PGvector :在 Spring AI 中实现向量数据库存储与相似性搜索
一、PGvector 概述与核心价值
1.1 什么是 PGvector
PGvector 是 PostgreSQL 的开源扩展,专为向量相似性搜索而设计。它允许开发者在 PostgreSQL 数据库中存储和搜索机器学习生成的嵌入(embeddings),支持精确和近似最近邻搜索。
💡 为什么选择 PGvector?
- 无缝集成:作为 PostgreSQL 扩展,与现有数据库生态系统无缝协作
- ACID 合规:保持 PostgreSQL 的事务完整性
- 功能丰富:支持多种距离度量和索引类型
- 高性能:针对大规模向量搜索进行优化
- 易用性:提供标准 SQL 接口,无需学习新查询语言
1.2 PGvector 的关键特性
| 特性 | 描述 | 优势 |
|---|---|---|
| 向量存储 | 支持多种向量类型(vector, halfvec, bit, sparsevec) |
适应不同精度和内存需求 |
| 距离度量 | L2、内积、余弦距离、L1、汉明距离、杰卡德距离 | 适用于不同场景的相似性度量 |
| 索引类型 | HNSW、IVFFlat | 平衡查询速度和召回率 |
| 元数据过滤 | 基于 JSON 的元数据过滤 | 精确控制检索结果 |
| 混合搜索 | 结合向量搜索和文本搜索 | 提高检索相关性 |
1.3 PGvector 与 Spring AI 的集成
Spring AI 通过 spring-ai-starter-vector-store-pgvector 提供了 PGvector 的开箱即用支持,使开发者能够轻松地将向量数据库集成到 RAG(检索增强生成)应用中。
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>二、PGvector 安装与配置
2.1 环境准备
2.1.1 前提条件
在使用 PGvector 之前,需要确保 PostgreSQL 实例已启用以下扩展:
sql
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";如果没有参考 ✅ 宝塔 PostgreSQL 安装 contrib 扩展完整指南
2.2 手动创建向量存储表
在数据库中创建向量存储表(推荐在应用启动时由 Spring AI 自动创建):
sql
CREATE TABLE IF NOT EXISTS vector_store (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
content text,
metadata json,
embedding vector(1536) -- 1536 是默认的嵌入维度
);
CREATE INDEX IF NOT EXISTS vector_index
ON vector_store USING hnsw (embedding vector_cosine_ops);💡 重要提示 :如果使用不同的嵌入维度,请将
1536替换为实际的嵌入维度。PGvector 对 HNSW 索引最多支持 2000 个维度。
三、Spring AI 集成 PGvector
3.1 依赖配置
在 Maven 项目中添加 PGvector 向量存储依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>3.2 自动配置
Spring AI 提供了自动配置功能,通过 application.yml 配置 PGvector:
yaml
spring:
datasource:
url: jdbc:postgresql://localhost:5432/postgres
username: postgres
password: postgres
ai:
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE
dimensions: 1536
max-document-batch-size: 10000 💡 关键配置说明:
initialize-schema: true:在应用启动时自动创建所需的数据库表dimensions:嵌入维度(如果未指定,将从 EmbeddingModel 获取)index-type:索引类型(HNSW、IVFFlat、NONE)distance-type:距离类型(COSINE_DISTANCE、EUCLIDEAN_DISTANCE、NEGATIVE_INNER_PRODUCT)
