一、索引
由于我们在使用数据库的时候,大部分操作的都是查询操作 ,但是我们每一次进行查询都需要遍历一遍表 中所有数据,这会花费O(n)的时间,因此数据引入了"索引" 也就是在底层使用了数据结构来进行优化查询 的操作,但是可能会造成插入/删除操作变慢 和消耗空间。
语法:
sql
show index from 表名;
#查看表中哪一列有索引
create index 索引名字 on 表名(列名);
#对某一列创建索引
drop index 索引名 on 表名;
#删除索引注意:
一个索引是针对列来指定的。只有针对这一列进行查询时,查询速度才能被索引优化~如果进行全列查询的话,那还是需要遍历表的。
如果某一列被primary key、foreign key、unique所约束的话,会自动创建索引。
创建索引 也是一个相当危险的操作,因为创建索引是需要对现有的数据进行大规模的整理,如果数据非常多,很容易就把服务器卡住,一般来说创建索引的时候都是在创建完表后立马操作,一旦使用久了的话, 需要慎重操作。不过也可以采用分治的思想,一点一点将数据写入到创建好的表中~
以上内容都是基础的知识,但是面试常考查的是索引的底层~~
(由于本人水平有限,在此先简单介绍简单的内容知识~)
索引的底层使用的是一种类似二叉搜索树 (在极端情况下,二叉搜索树的时间复杂度为O(n),AVL树,红黑树能达到O(logn) )的树 ,也就是一棵改进的树形结构:B+树 。可能会好奇,为啥不用哈希表呢?时间复杂度可以O(1),这是因为在查询的过程中我们往往会进行范围查询,而哈希表只能进行精确的查询,因此我们不使用哈希表。

B+树顾名思义是在B树的基础上改进的。那啥是B树呢?
B树:是一棵N叉搜索树,每个节点的度不确定,一个节点上保存N个数据的值,划分出N + 1个区间,每个区间衍生出一棵子树。
逻辑上存储结果如下:
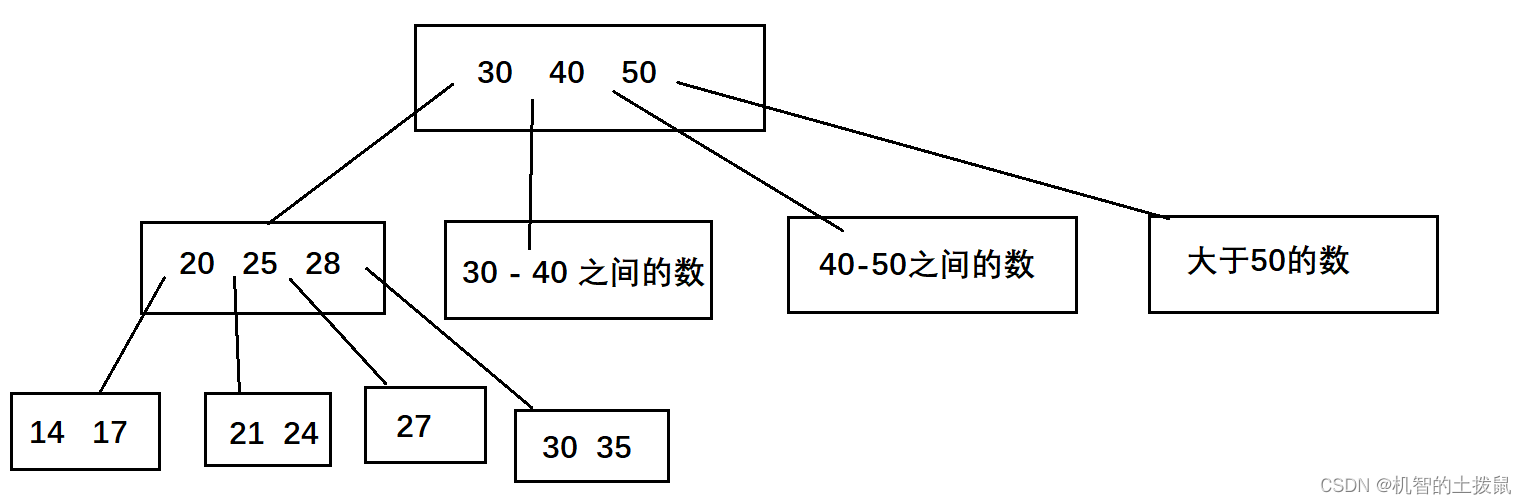
而B+树则是对B树的改进,感觉像是针对数据库进行量身定做。
如果使用B树会有遇到什么问题呢?假如我们现在要使用范围查询去查询10-40之间的数。我们在如下图中进行观察:
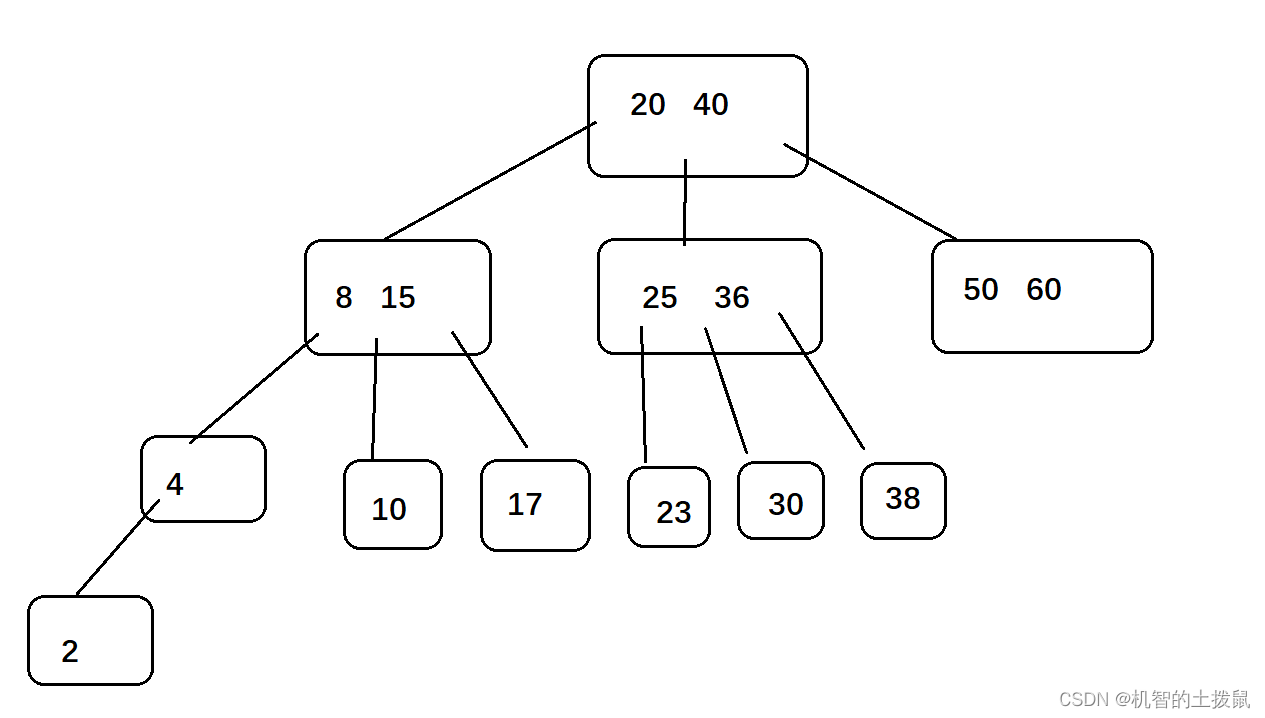
