一、通过手动注册rac实例的方式进行恢复,需要注册实例集群等。单机的db_name和rac的db_name要一致不然后面还要注册实例集群(db_unique_name、service_names、instance_name不会涉及在控制文件里,但db_name会涉及到控制文件和数据文件头部中。如果通过参数文件改完之后导致库启动不了ORA-01103: database name 'ORCL' in control file is not 'ORCLDG',如果参数文件改了控制文件也重置,那么在效验数据文件时文件的头部也是不能通过的,也会报ORA-01161: Database name ORCL in the file header does not match ORCLDG in the DATABASE clause)。所以db_name进行异机迁移,不管迁移到FS还是迁移到rac环境,db_name是不能变的。想要变动db_name就只能通过expdp这种逻辑迁移等。
Rac oracle用户节点一:
bash复制代码
[oracle@rac1 dbs]$ cd $ORACLE_HOME/dbs
[oracle@rac1 dbs]$ orapwd file=orapwliufei1 password=123456
[oracle@rac1 dbs]$ vi initliufei1.ora ---实例默认参数文件的保存路径为$ORACLE_HOME/dbs,init+SID_node.ora文件记录了以ASM方式启动参数文件的路径(ASM数据库启动时找不到spfileliufeidg1.ora,找到initliufeidg1.ora里的路径来通过asm管理的参数文件来启动)
SPFILE='+DATA/liufei/spfileliufei.ora'
Rac oracle用户节点二:
bash复制代码
[oracle@rac2 dbs]$ cd $ORACLE_HOME/dbs
[oracle@rac2 dbs]$ orapwd file=orapwliufei2 password=123456
[oracle@rac2 dbs]$ vi initliufei2.ora ---实例默认参数文件的保存路径为$ORACLE_HOME/dbs,init+SID_node.ora文件记录了以ASM方式启动参数文件的路径(ASM数据库启动时找不到spfileliufeidg2.ora,找到initliufeidg2.ora里的路径来通过asm管理的参数文件来启动)
SPFILE='+DATA/liufei/spfileliufei.ora'
节点二:
无须任何操作
节点一:迁移完成前的所有操作都在一个节点操作
(1)还原参数文件
bash复制代码
[oracle@rac1 ~]$ rman target /
run {
ALLOCATE CHANNEL ch00 TYPE disk;
restore spfile to '/oracle/app/oracle/product/11.2.0/db_1/dbs/spfileliufei.ora' from '/backup/full/orcl_spfile_1684_1_20240123';
release channel ch00;
}
[grid@rac1~]$ asmcmd
ASMCMD> cd +data
ASMCMD> mkdir liufei
[oracle@rac1 dbs]$ export ORACLE_SID=liufei1
[oracle@rac1 dbs]$ sqlplus / as sysdba
将vi编辑好的pfile文件转换成spfile文件在ASM磁盘中:
SQL> create spfile='+DATA/liufei/spfileliufei.ora' from pfile='/oracle/app/oracle/product/11.2.0/db_1/dbs/pfileliufei.ora';
SQL> startup nomount
(2)还原控制文件
bash复制代码
[oracle@rac1 ~]$ rman target /
run {
ALLOCATE CHANNEL ch00 TYPE disk;
restore controlfile to '+data/liufei/controlfile/control.ctl' from '/backup/full/orcl_ctl_1683_1_20240123';
release channel ch00;
}
查看asm路径是否有控制文件:
[grid@rac1 ~]$ asmcmd
ASMCMD> cd +data/liufei/controlfile
ASMCMD> ls -l ---通过asm管理的文件会自动命名。设置自动命名的文件+DATA/liufei/CONTROLFILE/current.332.1090793947,和手动恢复的文件+data/liufei/controlfile/control.ctl都可以
bash复制代码
修改控制文件的参数,启动至mount状态:
SQL> show parameter control
SQL> alter system set control_files='+DATA/liufei/CONTROLFILE/current.332.1090793947' scope=spfile; ---设置自动命名的文件+DATA/liufei/CONTROLFILE/current.332.1090793947,和手动恢复的文件+data/liufei/controlfile/control.ctl都可以
