✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:数据库



目录
[MySQL 案例实战教程](#MySQL 案例实战教程)
[逻辑条件:and or](#逻辑条件:and or)
[排序 order by](#排序 order by)
[like 通配符](#like 通配符)
[group by 分组查询](#group by 分组查询)
MySQL 案例实战教程

MySQL的数据类型
- MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
- 备注: char 和varchar 一定要指定长度,float 会自动提升为double,timestamp 是时间的混合类型,理论上可以存储 时间格式和时间戳。
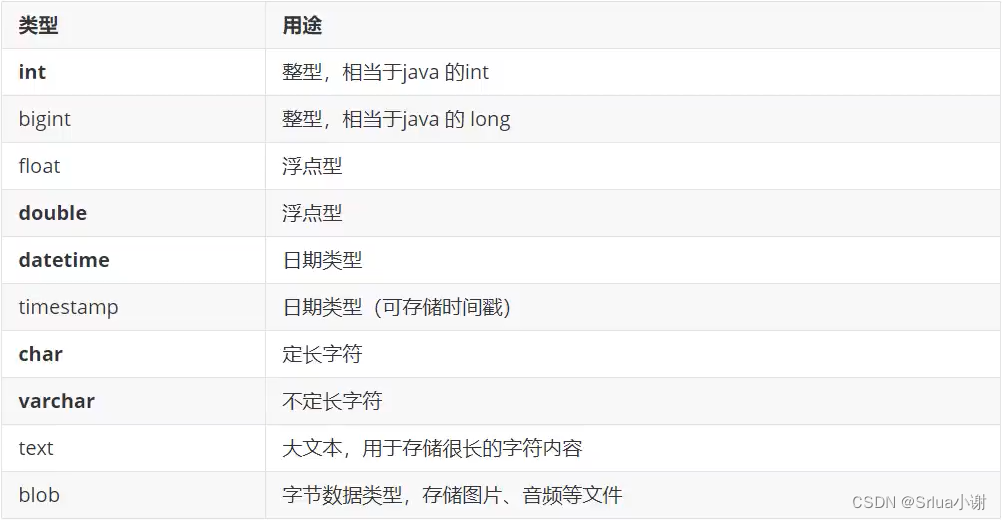
Mysql语法
建表
`--建表
create table 表名(
字段名 类型 约束(主键,非空,唯一,默认值),
字段名 类型 约束(主键,非空,唯一,默认值),
)编码,存储引擎`约束
- **NOT NULL:**规定某一列不能存储null值
- **UNIQUE:**保证某列的每行都有唯一的值
- **PRIMARY KEY:**NOT NULL和UNIQUE的组合
- **FOREIGN KEY(尽量少用,不好维护):**保证一个表中的数据匹配另一个表中的值的参照完全性
- **CHECK:**保证列中的值符合条件
- DEFAULT:规定没有列赋值时的默认值
实例
sql
DROP TABLE IF EXISTS `websites`;
CREATE TABLE `websites`(
id int(11) NOT NULL AUTO_INCREMENT,
name char(20) NOT NULL DEFAULT'' COMMENT'站点名称',
url varchar(255) NOT NULL DEFAULT '',
alexa int(11) NOT NULL DEFAULT '0' COMMENT'Alexa排名',
