1. 日志数据的存储
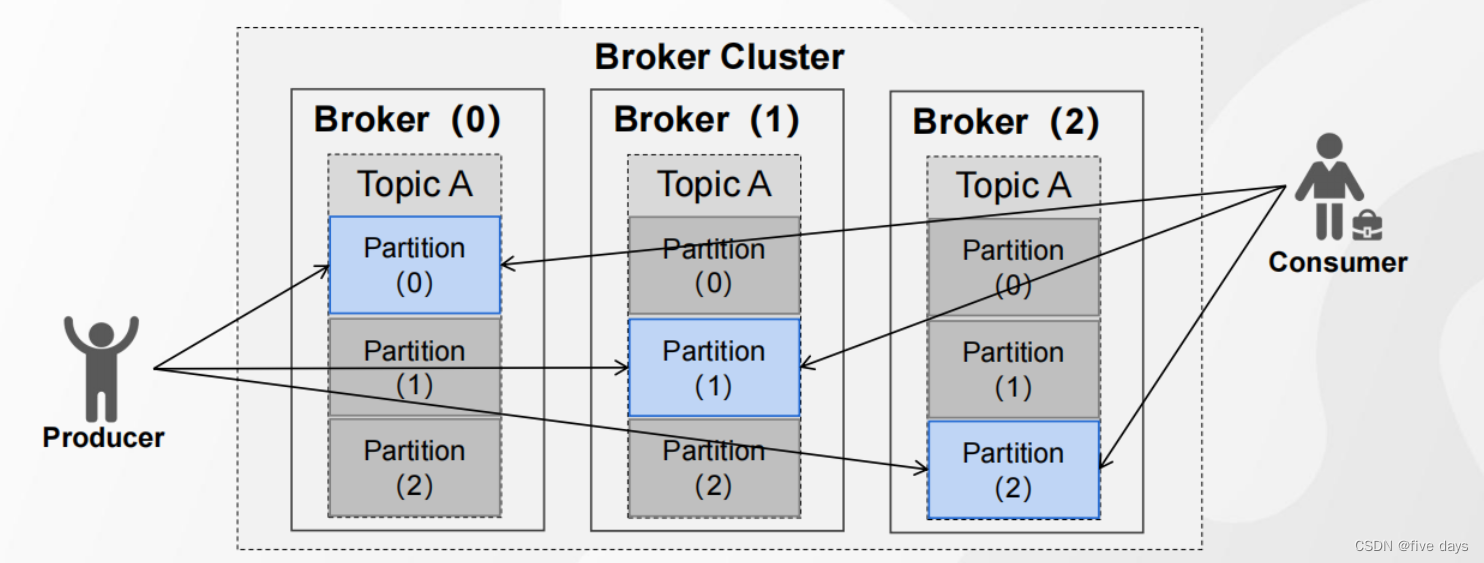
1.1 Partition
- 为了实现横向扩展,把不同的数据存放在不同的 Broker 上,同时降低单台服务器的访问压力,我们把一个Topic 中的数据分隔成多个 Partition
- 每个 Partition 中的消息是有序的,顺序写入,但是全局不一定有序
- 在服务器上,每个 Partition 都有一个物理目录( TopicN )后面的数字代表分区

1.2 Replica副本
- 为了提高分区的可靠性, Kafka 设计了副本机制
- 副本数必须小于等于节点数,而不能大于 Broker 的数量
- Leader 对外提供读写服务, Follower 唯一的任务就是从 Leader 异步拉取数据
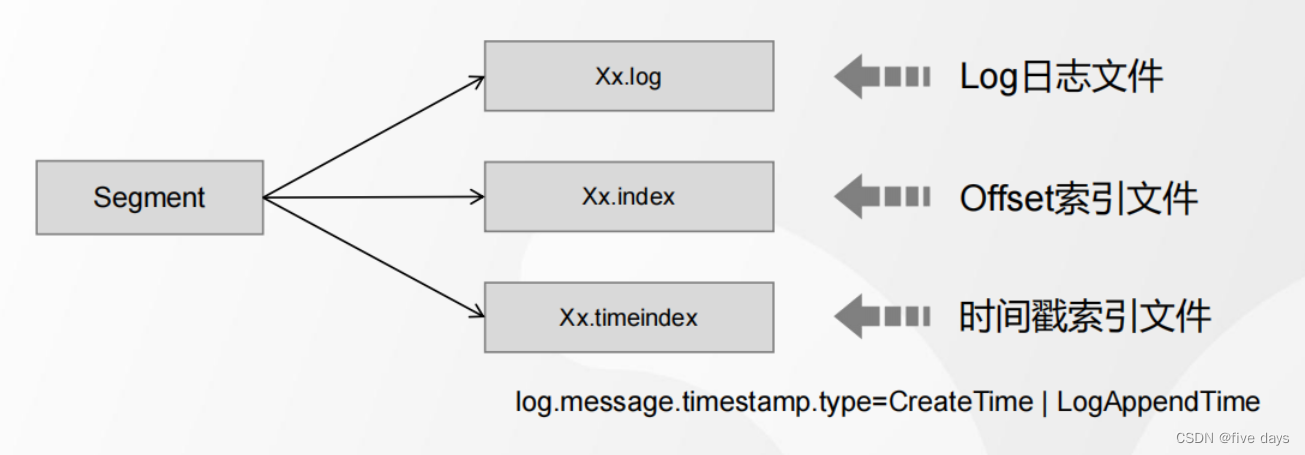
1.3 Segment段
- 为了防止Log不断追加导致文件过大,导致检索消息效率变低,一个Partition又 被划分成多个Segment来组织数据.