3.3 手动配置(高级用法)
不使用 Spring Boot 自动配置时,可以手动创建 PgVectorStore:
java
@Configuration
public class PgVectorConfig {
@Bean
public VectorStore vectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel) {
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.dimensions(1536) // 默认为模型维度
.distanceType(COSINE_DISTANCE)
.indexType(HNSW)
.initializeSchema(true) // 启用自动表创建
.schemaName("public")
.vectorTableName("vector_store") // 哪一个数据库
.maxDocumentBatchSize(10000)
.build();
}
}3.4 依赖项要求
手动配置时,需要添加以下依赖:
xml
<!-- Spring Boot JDBC 支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- PostgreSQL JDBC 驱动 -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Spring AI PGvector Store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>四、向量存储操作实践
4.1 存储文档
java
@Resource
@Qualifier("pgVectorStore")
private VectorStore vectorStore;
/**
* 文档嵌入与存储
*/
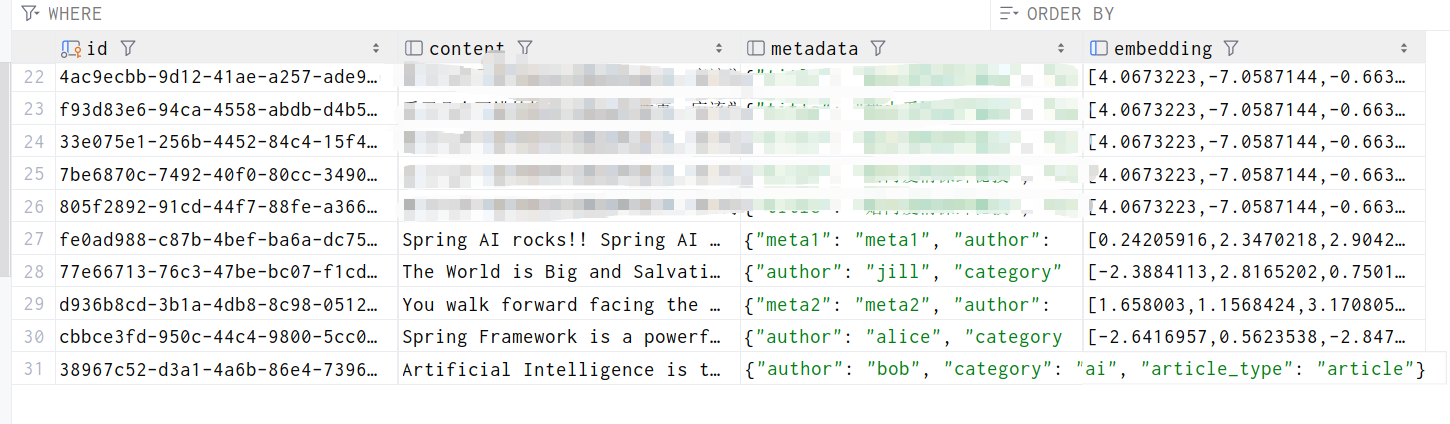
public void storeDocuments() {
// 4.1.1 创建文档对象
List<Document> documents = List.of(
new Document(
"Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!",
Map.of("author", "john", "article_type", "blog", "meta1", "meta1")
),
new Document(
"The World is Big and Salvation Lurks Around the Corner",
Map.of("author", "jill", "article_type", "news", "category", "philosophy")
),
new Document(
"You walk forward facing the past and you turn back toward the future.",
Map.of("author", "john", "article_type", "blog", "meta2", "meta2", "category", "philosophy")
),
new Document(
"Spring Framework is a powerful Java framework for building enterprise applications.",
Map.of("author", "alice", "article_type", "tutorial", "category", "programming")
),
new Document(
"Artificial Intelligence is transforming the tech industry.",
Map.of("author", "bob", "article_type", "article", "category", "ai")
)
);
// 4.1.2 存储文档到向量存储
System.out.println("开始存储文档到向量存储...");
vectorStore.add(documents);
System.out.println("文档存储完成!");
