1.UUID
uuid方式存在问题:占用字节数比较大;ID比较随机,作为MySQL主键写入库时,为了保证顺序性将导致B+Tree节点分裂比较频繁,影响IO性能。
2.数据库方式
步长step = 3,即为机器的数量。
第一台机器:起始值0,下一个ID位:0 + 0*3,0+1*3,0+2*3,..., ~ 0,3,6,9,...,3*n。
第一台机器:起始值1,下一个ID位:1 + 0*3,1+1*3,1+2*3,..., ~ 1,4,7,10,...,3*n + 1。
第一台机器:起始值2,下一个ID位:2 + 0*3,2+1*3,2+2*3,..., ~ 2,5,8,11,...,3*n + 2。
如果起初确认Mysql机器数量为4,则每台机器通过自增方式生成ID如下:
sql
第一台:4 * n + 0。
第二台:4 * n + 1。
第三台:4 * n + 2。
第四台:4 * n + 3。综上,该方式每台机器均衡负载后生成的ID均不会重复。每次请求均通过以下SQL申请新的ID:
sql
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;其中,表Tickets64只有两个字段,字段stub存在唯一索引。MySQL命令之replace保证每次更新stub值时如果存在该值则删除后自增,否则直接自增。
备注:表Tickets64只有一行数据,行锁保证并发问题。
问题:运行中途需要新增机器来增加并发性能,ID如何处理?
解答:观察现有所有机器找到其中最大ID值,例如1800。其次,重新确定每台机器的起始值,例如3000、3001、3002、...。【必须大于1800】。然后,再次修改Mysql自增的步长。最后重启所有机器。
以上这种方式存在的问题:
- 机器横向扩展比较麻烦。
- ID并非单调自增,而是趋势自增。
- 每次获取ID都得操作数据库,高并发严重影响性能。
解决办法之Leaf方案。
2.1.Leaf-segment数据库方案
第一种Leaf-segment方案,在使用数据库的方案上,做了如下改变: - 原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。 - 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库设计方案如下:

优点:
- Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来。
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
- DB宕机会造成整个系统不可用。
2.2.Leaf-segment数据库进化方案之双buffer优化
对于第二个缺点,Leaf-segment做了一些优化,简单的说就是:
Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的TP999指标。
java
public class SegmentIDGenImpl implements IDGen {
//tag 与 segment对应关系
private Map<String, SegmentBuffer> cache = new ConcurrentHashMap<String, SegmentBuffer>();
public Result get(final String key) {
if (cache.containsKey(key)) {
SegmentBuffer buffer = cache.get(key);
if (!buffer.isInitOk()) {// 双检加锁
synchronized (buffer) {
if (!buffer.isInitOk()) {
updateSegmentFromDb(key, buffer.getCurrent());
buffer.setInitOk(true);
}
}
}
return getIdFromSegmentBuffer(cache.get(key));
}
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
public void updateSegmentFromDb(String key, Segment segment) {
StopWatch sw = new Slf4JStopWatch();
SegmentBuffer buffer = segment.getBuffer();
LeafAlloc leafAlloc;
if (!buffer.isInitOk()) {
//UPDATE T_LEAF_ALLOC SET MAX_ID = MAX_ID + STEP WHERE BIZ_TAG = #{tag}
// mysql 写操作不存在并发问题。初始化完毕MAX_ID
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
} else if (buffer.getUpdateTimestamp() == 0) {
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);
buffer.setUpdateTimestamp(System.currentTimeMillis());
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step
} else {
long duration = System.currentTimeMillis() - buffer.getUpdateTimestamp();
int nextStep = buffer.getStep();
if (duration < SEGMENT_DURATION) {
if (nextStep * 2 > MAX_STEP) {
//do nothing
} else {
nextStep = nextStep * 2;
}
} else if (duration < SEGMENT_DURATION * 2) {
//do nothing with nextStep
} else {
nextStep = nextStep / 2 >= buffer.getMinStep() ? nextStep / 2 : nextStep;
}
logger.info("leafKey[{}], step[{}], duration[{}mins], nextStep[{}]", key, buffer.getStep(), String.format("%.2f",((double)duration / (1000 * 60))), nextStep);
LeafAlloc temp = new LeafAlloc();
temp.setKey(key);
temp.setStep(nextStep);
leafAlloc = dao.updateMaxIdByCustomStepAndGetLeafAlloc(temp);
buffer.setUpdateTimestamp(System.currentTimeMillis());
buffer.setStep(nextStep);
buffer.setMinStep(leafAlloc.getStep());//leafAlloc的step为DB中的step
}
// must set value before set max
long value = leafAlloc.getMaxId() - buffer.getStep();
segment.getValue().set(value);
segment.setMax(leafAlloc.getMaxId());
segment.setStep(buffer.getStep());