sal double COMMENT'广告收入',
country char(10) NOT NULL DEFAULT'' COMMENT'国家',
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;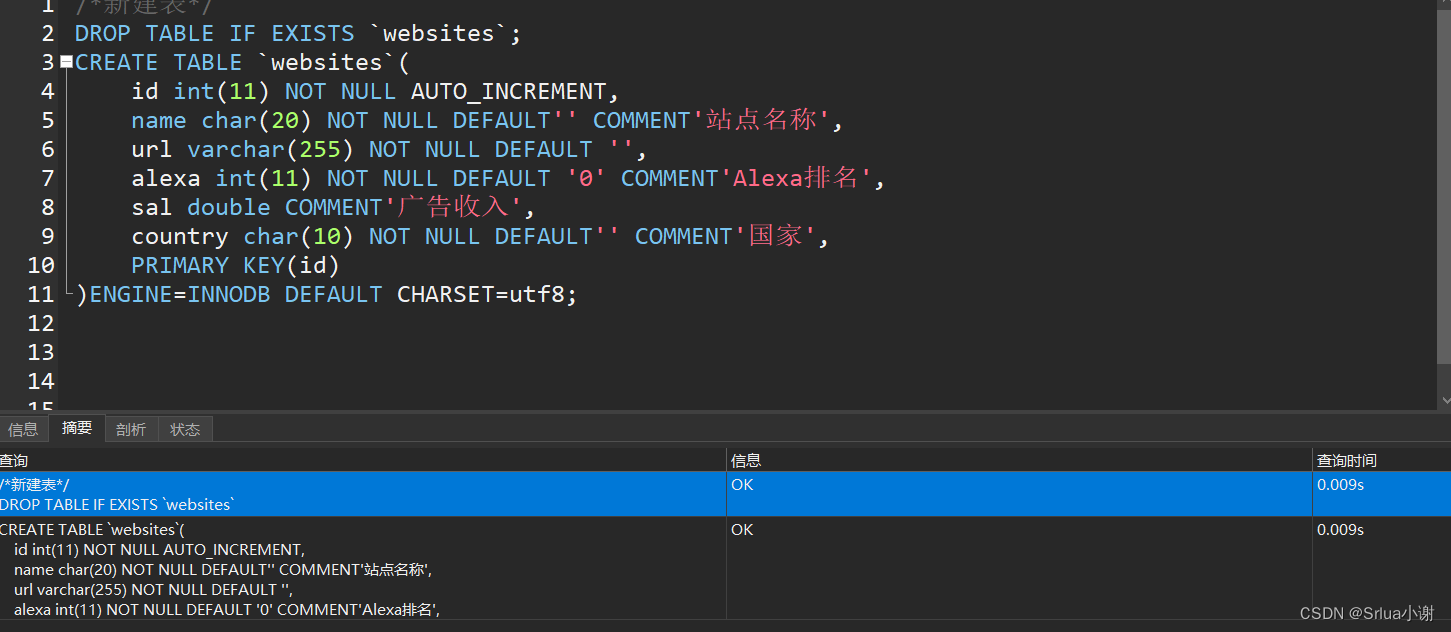
插入
sql
INSERT INTO websites(name,url,alexa,sal,country) VALUES("腾讯",'https://www.qq.com',18,1000,'CN');

删除
sql
DELETE FROM websites WHERE id = 2;现在我们删除di为2的行



更新
sql
UPDATE websites SET sal = 2000 WHERE id = 3;更新id为3的行sal为2000


注释
sql
-- 这是注释
/*
sql sentence
*/
查询
sql
DROP TABLE IF EXISTS `websites`;
CREATE TABLE `websites`(
id int(11) NOT NULL AUTO_INCREMENT,
name char(20) NOT NULL DEFAULT'' COMMENT'站点名称',
url varchar(255) NOT NULL DEFAULT '',
alexa int(11) NOT NULL DEFAULT '0' COMMENT'Alexa排名',
sal double COMMENT'广告收入',
country char(10) NOT NULL DEFAULT'' COMMENT'国家',
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
INSERT INTO `websites` VALUES
(1,'Google', 'https://www.google.com/', '1',2000 , 'USA '),