SQL> shutdown immediate
SQL> startup mount
SQL> show parameter control
(3)重命名redo日志组
注意:1)通过rman定义set newname for logfile设置路径失败,所以只能在sqlplus中重命名redo日志组。12c版本之后可能支持了在rman中定义set newname for logfile(待验证)
2)只进行重命名redo日志组操作,先不进行删除和重建redo日志组,如果同时进行重建redo日志组,就会导致在后续追归档日志阶段不能应用归档日志(执行recover database using backup controlfile until cancel;命令,报错ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below ORACLE)
SQL> select * from v$logfile; ---重做日志组
SQL> select * from v$standby_log; ---镜像日志组(dg)
sql复制代码
SQL>
alter database rename file '/oracle/app/oracle/oradata/orcl/redo1.log' to '+data/liufei/onlinelog/redo1.log';
alter database rename file '/oracle/app/oracle/oradata/orcl/redo2.log' to '+data/liufei/onlinelog/redo2.log';
RMAN> CATALOG START WITH '/backup/full'; ---注册目录(多用于批量注册归档,也可以用于注册备份片)
RMAN> report schema; ---显示实例的信息。根据数据文件和临时文件ID恢复
bash复制代码
RMAN>
run {
ALLOCATE CHANNEL ch00 TYPE disk;
ALLOCATE CHANNEL ch01 TYPE disk;
###还原数据文件到新的路径
set newname for datafile 1 to '+data';
set newname for datafile 2 to '+data';
set newname for datafile 3 to '+data';
set newname for datafile 4 to '+data';
set newname for datafile 5 to '+data';
set newname for datafile 6 to '+data';
set newname for datafile 7 to '+data';
set newname for datafile 8 to '+data';
###还原临时文件到新的路径
set newname for tempfile 2 to '+data';
###自动全库恢复。restore database会导致所有文件覆盖还原所以谨慎,restore datafile是指定单个文件从rman中还原。
restore database;
###将已发出SET NEWNAME for DATAFILE命令的所有数据文件切换为其新名称。如果是asm管理的文件可能在设置路径时出现问题,导致控制文件的路径和物理路径不对应。所以建议源库为asm转文件系统时不设置这个参数,手动注册和通知控制文件路径catalog datafilecopy和switch datafile。
switch datafile all;
release channel ch00;
release channel ch01;
}
(5)查看数据文件头部和控制文件头部还原的时间
bash复制代码
SQL> select name from v$datafile;
SQL> SELECT FILE#,to_char(checkpoint_change#,'999999999999') ,TO_CHAR(CHECKPOINT_TIME,'YYYY-MM-DD HH24:MI:SS') CPTIME FROM v$datafile_header; ---数据文件头部
SQL> SELECT FILE#,to_char(checkpoint_change#,'999999999999'),TO_CHAR(CHECKPOINT_TIME,'YYYY-MM-DD HH24:MI:SS') CPTIME FROM V$DATAFILE; ---控制文件头部
二、恢复数据
(1)还原归档
注意:先执行一遍recover database using backup controlfile until cancel;和vdatafile_header、VDATAFILE就会输出当前恢复的SCN时间,然后根据时间再决定恢复几天的归档,或者也会显示从那个归档开始恢复,确定了开始恢复的归档号之后,就按照序列号恢复RESTORE ARCHIVELOG sequence,恢复到最新的序列号通过list backup查看最后一个备份的归档号。
bash复制代码
RMAN>
run{
ALLOCATE CHANNEL ch00 TYPE disk;
set archivelog destination to '/backup/arch';