// 验证存储
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("Spring")
.topK(5)
.build()
);
System.out.println("\n存储验证 - 检索结果:");
results.forEach(doc -> {
System.out.println("内容: " + Objects.requireNonNull(doc.getText()).substring(0, Math.min(50, doc.getText().length())) + "...");
System.out.println("元数据: " + doc.getMetadata());
System.out.println("---");
});
}
4.2 基本相似性搜索
java
/**
* 基本相似性搜索
*/
public List<Document> basicSimilaritySearch() {
System.out.println("\n执行基本相似性搜索...");
SearchRequest searchRequest = SearchRequest.builder()
.query("Spring")
.topK(3)
.similarityThreshold(0.5) // 相似度阈值(0-1之间)
.build();
List<Document> results = vectorStore.similaritySearch(searchRequest);
System.out.println("基本搜索 - 查询 'Spring' 的结果:");
results.forEach(doc -> {
System.out.println("内容: " + doc.getText());
System.out.println("元数据: " + doc.getMetadata());
System.out.println("相似度: " + doc.getMetadata().get("distance"));
System.out.println("---");
});
return results;
}
4.3 使用元数据过滤 - 文本表达式
java
/**
* 使用元数据过滤 - 文本表达式
*/
public List<Document> searchWithMetadataFilter() {
System.out.println("\n使用元数据过滤搜索...");
SearchRequest searchRequest = SearchRequest.builder()
.query("technology")
.topK(5)
.similarityThreshold(0.3)
// 注意:具体过滤表达式语法取决于向量存储实现
// 这里使用 Spring AI 的标准过滤语法
.filterExpression("author in ['john', 'jill'] && article_type == 'blog'")
.build();
// 方法1: 使用文本表达式语言进行过滤
List<Document> results = vectorStore.similaritySearch(searchRequest);
System.out.println("元数据过滤搜索 - 文本表达式结果:");
results.forEach(doc -> {
System.out.println("内容: " + doc.getText());
System.out.println("元数据: " + doc.getMetadata());
System.out.println("---");
});
return results;
}
4.4 使用元数据过滤 - Filter.Expression DSL
java
public List<Document> searchWithProgrammaticFilter() {
System.out.println("\n使用编程式元数据过滤搜索...");
// 方法2: 使用 Filter.Expression DSL 进行编程式过滤
FilterExpressionBuilder b = new FilterExpressionBuilder();
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("technology")