(2,'淘宝','https://www.taobao.com/','13',2050,'CN'),
(3,'菜鸟教程', 'http://www.runoob.com/', '4689' ,0.0001,'CN'),
(4,'微博', 'http://weibo.com/','20',50,'CN'),
(5,'Facebook','https://www.facebook.com/','3',500, 'USA');
CREATE TABLE IF NOT EXISTS `access_log`(
`aid` int(11) NOT NULL AUTO_INCREMENT,
`site_id` int(11) NOT NULL DEFAULT '0' COMMENT '网站id',
`count` int(11) NOT NULL DEFAULT '0' COMMENT '访问次数',
`date` date NOT NULL,
PRIMARY KEY (`aid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `access_log` (`aid`,`site_id`,
`count`,`date`) VALUES
(1,1,45,'2016-05-10'),
(2,3,100,'2016-05-13'),
(3,1,230,'2016-05-14'),
(4,2,10,'2016-05-14'),
(5,5,205,'2016-05-14'),
(6,4,13,'2016-05-15'),
(7,3,220,'2016-05-15'),
(8,5,545,'2016-05-16'),
(9,3,201,'2016-05-17'),
(10,88,9999,'2016-09-09');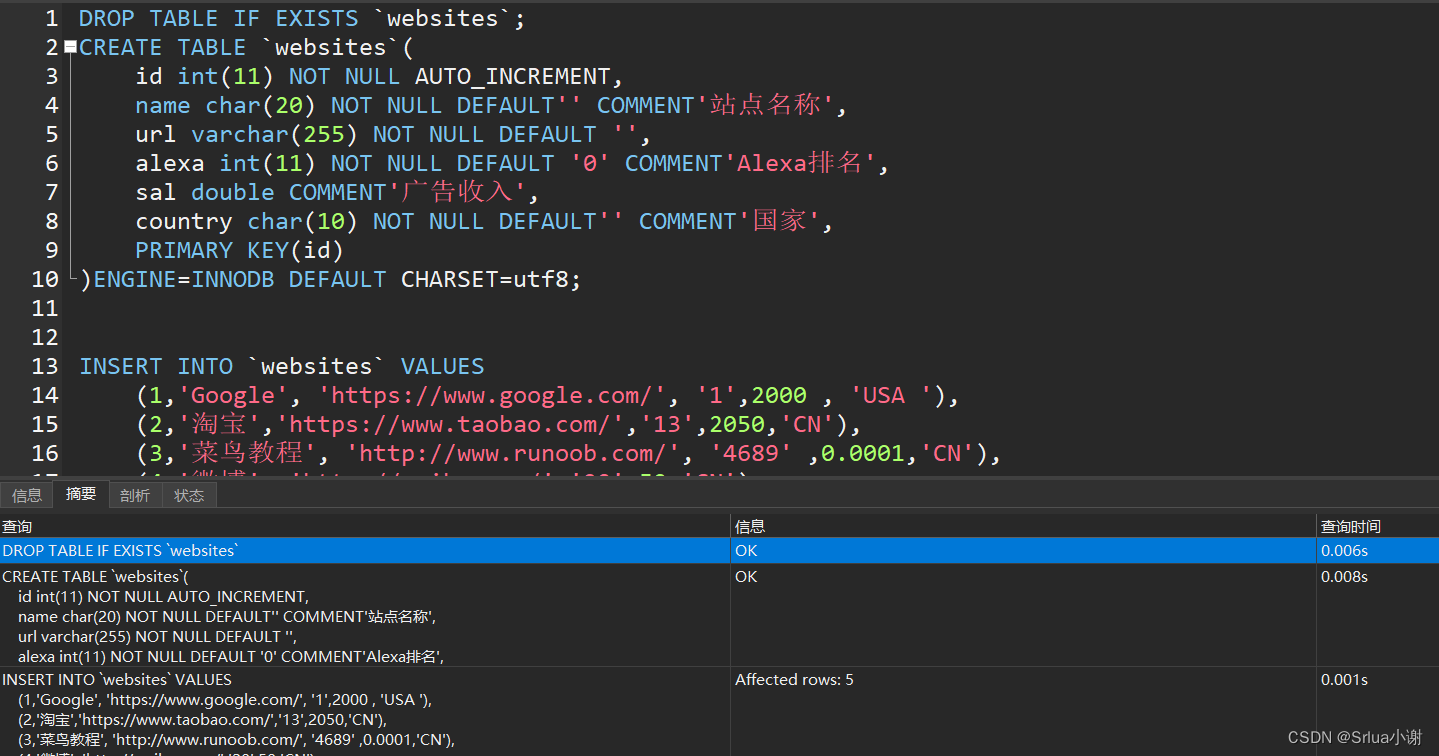
运行成功,查看websites表
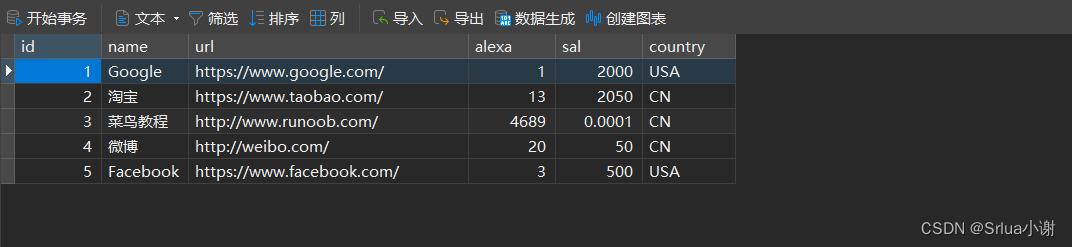
查询语句
sql
select * from websites