restore archivelog from time 'sysdate-10';
release channel ch00;
} ---如果恢复报错no backup of archived log,根据序列号恢复RESTORE ARCHIVELOG sequence BETWEEN 5877 AND 5971 thread 2;
SQL> select * from v$logfile; ---重做日志组
SQL> select * from v$standby_log; ---镜像日志组(dg)
SQL> select * from v$log; ---rac环境下有多个线程的重做日志组,所以在单机环境下重做日志只保留线程1
sql复制代码
SQL>
alter database add logfile thread 2 group 3 '+data' size 200M;
alter database add logfile thread 2 group 4 '+data' size 200M;
SQL> alter database enable thread 2; ---添加完之后再应用日志线程2,不然节点二报: redo thread 2 is not enabled - cannot mount
[oracle@rac1 dbs]$ srvctl config database -d liufei -a
Database unique name: liufei
Database name: liufei
Oracle home: /oracle/app/oracle/product/11.2.0/db_1
Oracle user: oracle
Spfile: +DATA/liufei/spfileliufei.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: liufei
Database instances: liufei1,liufei2
Disk Groups: DATA
Mount point paths:
Services:
Type: RAC
Database is enabled
Database is administrator managed
五、物理迁移完成查看状态
(1)通过rman恢复的实例是和生产环境一模一样的,所以只需要做后续参数部分的优化
参数优化参考RAC环境的配置即可😄
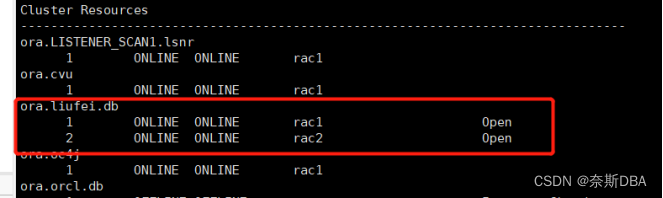
(2)各个节点执行检查实例情况
bash复制代码
数据库文件和undo:
set linesize 500
set pagesize 99
col file_name for a70
col file_id for 9999999
col status for a10
col ts_name for a25
col cur_mb for 99999
col max_mb for 99999
select status, file_id, file_name, tablespace_name ts_name,blocks/128 tolal_mb, maxblocks/128 max_mb,AUTOEXTENSIBLE from dba_data_files order by file_name;
temp临时表空间:
select username,temporary_tablespace from dba_users;
set linesize 230
col file_name for a65
select FILE_ID,FILE_NAME,TABLESPACE_NAME,bytes/1024/1024 tolal_mb,status,AUTOEXTENSIBLE,MAXBYTES/1024/1024 max_mb from dba_temp_files;
redo重做日志:
set linesize 230
col member for a50
select * from v$logfile;
select * from v$log;
查看数据库实例的状态和模式:
select instance_name , status from v$instance ;
select name, open_mode from v$database ;
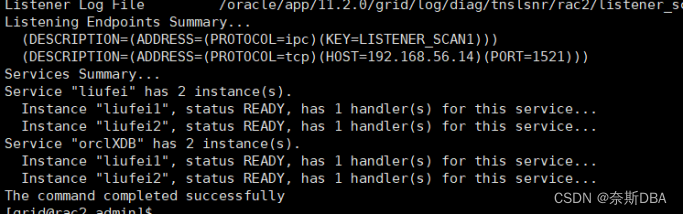
查看监听:
[grid@rac2 admin]$ lsnrctl status LISTENER_SCAN1
sql复制代码
数据同步测试:
节点一:
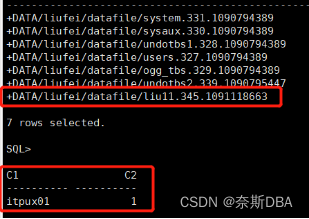
create tablespace liu11 datafile '+data' size 100m autoextend off;
create user liufei identified by 123456 default tablespace liu11;
grant dba to liufei;
conn liufei/123456;
create table liufei.itpux01(c1 varchar2(10),c2 number);
insert into itpux01 values('itpux01','1');
commit;
节点二:
select name from v$datafile;
select * from liufei.itpux01;