select b.cid,b.cname,b.credit from course b where b.cid=2;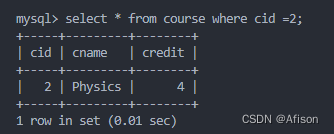
sql
select a.uid,a.name,a.age,a.sex,b.cid,b.cname,b.credit,c.score
from exame c
inner join student a on c.uid=a.uid
inner join course b on c.cid=b.cid
where c.uid=1 and c.cid=2;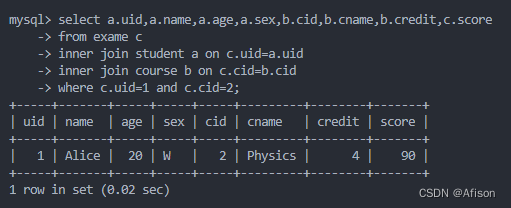
sql
select a.uid,a.name,a.age,a.sex,b.cid,b.cname,b.credit,c.score
from exame c
inner join student a on c.uid=a.uid
inner join course b on c.cid=b.cid
where c.cid=2 and c.score>=90.0;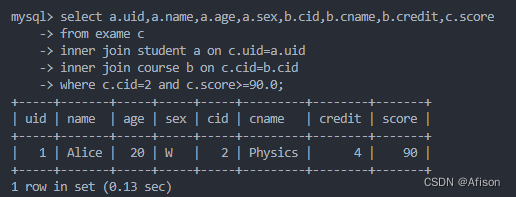
sql
select b.cid,b.cname,b.credit,count(*)
from exame c
inner join course b on c.cid=b.cid
where c.score>=90.0
group by c.cid
having c.cid=2;//分组以后的过滤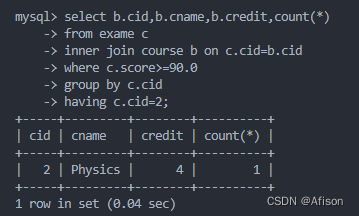
sql
select b.cid,b.cname,b.credit,count(*) cnt
from exame c
inner join course b on c.cid=b.cid
where c.score>=90.0
group by c.cid
order by cnt;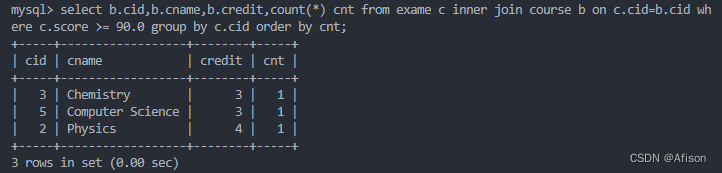
外连接查询
左连接查询
SELECT a.属性名列表, b.属性名列表 FROM table_name1 a LEFT OUTER JOIN table_name2 b on a.id = b.id;
sql
// 把left这边的表所有的数据显示出来,在右表中不存在相应数据,则显示NULL