select id,name,url,alexa from websites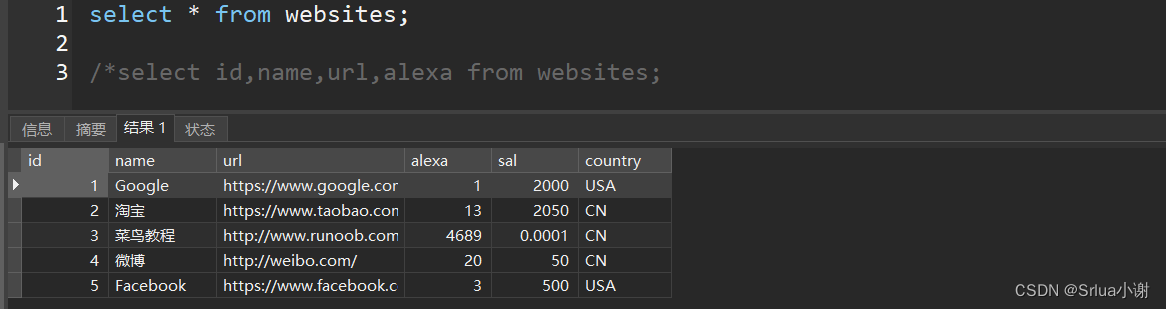

实际开发中尽量不要使用 *
原因:
在实际开发中尽量不要使用*通配符查询语句的原因有几个方面:
**1. 性能问题:**使用*通配符会导致数据库引擎进行全表扫描,这会带来性能上的损耗,特别是当数据量非常大的时候。相比之下,指定具体的列名可以让数据库引擎更有效地执行查询,提高查询效率。
**2. 查询结果的不确定性:**使用*通配符可能会返回多个不必要的列,包括一些不需要的敏感信息或者关联表中的数据,增加了数据传输的开销,并且也增加了处理结果集的复杂度。
**3. 维护性和可读性:**明确指定需要查询的列名可以使查询语句更易于维护和理解,尤其是在团队协作或者未来需要对查询进行修改和优化的情况下。
因此,尽量避免使用*通配符,而是明确指定需要查询的列名,可以提高查询的性能、确定性和可维护性。
分页查询
sql
select id,name,url,alexa from websites limit 2
-- 从第一条开始查,查到第二条
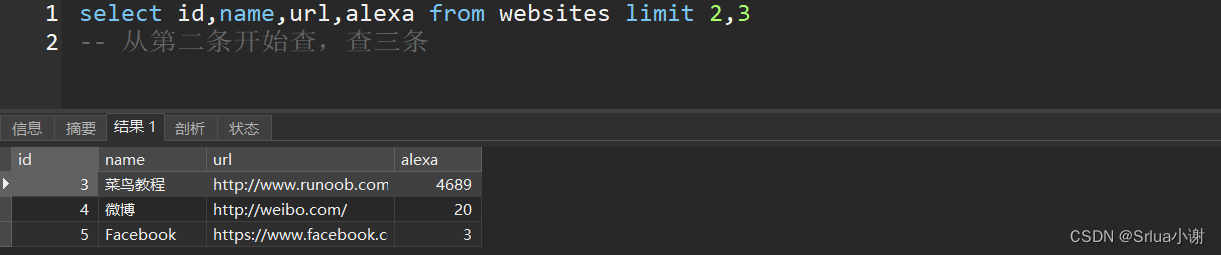
select id,name,url,alexa from websites limit 2,3
-- 从第二条开始查,查三条
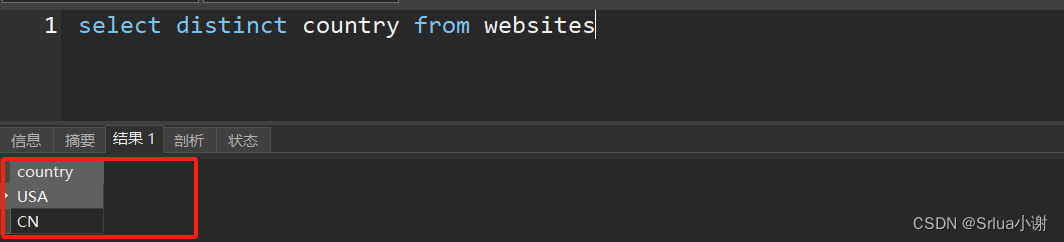
distinct去重
sql
select distinct country from websites查询结果去除表中重复重复国家的数据项

where语句
运算符> < >= <= <> != = is null is not null like in
在sql语句中 null值和任何东西比较 都为false,包括null
sql
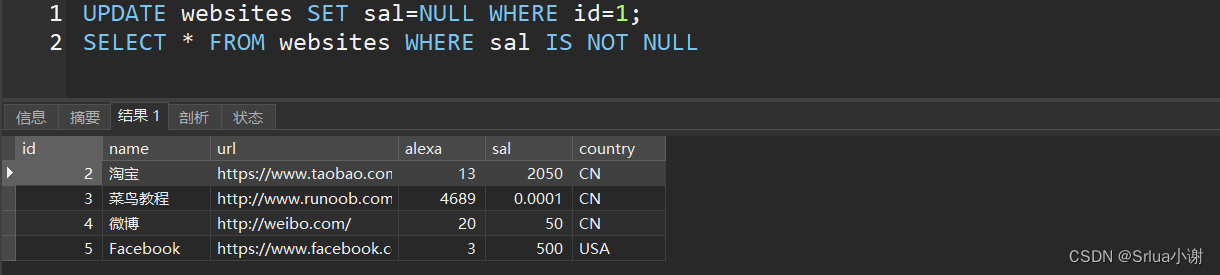
SELECT * FROM websites WHERE sal IS NOT NULL 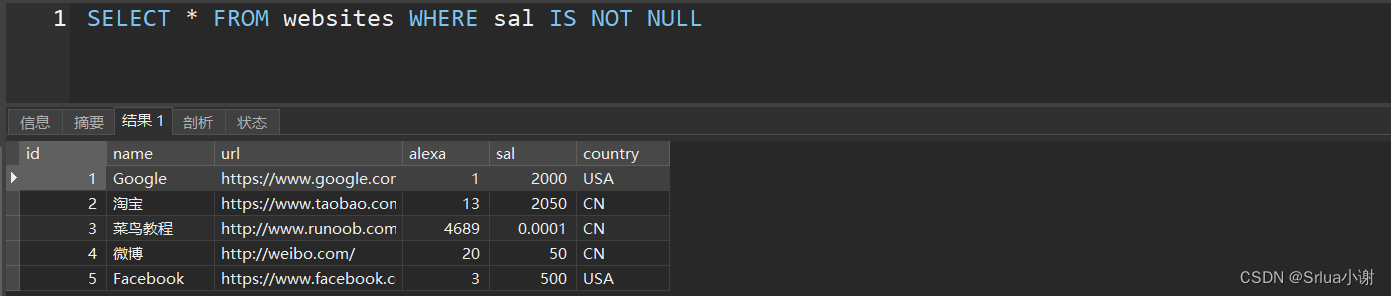