.topK(5)
.similarityThreshold(0.3)
.filterExpression(b.and(
b.in("author", "john", "jill"),
b.eq("article_type", "blog")
).build())
.build()
);
System.out.println("编程式过滤搜索结果:");
results.forEach(doc -> {
System.out.println("内容: " + doc.getText());
System.out.println("元数据: " + doc.getMetadata());
System.out.println("---");
});
return results;
}
4.5 高级搜索示例:组合查询和过滤
java
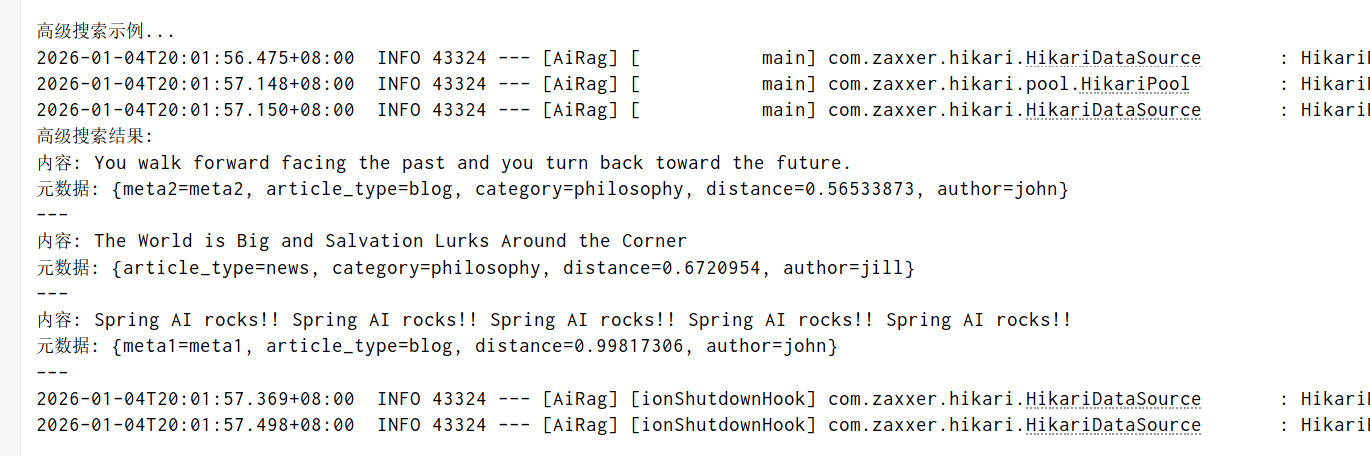
public List<Document> advancedSearchExample() {
System.out.println("\n高级搜索示例...");
// 创建复杂过滤条件
FilterExpressionBuilder builder = new FilterExpressionBuilder();
// (author == 'john' || author == 'jill') && category == 'philosophy'
Filter.Expression filter = builder.and(
builder.or(
builder.eq("author", "john"),
builder.eq("author", "jill")
),
builder.eq("category", "philosophy")
).build();
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("life and future")
.topK(10)
.similarityThreshold(0.0)
.filterExpression(filter)
.build()
);
System.out.println("高级搜索结果:");
results.forEach(doc -> {
System.out.println("内容: " + doc.getText());
System.out.println("元数据: " + doc.getMetadata());
System.out.println("---");
});
return results;
}
4.6 删除特定文档(根据元数据)
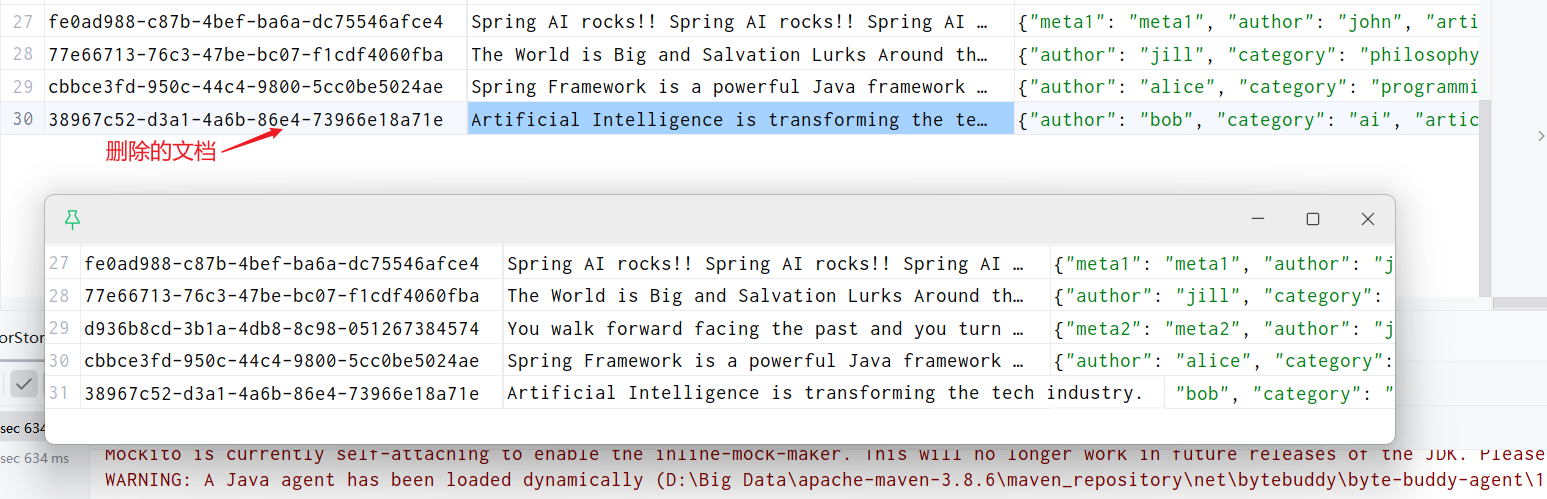
java
public void deleteDocumentsByMetadata() {
System.out.println("\n删除 author 为 'john' 的文档...");
// 注意:删除功能可能因向量存储实现而异
// PGvector 通常支持根据元数据过滤删除
// 先搜索要删除的文档
FilterExpressionBuilder builder = new FilterExpressionBuilder();
Filter.Expression filter = builder.eq("author", "john").build();
List<Document> docsToDelete = vectorStore.similaritySearch(
SearchRequest.builder()
.query("")
.topK(100)
.filterExpression(filter)
.build()
);
if (!docsToDelete.isEmpty()) {
// 提取文档ID(PGvector中id在metadata中)
List<String> ids = docsToDelete.stream()
.map(Document::getId)
.filter(Objects::nonNull)
.toList();
System.out.println("找到 " + ids.size() + " 个要删除的文档");
// 删除文档(具体方法取决于VectorStore实现)
vectorStore.delete(ids);