在这里会有3个配置,也就是log的阈值配置。什么时候下进行分段
- log.segment.bytes :根据日志文件大小
- log.roll.hours 、 log.roll.ms :根据时间戳差值
log.index.size.max.bytes:根据索引文件大小
每一个segment都是由一个log文件和2个index文件组成的,其中时间戳索引的创建方式可以自定义的执行createTime或LogAppendTime.默认是creareTime
1.4 Sparse Index(稀疏索引)
索引文件的查看可以通过以下命令进行查看

kfaka索引文件中记录的Offset不是连续的,而是采用了稀疏索引。根据配置的大小,稀疏索引记录的是从Log中的哪个位置开始检索,比如配置的是4kb,则当log文件中向下存储的数据达到4kb的话,就会记录一个索引值

1.5 分区副本在Broker上的分布
创建一个topic
./kafka-topics.sh--bootstrap-server192.168.61.101:9092--create--topic3p3r--partitions3--replication-factor3
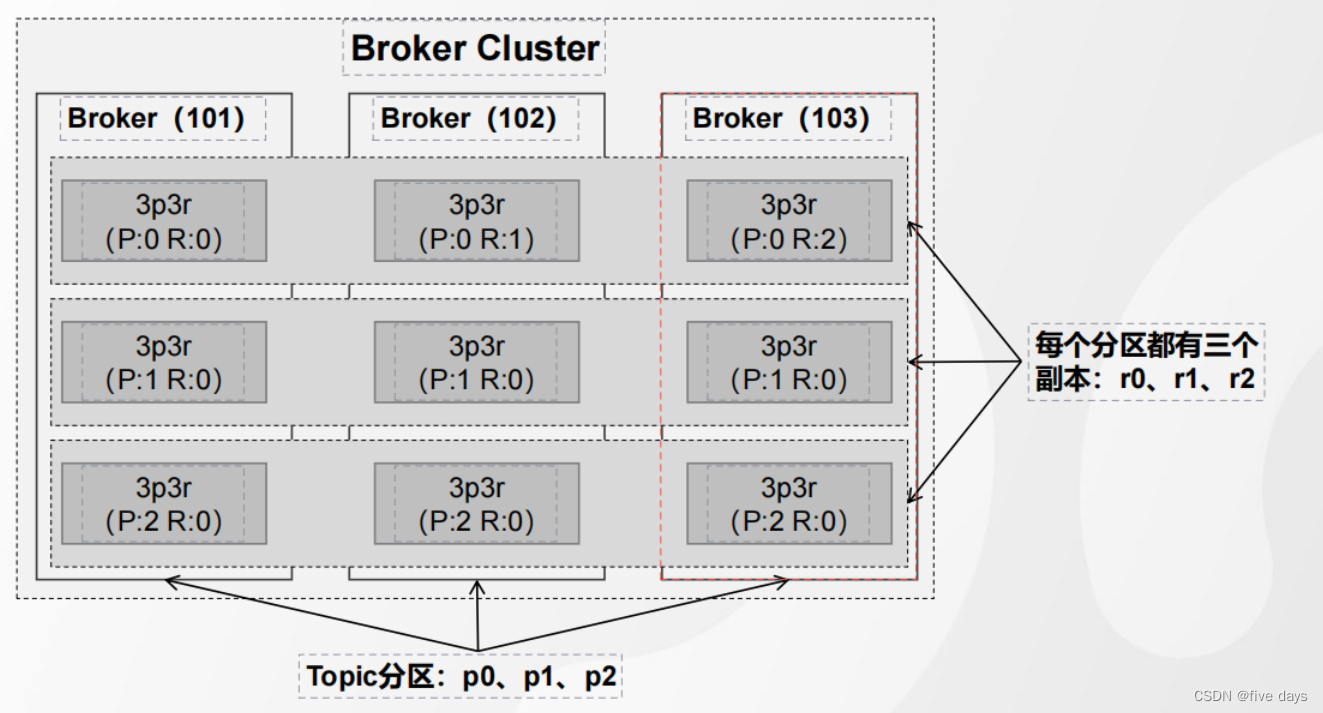
假设配置的是3p3r,则我们看下服务器上的存储
查看Topic信息
./kafka-topics.sh--bootstrap-server192.168.61.101:9092--describe--topic3p3r
其中 Partition是分区,Leader后面代表的是在哪台服务器上,Replicas就是副本信息,ISR是个副本队列
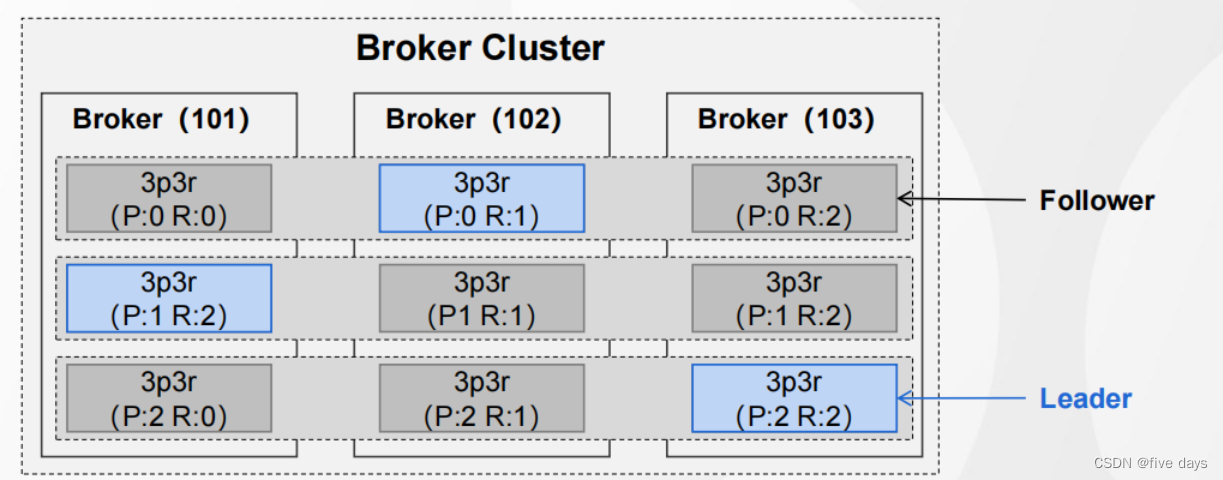
假设配置的是4p2r,则物品们查看topic信息如图所示
创建、查看topic
./kafka-topics.sh --bootstrap-server 192.168.61.101:9092 --create --topic 4p2r --partitions 4 --replication-factor 2