现在我们把id为1的行sal置为NULl,再次查询
逻辑条件:and or
sql
select * from websites where sal<=0 and sal>=2000;
select * from websites where sal between 2000 and 0;/*和上面效果一样*/
select * from websites where sal<5 or sal is null;
排序 order by
sql
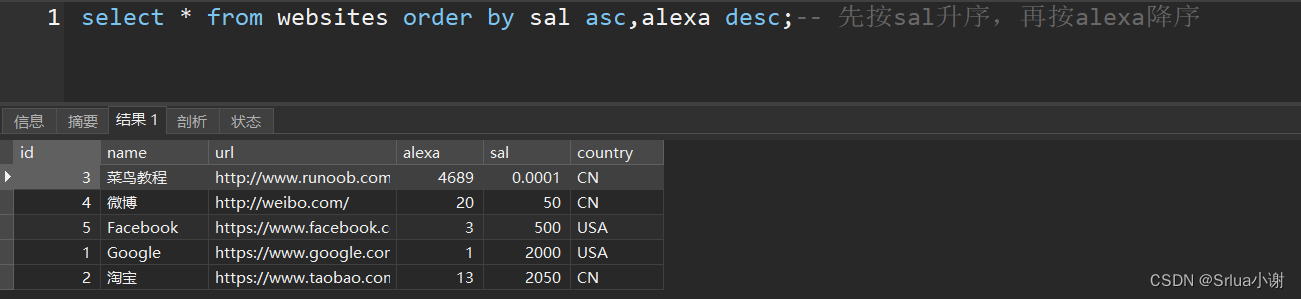
select * from websites order by sal asc,alexa desc;-- 先按sal升序,再按alexa降序注意 :分组时候的筛选用having
常见的几个组函数:max()min()avg()count()sum()
在 SQL 中,ASC 和 DESC 用于指定排序顺序:
-
ASC 表示升序(从小到大),是默认的排序顺序,如果不指定排序顺序,默认为 ASC。
-
DESC 表示降序(从大到小),使用 DESC 关键词可以让查询结果按指定列以降序排列。
`order by sal asc` 表示按照 sal 列的升序排列,而 `alexa desc` 表示按照 alexa 列的降序排列。
like 通配符
sql
select * from websites where name like '%O%'
select * from websites where name like '_O%'-- 匹配一个字符

in 匹配多个条件
sql
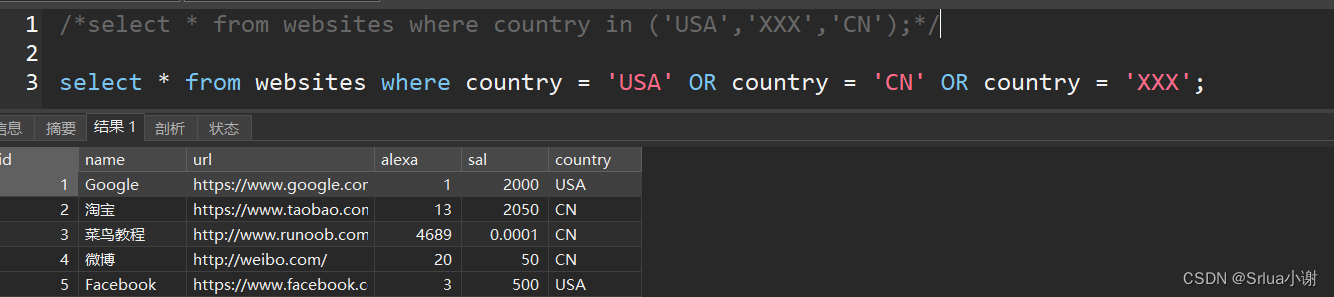
select * from websites where country in ('USA','XXX','CN');
-- 等价于
select * from websites where country = 'USA' OR country = 'CN' OR country = 'XXX';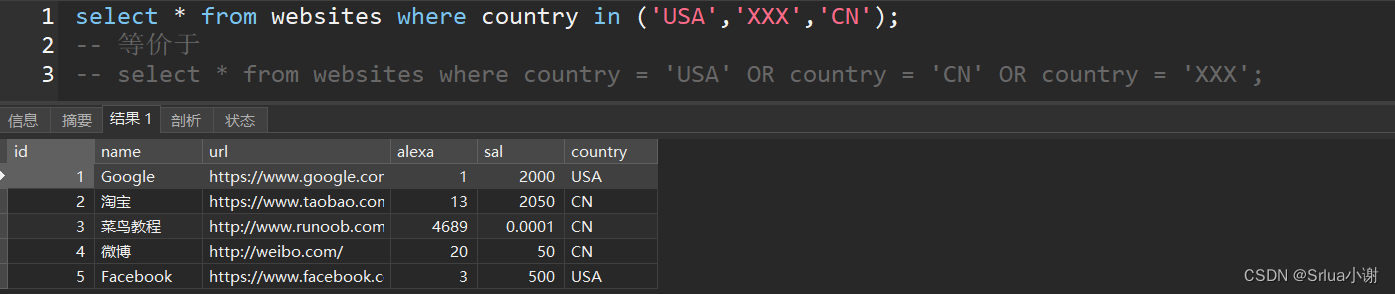