搜索过程大致如下:
我们先要进行小于20区间的搜索,然后再进行20-40区间的搜索,里面包含大量"向下递"(需要开辟内存空间),"回溯"的操作 ,如果一棵区间子树的高度较高,我们需要花费较多时间进行这个子树的搜索,恰巧另一些范围内的数据在另一棵子树上,那么我们又要花费较多时间进行搜索。总的来说,由于范围查询,我们有时要搜索多棵子树,这会导致效率的下降。
基于这些缺点,B+树进行了优化。首先,B+数在每个非叶子节点上存储的是索引 (B树上就是实际的值),所有数据都是存储在叶子节点上 ,B+树再使用了一个链表 ,将所有叶子节点连了起来,这就导致了范围查询更加高效,因为只要找到了一个符合要求的叶子节点,我们就直接对链表进行遍历,省去了再搜索其他子树的操作。
B+树的优点(相比B树、哈希、红黑树):
1、是一棵N叉搜索树,因此树的高度比较小。
2、磁盘IO次数更少,效率更高。
红黑树是一棵平衡二叉搜索树,为了平衡需要进行旋转操作,而旋转操作时针对于整棵树 的,但是因为数据库中可能存储着大量的数据,我们往往不能将所有的数据读取到内存中,因此需要部分多次读取 ,这就导致了旋转可能会有问题且效率不高,而且也无法利用磁盘预读(存储器某一个位置被访问了,那么其附近位置也会被访问)。
在B树中,每一个节点是在一个硬盘区域中 ,可以利用磁盘预读,一次读硬盘就能取出整个节点( 多个键值对)。而读取硬盘的时间远大于内存比较的时间,近似于 读一次硬盘 = 内存1w次比较。
在B+树中,非叶子节点上是存的索引信息 ,而对应数据库中一行数据可能内容比较多,但是单单某一行的某一列(索引)所占空间往往只有几个字节 ,因此我们能够将所有的索引信息读取到内存中进行比较,然后找到叶子节点上的值,再通过链表遍历的方式进行搜索,从而大大减少了IO次数。
3、所有的查询最终要落实到叶子节点,因此整体的查询效率比较稳定,而B树中可能在前面的节点就能找到,复杂度为O(1), 不稳定。
4、非常擅长范围查询
二、事务
事务:一组数据库的操作语句,这些操作将会被视为一个整体,保证要么这些语句全部执行,要么"一个都不执行"。
0x 00 案例引入

现在,SQL语句执行完了第一条但是还没执行第二条的时候,突然电脑关机/程序崩溃了.......