}
}五、PGvector 配置参数详解
5.1 关键配置属性
| 属性 | 描述 | 默认值 | 适用场景 |
|---|---|---|---|
index-type |
最近邻搜索索引类型 | HNSW | 需要高性能检索时 |
distance-type |
搜索距离类型 | COSINE_DISTANCE | 向量已归一化时 |
dimensions |
嵌入维度 | 从 EmbeddingModel 获取 | 与嵌入模型一致 |
remove-existing-vector-store-table |
启动时删除现有表 | false | 重置数据库时 |
initialize-schema |
是否初始化 schema | false | 首次使用时 |
schema-name |
向量存储 schema 名称 | public | 多 schema 环境 |
table-name |
向量存储表名称 | vector_store | 自定义表名 |
schema-validation |
启用 schema 和表名验证 | false | 安全敏感环境 |
max-document-batch-size |
单批处理的最大文档数 | 10000 | 大批量数据导入 |
5.2 索引类型对比
| 索引类型 | 构建时间 | 查询性能 | 内存使用 | 适用场景 |
|---|---|---|---|---|
| HNSW | 较慢 | 优秀 | 较高 | 高性能要求,数据量大 |
| IVFFlat | 快 | 一般 | 较低 | 数据量小,内存有限 |
| NONE | 无 | 一般 | 低 | 测试环境,小数据量 |
💡 HNSW 与 IVFFlat 选择建议:
- 对于 100K+ 向量,选择 HNSW
- 对于 10K-100K 向量,选择 IVFFlat
- 对于 <10K 向量,使用 NONE
5.3 距离类型选择
| 距离类型 | 适用场景 | 性能 | 说明 |
|---|---|---|---|
| COSINE_DISTANCE | 向量已归一化 | 优秀 | 适用于大多数嵌入模型 |
| EUCLIDEAN_DISTANCE | 向量未归一化 | 一般 | 需要精确距离 |
| NEGATIVE_INNER_PRODUCT | 向量已归一化 | 优秀 | 与 COSINE_DISTANCE 等效 |
💡 重要提示:如果向量已经归一化到长度 1(如 OpenAI 嵌入),使用 COSINE_DISTANCE 或 NEGATIVE_INNER_PRODUCT 能获得最佳性能。
六、高级用法与最佳实践
6.1 性能优化技巧
6.1.1 索引优化
java
// HNSW 索引优化参数
CREATE INDEX ON vector_store USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);- m:每层的最大连接数(默认 16)
- ef_construction:构建图时的动态候选列表大小(默认 64)
💡 优化建议 :对于高召回率要求,提高
ef_construction;对于快速构建,降低它。
6.1.2 查询优化
java
// 设置查询时的动态候选列表大小
SET hnsw.ef_search = 100;- ef_search:查询时的动态候选列表大小(默认 40)
- 值越大,召回率越高,但速度越慢
💡 优化建议 :对于关键查询,设置
ef_search=100;对于普通查询,保持默认。
6.1.3 批量处理优化
java
// 批量添加文档(使用最大批次大小)
vectorStore.add(documents, 10000); // 10000 是 maxDocumentBatchSize💡 优化建议 :使用
maxDocumentBatchSize配置值作为批量大小,避免内存溢出。
6.2 安全最佳实践
6.2.1 数据库权限管理
sql
-- 为应用用户创建最小权限
CREATE ROLE app_user;
GRANT CONNECT ON DATABASE postgres TO app_user;
GRANT USAGE ON SCHEMA public TO app_user;
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLE vector_store TO app_user;6.2.2 元数据过滤安全