./kafka-topics.sh --bootstrap-server 192.168.61.101:9092 --describe --topic 4p2r


假设我们配置的是6p2r


由以上我们可以看出,副本分配的两个基本原则和规律
1、副本会被平均分布在所有的Broker之上
2 、 partition 的多个副本应该分配在不同的 Broker 上
基于上面的规则,分区副本最终落入哪个节点,还会收到两个随机数的影响
1、第一个随机数:startIndex,决定了第一个分区的第一个副本的放置位置
2 、第二个随机数: nextReplicaShift ,决定了分区中,副本跟副本的间距nextReplicaShift%(BrokerSize-1)
这样设计的目的在于提高Broker服务器的容灾能力
2. 消息保留与清理机制
对于一些太久的日志,我们需要一定的清理策略。
当开启清理策略后,有两种方式提供开发者选择
log.cleanup.policy=delete (默认项) // 删除策略
log.cleanup.policy=compact // 压缩策略
2.1 删除策略(delete)
kafka可以通过定时任务实现日志数据的删除,默认5分钟执行一次
log.retention.check.interval.ms=300000
那么要删除什么样的数据呢?kafka提供了两个纬度以及对应不同的配置
时间纬度
log.retention.hours(默认值是168个小时,时间戳超过的数据会被删除)
log.retention.minutes (默认值是空,优先级比小时高)
log.retention.ms (默认值是空,优先级比分钟高)
若产生消息的速度不均匀,有时多、有时少,就可以根据日志大小删除
log.retention.bytes (表示所有日志文件的总大小,默认值是 -1 ,代表不限制大小)
log.segment.bytes (对单个 Segment 文件大小进行限制,默认值 1G )
2.2 压缩策略(compact)
若设置为压缩策略compact,则表示不清楚日志,只对日志数据进行压缩处理
思考问题: 如果同一个key重复写入多次,是会存储多次?还是会更新?