别名
sql
select tt.name '网站名字' from websites tt -- tt是表的别名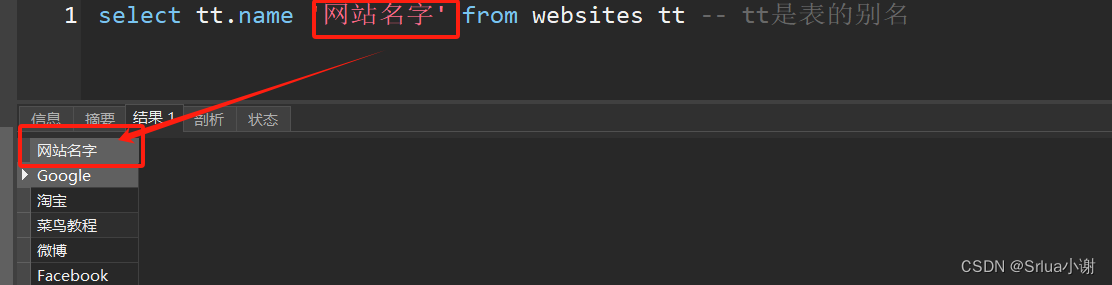
group by 分组查询
sql
select avg(sal) '平均值' ,country from websites group by country;
select avg(sal) '平均值' ,country from websites group by country HAVING 平均值 > 1200;-- 不能用where,只能用having;
子查询
把查询结果当做一个表来使用
子查询是指在 SQL 查询中嵌套使用的查询,将内部查询的结果作为外部查询的数据源之一。通过子查询,可以将查询结果当做一个表来使用,从而进行更复杂的数据操作和筛选。
例如,下面是一个简单的示例,演示了如何使用子查询:
sql
SELECT name, age
FROM students
WHERE age > (SELECT AVG(age) FROM students);在这个示例中,(SELECT AVG(age) FROM students) 就是一个子查询,它计算了学生年龄的平均值,并将该值作为外部查询条件进行筛选。子查询的结果就好像是一个临时的虚拟表,可以被外部查询引用和操作。
通过子查询,我们可以实现更灵活、更精细的数据查询和操作,从而满足复杂的业务需求。不过需要注意的是,过度复杂的子查询可能会影响查询性能和可读性,因此在使用子查询时需要权衡其优劣并谨慎设计。
连接查询
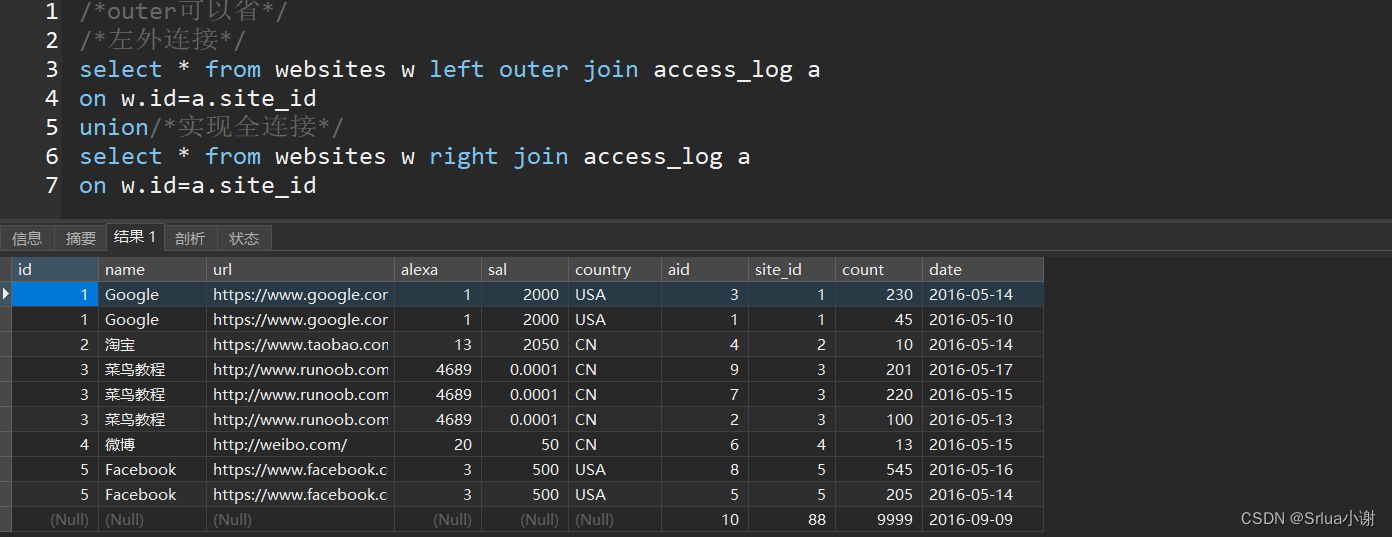
左外连接(Left Outer Join)、全连接(Full Outer Join)和右外连接(Right Outer Join)是 SQL 中用于合并表的不同类型的连接操作。