sw.stop("updateSegmentFromDb", key + " " + segment);
}
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {
// 一个进程中,存在并发访问cache中某个tag
while (true) {
buffer.rLock().lock();
try {
// 从双buffer中获取当前Segment
final Segment segment = buffer.getCurrent();
// 如果当前步长内,ID使用率已经达到步长的90%,则需要切换buffer
if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {
service.execute(new Runnable() {
@Override
public void run() {
//获取到第二个Segment
Segment next = buffer.getSegments()[buffer.nextPos()];
boolean updateOk = false;
try {
// 初始化第二个Segment对应的其实ID,以及步长
updateSegmentFromDb(buffer.getKey(), next);
updateOk = true;
} catch (Exception e) {
logger.warn(buffer.getKey() + " updateSegmentFromDb exception", e);
} finally {
if (updateOk) {
buffer.wLock().lock();
buffer.setNextReady(true);
buffer.getThreadRunning().set(false);
buffer.wLock().unlock();
} else {
buffer.getThreadRunning().set(false);
}
}
}
});
}
// 在当前步长中获取下一个ID
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {// 没有达到最大ID之前,均成功返回
return new Result(value, Status.SUCCESS);
}
} finally {
buffer.rLock().unlock();
}
//以下执行说明ID已经达到最大值
waitAndSleep(buffer);
buffer.wLock().lock();
try {
final Segment segment = buffer.getCurrent();
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {//以下成立,说明上述定时任务切换Segment成功
return new Result(value, Status.SUCCESS);
}
if (buffer.isNextReady()) {//
buffer.switchPos();
buffer.setNextReady(false);
} else {
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
} finally {
buffer.wLock().unlock();
}
}
}
}2.3.Leaf高可用容灾
对于第三点"DB可用性"问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式同步数据。同时使用公司Atlas数据库中间件(已开源,改名为DBProxy)做主从切换。当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小。如果你的系统要保证100%的数据强一致,可以选择使用"类Paxos算法"实现的强一致MySQL方案,如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。但是运维成本和精力都会相应的增加,根据实际情况选型即可。
3.Leaf-snowflake方案
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,我们提供了 Leaf-snowflake方案。
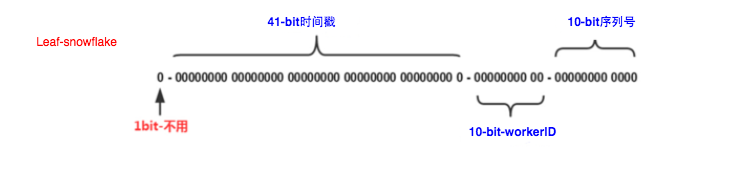
java
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
* @return
* 同步锁的保证:同一毫秒内可能存在多个请求竞争得到同步锁。
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
/**
* 同一毫秒内允许 MAX_SEQUENCE(4095)个请求先后生成ID。多余的请求因为以下条件的成立拒绝生成
*/
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
/**
* 在64位字节中通过 或 操作将 时间戳、数据中心、机器标识、序列号4部分放到对应字节范围内。
* 注意:对于同一个项目,datacenterId、machineId可能是不变的。如果随便更改时间戳起始值之START_STMP值可能导致分布式ID存在相同的情况。
*
* 在分布式ID 64个字节中,41个字节作为时间戳,其对应的最大值为2^41。41 位的时间位是2 ^ 41 / (365 * 24 * 3600 * 1000) = 69 年。
* currStmp - START_STMP 是指距离当年之后的69年内。
* 如果直接用 currStmp 替代,则表示距离1970年后的69年,以2024年为例最多可用15年。
*/
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void m1() {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}3.1.解决时钟回拨问题
时钟回拨导致的问题存在两个:获取分布式ID & 服务启动流程。
3.1.1.服务启动
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。

参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
- 若写过,则用自身系统时间与leaf_forever/{self}节点记录时间做比较,若小于leaf_forever/{self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
- 若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
- 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。
- 否则认为本机系统时间发生大步长偏移,启动失败并报警。
- 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
java
public class SnowflakeIDGenImpl implements IDGen {
public SnowflakeIDGenImpl(String zkAddress, int port, long twepoch) {
this.twepoch = twepoch;
Preconditions.checkArgument(timeGen() > twepoch, "Snowflake not support twepoch gt currentTime");
final String ip = Utils.getIp();