kafka中是存储多次的,如: _ _consumer_offsets
那么压缩策略是怎么做的呢?(将相同的key进行去重压缩)

3. Broker高可用架构
高可用,无非就是选举机制、数据的一致性也就是主从同步,以及对于故障的处理,由于kafka是直接数据存储在磁盘中的,因此无需考虑持久化,Broker的高可用 涉及到一系列的动作
- 选举出一个Controller
- 从分区中选举出Leader角色
- 主从同步
- Replica故障处理
3.1 选举机制
3.1.1 Controller选举
Controller其实就是一个Broker,由它来负责选举出新的Leader,那么Controller是怎么选举出来的呢
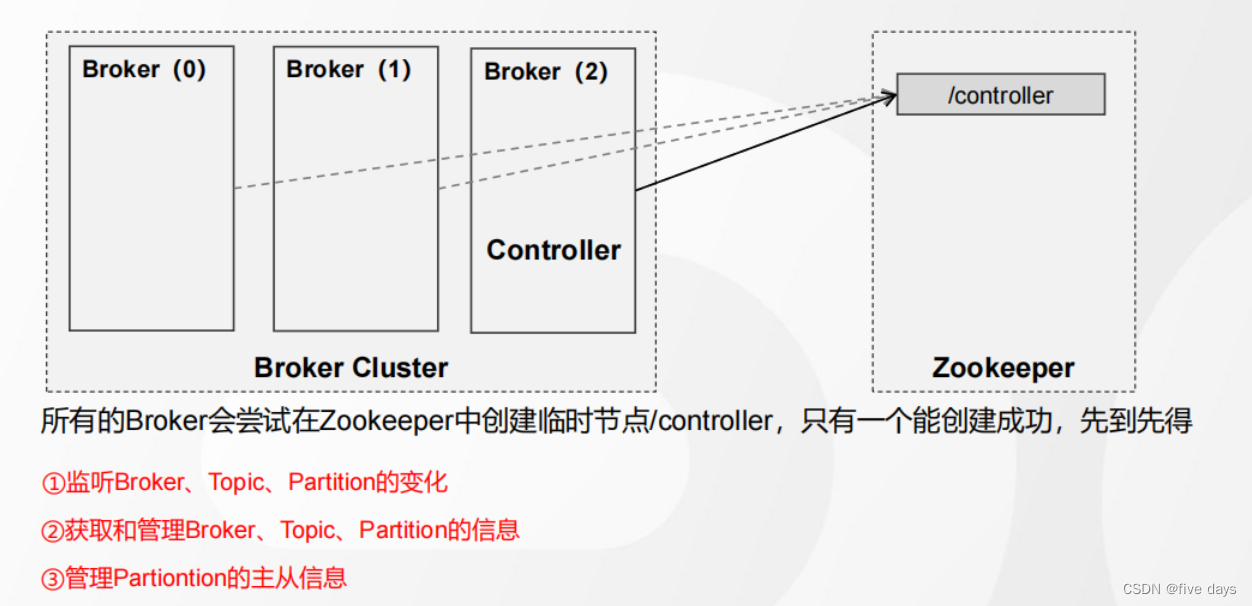
3.1.2 分区副本Leader的选举
在讲解Leader选举前,我们先复习以下博客Kafka之Producer原理-CSDN博客中提到的ISR机制的几个概念
AR ( Assigned-Replicas ),一个分区所有的副本
ISR ( In-Sync Replicas ),在 AR 中,跟 Leader 保持积极同步数据的副本
OSR ( Out-Sync-Replicas ),在 AR 中,跟 Leader 同步滞后的副本
AR = ISR + OSR
- 当Leader副本发生故障时,只有在ISR中的副本才能参与新Leader的选举
- 问题:如果ISR为空呢? unclean.leader.election.enable配置为false OSR也可以进行选举
- Kafka采用了类似于继位传嫡的选举协议,选择ISR中位置靠前的节点成为新的Leader.
