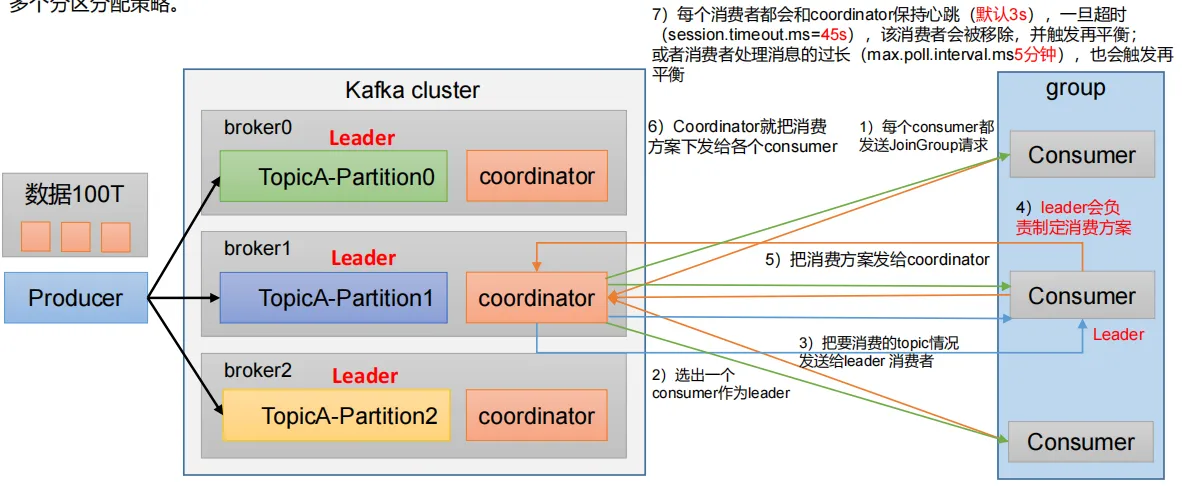
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。
2、Kafka有四种主流的分区分配策略: Range、RoundRobin(轮询)、Sticky(粘性)、CooperativeSticky(配合的粘性)。
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky
Kafka 消费者组的分区分配策略决定了分区如何分配给组内的消费者,核心策略包括以下三种:
1. Range(范围分配)
原理 :
按分区序号范围划分。计算每个消费者分配的分区数 N = \\lceil \\frac{分区总数}{消费者数} \\rceil,将连续 N 个分区分配给一个消费者。
示例:
- 分区:P_0, P_1, P_2, P_3, P_4
- 消费者:C_1, C_2
- 分配结果:
C_1: P_0, P_1, P_2
C_2: P_3, P_4
缺点 :
可能导致分区分配不均(如分区数无法整除时)。
2. RoundRobin(轮询分配)
原理 :
将分区按哈希值排序后轮询分配给消费者。
示例:
- 分区(按哈希排序):P_0, P_1, P_2, P_3
- 消费者:C_1, C_2
- 分配结果:
C_1: P_0, P_2
C_2: P_1, P_3
要求 :
消费者组内所有消费者订阅相同的主题列表。
3. Sticky(粘性分配)
原理 :
初始分配采用轮询,但在消费者变动时,仅调整必要的分区,最大化保留原有分配关系。
优势 :
减少重平衡(Rebalance)时的分区迁移开销。
配置方式
在消费者客户端中指定策略:
// Java 配置
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RoundRobinAssignor");
# Python (kafka-python)
from kafka import RoundRobinPartitionAssignor
consumer_config = {
"partition_assignment_strategy": [RoundRobinPartitionAssignor]
}分区重平衡(Rebalance)
当消费者组内成员变化(如新增或退出)时,触发重平衡,按策略重新分配分区。
影响 :
可能导致消费暂停,故需优化策略(如 Sticky)减少波动。
适用场景
- Range:主题少且分区分布均匀时。
- RoundRobin:多主题且需均衡负载时。
- Sticky:频繁变动消费者组的场景(如云环境)。