SnowflakeZookeeperHolder holder = new SnowflakeZookeeperHolder(ip, String.valueOf(port), zkAddress);
boolean initFlag = holder.init();
Preconditions.checkArgument(workerId >= 0 && workerId <= maxWorkerId, "workerID must gte 0 and lte 1023");
}
}
public class SnowflakeZookeeperHolder {
public boolean init() {
try {
CuratorFramework curator = createWithOptions(connectionString, new RetryUntilElapsed(1000, 4), 10000, 6000);
curator.start();
Stat stat = curator.checkExists().forPath(PATH_FOREVER);
if (stat == null) {
//不存在根节点,机器第一次启动,创建/snowflake/ip:port-000000000,并上传数据
zk_AddressNode = createNode(curator);
//worker id 默认是0
updateLocalWorkerID(workerID);
//定时上报本机时间给forever节点:其实就是一个定时任务,每隔3秒上报一次当前时间啊
ScheduledUploadData(curator, zk_AddressNode);
return true;
} else {
Map<String, Integer> nodeMap = Maps.newHashMap();//ip:port->00001
Map<String, String> realNode = Maps.newHashMap();//ip:port->(ipport-000001)
//存在根节点,先检查是否有属于自己的根节点
List<String> keys = curator.getChildren().forPath(PATH_FOREVER);
for (String key : keys) {
String[] nodeKey = key.split("-");
realNode.put(nodeKey[0], key);
nodeMap.put(nodeKey[0], Integer.parseInt(nodeKey[1]));
}
Integer workerid = nodeMap.get(listenAddress);
if (workerid != null) {
//有自己的节点,zk_AddressNode=ip:port
zk_AddressNode = PATH_FOREVER + "/" + realNode.get(listenAddress);
workerID = workerid;//启动worder时使用会使用
if (!checkInitTimeStamp(curator, zk_AddressNode)) {
throw new CheckLastTimeException("init timestamp check error,forever node timestamp gt this node time");
}
//准备创建临时节点
doService(curator);
// 将workerID 初始化在 leaf 服务本地磁盘内部,一旦zk出现问题可以从本地磁盘获取该workerID
updateLocalWorkerID(workerID);
} else {
//表示新启动的节点,创建持久节点 ,不用check时间
String newNode = createNode(curator);
zk_AddressNode = newNode;
String[] nodeKey = newNode.split("-");
workerID = Integer.parseInt(nodeKey[1]);
doService(curator);
updateLocalWorkerID(workerID);
LOGGER.info("[New NODE]can not find node on forever node that endpoint ip-{} port-{} workid-{},create own node on forever node and start SUCCESS ", ip, port, workerID);
}
}
} catch (Exception e) {
LOGGER.error("Start node ERROR {}", e);
try {
// 如果 zk 出现问题,从本地磁盘获取workerID
Properties properties = new Properties();
properties.load(new FileInputStream(new File(PROP_PATH.replace("{port}", port + ""))));
workerID = Integer.valueOf(properties.getProperty("workerID"));
LOGGER.warn("START FAILED ,use local node file properties workerID-{}", workerID);
} catch (Exception e1) {
LOGGER.error("Read file error ", e1);
return false;
}
}
return true;
}
}
java
public class SnowflakeIDGenImpl implements IDGen {
public synchronized Result get(String key) {//获取分布式事务ID
long timestamp = timeGen();
if (timestamp < lastTimestamp) {//出现了时钟回拨现象
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
wait(offset << 1);// 等待一段时间:时钟回拨时间段
timestamp = timeGen();// 再次获取新的时间
if (timestamp < lastTimestamp) {
return new Result(-1, Status.EXCEPTION);
}
} catch (InterruptedException e) {
LOGGER.error("wait interrupted");
return new Result(-2, Status.EXCEPTION);
}
} else {
return new Result(-3, Status.EXCEPTION);
}
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
//seq 为0的时候表示是下一毫秒时间开始对seq做随机
sequence = RANDOM.nextInt(100);
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//如果是新的ms开始
sequence = RANDOM.nextInt(100);
}
lastTimestamp = timestamp;
// 返回最终的分布式ID
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;
return new Result(id, Status.SUCCESS);
}
}