java
// 在应用层验证过滤表达式
if (isValidFilterExpression(filterExpression)) {
// 执行查询
}💡 安全建议:不要直接使用用户输入的过滤表达式,进行验证和清理。
6.2.3 启用 schema 验证
yaml
spring:
ai:
vectorstore:
pgvector:
schema-validation: true💡 安全建议 :在生产环境中始终启用
schema-validation,防止 SQL 注入。
6.3 与 RAG 流程集成
6.3.1 使用 QuestionAnswerAdvisor
java
@Bean
public Advisor questionAnswerAdvisor(VectorStore vectorStore) {
return QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.7)
.topK(5)
.build())
.build();
}6.3.2 使用 RetrievalAugmentationAdvisor
java
@Bean
public Advisor retrievalAugmentationAdvisor(VectorStore vectorStore) {
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.7)
.topK(5)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build())
.build();
}6.3.3 RAG 流程工作流程
- 用户输入:用户提出问题
- 查询处理:使用 QueryTransformer 优化查询
- 文档检索:使用 VectorStoreDocumentRetriever 检索相关文档
- 上下文增强:使用 ContextualQueryAugmenter 增强查询
- 生成响应:使用 ChatModel 生成最终响应
七、常见问题与解决方案
7.1 问题:查询性能差
可能原因:
- 没有使用合适的索引
- 索引参数未优化
解决方案:
-
确保已创建 HNSW 或 IVFFlat 索引
-
优化索引参数:
sqlCREATE INDEX ON vector_store USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); -
设置查询参数:
sqlSET hnsw.ef_search = 100;
7.2 问题:向量维度不匹配
可能原因:
- 数据库表中的嵌入维度与 EmbeddingModel 不一致
解决方案:
-
确认 EmbeddingModel 的维度
-
在数据库表中设置正确的维度:
sqlCREATE TABLE vector_store ( id uuid DEFAULT uuid_generate_v4() PRIMARY KEY, content text, metadata json, embedding vector(1536) -- 确保与模型一致 ); -
或在 Spring AI 配置中指定维度:
yamlspring: ai: vectorstore: pgvector: dimensions: 1536
7.3 问题:元数据过滤无效
可能原因:
- 过滤表达式格式不正确
- 元数据存储格式不一致
解决方案:
-
确认元数据格式:
javanew Document("内容", Map.of("key1", "value1", "key2", "value2")); -
使用正确的过滤表达式:
java.filterExpression("key1 == 'value1' && key2 == 'value2'") -
检查 PostgreSQL 日志,查看实际执行的 SQL 语句
7.4 问题:内存不足
可能原因:
- HNSW 索引构建时内存不足
- 查询时内存不足
八、总结
关键要点回顾
- PGvector :是 PostgreSQL 的开源向量扩展,支持高效向量相似性搜索
- Spring AI :通过
spring-ai-starter-vector-store-pgvector提供了开箱即用的集成 - 向量存储 :需要正确配置维度、距离类型和索引类型
- 元数据过滤 :提供了强大的结果筛选能力
- 性能优化 :通过调整索引和查询参数实现