文章目录
- 前言
- [1 字符串类型的数据结构组成](#1 字符串类型的数据结构组成)
- [2 为什么要这么设计数据结构?](#2 为什么要这么设计数据结构?)
- [3 为什么说字符串类型不可修改?](#3 为什么说字符串类型不可修改?)
- [4 如何实现字符串的修改?](#4 如何实现字符串的修改?)
- [5 为什么字符串修改的字面量用单引号?](#5 为什么字符串修改的字面量用单引号?)
- [6 如何判断字符串的修改新建了一个字符串?](#6 如何判断字符串的修改新建了一个字符串?)
- [7 字符串的修改后新建字符串的场景有哪些?](#7 字符串的修改后新建字符串的场景有哪些?)
- [8 概要总结](#8 概要总结)
- [9 参考链接](#9 参考链接)
前言
本文深入探讨了 Go 语言中字符串的不可变性及其底层实现 。
通过学习,我们将会理解为什么字符串设计为不可变的原因 ,以及如何判断字符串在修改后的底层数据地址是否发生变化,以确定是否创建了新的字符串。
1 字符串类型的数据结构组成
Go 字符串类型的数据结构 包括:一个指向底层字节数组的指针 和一个字符串长度的整数值 。
这个字节数组是不可变的 ,一旦字符串被创建,字符串的内容将无法被修改。
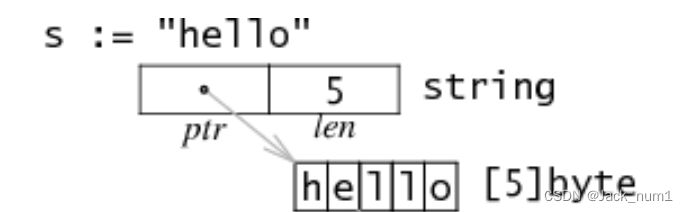
go
type stringStruct struct {
str unsafe.Pointer // 指向底层字节数组的指针
len int // 字符串长度
}2 为什么要这么设计数据结构?
- 保证线程安全:不可变字符串是线程安全的,只允许读操作,在并发场景下无需担心数据竞争问题。
- 实现内存共享:相同的字符串只需存储一次,实现多次重复使用,节省内存。
- 优化性能:作为哈希表的键时,不需要每次重新计算哈希值,提高性能。
3 为什么说字符串类型不可修改?
字符串底层是只读 的字节序列 ,任何对字符串的修改实际上都会创建一个新的字符串,而不会改变原始字符串
go
# 错误示范:导致编译报错!!
str := "hello"
str = "Hello"//字符串是不可修改的,是不允许直接在原字符串上操作的
fmt.Prtintln(str) 4 如何实现字符串的修改?
由于字符串是不可修改 的,实际的字符串修改操作是创建了一个新的字符串。
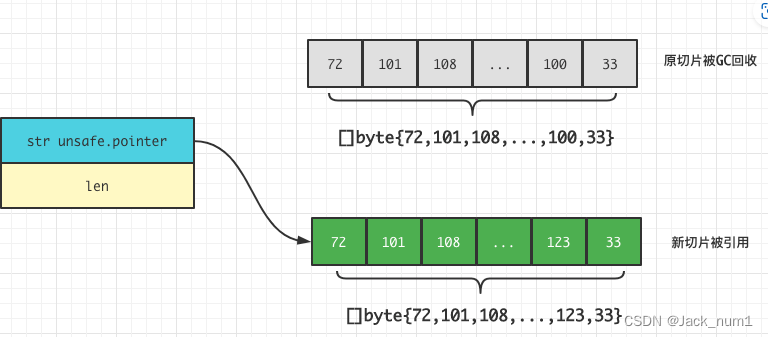
常见的做法 :先将字符串 转换为 \[\]byte 或者 \[\]rune ,进行修改操作后,再转换为字符串。
go
// 初始字符串:使用双引号表示字符串
str := "hello"
fmt.Println("旧字符串:%v",str)
// 将字符串转换为[]byte切片
strBytes := []byte(str)
// 修改 []byte 中的一个字符,使用单引号表示字符
strBytes[0] = 'H'
str = string(strBytes) // 创建了一个新的字符串
fmt.Println("新字符串:%v",str)5 为什么字符串修改的字面量用单引号?
!question+
strBytes[0] = 'H'使用了单引号,为什么需要使用单引号?
- 单引号字面量,代表单个字符 ,常用于\[\]byte和\[\]rune中的字符元素修改。
- 双引号和反引号的字面量,代表字符串
6 如何判断字符串的修改新建了一个字符串?
!warning+ 判断依据: 字符串修改操作会创建一个新的字符串,并将底层的指针地址指向新字符串。如果要判断 Go 字符串修改是否创建了新字符串,需要判断字符串内容的地址前后是否一致。
我们知道,获取一个变量的地址有两种方式 :①使用
unsafe包 ②使用fmt.Printf("%p", &s)。这两种方式对于获取字符串变量地址有所差异 ,第一种方式获取的是底层字节数组的地址 ,第二种方式获取的是字符串变量本身的地址。以下是代码示例:
go
// 获取字符串的指针地址
func getStringPointer(s string) uintptr {
return uintptr(unsafe.Pointer(&s))
}
func main() {
// 初始字符串
s := "hello"
// 获取初始字符串的指针地址
initialPointer := getStringPointer(s)
// 打印指针地址
fmt.Printf("Initial pointer: %x\n", initialPointer)
// 将字符串转换为 []byte
b := []byte(s)
// 修改 []byte
b[0] = 'H'
// 将 []byte 转回字符串,并给修改字符串s
s = string(b)
// 获取新字符串的指针地址
newPointer := getStringPointer(s)
fmt.Printf("New pointer: %x\n", newPointer)
// 判断是否创建了新字符串
if initialPointer != newPointer {
fmt.Println("新字符串已创建")
} else {
fmt.Println("没有创建新字符串")
}
}7 字符串的修改后新建字符串的场景有哪些?
每次对字符串的修改操作(字符串拼接、字符串替换、切片操作),都会创建一个新的字符串。
8 概要总结
!example+ 概要总结
- 我们从GO字符串的底层数据结构了解到,字符串是不可修改的,原因是字符串底层是只读的字节序列 ,若直接在原字符串修改,则编译器将引发错误。
- 想要修改字符串就必须转换为\[\]byte或者\[\]rune,修改之后转换为原有字符串类型。
- \[\]byte或者\[\]rune的修改的字面量必须使用单引号,双引号是代表的字符串。
- 通过代码分析可知,字符串修改操作会创建一个新的字符串,并将底层的指针地址指向新字符串。
9 参考链接
- 图片引用1:Go 数据结构
- 图片引用2:为什么说Go的字符串类型不能修改