**1. 左外连接(Left Outer Join):**左外连接会返回左表中所有的行,并且和右表中满足连接条件的行进行连接,如果右表中没有匹配的行,则会用 NULL 值填充。左表是指在 JOIN 关键字之前的表,而右表是指在 JOIN 关键字之后的表。
sql
SELECT * FROM table1 LEFT OUTER JOIN table2 ON table1.column_name = table2.column_name;**2. 全连接(Full Outer Join):**全连接会返回左表和右表中的所有行,并且对于没有匹配的行会用 NULL 值填充。
sql
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.column_name = table2.column_name;**3. 右外连接(Right Outer Join):**右外连接会返回右表中所有的行,并且和左表中满足连接条件的行进行连接,如果左表中没有匹配的行,则会用 NULL 值填充。
sql
SELECT * FROM table1 RIGHT OUTER JOIN table2 ON table1.column_name = table2.column_name;这些连接操作允许在 SQL 查询中根据特定的条件将两个表中的行进行关联,从而实现数据的联合查询和合并。左外连接、全连接和右外连接提供了灵活的方式来处理不同表之间的关系,使得我们可以根据具体的需求进行数据的组合和筛选。
查询每个网站的每天的访问量,显示出:名称访问量日期
sql
/*过时写法*/
/*不加where的话会随意乱连*/
/*内连接*/
select name,a.count,a.date from websites w,access_log a where w.id=a.site_id
/*outer可以省*/
/*左外连接*/
select * from websites w left outer join access_log a
on w.id=a.site_id
union/*实现全连接*/
select * from websites w right join access_log a
