MySQL 最重要的两层架构是服务器层和存储引擎层。
服务器层包括连接器、查询缓存、分析器、优化器、执行器、内置函数等所有跨存储引擎的功能。
存储引擎负责数据的存储与读取,使用插件式的架构,不同的存储引擎共用一个服务器层。
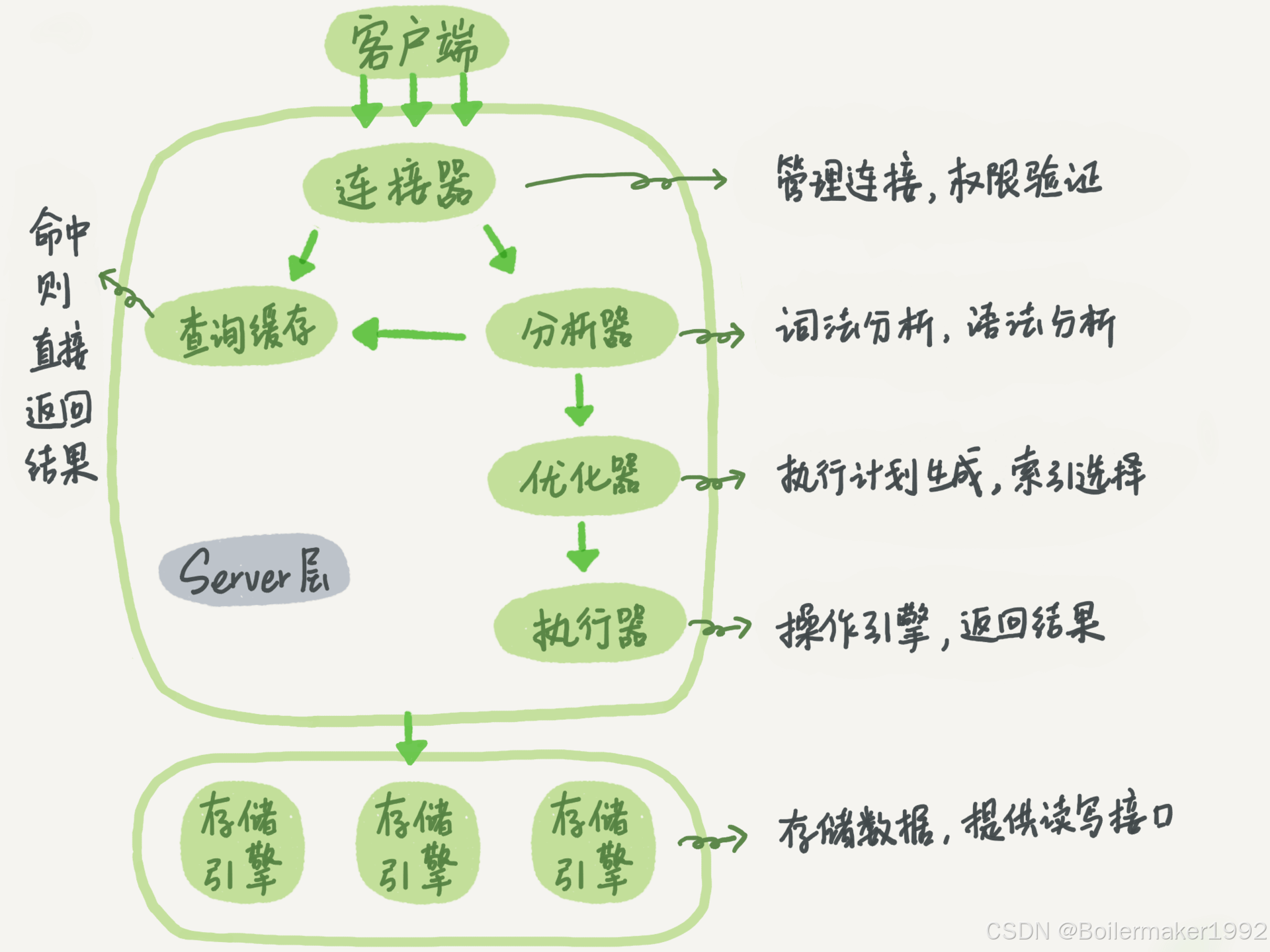
当我们在 MySQL 客户端输入类型这样的数据库连接指令时:mysql -hip -Pport -u$user -p,连接器开始工作。
首先是 TCP 握手,然后连接器开始认证身份。根据用户名和密码查找该用户的权限,这个权限将伴随整个连接。建立连接后,我们就可以执行 SQL 了。如果某个连接太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
我们可以选择与数据库建立长连接或是短连接。长连接就是指不主动断开连接,短连接就是指执行几次命令就断开连接,下次再重新建立。由于建立连接涉及到握手、权限校验等工作,我们会尽量选择长连接。
不过,使用长连接需要注意内存占用问题,因为:
每个数据库连接在数据库服务器和客户端都会占用一定的内存。在数据库服务器端,每个连接都会有一个线程来处理,同时会为连接分配一些缓冲区(如排序缓冲区、连接缓冲区等)。在客户端,连接对象也会占用一些内存。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
这就是为什么,我们会使用线程池与数据库进行连接。如 Hikari 这种高效的线程池会提供完善的内存管理机制。比如设置连接最大生命周期,空闲连接超时时间,维护一定数量的长连接。
在 Java 中,DataSource 是一个标准的接口(JDBC 规范),定义在 javax.sql 包中。不同的数据库连接池实现(如 HikariCP、Druid、Tomcat JDBC Pool 等)都实现了这个接口。
现在开始真正执行 SQL,首先工作的组件是分析器,它的工作通常分为以下阶段:
解析器 Parser:词法分析 -> 语法分析
预处理器 Preprocessor:语义分析 -> 输出解析树
词法分析阶段,我们的 SQL 被拆分成一个一个的 Token,这些 Token 被识别为关键字、标识符、运算符、字面量等。词法分析只将 SQL 流转化为 Token 流,并不对其内容做任何校验。比如,如果你在查询语句中把 select 误写为 elect,词法分析会将其只解析为一个标识符,不会报错。
语法分析阶段,关心这些 Token 的排列是否符合 SQL 语法规则,此时误写的 elect 就会报错,因为查询必须是关键字开头,而不是标识符开头。语法分析也是对 SQL 的结构而非内容进行校验。
语义分析阶段,真正开始分析 SQL 中每个词的含义。如果 SQL 中的表不存在或列不存在,就是在这个时候发现的。
经过了分析器,MySQL 知道要干什么了。在开始执行之前,还要先经过**优化器(Optimizer)**的处理,优化器会做出一系列的 SQL 结构优化和索引优化,筛选出最佳的执行方案。可以通过 explain 关键字查看优化器选择的执行方案。
经过了优化器,MySQL 知道该怎么干了,最终进入执行器阶段,真正开始执行语句。开始执行的时候,要先判断一下你对这个表有没有执行查询的权限。如果没有,就会返回没有权限的错误;如果有,就打开表继续执行。打开表的时候,执行器会根据表的存储引擎定义,去调用这个引擎提供的接口,再下面就进入存储引擎层了。