select a.* from User a left outer join Orderlist b on a.uid=b.uid where
a.orderid is null;例子:
sql
select a.*,b.* from student a left join exame b on a.uid=b.uid;
找出没有考过试的
sql
select a.*,b.* from student a left join exame b on a.uid=b.uid where b.cid is null;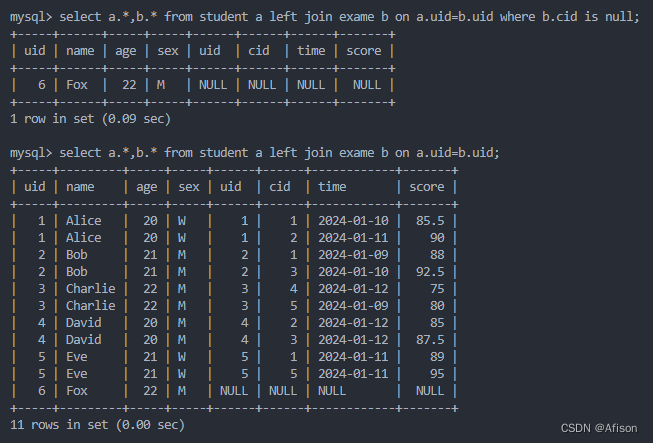
内连接结果如下

左连接结果如下
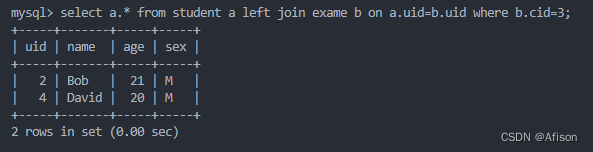
问题,为啥左连接没有把左表全部信息显示,左连接和内连接结果一样
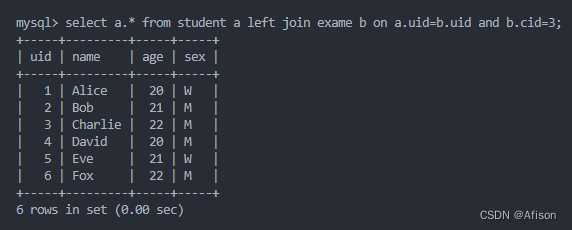
若把where条件放到连接条件on后面
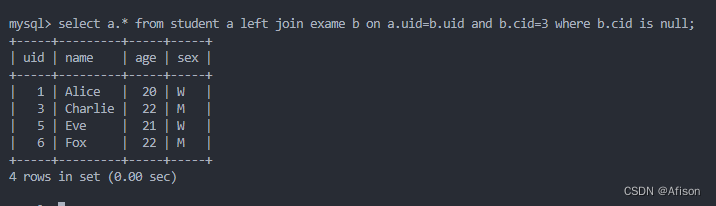
原因分析:
先用b.cid把b表过滤下
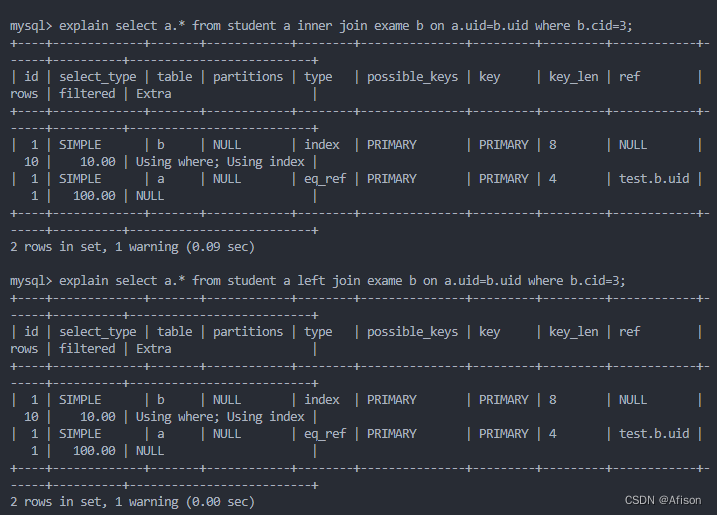
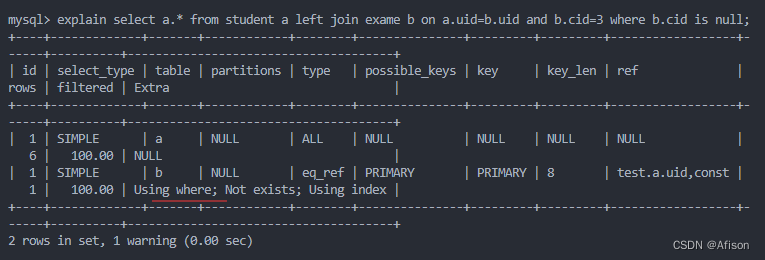
这个内连接和外连接毫无区别,是一样的。所以外连接要把过滤条件写到on中

外连接查不存在的场景,还带有一定的限制条件,限制条件加到on的连接条件后面,where的过滤条件后面写null判空。
右连接查询
SELECT a.属性名列表, b.属性名列表 FROM table_name1 a LEFT OUTER JOIN table_name2 b on a.id = b.id;
sql
// 把right这边的表所有的数据显示出来,在左表中不存在相应数据,则显示NULL
select a.* from User a right outer join Orderlist b on a.uid=b.uid where
b.orderid is null;
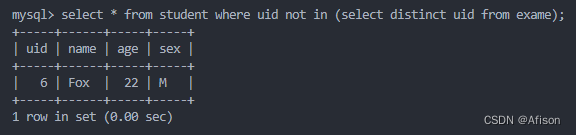
sql
select * from student where uid not in (select distinct uid from exame);select distinct uid from exame-》会产生一张中间表存储结果供外面的sql来查询
not in 对于索引的命中并不高