on w.id=a.site_id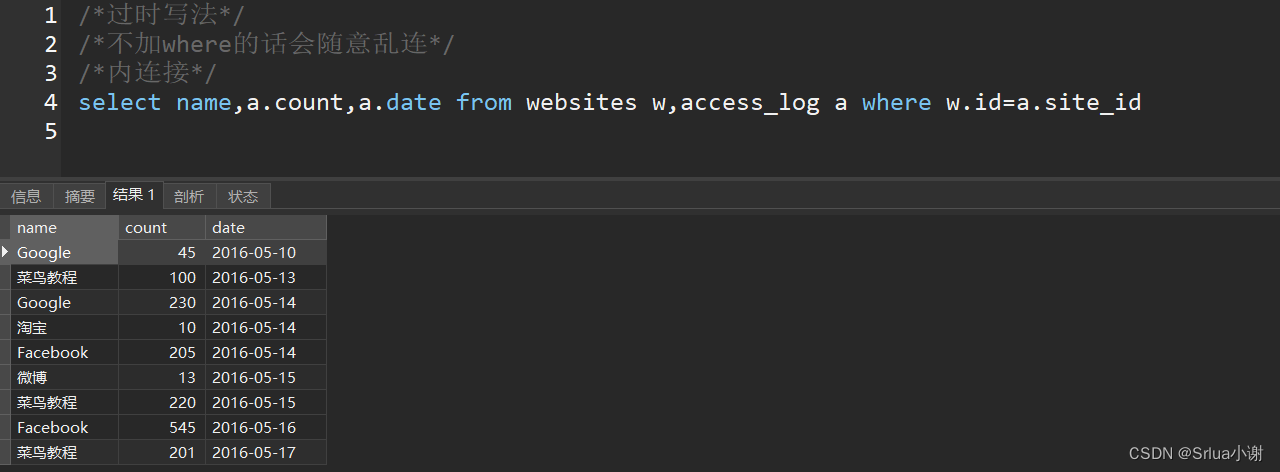
ifnull
sql
select name,ifnull(count,0),ifnull(a.date,'无日期') from websites w left outer join access_log a
on w.id=a.site_id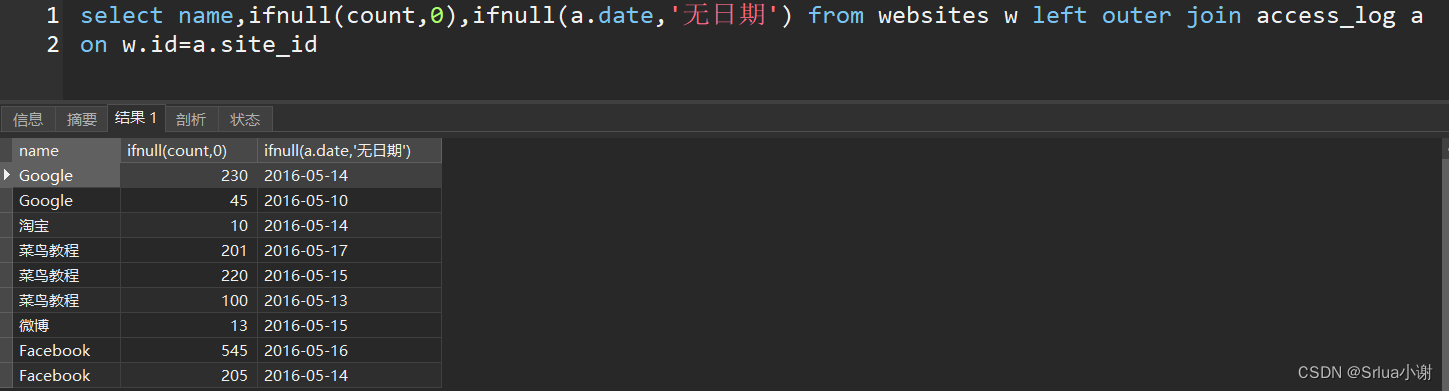
这条 SQL 查询语句使用了左外连接(Left Outer Join),将表 websites(别名为 w)和 access_log(别名为 a)进行连接,并使用了 ifnull 函数来处理可能出现的 NULL 值。
这条查询的作用是获取网站名称、访问次数以及最近访问日期(如果有的话)。具体解释如下:
- `select name, ifnull(count,0), ifnull(a.date,'无日期')`: 从左表 websites 中选择 name 列,并从右表 access_log 中选择 count 和 date 列,使用 ifnull 函数来处理可能的 NULL 值。
- `from websites w left outer join access_log a on w.id=a.site_id`: 这部分指定了左外连接的逻辑,即将表 websites 和 access_log 根据 site_id 列进行连接,左表为 w,右表为 a。
左外连接将返回左表 websites 中的所有行,同时匹配右表 access_log 中的行。如果某个网站在 access_log 中没有对应的访问记录,那么 count 和 date 列就会包含 NULL 值。ifnull 函数用于将可能的 NULL 值替换为指定的默认值(0 或 '无日期')。
总的来说,这条查询用于获取网站的访问次数以及最近访问日期(如果有的话),并且对可能的 NULL 值进行了处理。

希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!