3.2 主从同步
从节点和主节点的同步过程如下:
1 、首先, Follower 节点向 Leader 发送一个 fetch 请求
2 、然后, Leader 向 Follower 发送数据
3 、接着, Follower 接收到数据响应后,依次写入消息、并更新 LEO 值
4 、最后, Leader 更新 HW ( ISR 最小的 LEO )
5 、循环上述过程,直至所有 Follower 完成数据同步
整体流程图如下所示:



Kafka设计的ISR复制,既可以在保障数据一致性,又可以提供高吞吐量(ISR队列中清除响应不积极的Follower节点)
3.3 Replica故障处理
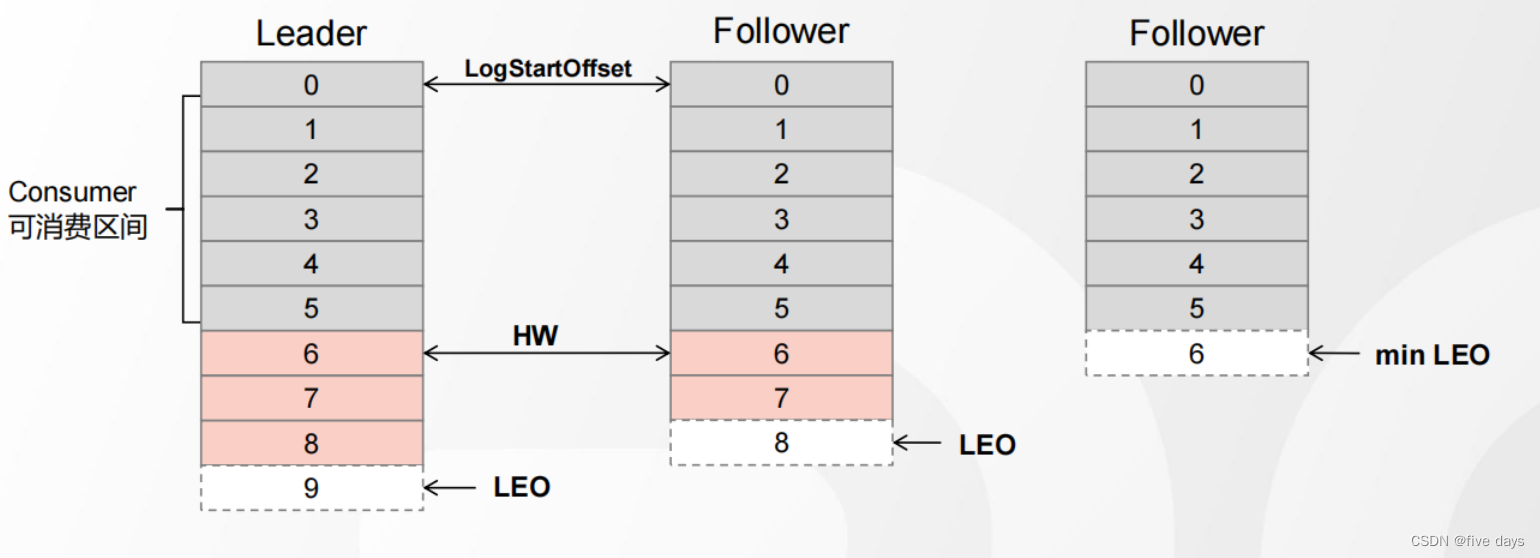
- Follower发生故障,会被先提出ISR,Follower恢复之后,从HW开始同步数据
- Leader发生故障,会先选举出一个新的Leader,其它的Follower将高于HW的消息截取掉,然后从新的Leader同步数据
4. 总结
本文介绍Broker服务器,主要讲了Broker中日志的存储,从大到小依次为Partition、Segment,副本机制的具体存储形式,是怎么进行负载均衡和容灾保障的,在Segment中我们直到了Segment是由一个Log文件和两个索引文件组成的,索引文件主要起的是一个提升查询效率的作用。随后当kafka中log文件过大的时候,kagka中提供了两种维度上的删除策略以及相同key去重压缩的compact策略。最后,kafka高可用中的选举机制是先到先得选举Controller,再根据ISR副本队列嫡长子继位的算法进行Leader的选举;以及Kafka中的主从同步是以高水位HW为界限,不断的同步数据,直到LEO值相等完成数据的同步。最后讲到了副本故障的处理,针对follwe节点故障,则直接踢出ISR队列,Leader故障,就会触发选举机制,选举出一个新的Leader,最后数据从LEO处以上的开始同步,高于HW的消息全部截断。