张三一看已经扣了钱,但是李四却没有收到,这就很尴尬了。此时我们需要引入"事务",来帮助我们解决这个问题,也就是要么张三扣了钱,李四收到了钱,要么就无事发生~ 我们将这种"要么全部执行,要么相当于没有执行"这个特殊的性质称为"原子性"
0x 01 事务的特性ACID
1、原子性(Atomicity) :事务出现的原因。将一系列sql语句看成一个整体,要么全部执行,要么通过回滚的方式,恢复如初。
2、 一致性(Consistency) :事务执行之前和之后,数据都不能出现非法的情况。
3、 持久性(Durability) :事务做出的修改,都是在硬盘上持久保存的,即使在系统故障或者崩溃的情况下,事务执行的修改都是有效的。
4、隔离性(Isolation) :**由于mysql是客户端-服务器的模式,会存在并发的情况,即多个用户在同一时间请求服务器。**事务的执行是相互隔离的,一个事务的操作不应该影响其他事务的操作。
补充:
并发操作往往能提高效率,但是会降低准确性。mysql数据库在并发执行的时候,会遇到如下问题:
1、脏读:
事务A在**改变(修改,增加,删除)**数据
事务B在事务A未提交的时候就来读取数据
后来事物A可能在事物B读完了数据后又修改了或者回滚了,此时事务B读到数据就是"脏"的,即无效的。
脏读也就是在写的过程中进行读操作。 解决脏读问题,思路是对写操作进行加锁,告诉事务B在我写的时候,不要来读取数据。此时并发性降低了,隔离性提高了,效率降低了,准确性提高了~
2、不可重复读:
事务B在读取数据
事务A修改或删除了数据然后提交事务
事务B第二次读数据的时候,发现两次读到的数据不相同,也就是事务A在事物B两次读取的时候进行了修改。
不可重复读也就是在读的过程中进行了写操作 。解决不可重复读问题,思路是对读操作进行加锁,告诉事务A在我读的时候,不要来修改数据。
3、幻读:
事务B在读数据
事务A此时插入了数据然后提交了事务
事务B第二次读数据,然后读到了与第一不一样的结果集。
幻读与不可重复读类似,区别在于幻读是强调插入操作,不可重读是修改操作。 解决幻读的问题,思路是引入串行化的方式,保证绝对的串行执行事务,此时完全没有并发了。
针对以上的问题,mysql提供了4种隔离级别,可以在mysql配置文件中修改~
| 隔离级别 | 解决问题 |
|---|---|
| read uncommitted(读未提交) | 隔离性最低,但效率最高 |
| read committed(读已提交) | 给写加锁,解决脏读 |
| repeatable read(可重复读) | 给读、写加锁,解决脏读、不可重复读、幻读问题 |
| serializable(串行化) | 严格按照串行的方式,一个一个执行事务,解决脏读、不可重复读、幻读 |
0x 02 操作语句
sql
start transaction; #开启事务
进行一些列sql语句......
rollback; #回滚事务,恢复到未执行事务前
commit; #提交事务
#事务的使用很简单,但需要关注事务背后的一些原理性质的内容三、JDBC
0x 00 什么是JDBC
JDBC代表Java连接数据库,也就是通过Java代码操作数据库。
在初期,市面上有着许多的数据库,如:MySQL, Oracle, SQL Sever.......但是不同的数据库 大概率是由不同的程序员所开发 出来的,因此在使用方面存在差异(如:方法名,类名,功能不同) ,这就大大的增加了程序员的难度,苦不堪言~这时候就需要一个真正有分量的大佬来一统江湖!!!于是Java就自己设计出一套API的规范 ,让各种各样的数据库都要遵守 ,因此java程序员只需要会一套自己的API就好了,大大减少了学习成本~

各厂商实现了接口 后将其打包好并发布,如果Java程序员想要操作MySQL的话,只需要导入MySQL实现的jar包,然后在程序中调佣Java自己制定的API即可。其他如果数据库也同理,不过需要导入不同厂家的jar包。
0x 01导入jar包
在使用Java操作数据库前需要先将下载好的jar包(可以去中央仓库下载)导入程序。
Maven Repository: mysql >> mysql-connector-java (mvnrepository.com)
然后就可以在程序中使用了。
0x 02 使用JDBC
1、创建DataSource
java
public class Main {
public static void main(String[] args) {
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
}
}在这里我们可以看到,我们创建了一个dataSource ,但是使用的时候却进行了向下转型 ,那为什么不直接创建一个MysqlDataSource的呢? 这是因为要降低代码的耦合度,让MysqlDataSource这个类名不要扩散到代码的其他地方,如果后续要操作别的数据库了,代码的改动比较小。
那Url是什么 呢?url表示网络上的资源位置通俗讲就是网址,因为服务器是cs模式,需要通过网络交互。
127.0.0.1 表示IP地址 ,描述网络上一个主机所在的位置,不过这个IP地址是一个**"环回IP"** ,即自己把数据发给自己。这是因为jdbc程序和mysql服务器都在我们自己的电脑上~
3306 表示端口号,用来区分不同进程的。
test 表示数据库名称。
?& /...... 这些符号是一些特殊符号。这里从?后面,表示访问资源的时候,需要哪些参数
useSSL=false 表示是否要加密
这里dataSource光写url的话 只能找到mysql服务器,但还得登录认证,因此还需要设置账号,密码。
2、和数据库服务器建立连接
java
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
}
}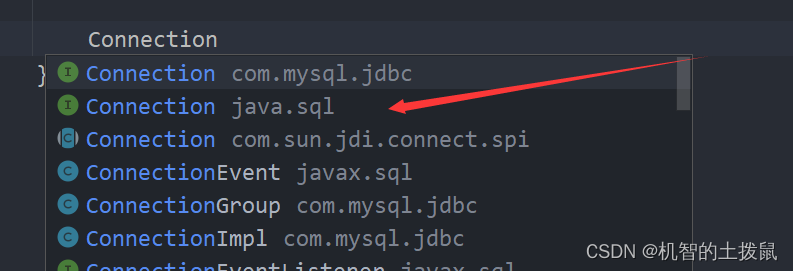
在创建的时候千万不要选错!!!
3、构造sql语句并执行
java
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
String sql = "insert into student values(1, '张三')";
PreparedStatement statement = connection.prepareStatement(sql);
int n = statement.executeUpdate(); //看看修改了几条
}
}这里通过使用preparedStatement进行对sql语句的检查 ,在将sql发给服务器之前先看看有没有语法错误 啥的,这样就能减小mysql服务器的开销。
如果要执查询操作 的话,要使用executeQuery()方法 ,如果是改操作 的话,使用executeUpdate()方法。
4、执行完后关闭连接,释放资源
程序通过代码和服务器进行通信 ,是需要消耗一定的资源 的。因此在程序结束后需要告知服务器,释放这些资源。
java
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
String sql = "insert into student values(1, '张三')";
PreparedStatement statement = connection.prepareStatement(sql);
int n = statement.executeUpdate();
statement.close();
connection.close();
}
}后申请的先释放!!!
0x 03自定义sql语句
刚刚我们是为了演示总得流程,所以sql语句就在程序中写死了,如果我们要插入我们想要的数据该怎么办呢?
方案一:
创建变量让用户输入赋值修改就行。
java
String sql = "insert into sutdent values (" + id + ", '" + name + "')";这样写,既不优雅,也不安全。这么多符号很容易出错,然后如果用户是高手,懂sql注入的话,那就危险了。name一栏不好好写,写成 删库 那就惨了。
方案二:
创建变量并使用占位符。
java
String sql = "insert into student values(?, ?)";
statement.setInt(1, id); //当心第一个是从1位置开始计算的,而不是0
statement.setString(2, name);这样就好多了~
0x 04 输出查询结果
查询在数据库操作中是大头,怎么将查询结果输出呢?
java
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
String sql = "select * from student";
PreparedStatement statement = connection.prepareStatement(sql);
ResultSet resultSet = statement.executeQuery();
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println(id + "," + name);
}
resultSet.close();
statement.close();
connection.close();
}我们的查询结果返回的是一张临时表 ,此时需要使用ResultSet类来接收结果集 。然后要进行遍历ResultSet才能取出全部数据。
遍历ResultSet是通过调用next方法 获取临时表中的每一行数据。这个next方法相当于在临时表中有一个"光标",一开始的时候指向的是第一行的前一个位置,而每一次执行,就相当于将光标移到下一行。如果走到最后一行,将会放回false。
resultSet中提供了getXXX方法 ,里面的参数是列名,这样就可以拿到一行中的某一列数据了。
最后记得要释放result资源~